分布式服务(RPC)+分布式消息队列(MQ)面试题精选
分布式系统(distributed system)是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。

分布式消息队列(MQ)
为什么使用 MQ?
- 异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。
- 应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。
- 流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。
- 日志处理 - 解决大量日志传输。
- 消息通讯 - 消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
如何保证 MQ 的高可用?
- 将所有 Broker 和待分配的 Partition 排序
- 将第 i 个 Partition 分配到第(i mod n)个 Broker 上
- 将第 i 个 Partition 的第 j 个 Replica 分配到第((i + j) mode n)个 Broker 上
MQ 有哪些常见问题?如何解决这些问题?
MQ 的常见问题有:
- 消息的顺序问题
- 消息的重复问题
消息的顺序问题
消息有序指的是可以按照消息的发送顺序来消费。
假如生产者产生了 2 条消息:M1、M2,假定 M1 发送到 S1,M2 发送到 S2,如果要保证 M1 先于 M2 被消费,怎么做?
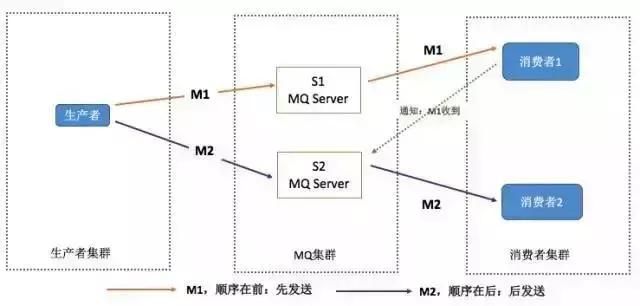
解决方案:(1)保证生产者 - MQServer - 消费者是一对一对一的关系

- 缺陷:并行度就会成为消息系统的瓶颈(吞吐量不够)
- 更多的异常处理,比如:只要消费端出现问题,就会导致整个处理流程阻塞,我们不得不花费更多的精力来解决阻塞的问题。 (2)通过合理的设计或者将问题分解来规避。
- 不关注乱序的应用实际大量存在
- 队列无序并不意味着消息无序 所以从业务层面来保证消息的顺序而不仅仅是依赖于消息系统,是一种更合理的方式。
消息的重复问题
造成消息重复的根本原因是:网络不可达。
所以解决这个问题的办法就是绕过这个问题。那么问题就变成了:如果消费端收到两条一样的消息,应该怎样处理?
消费端处理消息的业务逻辑保持幂等性。只要保持幂等性,不管来多少条重复消息,最后处理的结果都一样。保证每条消息都有唯一编号且保证消息处理成功与去重表的日志同时出现。利用一张日志表来记录已经处理成功的消息的 ID,如果新到的消息 ID 已经在日志表中,那么就不再处理这条消息。
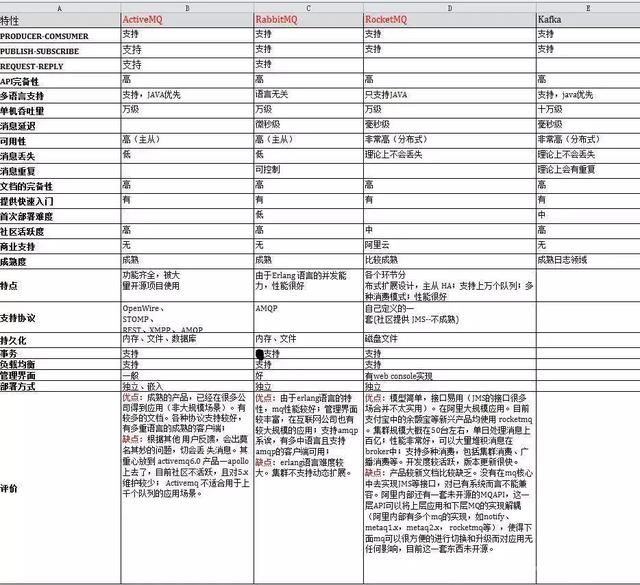
Kafka, ActiveMQ, RabbitMQ, RocketMQ 各有什么优缺点?
分布式服务(RPC)
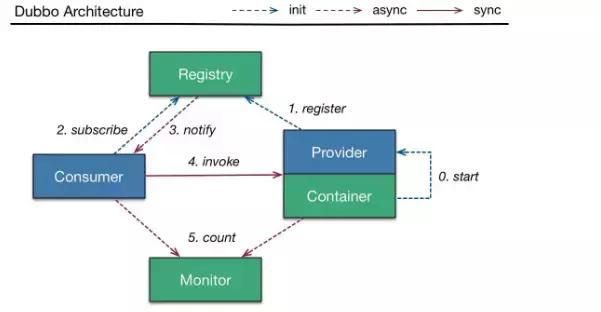
Dubbo 的实现过程?
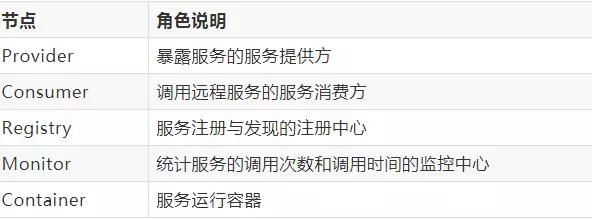
节点角色:
调用关系:
- 务容器负责启动,加载,运行服务提供者
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo 负载均衡策略有哪些?
Random
- 随机,按权重设置随机概率。
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
RoundRobin
- 轮循,按公约后的权重设置轮循比率。
- 存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
LeastActive
- 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
- 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHash
- 一致性 Hash,相同参数的请求总是发到同一提供者。
- 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
- 缺省只对第一个参数 Hash,如果要修改,请配置
- 缺省用 160 份虚拟节点,如果要修改,请配置
Dubbo 集群容错策略 ?
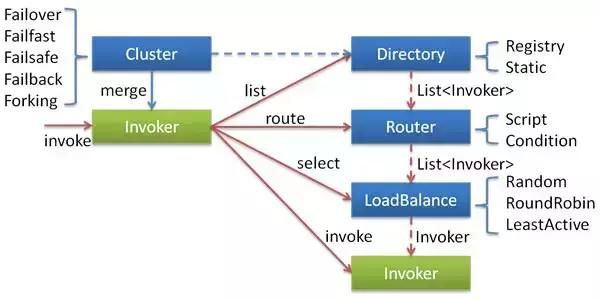
- Failover - 失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。
- Failfast - 快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
- Failsafe - 失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
- Failback - 失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
- Forking - 并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
- Broadcast - 播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
动态代理策略?
Dubbo 作为 RPC 框架,首先要完成的就是跨系统,跨网络的服务调用。消费方与提供方遵循统一的接口定义,消费方调用接口时,Dubbo 将其转换成统一格式的数据结构,通过网络传输,提供方根据规则找到接口实现,通过反射完成调用。也就是说,消费方获取的是对远程服务的一个代理(Proxy),而提供方因为要支持不同的接口实现,需要一个包装层(Wrapper)。调用的过程大概是这样:
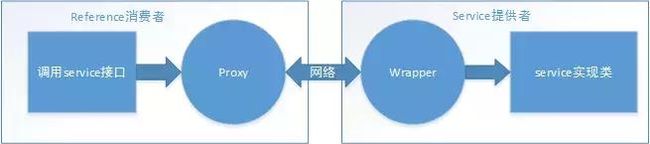
消费方的 Proxy 和提供方的 Wrapper 得以让 Dubbo 构建出复杂、统一的体系。而这种动态代理与包装也是通过基于 SPI 的插件方式实现的,它的接口就是ProxyFactory。@SPI("javassist")
public interface ProxyFactory {
@Adaptive({Constants.PROXY_KEY})
T getProxy(Invoker invoker) throws RpcException;
@Adaptive({Constants.PROXY_KEY})
Invoker getInvoker(T proxy, Class type, URL url) throws RpcException;
}
ProxyFactory 有两种实现方式,一种是基于 JDK 的代理实现,一种是基于 javassist 的实现。ProxyFactory 接口上定义了@SPI("javassist"),默认为 javassist 的实现。
Dubbo 支持哪些序列化协议?Hessian?Hessian 的数据结构?
- dubbo 序列化,阿里尚不成熟的 java 序列化实现。
- hessian2 序列化:hessian 是一种跨语言的高效二进制的序列化方式,但这里实际不是原生的 hessian2 序列化,而是阿里修改过的 hessian lite,它是 dubbo RPC 默认启用的序列化方式。
- json 序列化:目前有两种实现,一种是采用的阿里的 fastjson 库,另一种是采用 dubbo 中自已实现的简单 json 库,一般情况下,json 这种文本序列化性能不如二进制序列化。
- java 序列化:主要是采用 JDK 自带的 java 序列化实现,性能很不理想。
- Kryo 和 FST:Kryo 和 FST 的性能依然普遍优于 hessian 和 dubbo 序列化。
Hessian 序列化与 Java 默认的序列化区别?
Hessian 是一个轻量级的 remoting on http 工具,采用的是 Binary RPC 协议,所以它很适合于发送二进制数据,同时又具有防火墙穿透能力。
- Hessian 支持跨语言串行
- 比 java 序列化具有更好的性能和易用性
- 支持的语言比较多 Protoco Buffer 是什么?
Protocol Buffer 是 Google 出品的一种轻量 & 高效的结构化数据存储格式,性能比 Json、XML 真的强!太!多!
Protocol Buffer 的序列化 & 反序列化简单 & 速度快的原因是:
- 编码 / 解码 方式简单(只需要简单的数学运算 = 位移等等)
- 采用 Protocol Buffer 自身的框架代码 和 编译器 共同完成
Protocol Buffer 的数据压缩效果好(即序列化后的数据量体积小)的原因是:
- 采用了独特的编码方式,如 Varint、Zigzag 编码方式等等
- 采用 T - L - V 的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑
注册中心挂了可以继续通信吗?
可以。Dubbo 消费者在应用启动时会从注册中心拉取已注册的生产者的地址接口,并缓存在本地。每次调用时,按照本地存储的地址进行调用。
ZooKeeper 原理是什么?ZooKeeper 有什么用?
ZooKeeper 是一个分布式应用协调系统,已经用到了许多分布式项目中,用来完成统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等工作。

- 每个 Server 在内存中存储了一份数据;
- Zookeeper 启动时,将从实例中选举一个 leader(Paxos 协议);
- Leader 负责处理数据更新等操作(Zab 协议);
- 一个更新操作成功,当且仅当大多数 Server 在内存中成功修改数据。
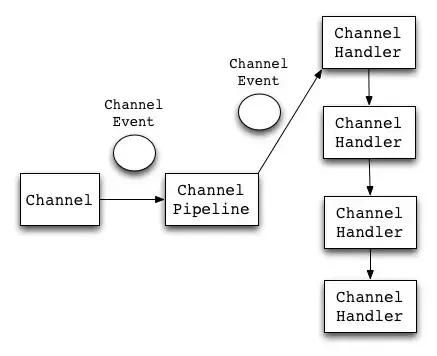
Netty 有什么用?NIO/BIO/AIO 有什么用?有什么区别?
Netty 是一个“网络通讯框架”。
Netty 进行事件处理的流程。Channel是连接的通道,是 ChannelEvent 的产生者,而ChannelPipeline可以理解为 ChannelHandler 的集合。
IO 的方式通常分为几种:
- 同步阻塞的 BIO
- 同步非阻塞的 NIO
- 异步非阻塞的 AIO 在使用同步 I/O 的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。
NIO 基于 Reactor,当 socket 有流可读或可写入 socket 时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。
与 NIO 不同,当进行读写操作时,只须直接调用 API 的 read 或 write 方法即可。这两种方法均为异步的,对于读操作而言,当有流可读取时,操作系统会将可读的流传入 read 方法的缓冲区,并通知应用程序;对于写操作而言,当操作系统将 write 方法传递的流写入完毕时,操作系统主动通知应用程序。即可以理解为,read/write 方法都是异步的,完成后会主动调用回调函数。
为什么要进行系统拆分?拆分不用 Dubbo 可以吗?
系统拆分从资源角度分为:应用拆分和数据库拆分。
从采用的先后顺序可分为:水平扩展、垂直拆分、业务拆分、水平拆分。
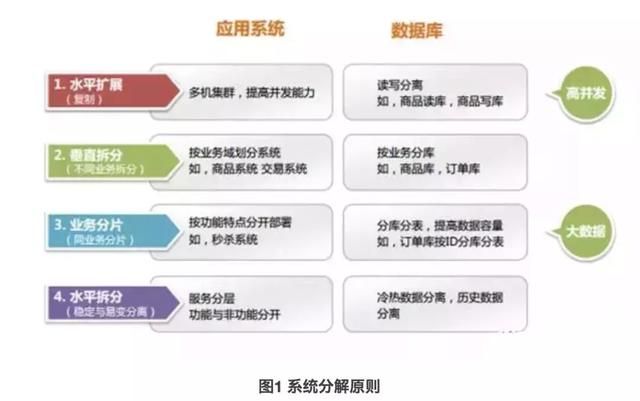
是否使用服务依据实际业务场景来决定。当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。
Dubbo 和 Thrift 有什么区别?
- Thrift 是跨语言的 RPC 框架。
- Dubbo 支持服务治理,而 Thrift 不支持。
最后
这里分享的只是个人的看法,要考虑的事没那么简单的,后面有机会深入的话,我还会继续分享,希望这篇文章对大家有所帮助~
最后福利:欢迎大家加入Java猫的架构学习基地:810589193免费获取Java工程化、高性能及分布式、高性能、高架构、性能调优、Spring、MyBatis、Netty源码分析等多个知识点高级进阶干货的直播免费学习权限及相关视频资料,还有spring和虚拟机等书籍扫描版
私信关键词 【架构】免费获取!