飞桨工程师亲授调参技巧,可使MobileNetv3-YOLOv3模型压缩70%,推理速度提升1倍

随着端侧算力日益增长,以及模型小型化方案日趋成熟,使得高精度的深度学习模型在移动端、嵌入式等终端设备上流畅运行成为可能。然而将深度学习融合到终端设备上依旧面临平衡复杂神经网络结构的精度和设备性能约束的挑战,往往需要模型开发者在深入理解模型结构的基础上,各种调参并进行细致全面的优化才能达到理想的效果。

近期PaddleDetection推出了一系列针对端侧设备的紧致高效模型,覆盖单阶段及两阶段等主流网络结构,在速度、精度上均取得了不错的表现。这里将模型迭代过程中的设计思路及用到的技巧做一个总结,供感兴趣的同学参考。
为方便大家快速练手,这里提供了一个基于MobileNetv3-YOLOv3的模型优化项目,使用了剪裁、蒸馏的优化策略,所有代码均可以在AI Studio跑通,大家也可以通过AI Studio在线调试。
https://aistudio.baidu.com/aistudio/projectdetail/551433
目标检测模型特点
PaddleDetection此次发布的端侧模型涵盖了三类主流模型结构,按照设计思想可以分为单阶段和两阶段:
1、单阶段(One-stage):这类模型结构相对简单,通常在全卷积网络(FCN)上直接连接检测头输出类别及位置信息。典型代表有:SSD[1]系列、YOLO[2]系列。这类结构由于其pipeline相对短,相对延时低,对移动应用比较友好。尤其是SSD系列,在端侧使用广泛,各种人脸,手势检测应用中都能见到它的身影。
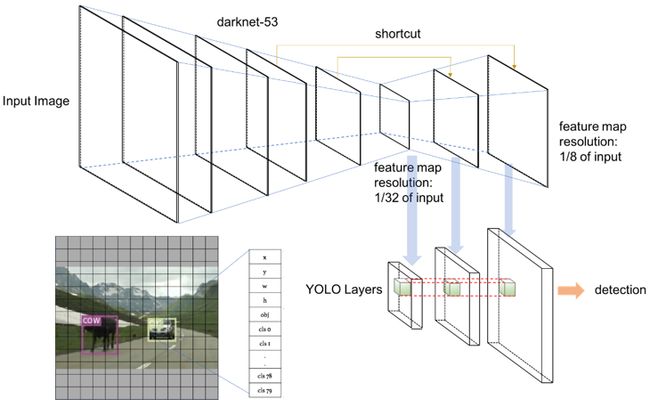
图1 YOLOv3
2、两阶段 (Two-stage):顾名思义,这类结构将检测流程分为两个阶段,第一阶段输出粗糙的候选框(proposal),第二阶段将候选框对应特征提取出来,在其基础进一步预测类别并细化输出位置信息,代表结构如Faster R-CNN[3]。这种设计的好处是位置信息较为精确,小目标的检测精度更好。但是由于组成部分较多,整体流程较长,时延往往会比较高,很难在端侧成功落地(后面可以看到,通过使用我们的优化方法,这类模型在端侧也能取得不俗的成绩)。
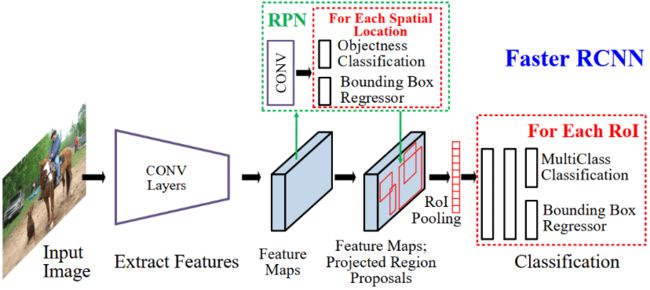
图2 Faster RCNN
优化思路
上述两类模型的运行流程如下所示:
-
单阶段: 特征提取 -> 检测头 -> 后处理
-
两阶段: 特征提取 -> RPN (Region Proposal Network) -> ROI池化 -> 检测头 -> 后处理
其中,ROI池化和后处理多为手工设计的模块,依赖于部署框架的实现;RPN只有2个卷积层,且输出通道数仅为4和1,运行时间占比不高。综合来看,优化特征提取器和检测头是减少端侧运算量的关键。
实用Trick分享
优化特征提取器
通用物体检测模型的特征提取器通常使用基于ImageNet预训练的CNN模型(ResNet, ResNeXt, MobileNet, ShuffleNet)等作为主干网络(Backbone)。主干网络预训练模型的精度和速度会极大的影响检测模型的最终表现。飞桨图像分类库PaddleClas的预训练模型为主干网络提供了丰富的选择。例如端侧通用检测模型常用的MobileNet系列,就有多个版本(部分精度及延时对比见下表)。
我们统一使用了半监督学习知识蒸馏预训练的MobileNetV3,最终各检测模型在COCO mAP上均获得了0.7%~1.5%的精度提升。以YOLOv3为例,用MobileNetV3替换MobileNetV1作为主干网络,COCO的精度从29.3提升到31.4,而且骁龙855芯片上推理时延从187.13ms降低到155.95ms。

需要注意的是,由于蒸馏的预训练模型的特征非常精细,需要适当减小主干网络的相对学习率及L2 decay,防止在训练的过程中破坏其特征。
优化特征融合FPN
为了进一步将多层的特征进行有效融合(fusion)及细化(refine),Faster R-CNN模型使用了FPN(Feature Pyramid Network )[4]模块,其中选择哪些特征层进行FPN融合及后续处理非常关键。对于MobileNet主干网络,通常使用C2~C5特征层进行特征融合。
融合处理后,输出5个特征层(P2~P6),分辨率从1/4到1/64。为了提升预测速度,我们尝试减少一个特征层,即只输入C2~C4,生成P2~P4,该调整可以减少21%的延时,但在COCO数据集上mAP仅降低了0.9%。进一步分析发现在此特征组合下,RPN输出大物体的召回率很低。由此,我们在FPN模块里添加降采样卷积,额外生成P5~P6,此修改将COCO mAP提升了1.3%,但预测时间仅增加9%左右。
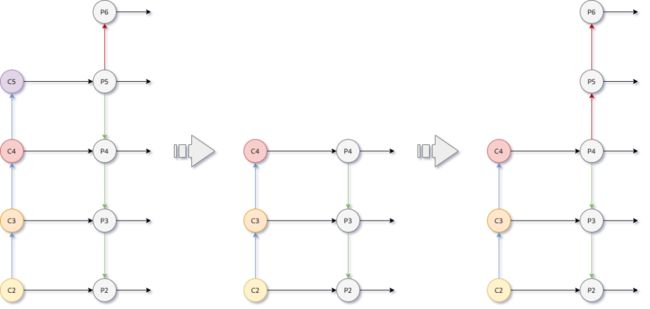
图3 FPN调整
优化检测头
检测头通常由多层卷积组成。当提取特征的骨干网络的运算量减少后,如果继续使用检测头的标准配置,耗时将会成为优化的主要瓶颈。例如,在YOLOv3-MobileNetv3中,检测头部分的耗时约占50%。缩小检测头,减少检测头的预算量,对于端侧模型来说是一个非常重要的优化环节。一般是通过手动设计或者通过模型压缩裁剪策略,对检测头的卷积层进行结构化裁剪来实现。
比如,我们对两阶段Faster R-CNN模型,大幅减少FPN的卷积通道数量(256->48)及检测头的全连接层通道数量(1024->128)。在YOLOv3模型中,通过模型压缩的裁剪方法对检测头进行裁剪,下文有详细的实战说明。
调参技巧大放送
对于端侧模型,除了通过修改结构来获得较好的延时以外,往往还需要通过优化训练过程来提升精度。模型的训练过程一般包含数据预处理,损失函数的设计,学习率策略等,这类训练技巧可以在不增加运算量的基础上大大提升模型的精度。
1)自动增广(AutoAugment)数据增强
数据增强是提高神经网络准确性的有效技术,但是大部分的数据增强实现是手动设计的。自动增广AutoAugment,是将若干种组合策略,如图像平移、旋转、直方图均衡化等,组合为一个增广的集合,每次随机从其中选择一个子策略(该子策略也可能是多种增广的融合),并使用该策略对输入图像进行增广。经实验验证,在两阶段端侧检测模型上,使用该策略能够带来0.5%的精度提升。
值得提醒的一点:对小模型而言,由于本身学习能力有限,过度的数据增强很难提升模型的最终精度,甚至还可能起到相反的效果。例如,实验发现,两阶段端侧检测模型采用GridMask后,精度不升反降。
2)学习率策略
深度学习的训练是一个优化过程,训练过程中模型的权重会不断变化,而这个变化的速度由学习率决定。随着训练的进行,学习率本身也要不断的调整,从而避免模型陷入局部最优,鞍点或者最优点一直在附近振荡。合适的学习率调整策略会使得训练过程更加平滑,从而提升模型的最终精度。实验发现,相比通常的三段学习率,使用余弦学习率策略训练可以达到更高的精度,而且该策略不引入额外超参,鲁棒性较高。余弦学习率策略的计算公式如下:
decayed_lr=learning_rate∗0.5∗(cos(epoch∗math.piepochs)+1)
余弦学习率策略同三阶段学习率策略对比曲线如下: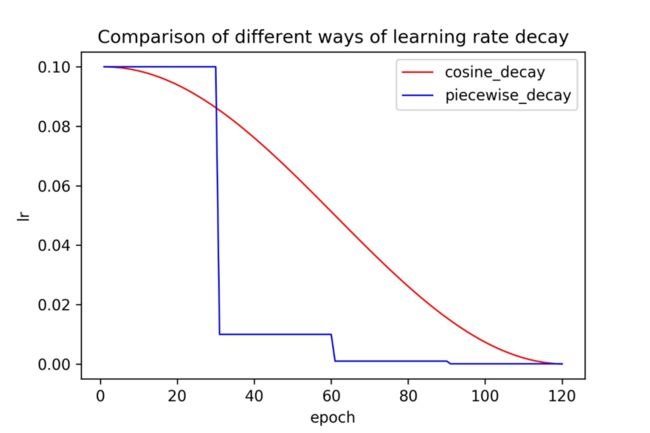
可以看到,在整个训练过程中,余弦策略都保持着较大的学习率,所以其收敛较为缓慢,但是最终的收敛效果更好。在两阶段端侧模型优化中,使用余弦学习率策略精度相对提升0.8%。
3)Balanced L1 loss
Libra R-CNN[5]提出了Balanced L1 loss损失函数。中心思想是平衡目标检测的两种任务(定位及分类)及样本难度对模型训练的影响,从而达到更优的精度表现。具体做法是对定位任务的smooth L1 loss进行改进,通过对难样本(outlier)进行梯度裁剪(gradient clip),避免模型权重更新不平衡。其公式如下:
∂Lb∂x={αln(b|x|+1)γif |x|<1otherwise
两阶段检测模型中,最后在检测头部分进行边框回归时,使用Balanced L1 loss替换传统的somooth l1 loss,可以带来0.4%的mAP提升。
模型裁剪
卷积通道裁剪是一种很有效的在保证模型精度的情况下减小模型大小的解决方案。通过一定的裁剪机制,将重要性低的卷积通道剪裁掉,从而减小运算量。相比于手工设计缩小网络,基于模型压缩的裁剪算法更具通用性和迁移性。
目前PaddleDetection集成了飞桨模型压缩工具PaddleSlim,提供针对检测模型的压缩方案。在MobileNetv3-YOLOv3中就是通过此方案实现的模型加速。感兴趣的同学可以猛戳这里进行YOLOv3剪裁的实操实验。
知识蒸馏
知识蒸馏[6]对深度学习爱好者应该不再陌生,该技术已被广泛应用于CV,NLP等多个领域。就CV而言,知识蒸馏的有效性在分类任务已获得大量验证,但目前在检测领域的应用还相对较少。我们在YOLOv3的检测头优化过程中尝试了蒸馏方式来fine tune剪裁后的模型,使用精度更高的YOLOv3-ResNet34模型作为teacher模型,对YOLOv3-MobileNetV3模型进行蒸馏。最终的实验结果表明,在COCO数据集上可以获得2-3个点的精度收益。感兴趣的同学可以继续猛戳这里进行实操实验。
模型量化
考虑到端侧模型通常使用CPU部署,通常有较好的Int8 vectorization运算支持。使用Int8精度对FP32的模型进行量化,不仅可以减小存储体积,还能够对常见卷积、全连接的计算进行加速。模型量化主流方式有:训练后量化 (Post training quantization)和量化训练(Quantization aware training)。前者使用少量样本数据对模型进行校准,获取其权重及激活的动态数值范围,再根据该数据对权重进行量化。后者在模型训练过程中对模型权重进行伪量化(fake quantization)使得模型能够适应量化带来的噪音,从而减少最终得精度损失。我们在SSDLite[7]的训练过程中使用这种量化方式,最终实现在少量精度损失(mAP -0.4%)的基础上加速22%左右的效果。
已发布模型
这次PaddleDetection发布了三类模型,根据模型本身的设计特点选择使用上述技巧,最终的收益非常显著。
-
Faster-RCNN: 在调整FPN结构的基础上手动减少了FPN及检测头的通道数,并使用AutoAugment数据增强、余弦学习率策略及Balanced L1 loss进行训练
-
YOLOv3:使用剪裁缩小检测头提升速度,并使用蒸馏训练来提升模型精度。
-
SSDLite:使用余弦学习率策略训练,并使用量化训练进一步加速。
最终发布的模型测评结果可参考下表:

结论及展望
以上是PaddleDetection在端侧模型开发过程中的一些经验总结,希望对开发端侧模型有兴趣的同学有所帮助。除了上面提到的模型外,PaddleDetection后续将会持续发布更小,更快,更强的端侧检测模型。其中,无锚点(Anchor-free)模型目前正在紧锣密鼓的开发中,敬请期待呦!
参考文献
-
Liu, Wei, et al. “SSD: Single Shot MultiBox Detector.” ArXiv:1512.02325
-
Redmon, Joseph, and Ali Farhadi. “YOLOv3: An Incremental Improvement.” ArXiv:1804.02767
-
Ren, Shaoqing, et al. “Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks.” ArXiv:1506.01497
-
Lin, Tsung-Yi, et al. “Feature Pyramid Networks for Object Detection.” ArXiv:1612.03144
-
Pang, Jiangmiao, et al. “Libra R-CNN: Towards Balanced Learning for Object Detection.” ArXiv:1904.02701
-
Hinton, Geoffrey, et al. “Distilling the Knowledge in a Neural Network.” ArXiv:1503.02531
-
Sandler, Mark, et al. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” ArXiv:1801.04381
本项目代码和文件均放在百度一站式在线开发平台AI Studio上,链接如下:
https://aistudio.baidu.com/aistudio/projectdetail/551433
如在使用过程中有问题,可加入飞桨官方QQ群:1108045677
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub:
https://github.com/PaddlePaddle/Paddle
Gitee:
https://gitee.com/paddlepaddle/Paddle
END
