binder驱动-------之数据结构篇1
1: 进程在binder驱动中的表示(struct binder_proc)
每个参与binder通讯的进程在binder驱动中,都会用这样一个结构体来描述。在应用空间,每个进程都会通过ProcessState::self()函数来调用到open_driver()函数,从而open一次/dev/binder节点,并且会创建一个属于该进程的一个 binder_proc *proc 结构体,并初始化该结构体,最后添加到全局的 binder_procs 哈希列表中。
struct binder_proc {
struct hlist_node proc_node;
struct rb_root threads;
struct rb_root nodes;
struct rb_root refs_by_desc;
struct rb_root refs_by_node;
int pid;
struct vm_area_struct *vma;
struct mm_struct *vma_vm_mm;
struct task_struct *tsk;
struct files_struct *files;
struct hlist_node deferred_work_node;
int deferred_work;
void *buffer;
ptrdiff_t user_buffer_offset;
struct list_head buffers;
struct rb_root free_buffers;
struct rb_root allocated_buffers;
size_t free_async_space;
struct page **pages;
size_t buffer_size;
uint32_t buffer_free;
struct list_head todo;
wait_queue_head_t wait;
struct binder_stats stats;
struct list_head delivered_death;
int max_threads;
int requested_threads;
int requested_threads_started;
int ready_threads;
long default_priority;
struct dentry *debugfs_entry;
};1.1 binder misc
- proc_node成员:用于将当前系统所有参与binde通讯的进程通过该节点组织到一张hash表:binder_procs中
- threads:该成员的描述见下节。
- nodes: 属于该进程的所有binder实体都连接在以该节点为根的红黑树下
- refs_by_desc:属于该进程的所有binder引用以引用号为索引,组织在以该节点为根的红黑树下
- refs_by_node:属于该进程的所有binder引用以该引用对应的binder实体在内核的地址为索引,组织在以该节点为根的红黑树下
为什么binder引用要组织成两颗红黑树呢,前一颗树便于在已知引用号(handle)的情况下快速得到binder引用(struct binder_ref),而后者便于在已知binder实体(struct binder_node)的地址,快速得到该binder实体在进程下的binder引用(struct binder_ref),典型的以内存换速度,在ipc通讯中,速度是至关重要的。
- pid:当前进程的id号
1.2 binder内存管理相关
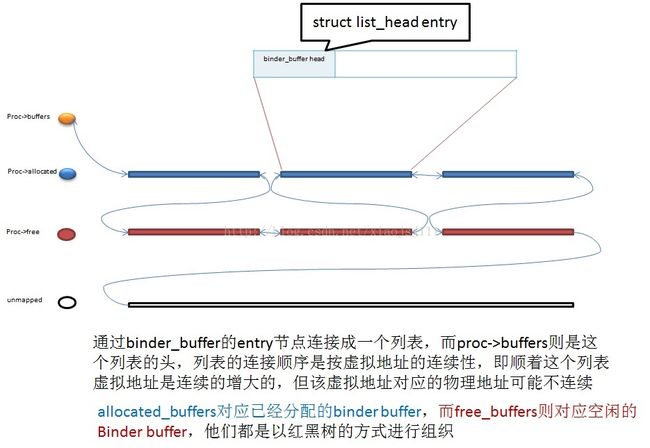
binder驱动为每个参与通讯的进程开辟了1Mbyte左右的内存区域,他们是虚拟地址连续,但是物理地址可能不连续。到这里具有忧患意识的程序员可能已经意识到:如果系统很有多进程都参与binder通讯,每个进程都有1M左右的内存空间,那这个系统内存不是一下就用光光了?呵呵,但事实是这样的:binder驱动只是预留了一段1M大小的虚拟地址,只是做了一个物理页的内存映射,其他都空着,虚位以待,待日后需要实际访问时,再去根据需要分配实际的物理内存;并且在使用完后都会及时释放掉,这样就充分利用了宝贵的物理内存。先上一个大概的草图:
- vma:当前进程的mmap对应的内存区块在应用空间的表示
- vma_vm_mm:
- buffer:指向内核vmalloc区域的一片虚拟内存,该片区域大小在应用空间被固定为1Mbtye-8192byte左右,并且刚开始只是映射了一个物理页,并将这一物理页插入到free_buffers树中。
- user_buffer_offset:binder的这块物理内存在内核空间的地址跟同样的这块物理内存在当前进程的用户空间的地址之差
- buffers:内核中,binder buffer的虚拟内存块按地址的连续性连接成一个列表,buffers即为这个列表的头
- free_buffers:对应空闲buffer,这些buffer块以块的大小为index,组织为一个红黑树,这个树上的buffer块,有可能已经映射过,也有可能没有映射过
- allocated_buffers:对应已经分配的buffer,这些buffer块以地址为index,组织为一颗红黑树,这个树上的buffer块都已经建立好了映射
- pages:用来存储物理页表对应的struct page结构的地址的指针数组,大小为:sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE
- buffer_size:表示虚拟内存块的总大小,即为:vma->vm_end - vma->vm_start
1.3 binder的数据接收队列和进程等待队列
- todo:用来存储binder_transaction事物的队列,由于该事物包含了数据流,所以可以认为就是一个数据接收队列
- wait:进程等待队列,当线程本身没有事物需要处理(条件:thread->transaction_stack == NULL && list_empty(&thread->todo)),且进程本身也没有事物需要处理(条件:list_empty(&proc->todo)),这个时候就将这个线程放到proc->wait的等待队列,并将proc->ready_threads加一,当后续有事物请求过来的时候,再唤醒这个线程来进行处理,唤醒后需要及时的将proc->ready_threads减一。
1.4 binder的线程管理
- max_threads:binder在应用空间的实体在初始化阶段,通过BINDER_SET_MAX_THREADS ioctl命令就已经设置了该服务端可以启动的最大线程数。
- requested_threads:在服务器端线程池中的线程即将不能满足接下来的并发请求时,且进程中也没有空闲的线程,且且池中的线程数还未超过允许的最大线程数(判断条件:proc->requested_threads + proc->ready_threads == 0 && proc->requested_threads_started < proc->max_threads)则内核请求binder在应用空间的实体,再spawn出一个新的线程来处理客服端过来的并发请求,此时只是发起请求,但还未真正创建这个线程:内核在发送BR_SPAWN_LOOPER ID到应用空间之前,将proc->requested_threads++
- requested_threads_started:binde在应用空间的实体通过命令:BC_REGISTER_LOOPER,告诉binder内核线程已经创建,此时内核执行如下操作:proc->requested_threads--和proc->requested_threads_started++。
- ready_threads:表示空闲的线程数,当线程没有正在处理但还未处理完的事物(thread->transaction_stack == NULL),todo列表也没有待处理的事物(list_empty(&thread->todo)),则该线程就是空闲的,内核将proc->ready_threads++,(注意在thread->todo为空,但proc->todo这个时候可能不为空)当线程由空闲状态转到非空闲状态时,即线程被唤醒时,需要执行:proc->ready_threads--
1.5 总结
在研究一个数据结构时,首先应该搞清楚的是该结构体表示什么含义,具体一点就代表什么概念或是对象,其次该结构体下的成员为什么这样组织。譬如回到这个binder_proc结构体,binder内存相关的这些成员(vma,buffer,buffers,free_buffers,allocated_buffers等)由于他们是依赖于具体进程的,不同的进程,在驱动中,这些成员的值都是不同的。所以将这些成员放到了表示进程的binder_proc结构体中,这样不同的进程实例都有自己私有的内存相关的成员变量;其次就是要定义清楚状态的判断标准是什么,而这些判断标准一般都是由条件变量组成,而清楚这些条件变量各自表示什么含义就至关重要了。
2:线程在binder驱动中的表示(binder_thread)
在同一个进程下,会有多个线程,而每个线程在内核用这个结构体来表示,而在同一个进程下,所有线程以线程的pid号为index,组织成一个以proc->threads为根节点的红黑树。
struct binder_thread {
struct binder_proc *proc;
struct rb_node rb_node;
int pid;
int looper;
struct binder_transaction *transaction_stack;
struct list_head todo;
uint32_t return_error; /* Write failed, return error code in read buf */
uint32_t return_error2; /* Write failed, return error code in read */
/* buffer. Used when sending a reply to a dead process that */
/* we are also waiting on */
wait_queue_head_t wait;
struct binder_stats stats;
};- struct binder_proc *proc;表示该线程所从属的进程
- struct rb_node rb_node;以此为节点,将该线程插入到红黑树中,这样就便于从应用空间进入到内核空间,根据当前线程的pid号就可以在这棵红黑树上,快速找到这个线程对应的bind_thread结构体。当然线程在应用空间被创建后,第一次进入到内核空间通过binder_get_thread函数来获取这个bind_thread结构体时,这时这个线程对应的bind_thread结构体还是空的,所以需要动态的为这个线程创建并初始化这个bind_thread结构体,并将它插入到这棵红黑树中
- int pid;对应线程的pid
- int looper;标记当前线程的状态,有如下可能的值:
enum {
BINDER_LOOPER_STATE_REGISTERED = 0x01, //表示线程已经创建,马上可以开始接收请求了。
BINDER_LOOPER_STATE_ENTERED = 0x02, //表示线程已经进入主循环,可以接收来自远端的请求了
BINDER_LOOPER_STATE_EXITED = 0x04, //表示线程已经已经推出循环,不再可以接受请求了
BINDER_LOOPER_STATE_INVALID = 0x08, //表示线程状态又冲突,出现问题
BINDER_LOOPER_STATE_WAITING = 0x10, //表示线程已经空闲,正在等待队列上等待远端的请求
BINDER_LOOPER_STATE_NEED_RETURN = 0x20 //表示此次让该线程能够返回到用户空间,而不是阻塞在等待队列上
};
-
struct binder_transaction *transaction_stack;//表示一个binder的传输事物,详见数据结构篇2
-
wait_queue_head_t wait;线程的等待队列,这些线程有可能是service端线程池中的空闲线程,也可能是client端正在等待请求回复的请求线程
3:binder驱动中的共享内存表示(struct binder_buffer)
参与binder通讯的进程,无论是客服端还是服务器端,都会有自己的binder内存,这些内存在内核空间被分配,通过在内核和用户空间分别建立相应的映射,从而实现内核和应用空间共享同一块内存。
而这些binder内存是依赖于进程的,所以作为binder_proc的成员,并且他们有自己的内存分配(binder_alloc_buf)和内存释放(binder_free_buf)的内存管理办法(具体见binder内存管理篇),内存的组织结构如下图:
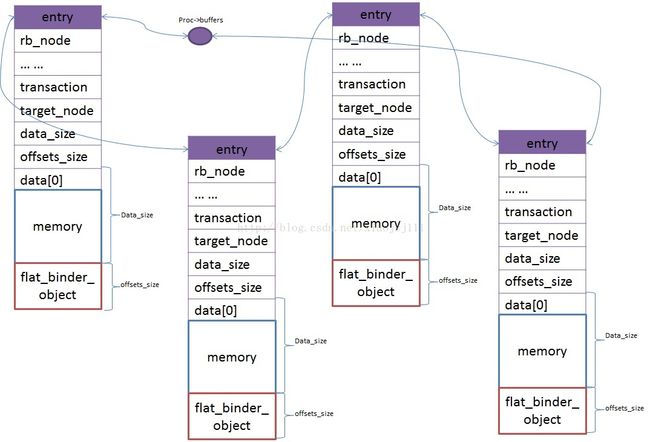
如上图,binder中的内存都是分块的,每块内存块的开始40个字节是用来存储binder_buffer结构体的,该结构体就是用来描述这块内存,然后每个内存通过struct list_head entry节点连接起来,顺着这个列表,这些内存块都是首尾相连,虚拟地址连续的。binder_buffer结构体成员如下:
struct binder_buffer {
struct list_head entry; /* free and allocated entries by address */
struct rb_node rb_node; /* free entry by size or allocated entry */
/* by address */
unsigned free:1;
unsigned allow_user_free:1;
unsigned async_transaction:1;
unsigned debug_id:29;
struct binder_transaction *transaction;
struct binder_node *target_node;
size_t data_size;
size_t offsets_size;
uint8_t data[0];
};
- struct list_head entry;结合注释和前面画的那个内存管理图,我们可以知道,根据地址的毗邻关系,这个节点用来连接所有的内存块(包括空闲内存块和已分配的内存块),由于顺着这个列表,他们是首尾相连的,所以可通过这个列表来知道每块内存的大小,分两种情况:
- 如果这个内存块不是列表的最后一块,则size = list_entry(buffer->entry.next,
struct binder_buffer, entry) - (size_t)buffer->data - 如果这个内存块是列表的最后一块,则size=proc->buffer + proc->buffer_size - (void *)buffer->data
- 如果这个内存块不是列表的最后一块,则size = list_entry(buffer->entry.next,
注意在这个列表上的物理块都是已经建立了映射,有实际物理内存的,而针对最后一块的大小,这里的处理有点特殊,就是最后一块内存的大小不但包括了自己本身已经分配的物理内存,还包括那些尚未建立映射的内存段,直至binder内存的末尾(即proc->buffer + proc->buffer_size对应的地址)
-
struct rb_node rb_node;通过这个节点,来将该块buffer添加到以allocated_buffers或free_buffers为根的红黑树上。如果是allocated_buffers树,则是以地址为index,如果是free_buffers树,则是以buffer的size为index。
- unsigned free:1;表示该内存是否空闲或已经被分配
- unsigned allow_user_free:1;指示该binder buffer是否已经可以释放,在BC_TRANSACTION被发送到内核时,会通过kzalloc分配生成一个binder_transaction t结构体,然后该结构会对应一个binder buffer,并通过binder_alloc_buf函数来分配这段buffer的空间,初始化完这个binder_transaction t结构体后,会将它挂在target proc或target thread的todo列表上,并且唤醒等待在target proc或target thread的wait队列上的线程,然后被唤醒起来的线程着手处理他自己的todo列表(thread->todo or proc->todo)上这个binder_transaction t结构体,用这个binder_transaction t结构体来初始化struct binder_transaction_data tr结构体,并将这个struct binder_transaction_data tr结构体作为BR_TRANSACTION命令的数据一起返回到服务器进程的应用空间,至此这个binder_transaction t结构体已经被利用完,可以将allow_user_free成员标志为1,表示可以被释放,这个时候,binder_transaction t结构体中的binder buffer会在服务器发送BC_FREE_BUFFER命令给内核时,通过调用binder_free_buf函数,将这个binder_transaction t结构体中的binder buffer成员释放掉。
- struct binder_transaction *transaction; BC_TRANSACTION/BC_REPLY 与 BR_TRANSACTION/BR_REPLY命令他们的参数都是struct binder_transaction_data tr结构体,而内核中数据流都是通过binder_transaction t结构体来表示的,所以驱动中,存在binder_transaction_data与binder_transaction结构相互转换的过程。当BC_xx命令时,会以命令+数据的方式将binder_transaction_data tr结构体作为参数传递到内核,驱动中将该命令对应的参数binder_transaction_data tr中的信息转换到binder_transaction t结构中;而在BR_xx 消息时,会将内核的中的binder_transaction t结构中的信息转换成binder_transaction_data tr结构体中的信息和BR_xx消息一起以(消息ID+数据)的形式返回到用户空间。
- struct binder_node *target_node;表示该bind buffer所要去往的target proc或thread所对应的binder实体
- size_t data_size;表示该buffer块的大小
- size_t offsets_size;表示offsets数组的大小
- uint8_t data[0];表示该binder buffer块实际可以存储数据的开始地址
binder驱动中,对每个进程的mmap内存区域中的每块内存都使用struct binder_buffer结构体来描述,每个内存块的开始40个字节(sizeof(struct binder_buffer))即用来存储struct binder_buffer结构体,而这个结构体则用来描述他所管理的这块内存。系统对binder内存的管理,即就是对struct binder_buffer结构体的管理和操作。
4:参考文献
http://blog.csdn.net/universus/article/details/6211589#t7
kernel3.4.5/drivers/staging/android/binder.c