ElasticSearch知识点记录
ElasticSearch
- 一 ElasticSearch
- 1.1 全文检索,倒排索引
- 1.2 Lucene
- 1.3 什么是ElasticSearch
- 1.4 Elasticsearch的功能
- 1.5 elasticsearch的适用场景
- 1.6 elasticsearch的特点
- 二 Elasticsearch的核心概念
- 2.1 Lucene和ElasticSearch的前世今生
- 2.2 elasticsearch的核心概念
- 2.3 full-text search(全文检索)
- 2.4 phrase search (短语搜索)
- 2.5 elasticsearch 聚合分析
- 2.6 ES的基础分布式结构
- 2.7 primary&replica shard
- 2.8 ES横向扩容
- 2.9 ES容错机制
- 2.10 ES _index/_type/_id 元数据介绍
- 2.11 ES id生成的两种方式
- 2.12 _source元数据
- 2.13 document的全量替换、强制创建、删除
- 2.13 ES并发冲突
- 2.14 ES内部如何基于_version进行乐观锁并发控制
- 2.15 partial update实现原理
- 2.16 mget 批量查询
- 2.17 bulk 批量增删改
- 2.18 distributed document system
- 2.19 初识搜索引擎
- search 结果深入解析
- 分页搜索与deep paging性能问题
- 快速掌握query string search
- mapping
- 精确匹配与全文搜索的对比分析
- 倒排索引
- 分词器的内部组成
- query string的分词以及mapping
- mapping
- dynamic mapping
- 手动建立mapping以及定制string类型数据是否分词
- mapping复杂数据类型以及object类型数据底层结构
- search api的基础语法
- Query DSL搜索语法
- query与filter深入对比解密:相关度、性能
- query常用搜索语法
- 多搜索条件组合查询
- 如何定位不合法的搜索及其原因
- 定制搜索结果的排序规则
- 如何将一个field索引两次来解决字符串排序问题
- 相关度评分TF&IDF算法
- 内核级知识点之doc _value
- 内核级知识点之query phase
- 内核级知识点之fetch phase
- 搜索相关参数梳理以及bouncing results问题解决方案
- scoll技术滚动搜索大量数据
- 2.20 索引管理
- 创建、修改以及删除索引
- 修改分词器以及定制自己的分词器
- type底层数据结构
- mapping root object
- 定制化dynamic mapping策略
- 基于scoll+bulk+索引别名实现零停机重建索引
- 2.21 内核原理
- 倒排索引
- document写入原理
- 优化写入流程实现NRT近实时
- 优化写入流程实现durability可靠存储
- 最后优化写入流程实现海量磁盘文件合并
- Elasticsearch顶尖高手系列-快速入门篇原视频
一 ElasticSearch
1.1 全文检索,倒排索引
倒排索引:给每一个数据都设定一个id,倒排索引看起来类似下图,是将每一个词条都拆开来,将所有的拆出来的词全部排列,建立倒排索引,搜索的时候也会将搜索词进行拆分,然后将拆分后的词放入倒排索引进行查询
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。

利用倒排索引进行全文索引,假设100万条数据,拆分出来的词语,假设有100万个词语,那么在倒排索引中,就有1000万行,优化搜索算法,有可能快速的查询到想要查询的词 。
1.2 Lucene
就是一个jar包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法。一般就用Java开发时,引用Lucene jar,基于Lucene的api进行开发就可以了。我们就可以去将已有的数据建立索引,Lucene会在本地磁盘上面,给我们组织索引的数据结构。另外的话,我们也可以用Lucene提供的一些功能和api来针对磁盘上的索引数据,进行搜索。
1.3 什么是ElasticSearch
Lucene封装了搜索引擎的功能
ElasticSearch 底层会封装Lucene,elasticSearch是多个节点
es的特点和优点:
1.自动维护数据的冗余副本,保证数据不丢失,由于宕机
2.封装了Lucene,提升高级api,能快速开发复杂的功能
3.基于地理位置的搜索,搜索距离我当前一公里的烤肉店
4.自动维护数据的分布到多个节点的索引的建立,还有搜索请求分布到多个节点的执行
Elasticsearch 分布式,高可用,可伸缩,高性能
1.4 Elasticsearch的功能
1)分布式的搜索引擎和数据分析引擎
搜索:百度,网站的站内搜索,IT系统的检索
数据分析:电商网站,最近七天牙膏这种商品销量排名前十的商家有哪些
分布式,搜索,数据分析
2)全文检索,结构化检索,数据分析
全文检索:我想搜索商品名称包含牙膏的商品 like
结构化搜索:我想搜索商品分类为日化用品的商品有哪些 =
部分匹配,自动完成,搜索纠错,搜索推荐
数据分析:我想分析每一个商品分类下有多少个商品 group by
3)对海量数据进行近实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上存储和检索
海量数据的处理:分布式以后,就可以采用大量的服务器和检索数据,自然而然就可以实现海量数据的处理了
近实时:在秒级别对数据进行搜索和分析
跟分布式/海量数据相反的:lucene,单机应用,只能在单台机器上使用,最多只能处理单台服务器的数据量
1.5 elasticsearch的适用场景
维基百科
国外新闻网站,类似搜狐新闻
Stack Overflow
GitHub
电商网站
日志数据分析,Logstash采集日志,es进行复杂的数据分析
商品价格监控网站,用户设定某商品的价格阈值的时候,发送通知消息给用户
BI系统,ES执行数据分析和挖掘,Kibana进行数据可视化
1.6 elasticsearch的特点
- 可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据
- Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并成了独一无二的ES
- 对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分支部署一下es,就可以作为生产环境的系统来使用,数据量不大,操作不是太复杂
- 数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型操作);特殊的功能,比如,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个补充,提供了数据库所不能提供的很多功能
二 Elasticsearch的核心概念
2.1 Lucene和ElasticSearch的前世今生
Lucene:最先进、功能最强大的搜索库,直接基于Lucene开发,非常复杂,api复杂,需要深入理解原理
elasticsearch,基于Lucene,隐藏复杂性,提供简单易用的restful api接口、java api接口(还有其他语言的api接口)
- 分布式文档存储引擎
- 分布式的搜索引擎和分析引擎
- 分布式,支持PB级数据
开箱即用,优秀的默认参数,不需要任何额外设置,完全开源
2.2 elasticsearch的核心概念
Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个延迟(大概1秒);基于es执行搜索和分析可以达到秒级
cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
Node:节点,集群中的一个节点,节点也有一个名称(默认随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
Document:文档,es中最小数据单元,一个document可以是一条客户数据,通常用JSON数据结构表示,每个Index下的type中,都可以存储多个document,一个document里面有多个field,每个field就是一个数据字段
Index:索引,包含一堆有相似的文档数据,比如可以有一个客户索引,商品分类索引,订单索引。
Type:类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field。
shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
replica:任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
2.3 full-text search(全文检索)
get /ecommerce/product/_search
{
"query": {
"match": {
"producer": "yagao producer"
}
}
}
producer 这个字段,会先被拆解,建立倒排索引
special 4
yago 4
producer 1,2,3,4
gaolujie 1
zhonghua 3
jiajieshi 2
2.4 phrase search (短语搜索)
match_phrase
跟全文检索相对应,相反,全文检索会将输入的搜索串拆解开来,去倒排索引里面去一一匹配,只要能匹配上任意一个拆解后的单词,就可以作为结果返回
phrase search 要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回
2.5 elasticsearch 聚合分析
聚合分析的需求:先分组,再算每组的平均值,计算每个tag下的商品的平均价格
GET /ecommerce/product/_search
{
"size": 0,
"aggs" : {
"group_by_tags" : {
"terms" : { "field" : "tags" },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
数据分析需求:计算每个tag下的商品的平均价格,并且按照平均价格降序排序
GET /ecommerce/product/_search
{
"size": 0,
"aggs" : {
"all_tags" : {
"terms" : { "field" : "tags", "order": { "avg_price": "desc" } },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
数据分析需求:按照指定的价格范围区间进行分组,然后在每组内再按照tag进行分组,最后再计算每组的平均价格
GET /ecommerce/product/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 20
},
{
"from": 20,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_tags": {
"terms": {
"field": "tags"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
2.6 ES的基础分布式结构

1.ElasticSearch对复杂分布式机制的透明隐藏特性
2.ElasticSearch的垂直扩容与水平扩容
3.增减或减少节点的数据rebalance
4.master节点
5.节点对等的分布式架构
2.7 primary&replica shard
1)index包含多个shard
2)每个shard都是一个最小工作单元,承载部分数据,Lucene实例,完整的建立索引和处理请求的能力
3)增减节点时,shard 会自动在nodes中负载均衡
4)primary shard和replica shard,每个document肯定只存在某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
8)primary shard不能和自己的replica shard放在同一个节点上,但是可以和其他primary shard的replica shard放在同一个节点上
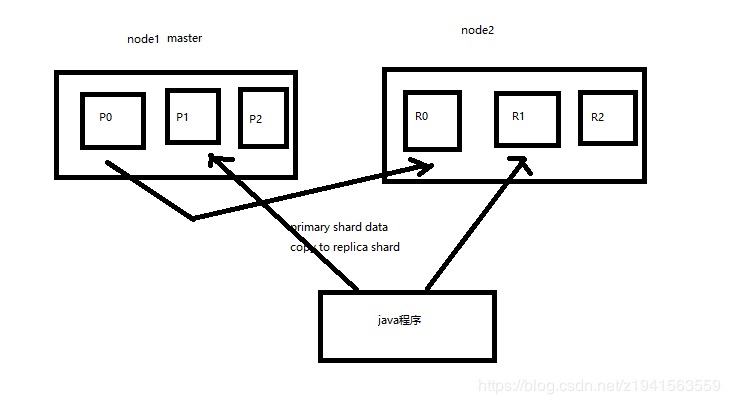
2.8 ES横向扩容
图解横向扩容过程,如何超出扩容极限,以及如何提升容错性
1)primary&replica自动负载均衡,6个shard,3 primary,3 replica
2)每个node有更少的shard,IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好
3)扩容的极限,6个shard(3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好
4)超出扩容极限,动态修改replica数量,9个shard(3 primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量
5)3台机器下,9个shard(3 primary ,6 replica),资源更少,但是容错性更好,做多容纳2台机器宕机,6个shard只能容纳1台机器宕机
6)这里的这些知识点,你综合起来看,就是说,一方面告诉你扩容的原理,怎么扩容,怎么提升系统整体吞吐量:另一方面要考虑到系统的容错性,怎么保证提高容错性,让尽可能多的服务器宕机,保证数据不丢失

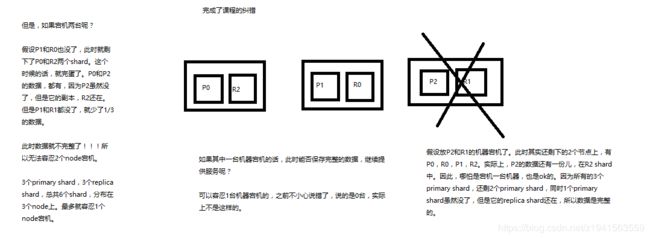
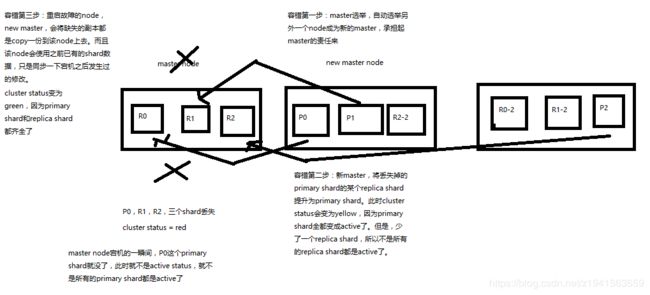
2.9 ES容错机制
ElasticSearch容错机制:master选举,replica容错,数据恢复
1)9 shard, 3 node
2)master node宕机,自动master选举,red
3)replica容错:新master将replica提升为primary shard,yellow
4)重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,green
2.10 ES _index/_type/_id 元数据介绍
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"test_content": "test test"
}
}
1、_index元数据
(1)代表一个document存放在哪个index中
(2)类似的数据放在一个索引,非类似的数据放不同索引:product index(包含了所有的商品),sales index(包含了所有的商品销售数据),inventory index(包含了所有库存相关的数据)。如果你把比如product,sales,human resource(employee),全都放在一个大的index里面,比如说company index,不合适的。
(3)index中包含了很多类似的document:类似是什么意思,其实指的就是说,这些document的fields很大一部分是相同的,你说你放了3个document,每个document的fields都完全不一样,这就不是类似了,就不太适合放到一个index里面去了。
(4)索引名称必须是小写的,不能用下划线开头,不能包含逗号:product,website,blog
2、_type元数据
(1)代表document属于index中的哪个类别(type)
(2)一个索引通常会划分为多个type,逻辑上对index中有些许不同的几类数据进行分类:因为一批相同的数据,可能有很多相同的fields,但是还是可能会有一些轻微的不同,可能会有少数fields是不一样的,举个例子,就比如说,商品,可能划分为电子商品,生鲜商品,日化商品,等等。
(3)type名称可以是大写或者小写,但是同时不能用下划线开头,不能包含逗号
3、_id元数据
(1)代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document
(2)我们可以手动指定document的id(put /index/type/id),也可以不指定,由es自动为我们创建一个id
2.11 ES id生成的两种方式
一般来说,是从某些其他的系统中,导入一些数据到es时,会采取这种方式,就是使用系统中已有数据的唯一标识,作为es中document的id。举个例子,比如说,我们现在在开发一个电商网站,做搜索功能,或者是OA系统,做员工检索功能。这个时候,数据首先会在网站系统或者IT系统内部的数据库中,会先有一份,此时就肯定会有一个数据库的primary key(自增长,UUID,或者是业务编号)。如果将数据导入到es中,此时就比较适合采用数据在数据库中已有的primary key。
如果说,我们是在做一个系统,这个系统主要的数据存储就是es一种,也就是说,数据产生出来以后,可能就没有id,直接就放es一个存储,那么这个时候,可能就不太适合说手动指定document id的形式了,因为你也不知道id应该是什么,此时可以采取下面要讲解的让es自动生成id的方式。
1、手动指定document id
put /index/type/id
PUT /test_index/test_type/2
{
"test_content": "my test"
}
2、自动生成document id
POST /index/type
POST /test_index/test_type
{
"test_content": "my test"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "AVp4RN0bhjxldOOnBxaE",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
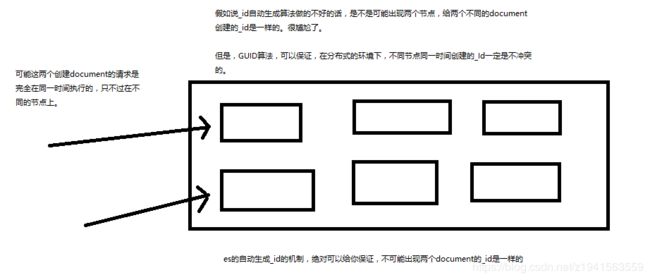
自动生成的id,长度为20个字符,URL安全,base64编码,GUID,分布式系统并行生成时不可能会发生冲突
GUID算法不冲突解释:
2.12 _source元数据
1、_source元数据
put /test_index/test_type/1
{
"test_field1": "test field1",
"test_field2": "test field2"
}
get /test_index/test_type/1
result:
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field1": "test field1",
"test_field2": "test field2"
}
}
_source元数据:就是说,我们在创建一个document的时候,使用的那个放在request body中的json串,默认情况下,在get的时候,会原封不动的给我们返回回来。
2、定制返回结果
定制返回的结果,指定_source中,返回哪些field
GET /test_index/test_type/1?_source=test_field1,test_field2
result:
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field2": "test field2"
}
}
2.13 document的全量替换、强制创建、删除
1、document的全量替换
(1)语法与创建文档是一样的,如果document id不存在,那么就是创建;如果document id已经存在,那么就是全量替换操作,替换document的json串内容
(2)document是不可变的,如果要修改document的内容,第一种方式就是全量替换,直接对document重新建立索引,替换里面所有的内容
(3)es会将老的document标记为deleted,然后新增我们给定的一个document,当我们创建越来越多的document的时候,es会在适当的时机在后台自动删除标记为deleted的document
2、document的强制创建
(1)创建文档与全量替换的语法是一样的,有时我们只是想新建文档,不想替换文档,如果强制进行创建呢?
(2)PUT /index/type/id?op_type=create,PUT /index/type/id/_create
3、document的删除
(1)DELETE /index/type/id
(2)不会理解物理删除,只会将其标记为deleted,当数据越来越多的时候,在后台自动删除
2.13 ES并发冲突
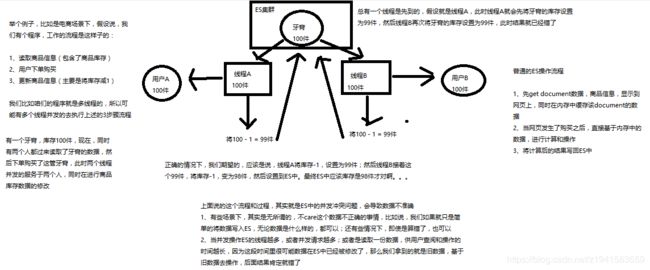
2.14 ES内部如何基于_version进行乐观锁并发控制
悲观锁与乐观锁两种并发控制方案

mysql 采用悲观锁技术
ES 采用乐观锁技术,乐观锁引入 version
悲观锁与乐观锁
1.悲观锁的优点是:方便,直接加锁,对应用程序来说,透明,不需要做额外的操作;缺点,并发能力很低,同一时间只能有一条线程操作数据
2.乐观锁的优点是:并发能力很高,不给数据加锁,大量线程并发操作;缺点,麻烦,每次更新的时候,都要先对比版本号,然后可能需要重新加载数据,再次修改,再写;这个过程可能要重复好几次。
_version
每一次创建一个document的时候,它的_version内部版本号就是1;以后,每次对这个document执行修改或者删除操作,都会对这个_version版本号自动加1;哪怕是删除,也会对这条数据的版本号加1
PUT /test_index/test_type/6
{
"test_field": "test test"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
{
"found": true,
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_version": 4,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
我们会发现,在删除一个document之后,可以从侧面证明,它不是立即物理删除的,因为它的一些版本号信息还是保留着的。先删除一条document,再重新创建这条document,其实会在delete version基础之上,再把version号加1。
es 中的数据的版本号,跟客户端中的数据的版本号是相同才能修改
基于最新的数据和版本号,去进行修改,修改后,带上最新的版本号,可能这个步骤会需要反复执行好几次,才能成功,特别是在多线程并发更新同一条数据很频繁的情况下
external version
es 提供了一个feature,就是说,你可以不用它提供的内部_version 版本号来进行并发控制,可以基于你自己维护的一个版本号来进行并发控制。举个例子,加入你的数据在mysql里也有一份,然后你的应用系统本身就维护了一个版本号,无论是自己生成的,程序控制的。这个时候,你进行乐观锁并发控制的时候,可能并不是想要的es 内部的_version 来进行控制,而是用你自己维护的那个version 来进行控制。
?version=1
?version=1&version_type=external
version_type=external,唯一的区别在于,_version,只有当你提供的version 与 es 中的_version一模一样的时候,才可以进行修改,只要不一样,就报错;当version_type=external的时候,只有当你提供的version比es中的_version大的时候,才能完成修改
es,_version=1,?version=1,才能更新成功
es,_version=1,?version>1&version_type=external,才能成功,比如说?version=2&version_type=external
2.15 partial update实现原理
1. 什么是 partial update?
PUT /index/type/id,创建文档&替换文档,就是一样的语法
一般对应到应用程序中,每次的执行流程基本是这样的:
(1)应用程序先发起一个get请求,获取到document,展示到前台界面,供用户查看和修改
(2)用户在前台界面修改数据,发送到后台
(3)后台代码,会将用户修改的数据在内存中进行执行,然后封装好修改后的全量数据
(4)然后发送PUT请求,到es中,进行全量替换
(5)es将老的document标记为deleted,然后重新创建一个新的document
partial update
post /index/type/id/_update
{
"doc": {
"要修改的少数几个field即可,不需要全量的数据"
}
}
看起来,好像就比较方便了,每次就传递少数几个发生修改的field即可,不需要将全量的document数据发送过去
PUT /test_index/test_type/10
{
"test_field1": "test1",
"test_field2": "test2"
}
POST /test_index/test_type/10/_update
{
"doc": {
"test_field2": "updated test2"
}
}
partial update 相较于全量替换的优点
1.所有的查询、修改和写回操作,都发生在es中的一个shard 内部,避免了所有的网络数据传输的开销(减少2次网络请求),大大提升了性能(全量替换的查询、修改是发生在java或别的程序中的)
2.减少了查询和修改中的时间间隔,可以有效减少并发冲突的情况
groovy 脚本进行 partial update
es,有个内置脚本支持,可以基于groovy实现各种各样复杂操作
(1)内置脚本
POST /test_index/test_type/11/_update
{
"script" : "ctx._source.num+=1"
}
result:
{
"_index": "test_index",
"_type": "test_type",
"_id": "11",
"_version": 2,
"found": true,
"_source": {
"num": 1,
"tags": []
}
}
(2)外部脚本
脚本文件test-add-tags.groovy
ctx._source.tags+=new_tag
“file”: “test-add-tags”
POST /test_index/test_type/11/_update
{
"script": {
"lang": "groovy",
"file": "test-add-tags",
"params": {
"new_tag": "tag1"
}
}
}
(3)用脚本删除文档
脚本文件:test-delete-document.groovy
ctx.op = ctx._source.num == count ? ‘delete’ : ‘none’
POST /test_index/test_type/11/_update
{
"script": {
"lang": "groovy",
"file": "test-delete-document",
"params": {
"count": 1
}
}
}
(4)upsert操作
POST /test_index/test_type/11/_update
{
"doc": {
"num": 1
}
}
{
"error": {
"root_cause": [
{
"type": "document_missing_exception",
"reason": "[test_type][11]: document missing",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "4",
"index": "test_index"
}
],
"type": "document_missing_exception",
"reason": "[test_type][11]: document missing",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "4",
"index": "test_index"
},
"status": 404
}
如果指定的document不存在,就执行upsert中的初始化操作;如果指定的document存在,就执行doc或者script指定的partial update操作
POST /test_index/test_type/11/_update
{
"script" : "ctx._source.num+=1",
"upsert": {
"num": 0,
"tags": []
}
}
partial update 内置乐观锁并发控制
partial update 内置乐观锁并发控制
retry_on_conflict
_version
post /index/type/id/_update?retry_on_conflict=5&version=6
2.16 mget 批量查询
1、批量查询的好处
就是一条一条的查询,比如说要查询100条数据,那么就要发送100次网络请求,这个开销还是很大的
如果进行批量查询的话,查询100条数据,就只要发送1次网络请求,网络请求的性能开销缩减100倍
2、mget的语法
(1)一条一条的查询
GET /test_index/test_type/1
GET /test_index/test_type/2
(2)mget批量查询
GET /_mget
{
"docs" : [
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 1
},
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 2
}
]
}
result:
{
"docs": [
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field1": "test field1",
"test_field2": "test field2"
}
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "2",
"_version": 1,
"found": true,
"_source": {
"test_content": "my test"
}
}
]
}
(3)如果查询的document是一个index下的不同type种的话
GET /test_index/_mget
{
"docs" : [
{
"_type" : "test_type",
"_id" : 1
},
{
"_type" : "test_type",
"_id" : 2
}
]
}
(4)如果查询的数据都在同一个index下的同一个type下,最简单了
GET /test_index/test_type/_mget
{
"ids": [1, 2]
}
3、mget的重要性
可以说mget是很重要的,一般来说,在进行查询的时候,如果一次性要查询多条数据的话,那么一定要用batch批量操作的api
尽可能减少网络开销次数,可能可以将性能提升数倍,甚至数十倍,非常非常之重要
2.17 bulk 批量增删改
1、bulk语法
POST /_bulk
{ "delete": { "_index": "test_index", "_type": "test_type", "_id": "3" }}
{ "create": { "_index": "test_index", "_type": "test_type", "_id": "12" }}
{ "test_field": "test12" }
{ "index": { "_index": "test_index", "_type": "test_type", "_id": "2" }}
{ "test_field": "replaced test2" }
{ "update": { "_index": "test_index", "_type": "test_type", "_id": "1", "_retry_on_conflict" : 3} }
{ "doc" : {"test_field2" : "bulk test1"} }
每一个操作要两个json串,语法如下:
{"action": {"metadata"}}
{"data"}
举例,比如你现在要创建一个文档,放bulk里面,看起来会是这样子的:
{"index": {"_index": "test_index", "_type", "test_type", "_id": "1"}}
{"test_field1": "test1", "test_field2": "test2"}
有哪些类型的操作可以执行呢?
(1)delete:删除一个文档,只要1个json串就可以了
(2)create:PUT /index/type/id/_create,强制创建
(3)index:普通的put操作,可以是创建文档,也可以是全量替换文档
(4)update:执行的partial update操作
bulk api对json的语法,有严格的要求,每个json串不能换行,只能放一行,同时一个json串和一个json串之间,必须有一个换行
{
"took": 41,
"errors": true,
"items": [
{
"delete": {
"found": true,
"_index": "test_index",
"_type": "test_type",
"_id": "10",
"_version": 3,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 200
}
},
{
"create": {
"_index": "test_index",
"_type": "test_type",
"_id": "3",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
},
{
"create": {
"_index": "test_index",
"_type": "test_type",
"_id": "2",
"status": 409,
"error": {
"type": "version_conflict_engine_exception",
"reason": "[test_type][2]: version conflict, document already exists (current version [1])",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "2",
"index": "test_index"
}
}
},
{
"index": {
"_index": "test_index",
"_type": "test_type",
"_id": "4",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
},
{
"index": {
"_index": "test_index",
"_type": "test_type",
"_id": "2",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false,
"status": 200
}
},
{
"update": {
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 200
}
}
]
}
bulk操作中,任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志
POST /test_index/_bulk
{ "delete": { "_type": "test_type", "_id": "3" }}
{ "create": { "_type": "test_type", "_id": "12" }}
{ "test_field": "test12" }
{ "index": { "_type": "test_type" }}
{ "test_field": "auto-generate id test" }
{ "index": { "_type": "test_type", "_id": "2" }}
{ "test_field": "replaced test2" }
{ "update": { "_type": "test_type", "_id": "1", "_retry_on_conflict" : 3} }
{ "doc" : {"test_field2" : "bulk test1"} }
POST /test_index/test_type/_bulk
{ "delete": { "_id": "3" }}
{ "create": { "_id": "12" }}
{ "test_field": "test12" }
{ "index": { }}
{ "test_field": "auto-generate id test" }
{ "index": { "_id": "2" }}
{ "test_field": "replaced test2" }
{ "update": { "_id": "1", "_retry_on_conflict" : 3} }
{ "doc" : {"test_field2" : "bulk test1"} }
2、bulk size最佳大小
bulk request会加载到内存里,如果太大的话,性能反而会下降,因此需要反复尝试一个最佳的bulk size。一般从1000~ 5000条数据开始,尝试逐渐增加。另外,如果看大小的话,最好是在5~15MB之间。
2.18 distributed document system
distributed document store
ElasticSearch在跑起来以后,其实起到的第一个最核心的功能,就是一个分布式的文档数据存储系统。ES是分布式的。文档数据存储系统。文档数据,存储系统。
文档数据:es可以存储和操作json文档类型的数据,而且这也是es的核心数据结构
存储系统:es可以对json文档类型的数据进行存储,查询,创建,更新,删除,等等操作。其实已经起到了一个什么样的效果呢?其实ES满足了这些功能,就可以说已经是一个NoSQL的存储系统了。
围绕着document在操作,其实就是把es当成了一个NoSQL存储引擎,一个可以存储文档类型数据的系统,再操作里面的document。
es可以作为一个分布式的文档存储系统,所以说,我们的应用系统,是不是就可以基于这个概念,去进行相关的应用程序的开发了。
什么类型的应用程序呢?
(1)数据量较大,es的分布式本质,可以帮助你快速进行扩容,承载大量数据
(2)数据结构灵活多变,随时可能会变化,数据结构之间的关系非常复杂
(3)对数据的相关操作比较简单
(4)NoSQL数据库,适用的也是类似上面的这种场景
举个例子,比如说像一些网站系统,或者是普通的电商系统,博客系统,面向对象概念比较复杂,但是作为终端网站来说,没什么太复杂的功能,就是一些简单的CRUD操作,而且数据量可能还比较大。这个时候选用ES这种NoSQL型的数据存储,比传统的复杂的功能务必强大的支持SQL的关系型数据库,更加合适一些。无论是性能,还是吞吐量,可能都会更好。
document数据路由原理
我们知道,一个index的数据会被分为多片,每片都在一个shard中。所以说,一个document,只能存在于一个shard中。当客户端创建document的时候,es此时就需要决定说,这个document是放在这个index的哪个shard上。这个过程就称之为document routing,数据路由。
(1)document路由到shard上是什么意思?
(2)路由算法:shard = hash(routing) % number_of_primary_shards
举个例子,一个index有3个primary shard,P0,P1,P2
每次增删改查一个document的时候,都会带过来一个routing number,默认就是这个document的_id(可能是手动指定,也可能是自动生成)
routing = _id,假设_id=1
会将这个routing值,传入一个hash函数中,产出一个rout ing值的hash值,hash(routing) = 21
然后将hash函数产出的值对这个index的primary shard的数量求余数,21 % 3 = 0
就决定了,这个document就放在P0上。
决定一个document在哪个shard上,最重要的一个值就是routing值,默认是_id,也可以手动指定,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的
无论hash值是几,无论是什么数字,对number_of_primary_shards求余数,结果一定是在0~number_of_primary_shards-1之间这个范围内的。0,1,2。
(3)_id or custom routing value
默认的routing就是_id
也可以在发送请求的时候,手动指定一个routing value,比如说put /index/type/id?routing=user_id
手动指定routing value是很有用的,可以保证说,某一类document一定被路由到一个shard上去,那么在后续进行应用级别的负载均衡,以及提升批量读取的性能的时候,是很有帮助的
(4)primary shard数量不可变的谜底
document增删改内部原理
(1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
(2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
(3)实际的node上的primary shard处理请求,然后将数据同步到replica node
(4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
写一致性原理以及quorum机制
(1)consistency,one(primary shard),all(all shard),quorum(default)
我们在发送任何一个增删改操作的时候,比如说put /index/type/id,都可以带上一个consistency参数,指明我们想要的写一致性是什么?
put /index/type/id?consistency=quorum
one:要求我们这个写操作,只要有一个primary shard是active活跃可用的,就可以执行
all:要求我们这个写操作,必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作
quorum:默认的值,要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
(2)quorum机制,写之前必须确保大多数shard都可用,int( (primary + number_of_replicas) / 2 ) + 1,当number_of_replicas>1时才生效
quroum = int( (primary + number_of_replicas) / 2 ) + 1
举个例子,3个primary shard,number_of_replicas=1,总共有3 + 3 * 1 = 6个shard
quorum = int( (3 + 1) / 2 ) + 1 = 3
所以,要求6个shard中至少有3个shard是active状态的,才可以执行这个写操作
(3)如果节点数少于quorum数量,可能导致quorum不齐全,进而导致无法执行任何写操作
3个primary shard,replica=1,要求至少3个shard是active,3个shard按照之前学习的shard&replica机制,必须在不同的节点上,如果说只有2台机器的话,是不是有可能出现说,3个shard都没法分配齐全,此时就可能会出现写操作无法执行的情况
es提供了一种特殊的处理场景,就是说当number_of_replicas>1时才生效,因为假如说,你就一个primary shard,replica=1,此时就2个shard
(1 + 1 / 2) + 1 = 2,要求必须有2个shard是活跃的,但是可能就1个node,此时就1个shard是活跃的,如果你不特殊处理的话,导致我们的单节点集群就无法工作
(4)quorum不齐全时,wait,默认1分钟,timeout,100,30s
等待期间,期望活跃的shard数量可以增加,最后实在不行,就会timeout
我们其实可以在写操作的时候,加一个timeout参数,比如说put /index/type/id?timeout=30,这个就是说自己去设定quorum不齐全的时候,es的timeout时长,可以缩短,也可以增长
document 读请求内部原理
1、客户端发送请求到任意一个node,成为coordinate node
2、coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
3、接收请求的node返回document给coordinate node
4、coordinate node返回document给客户端
5、特殊情况:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了
bulk api 的奇特json格式与底层性能优化关系大揭秘
// bulk api奇特的json格式
{“action”: {“meta”}}\n
{“data”}\n
{“action”: {“meta”}}\n
{“data”}\n
为什么不能使用下面这种方式或其他方式:
[{
“action”: {
},
“data”: {
}
}]
1、bulk中的每个操作都可能要转发到不同的node的shard去执行
2、如果采用比较良好的json数组格式
允许任意的换行,整个可读性非常棒,读起来很爽,es拿到那种标准格式的json串以后,要按照下述流程去进行处理
(1)将json数组解析为JSONArray对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是JSONArray对象
(2)解析json数组里的每个json,对每个请求中的document进行路由
(3)为路由到同一个shard上的多个请求,创建一个请求数组
(4)将这个请求数组序列化
(5)将序列化后的请求数组发送到对应的节点上去
3、耗费更多内存,更多的jvm gc开销
我们之前提到过bulk size最佳大小的那个问题,一般建议说在几千条那样,然后大小在10MB左右,所以说,可怕的事情来了。假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB = 1GB,然后每个请求的json都copy一份为jsonarray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成jsonarray之后,还可能会多搞一些其他的数据结构,2GB+的内存占用。
占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降
另外的话,占用内存更多,就会导致java虚拟机的垃圾回收次数更多,更频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致es的java虚拟机停止工作线程的时间更多
4、现在的奇特格式
{“action”: {“meta”}}\n
{“data”}\n
{“action”: {“meta”}}\n
{“data”}\n
(1)不用将其转换为json对象,不会出现内存中的相同数据的拷贝,直接按照换行符切割json
(2)对每两个一组的json,读取meta,进行document路由
(3)直接将对应的json发送到node上去
5、最大的优势在于,不需要将json数组解析为一个JSONArray对象,形成一份大数据的拷贝,浪费内存空间,尽可能地保证性能
2.19 初识搜索引擎
search 结果深入解析
GET /_search
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 6,
"successful": 6,
"failed": 0
},
"hits": {
"total": 10,
"max_score": 1,
"hits": [
{
"_index": ".kibana",
"_type": "config",
"_id": "5.2.0",
"_score": 1,
"_source": {
"buildNum": 14695
}
}
]
}
}
took:整个搜索请求花费了多少毫秒
hits.total:本次搜索,返回了几条结果
hits.max_score:本次搜索的所有结果中,最大的相关度分数是多少,每一条document对于search的相关度,越相关,_score分数越大,排位越靠前
hits.hits:默认查询前10条数据,完整数据,_score降序排序
shards:shards fail的条件(primary和replica全部挂掉),不影响其他shard。默认情况下来说,一个搜索请求,会打到一个index的所有primary shard上去,当然了,每个primary shard都可能会有一个或多个replic shard,所以请求也可以到primary shard的其中一个replica shard上去。
timeout:默认无timeout,latency平衡completeness,手动指定timeout,timeout查询执行机制
timeout=10ms,timeout=1s,timeout=1m
GET /_search?timeout=10m
timeout机制详解:

multi-index & multi-type搜索模式解析
1、multi-index和multi-type搜索模式
告诉你如何一次性搜索多个index和多个type下的数据
/_search:所有索引,所有type下的所有数据都搜索出来
/index1/_search:指定一个index,搜索其下所有type的数据
/index1,index2/_search:同时搜索两个index下的数据
/*1,*2/_search:按照通配符去匹配多个索引
/index1/type1/_search:搜索一个index下指定的type的数据
/index1/type1,type2/_search:可以搜索一个index下多个type的数据
/index1,index2/type1,type2/_search:搜索多个index下的多个type的数据
/_all/type1,type2/_search:_all,可以代表搜索所有index下的指定type的数据
2、初步图解一下简单的搜索原理
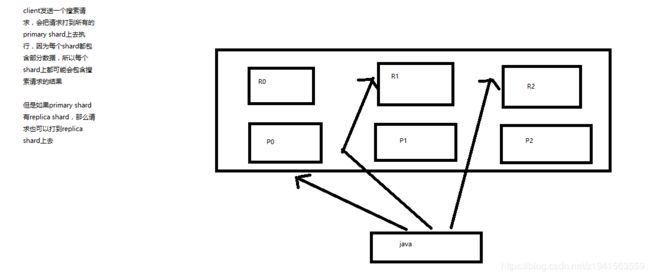
client发送一个搜索请求,会把请求打到所有的primary shard 上去执行,因为每个shard都包含部分数据,所以每个shard上都可能会包含搜索请求的结果
但是如果primary shard有replica shard,那么请求也可以打到replica shard 上去
分页搜索与deep paging性能问题
1、讲解如何使用es进行分页搜索的语法
// size,from
GET /_search?size=10
GET /_search?size=10&from=0
GET /_search?size=10&from=20
GET /test_index/test_type/_search
"hits": {
"total": 9,
"max_score": 1,
我们假设将这9条数据分成3页,每一页是3条数据,来实验一下这个分页搜索的效果
GET /test_index/test_type/_search?from=0&size=3
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 9,
"max_score": 1,
"hits": [
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_score": 1,
"_source": {
"test_field": "test client 2"
}
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_score": 1,
"_source": {
"test_field": "tes test"
}
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "4",
"_score": 1,
"_source": {
"test_field": "test4"
}
}
]
}
}
第一页:id=8,6,4
GET /test_index/test_type/_search?from=3&size=3
第二页:id=2,自动生成,7
GET /test_index/test_type/_search?from=6&size=3
第三页:id=1,11,3
2、什么是deep paging问题?为什么会产生这个问题,它的底层原理是什么?
deep paging:简单来说,就是搜索的特别深,比如总共有60000条数据,每个shard上分了20000条数据。每页是10条数据,这个时候,你要搜索到第1000页,实际上拿到的是10001~10010大家自己思考一下,是第几条到第几条?
每个shard,其实都要返回的是最后10条,不是这样理解。。。错误!!!
你的请求首先可能是打到一个不包含这个index的shard的node上去,这个node就是一个coordinator node,那么这个coordinator node就会将搜索请求转发到index的三个shard所在的node上去。

快速掌握query string search
1、query string基础语法
GET /test_index/test_type/_search?q=test_field:test
GET /test_index/test_type/_search?q=+test_field:test # + field必须要有
GET /test_index/test_type/_search?q=-test_field:test # - field不包含
一个是掌握q=field:search content的语法,还有一个是掌握+和-的含义
2、_all metadata的原理和作用
GET /test_index/test_type/_search?q=test
直接可以搜索所有的field,任意一个field包含指定的关键字就可以搜索出来。我们在进行中搜索的时候,难道是对document中的每一个field都进行一次搜索吗?不是的
es中的_all元数据,在建立索引的时候,我们插入一条document,它里面包含了多个field,此时,es会自动将多个field的值,全部用字符串的方式串联起来,变成一个长的字符串,作为_all field的值,同时建立索引
后面如果在搜索的时候,没有对某个field指定搜索,就默认搜索_all field,其中是包含了所有field的值的
举个例子
{
"name": "jack",
"age": 26,
"email": "[email protected]",
"address": "guamgzhou"
}
“jack 26 [email protected] guangzhou”,作为这一条document的_all field的值,同时进行分词后建立对应的倒排索引
生产环境不使用
mapping
插入几条数据,让es自动为我们建立一个索引
PUT /website/article/1
{
"post_date": "2017-01-01",
"title": "my first article",
"content": "this is my first article in this website",
"author_id": 11400
}
PUT /website/article/2
{
"post_date": "2017-01-02",
"title": "my second article",
"content": "this is my second article in this website",
"author_id": 11400
}
PUT /website/article/3
{
"post_date": "2017-01-03",
"title": "my third article",
"content": "this is my third article in this website",
"author_id": 11400
}
尝试各种搜索
GET /website/article/_search?q=2017 3条结果
GET /website/article/_search?q=2017-01-01 3条结果
GET /website/article/_search?q=post_date:2017-01-01 1条结果
GET /website/article/_search?q=post_date:2017 1条结果
查看es自动建立的mapping,带出什么是mapping的知识点
自动或手动为index中的type建立的一种数据结构和相关配置,简称为mapping
dynamic mapping,自动为我们建立index,创建type,以及type对应的mapping,mapping中包含了每个field对应的数据类型,以及如何分词等设置
我们当然,后面会讲解,也可以手动在创建数据之前,先创建index和type,以及type对应的mapping
GET /website/_mapping/article
{
"website": {
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "long"
},
"content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"post_date": {
"type": "date"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
搜索结果为什么不一致,因为es自动建立mapping的时候,设置了不同的field不同的data type。不同的data type的分词、搜索等行为是不一样的。所以出现了_all field和post_date field的搜索表现完全不一样。
精确匹配与全文搜索的对比分析
1、exact value
2017-01-01,exact value,搜索的时候,必须输入2017-01-01,才能搜索出来
如果你输入一个01,是搜索不出来的
2、full text
(1)缩写 vs. 全程:cn vs. china
(2)格式转化:like liked likes
(3)大小写:Tom vs tom
(4)同义词:like vs love
2017-01-01,2017 01 01,搜索2017,或者01,都可以搜索出来
china,搜索cn,也可以将china搜索出来
likes,搜索like,也可以将likes搜索出来
Tom,搜索tom,也可以将Tom搜索出来
like,搜索love,同义词,也可以将like搜索出来
就不是说单纯的只是匹配完整的一个值,而是可以对值进行拆分词语后(分词)进行匹配,也可以通过缩写、时态、大小写、同义词等进行匹配
倒排索引
doc1:I really liked my small dogs, and I think my mom also liked them.
doc2:He never liked any dogs, so I hope that my mom will not expect me to liked him.

演示了一下倒排索引最简单的建立的一个过程
搜索
mother like little dog,不可能有任何结果
mother
like
little
dog
这个是不是我们想要的搜索结果???绝对不是,因为在我们看来,mother和mom有区别吗?同义词,都是妈妈的意思。like和liked有区别吗?没有,都是喜欢的意思,只不过一个是现在时,一个是过去时。little和small有区别吗?同义词,都是小小的。dog和dogs有区别吗?狗,只不过一个是单数,一个是复数。
normalization,建立倒排索引的时候,会执行一个操作,也就是说对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率
时态的转换,单复数的转换,同义词的转换,大小写的转换
mom —> mother
liked —> like
small —> little
dogs —> dog
重新建立倒排索引,加入normalization,再次用mother liked little dog搜索,就可以搜索到了

mother like little dog,分词,normalization
mother --> mom
like --> like
little --> little
dog --> dog
doc1和doc2都会搜索出来
doc1:I really liked my small dogs, and I think my mom also liked them.
doc2:He never liked any dogs, so I hope that my mom will not expect me to liked him.
分词器的内部组成
1、什么是分词器
切分词语,normalization(提升recall召回率)
给你一段句子,然后将这段句子拆分成一个一个的单个的单词,同时对每个单词进行normalization(时态转换,单复数转换),分词器
recall,召回率:搜索的时候,增加能够搜索到的结果的数量
character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello --> hello),& --> and(I&you --> I and you)
tokenizer:分词,hello you and me --> hello, you, and, me
token filter:lowercase,stop word,synonymom,dogs --> dog,liked --> like,Tom --> tom,a/the/an --> 干掉,mother --> mom,small --> little
一个分词器,很重要,将一段文本进行各种处理,最后处理好的结果才会拿去建立倒排索引
2、内置分词器的介绍
Set the shape to semi-transparent by calling set_trans(5)
standard analyzer:set, the, shape, to, semi, transparent, by, calling, set_trans, 5(默认的是standard)
simple analyzer:set, the, shape, to, semi, transparent, by, calling, set, trans
whitespace analyzer:Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
language analyzer(特定的语言的分词器,比如说,english,英语分词器):set, shape, semi, transpar, call, set_tran, 5
query string的分词以及mapping
1、query string分词
query string必须以和index建立时相同的analyzer进行分词
query string对exact value和full text的区别对待
date:exact value
_all:full text
比如我们有一个document,其中有一个field,包含的value是:hello you and me,建立倒排索引
我们要搜索这个document对应的index,搜索文本是hell me,这个搜索文本就是query string
query string,默认情况下,es会使用它对应的field建立倒排索引时相同的分词器去进行分词,分词和normalization,只有这样,才能实现正确的搜索
我们建立倒排索引的时候,将dogs --> dog,结果你搜索的时候,还是一个dogs,那不就搜索不到了吗?所以搜索的时候,那个dogs也必须变成dog才行。才能搜索到。
知识点:不同类型的field,可能有的就是full text,有的就是exact value
post_date,date:exact value
_all:full text,分词,normalization
2、mapping引入案例遗留问题大揭秘
GET /_search?q=2017
搜索的是_all field,document所有的field都会拼接成一个大串,进行分词
2017-01-02 my second article this is my second article in this website 11400

_all,2017,自然会搜索到3个docuemnt
GET /_search?q=2017-01-01
_all,2017-01-01,query string会用跟建立倒排索引一样的分词器去进行分词
2017
01
01
GET /_search?q=post_date:2017-01-01
date,会作为exact value去建立索引

post_date:2017-01-01,2017-01-01,doc1一条document
GET /_search?q=post_date:2017,这个在这里不讲解,因为是es 5.2以后做的一个优化
3、测试分词器
GET /_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}
mapping
(1)往es里面直接插入数据,es会自动建立索引,同时建立type以及对应的mapping
(2)mapping中就自动定义了每个field的数据类型
(3)不同的数据类型(比如说text和date),可能有的是exact value,有的是full text
(4)exact value,在建立倒排索引的时候,分词的时候,是将整个值一起作为一个关键词建立到倒排索引中的;full text,会经历各种各样的处理,分词,normaliztion(时态转换,同义词转换,大小写转换),才会建立到倒排索引中
(5)同时呢,exact value和full text类型的field就决定了,在一个搜索过来的时候,对exact value field或者是full text field进行搜索的行为也是不一样的,会跟建立倒排索引的行为保持一致;比如说exact value搜索的时候,就是直接按照整个值进行匹配,full text query string,也会进行分词和normalization再去倒排索引中去搜索
(6)可以用es的dynamic mapping,让其自动建立mapping,包括自动设置数据类型;也可以提前手动创建index和type的mapping,自己对各个field进行设置,包括数据类型,包括索引行为,包括分词器,等等
mapping,就是index的type的元数据,每个type都有一个自己的mapping,决定了数据类型,建立倒排索引的行为,还有进行搜索的行为
dynamic mapping
核心的数据类型
string
byte,short,integer,long
float,double
boolean
date
dynamic mapping
true or false --> boolean
123 --> long
123.45 --> double
2017-01-01 --> date
"hello world" --> string/text
查看mapping
GET /index/_mapping/type
手动建立mapping以及定制string类型数据是否分词
如何建立索引
analyzed
not_analyzed
no
修改mapping
只能创建index时手动建立mapping,或者新增field mapping,但是不能update field mapping
PUT /website
{
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "english"
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
},
"publisher_id": {
"type": "text",
"index": "not_analyzed"
}
}
}
}
}
PUT /website
{
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "text"
}
}
}
}
}
result:
{
"error": {
"root_cause": [
{
"type": "index_already_exists_exception",
"reason": "index [website/co1dgJ-uTYGBEEOOL8GsQQ] already exists",
"index_uuid": "co1dgJ-uTYGBEEOOL8GsQQ",
"index": "website"
}
],
"type": "index_already_exists_exception",
"reason": "index [website/co1dgJ-uTYGBEEOOL8GsQQ] already exists",
"index_uuid": "co1dgJ-uTYGBEEOOL8GsQQ",
"index": "website"
},
"status": 400
}
PUT /website/_mapping/article
{
"properties" : {
"new_field" : {
"type" : "string",
"index": "not_analyzed"
}
}
}
测试mapping
GET /website/_analyze
{
"field": "content",
"text": "my-dogs"
}
GET website/_analyze
{
"field": "new_field",
"text": "my dogs"
}
result:
{
"error": {
"root_cause": [
{
"type": "remote_transport_exception",
"reason": "[4onsTYV][127.0.0.1:9300][indices:admin/analyze[s]]"
}
],
"type": "illegal_argument_exception",
"reason": "Can't process field [new_field], Analysis requests are only supported on tokenized fields"
},
"status": 400
}
mapping复杂数据类型以及object类型数据底层结构
1、multivalue field
{ "tags": [ "tag1", "tag2" ]}
建立索引时与string是一样的,数据类型不能混
2、empty field
null,[],[null]
3、object field
PUT /company/employee/1
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2017-01-01"
}
address:object类型
{
"company": {
"mappings": {
"employee": {
"properties": {
"address": {
"properties": {
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"country": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"province": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"age": {
"type": "long"
},
"join_date": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2017-01-01"
}
底层结构(行式存储转为列式存储):
{
"name": [jack],
"age": [27],
"join_date": [2017-01-01],
"address.country": [china],
"address.province": [guangdong],
"address.city": [guangzhou]
}
{
"authors": [
{ "age": 26, "name": "Jack White"},
{ "age": 55, "name": "Tom Jones"},
{ "age": 39, "name": "Kitty Smith"}
]
}
底层结构(行式存储转为列式存储):
{
"authors.age": [26, 55, 39],
"authors.name": [jack, white, tom, jones, kitty, smith]
}
search api的基础语法
1、search api的基本语法
GET /search
{}
GET /index1,index2/type1,type2/search
{}
GET /_search
{
"from": 0,
"size": 10
}
2、http协议中get是否可以带上request body
HTTP协议,一般不允许get请求带上request body,但是因为get更加适合描述查询数据的操作,因此还是这么用了
GET /_search?from=0&size=10
POST /_search
{
"from":0,
"size":10
}
碰巧,很多浏览器,或者是服务器,也都支持GET+request body模式
如果遇到不支持的场景,也可以用POST /_search
Query DSL搜索语法
1、一个例子让你明白什么是Query DSL
GET /_search
{
"query": {
"match_all": {}
}
}
2、Query DSL的基本语法
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
示例:
GET /test_index/test_type/_search
{
"query": {
"match": {
"test_field": "test"
}
}
}
3、如何组合多个搜索条件
搜索需求:title必须包含elasticsearch,content可以包含elasticsearch也可以不包含,author_id必须不为111
GET /website/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "elasticsearch"
}
}
],
"should": [
{
"match": {
"content": "elasticsearch"
}
}
],
"must_not": [
{
"match": {
"author_id": 111
}
}
]
}
}
}
GET /test_index/_search
{
"query": {
"bool": {
"must": { "match": { "name": "tom" }},
"should": [
{ "match": { "hired": true }},
{ "bool": {
"must": { "match": { "personality": "good" }},
"must_not": { "match": { "rude": true }}
}}
],
"minimum_should_match": 1
}
}
}
query与filter深入对比解密:相关度、性能
1、filter与query示例
PUT /company/employee/2
{
"address": {
"country": "china",
"province": "jiangsu",
"city": "nanjing"
},
"name": "tom",
"age": 30,
"join_date": "2016-01-01"
}
PUT /company/employee/3
{
"address": {
"country": "china",
"province": "shanxi",
"city": "xian"
},
"name": "marry",
"age": 35,
"join_date": "2015-01-01"
}
搜索请求:年龄必须大于等于30,同时join_date必须是2016-01-01
GET /company/employee/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"join_date": "2016-01-01"
}
}
],
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
}
}
2、filter与query对比大解密
filter,仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响
query,会去计算每个document相对于搜索条件的相关度,并按照相关度进行排序
一般来说,如果你是在进行搜索,需要将最匹配搜索条件的数据先返回,那么用query;如果你只是要根据一些条件筛选出一部分数据,不关注其排序,那么用filter
除非是你的这些搜索条件,你希望越符合这些搜索条件的document越排在前面返回,那么这些搜索条件要放在query中;如果你不希望一些搜索条件来影响你的document排序,那么就放在filter中即可
3、filter与query性能
filter,不需要计算相关度分数,不需要按照相关度分数进行排序,同时还有内置的自动cache最常使用filter的数据
query,相反,要计算相关度分数,按照分数进行排序,而且无法cache结果
query常用搜索语法
1、match all
GET /_search
{
"query": {
"match_all": {}
}
}
2、match
GET /_search
{
"query": { "match": { "title": "my elasticsearch article" }}
}
3、multi match
GET /test_index/test_type/_search
{
"query": {
"multi_match": {
"query": "test",
"fields": ["test_field", "test_field1"]
}
}
}
4、range query
GET /company/employee/_search
{
"query": {
"range": {
"age": {
"gte": 30
}
}
}
}
5、term query
GET /test_index/test_type/_search
{
"query": {
"term": {
"test_field": "test hello"
}
}
}
6、terms query
GET /_search
{
"query": { "terms": { "tag": [ "search", "full_text", "nosql" ] }}
}
7、exist query(2.x中的查询,现在已经不提供了)
多搜索条件组合查询
GET /website/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "elasticsearch"
}
}
],
"should": [
{
"match": {
"content": "elasticsearch"
}
}
],
"must_not": [
{
"match": {
"author_id": 111
}
}
]
}
}
}
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"range": { "date": { "gte": "2014-01-01" }}
}
}
}
bool
must,must_not,should,filter
每个子查询都会计算一个document针对它的相关度分数,然后bool综合所有分数,合并为一个分数,当然filter是不会计算分数的
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte": "2014-01-01" }}},
{ "range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks" }}
]
}
}
}
}
GET /company/employee/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
}
}
如何定位不合法的搜索及其原因
GET /test_index/test_type/_validate/query?explain
{
"query": {
"math": {
"test_field": "test"
}
}
}
{
"valid": false,
"error": "org.elasticsearch.common.ParsingException: no [query] registered for [math]"
}
GET /test_index/test_type/_validate/query?explain
{
"query": {
"match": {
"test_field": "test"
}
}
}
{
"valid": true,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"explanations": [
{
"index": "test_index",
"valid": true,
"explanation": "+test_field:test #(#_type:test_type)"
}
]
}
一般用在那种特别复杂庞大的搜索下,比如你一下子写了上百行的搜索,这个时候可以先用validate api去验证一下,搜索是否合法
定制搜索结果的排序规则
1、默认排序规则
默认情况下,是按照_score降序排序的
然而,某些情况下,可能没有有用的_score,比如说filter
GET /_search
{
"query" : {
"bool" : {
"filter" : {
"term" : {
"author_id" : 1
}
}
}
}
}
当然,也可以是constant_score
GET /_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"author_id" : 1
}
}
}
}
}
2、定制排序规则
GET /company/employee/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
},
"sort": [
{
"join_date": {
"order": "asc"
}
}
]
}
如何将一个field索引两次来解决字符串排序问题
如果对一个string field进行排序,结果往往不准确,因为分词后是多个单词,再排序就不是我们想要的结果了
通常解决方案是,将一个string field建立两次索引,一个分词,用来进行搜索;一个不分词,用来进行排序
PUT /website
{
"mappings": {
"article": {
"properties": {
"title": {
"type": "text",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed"
}
},
"fielddata": true
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
},
"author_id": {
"type": "long"
}
}
}
}
}
PUT /website/article/1
{
"title": "first article",
"content": "this is my second article",
"post_date": "2017-01-01",
"author_id": 110
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "website",
"_type": "article",
"_id": "2",
"_score": 1,
"_source": {
"title": "first article",
"content": "this is my first article",
"post_date": "2017-02-01",
"author_id": 110
}
},
{
"_index": "website",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"title": "second article",
"content": "this is my second article",
"post_date": "2017-01-01",
"author_id": 110
}
},
{
"_index": "website",
"_type": "article",
"_id": "3",
"_score": 1,
"_source": {
"title": "third article",
"content": "this is my third article",
"post_date": "2017-03-01",
"author_id": 110
}
}
]
}
}
GET /website/article/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"title.raw": {
"order": "desc"
}
}
]
}
相关度评分TF&IDF算法
1、算法介绍
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度
Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关
搜索请求:hello world
doc1:hello you, and world is very good
doc2:hello, how are you
Inverse document frequency:搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关
搜索请求:hello world
doc1:hello, today is very good
doc2:hi world, how are you
比如说,在index中有1万条document,hello这个单词在所有的document中,一共出现了1000次;world这个单词在所有的document中,一共出现了100次
doc2更相关
Field-length norm:field长度,field越长,相关度越弱
搜索请求:hello world
doc1:{ “title”: “hello article”, “content”: “babaaba 1万个单词” }
doc2:{ “title”: “my article”, “content”: “blablabala 1万个单词,hi world” }
hello world在整个index中出现的次数是一样多
doc1更相关,title field更短
2、_score是如何被计算出来的
GET /test_index/test_type/_search?explain
{
"query": {
"match": {
"test_field": "test hello"
}
}
}
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1.595089,
"hits": [
{
"_shard": "[test_index][2]",
"_node": "4onsTYVZTjGvIj9_spWz2w",
"_index": "test_index",
"_type": "test_type",
"_id": "20",
"_score": 1.595089,
"_source": {
"test_field": "test hello"
},
"_explanation": {
"value": 1.595089,
"description": "sum of:",
"details": [
{
"value": 1.595089,
"description": "sum of:",
"details": [
{
"value": 0.58279467,
"description": "weight(test_field:test in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.58279467,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 0.6931472,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 2,
"description": "docFreq",
"details": []
},
{
"value": 4,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.840795,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 1.75,
"description": "avgFieldLength",
"details": []
},
{
"value": 2.56,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
},
{
"value": 1.0122943,
"description": "weight(test_field:hello in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 1.0122943,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 1.2039728,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 1,
"description": "docFreq",
"details": []
},
{
"value": 4,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.840795,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 1.75,
"description": "avgFieldLength",
"details": []
},
{
"value": 2.56,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "*:*, product of:",
"details": [
{
"value": 1,
"description": "boost",
"details": []
},
{
"value": 1,
"description": "queryNorm",
"details": []
}
]
}
]
}
]
}
},
{
"_shard": "[test_index][2]",
"_node": "4onsTYVZTjGvIj9_spWz2w",
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_score": 0.58279467,
"_source": {
"test_field": "tes test"
},
"_explanation": {
"value": 0.58279467,
"description": "sum of:",
"details": [
{
"value": 0.58279467,
"description": "sum of:",
"details": [
{
"value": 0.58279467,
"description": "weight(test_field:test in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.58279467,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 0.6931472,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 2,
"description": "docFreq",
"details": []
},
{
"value": 4,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.840795,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 1.75,
"description": "avgFieldLength",
"details": []
},
{
"value": 2.56,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "*:*, product of:",
"details": [
{
"value": 1,
"description": "boost",
"details": []
},
{
"value": 1,
"description": "queryNorm",
"details": []
}
]
}
]
}
]
}
},
{
"_shard": "[test_index][3]",
"_node": "4onsTYVZTjGvIj9_spWz2w",
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_score": 0.5565415,
"_source": {
"test_field": "test client 2"
},
"_explanation": {
"value": 0.5565415,
"description": "sum of:",
"details": [
{
"value": 0.5565415,
"description": "sum of:",
"details": [
{
"value": 0.5565415,
"description": "weight(test_field:test in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.5565415,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 0.6931472,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 1,
"description": "docFreq",
"details": []
},
{
"value": 2,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.8029196,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 2.5,
"description": "avgFieldLength",
"details": []
},
{
"value": 4,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "_type:test_type, product of:",
"details": [
{
"value": 1,
"description": "boost",
"details": []
},
{
"value": 1,
"description": "queryNorm",
"details": []
}
]
}
]
}
]
}
},
{
"_shard": "[test_index][1]",
"_node": "4onsTYVZTjGvIj9_spWz2w",
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_score": 0.25316024,
"_source": {
"test_field": "test client 2"
},
"_explanation": {
"value": 0.25316024,
"description": "sum of:",
"details": [
{
"value": 0.25316024,
"description": "sum of:",
"details": [
{
"value": 0.25316024,
"description": "weight(test_field:test in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.25316024,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 0.2876821,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 1,
"description": "docFreq",
"details": []
},
{
"value": 1,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.88,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 3,
"description": "avgFieldLength",
"details": []
},
{
"value": 4,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "*:*, product of:",
"details": [
{
"value": 1,
"description": "boost",
"details": []
},
{
"value": 1,
"description": "queryNorm",
"details": []
}
]
}
]
}
]
}
}
]
}
}
3、分析一个document是如何被匹配上的
GET /test_index/test_type/6/_explain
{
"query": {
"match": {
"test_field": "test hello"
}
}
}
内核级知识点之doc _value
搜索的时候,要依靠倒排索引;排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values
在建立索引的时候,一方面会建立倒排索引,以供搜索用;一方面会建立正排索引,也就是doc values,以供排序,聚合,过滤等操作使用
doc values是被保存在磁盘上的,此时如果内存足够,os会自动将其缓存在内存中,性能还是会很高;如果内存不足够,os会将其写入磁盘上
doc1: hello world you and me
doc2: hi, world, how are you
倒排索引

hello you --> hello, you
hello --> doc1
you --> doc1,doc2
sort by age
doc1: { “name”: “jack”, “age”: 27 }
doc2: { “name”: “tom”, “age”: 30 }
正排索引

内核级知识点之query phase
1、query phase
(1)搜索请求发送到某一个coordinate node,构构建一个priority queue,长度以paging操作from和size为准,默认为10
(2)coordinate node将请求转发到所有shard,每个shard本地搜索,并构建一个本地的priority queue
(3)各个shard将自己的priority queue返回给coordinate node,并构建一个全局的priority queue
2、replica shard如何提升搜索吞吐量
一次请求要打到所有shard的一个replica/primary上去,如果每个shard都有多个replica,那么同时并发过来的搜索请求可以同时打到其他的replica上去
图解:

内核级知识点之fetch phase
1、fetch phbase工作流
(1)coordinate node构建完priority queue之后,就发送mget请求去所有shard上获取对应的document
(2)各个shard将document返回给coordinate node
(3)coordinate node将合并后的document结果返回给client客户端
2、一般搜索,如果不加from和size,就默认搜索前10条,按照_score排序
图解:

搜索相关参数梳理以及bouncing results问题解决方案
1、preference
决定了哪些shard会被用来执行搜索操作
_primary, _primary_first, _local,
_only_node:xyz, _prefer_node:xyz, _shards:2,3
bouncing results问题,两个document排序,field值相同;不同的shard上,可能排序不同;每次请求轮询打到不同的replica shard上;每次页面上看到的搜索结果的排序都不一样。这就是bouncing result,也就是跳跃的结果。
搜索的时候,是轮询将搜索请求发送到每一个replica shard(primary shard),但是在不同的shard上,可能document的排序不同
解决方案就是将preference设置为一个字符串,比如说user_id,让每个user每次搜索的时候,都使用同一个replica shard去执行,就不会看到bouncing results了
2、timeout,已经讲解过原理了,主要就是限定在一定时间内,将部分获取到的数据直接返回,避免查询耗时过长
3、routing,document文档路由,_id路由,routing=user_id,这样的话可以让同一个user对应的数据到一个shard上去
4、search_type
default:query_then_fetch
dfs_query_then_fetch,可以提升revelance sort精准度
scoll技术滚动搜索大量数据
如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scoll滚动查询,一批一批的查,直到所有数据都查询完处理完
使用scoll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来
scoll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的
采用基于_doc进行排序的方式,性能较高
每次发送scroll请求,我们还需要指定一个scoll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了
GET /test_index/test_type/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": [ "_doc" ],
"size": 3
}
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAACxeFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYBY0b25zVFlWWlRqR3ZJajlfc3BXejJ3AAAAAAAALF8WNG9uc1RZVlpUakd2SWo5X3NwV3oydwAAAAAAACxhFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYhY0b25zVFlWWlRqR3ZJajlfc3BXejJ3",
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 10,
"max_score": null,
"hits": [
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_score": null,
"_source": {
"test_field": "test client 2"
},
"sort": [
0
]
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_score": null,
"_source": {
"test_field": "tes test"
},
"sort": [
0
]
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "AVp4RN0bhjxldOOnBxaE",
"_score": null,
"_source": {
"test_content": "my test"
},
"sort": [
0
]
}
]
}
}
获得的结果会有一个scoll_id,下一次再发送scoll请求的时候,必须带上这个scoll_id
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAACxeFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYBY0b25zVFlWWlRqR3ZJajlfc3BXejJ3AAAAAAAALF8WNG9uc1RZVlpUakd2SWo5X3NwV3oydwAAAAAAACxhFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYhY0b25zVFlWWlRqR3ZJajlfc3BXejJ3"
}
11,4,7
3,2,1
20
scoll,看起来挺像分页的,但是其实使用场景不一样。分页主要是用来一页一页搜索,给用户看的;scoll主要是用来一批一批检索数据,让系统进行处理的
2.20 索引管理
创建、修改以及删除索引
1、为什么我们要手动创建索引?
2、创建索引
创建索引的语法
PUT /my_index
{
“settings”: { … any settings … },
“mappings”: {
“type_one”: { … any mappings … },
“type_two”: { … any mappings … },
…
}
}
创建索引的示例
PUT /my_index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"my_type": {
"properties": {
"my_field": {
"type": "text"
}
}
}
}
}
3、修改索引
PUT /my_index/_settings
{
"number_of_replicas": 1
}
4、删除索引
DELETE /my_index
DELETE /index_one,index_two
DELETE /index_*
DELETE /_all
elasticsearch.yml
action.destructive_requires_name: true
修改分词器以及定制自己的分词器
1、默认的分词器
standard
standard tokenizer:以单词边界进行切分
standard token filter:什么都不做
lowercase token filter:将所有字母转换为小写
stop token filer(默认被禁用):移除停用词,比如a the it等等
2、修改分词器的设置
启用english停用词token filter
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
GET /my_index/_analyze
{
"analyzer": "standard",
"text": "a dog is in the house"
}
result:a dog is in the house
GET /my_index/_analyze
{
"analyzer": "es_std",
"text":"a dog is in the house"
}
result:dog house
3、定制化自己的分词器
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and"]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": ["the", "a"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["html_strip", "&_to_and"],
"tokenizer": "standard",
"filter": ["lowercase", "my_stopwords"]
}
}
}
}
}
GET /my_index/_analyze
{
"text": "tom&jerry are a friend in the house, , HAHA!!",
"analyzer": "my_analyzer"
}
PUT /my_index/_mapping/my_type
{
"properties": {
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
type底层数据结构
type,是一个index中用来区分类似的数据的,类似的数据,但是可能有不同的fields,而且有不同的属性来控制索引建立、分词器
field的value,在底层的lucene中建立索引的时候,全部是opaque bytes类型,不区分类型的
lucene是没有type的概念的,在document中,实际上将type作为一个document的field来存储,即_type,es通过_type来进行type的过滤和筛选
一个index中的多个type,实际上是放在一起存储的,因此一个index下,不能有多个type重名,而类型或者其他设置不同的,因为那样是无法处理的
{
"ecommerce": {
"mappings": {
"elactronic_goods": {
"properties": {
"name": {
"type": "string",
},
"price": {
"type": "double"
},
"service_period": {
"type": "string"
}
}
},
"fresh_goods": {
"properties": {
"name": {
"type": "string",
},
"price": {
"type": "double"
},
"eat_period": {
"type": "string"
}
}
}
}
}
}
{
"name": "geli kongtiao",
"price": 1999.0,
"service_period": "one year"
}
{
"name": "aozhou dalongxia",
"price": 199.0,
"eat_period": "one week"
}
在底层的存储是这样子的。。。。
{
"ecommerce": {
"mappings": {
"_type": {
"type": "string",
"index": "not_analyzed"
},
"name": {
"type": "string"
}
"price": {
"type": "double"
}
"service_period": {
"type": "string"
}
"eat_period": {
"type": "string"
}
}
}
}
{
"_type": "elactronic_goods",
"name": "geli kongtiao",
"price": 1999.0,
"service_period": "one year",
"eat_period": ""
}
{
"_type": "fresh_goods",
"name": "aozhou dalongxia",
"price": 199.0,
"service_period": "",
"eat_period": "one week"
}
最佳实践,将类似结构的type放在一个index下,这些type应该有多个field是相同的
假如说,你将两个type的field完全不同,放在一个index下,那么就每条数据都至少有一半的field在底层的lucene中是空值,会有严重的性能问题
mapping root object
1、root object
就是某个type对应的mapping json,包括了properties,metadata(_id,_source,_type),settings(analyzer),其他settings(比如include_in_all)
PUT /my_index
{
"mappings": {
"my_type": {
"properties": {}
}
}
}
2、properties
type,index,analyzer
PUT /my_index/_mapping/my_type
{
"properties": {
"title": {
"type": "text"
}
}
}
3、_source
好处
(1)查询的时候,直接可以拿到完整的document,不需要先拿document id,再发送一次请求拿document
(2)partial update基于_source实现
(3)reindex时,直接基于_source实现,不需要从数据库(或者其他外部存储)查询数据再修改
(4)可以基于_source定制返回field
(5)debug query更容易,因为可以直接看到_source
如果不需要上述好处,可以禁用_source
PUT /my_index/_mapping/my_type2
{
"_source": {"enabled": false}
}
4、_all
将所有field打包在一起,作为一个_all field,建立索引。没指定任何field进行搜索时,就是使用_all field在搜索。
PUT /my_index/_mapping/my_type3
{
"_all": {"enabled": false}
}
也可以在field级别设置include_in_all field,设置是否要将field的值包含在_all field中
PUT /my_index/_mapping/my_type4
{
"properties": {
"my_field": {
"type": "text",
"include_in_all": false
}
}
}
5、标识性metadata
_index,_type,_id
定制化dynamic mapping策略
1、定制dynamic策略
true:遇到陌生字段,就进行dynamic mapping
false:遇到陌生字段,就忽略
strict:遇到陌生字段,就报错
PUT /my_index
{
"mappings": {
"my_type": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": "true"
}
}
}
}
}
PUT /my_index/my_type/1
{
"title": "my article",
"content": "this is my article",
"address": {
"province": "guangdong",
"city": "guangzhou"
}
}
result:
{
"error": {
"root_cause": [
{
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [content] within [my_type] is not allowed"
}
],
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [content] within [my_type] is not allowed"
},
"status": 400
}
PUT /my_index/my_type/1
{
"title": "my article",
"address": {
"province": "guangdong",
"city": "guangzhou"
}
}
GET /my_index/_mapping/my_type
{
"my_index": {
"mappings": {
"my_type": {
"dynamic": "strict",
"properties": {
"address": {
"dynamic": "true",
"properties": {
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"province": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"title": {
"type": "text"
}
}
}
}
}
}
2、定制dynamic mapping策略
(1)date_detection
默认会按照一定格式识别date,比如yyyy-MM-dd。但是如果某个field先过来一个2017-01-01的值,就会被自动dynamic mapping成date,后面如果再来一个"hello world"之类的值,就会报错。可以手动关闭某个type的date_detection,如果有需要,自己手动指定某个field为date类型。
PUT /my_index/_mapping/my_type
{
"date_detection": false
}
(2)定制自己的dynamic mapping template(type level)
PUT /my_index
{
"mappings": {
"my_type": {
"dynamic_templates": [
{ "en": {
"match": "*_en",
"match_mapping_type": "string",
"mapping": {
"type": "string",
"analyzer": "english"
}
}}
]
}}}
PUT /my_index/my_type/1
{
"title": "this is my first article"
}
PUT /my_index/my_type/2
{
"title_en": "this is my first article"
}
title没有匹配到任何的dynamic模板,默认就是standard分词器,不会过滤停用词,is会进入倒排索引,用is来搜索是可以搜索到的
title_en匹配到了dynamic模板,就是english分词器,会过滤停用词,is这种停用词就会被过滤掉,用is来搜索就搜索不到了
(3)定制自己的default mapping template(index level)
PUT /my_index
{
"mappings": {
"_default_": {
"_all": { "enabled": false }
},
"blog": {
"_all": { "enabled": true }
}
}
}
基于scoll+bulk+索引别名实现零停机重建索引
1、重建索引
一个field的设置是不能被修改的,如果要修改一个Field,那么应该重新按照新的mapping,建立一个index,然后将数据批量查询出来,重新用bulk api写入index中
批量查询的时候,建议采用scroll api,并且采用多线程并发的方式来reindex数据,每次scoll就查询指定日期的一段数据,交给一个线程即可
(1)一开始,依靠dynamic mapping,插入数据,但是不小心有些数据是2017-01-01这种日期格式的,所以title这种field被自动映射为了date类型,实际上它应该是string类型的
PUT /my_index/my_type/3
{
"title": "2017-01-03"
}
{
"my_index": {
"mappings": {
"my_type": {
"properties": {
"title": {
"type": "date"
}
}
}
}
}
}
(2)当后期向索引中加入string类型的title值的时候,就会报错
PUT /my_index/my_type/4
{
"title": "my first article"
}
result:
{
"error": {
"root_cause": [
{
"type": "mapper_parsing_exception",
"reason": "failed to parse [title]"
}
],
"type": "mapper_parsing_exception",
"reason": "failed to parse [title]",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Invalid format: \"my first article\""
}
},
"status": 400
}
(3)如果此时想修改title的类型,是不可能的
PUT /my_index/_mapping/my_type
{
"properties": {
"title": {
"type": "text"
}
}
}
result:
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "mapper [title] of different type, current_type [date], merged_type [text]"
}
],
"type": "illegal_argument_exception",
"reason": "mapper [title] of different type, current_type [date], merged_type [text]"
},
"status": 400
}
(4)此时,唯一的办法,就是进行reindex,也就是说,重新建立一个索引,将旧索引的数据查询出来,再导入新索引
(5)如果说旧索引的名字,是old_index,新索引的名字是new_index,终端java应用,已经在使用old_index在操作了,难道还要去停止java应用,修改使用的index为new_index,才重新启动java应用吗?这个过程中,就会导致java应用停机,可用性降低
(6)所以说,给java应用一个别名,这个别名是指向旧索引的,java应用先用着,java应用先用goods_index alias来操作,此时实际指向的是旧的my_index
PUT /my_index/_alias/goods_index
(7)新建一个index,调整其title的类型为string
PUT /my_index_new
{
"mappings": {
"my_type": {
"properties": {
"title": {
"type": "text"
}
}
}
}
}
(8)使用scroll api将数据批量查询出来
GET /my_index/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": ["_doc"],
"size": 1
}
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAADpAFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAA6QRY0b25zVFlWWlRqR3ZJajlfc3BXejJ3AAAAAAAAOkIWNG9uc1RZVlpUakd2SWo5X3NwV3oydwAAAAAAADpDFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAA6RBY0b25zVFlWWlRqR3ZJajlfc3BXejJ3",
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": null,
"hits": [
{
"_index": "my_index",
"_type": "my_type",
"_id": "2",
"_score": null,
"_source": {
"title": "2017-01-02"
},
"sort": [
0
]
}
]
}
}
(9)采用bulk api将scoll查出来的一批数据,批量写入新索引
POST /_bulk
{ "index": { "_index": "my_index_new", "_type": "my_type", "_id": "2" }}
{ "title": "2017-01-02" }
(10)反复循环8~9,查询一批又一批的数据出来,采取bulk api将每一批数据批量写入新索引
(11)将goods_index alias切换到my_index_new上去,java应用会直接通过index别名使用新的索引中的数据,java应用程序不需要停机,零提交,高可用
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index", "alias": "goods_index" }},
{ "add": { "index": "my_index_new", "alias": "goods_index" }}
]
}
(12)直接通过goods_index别名来查询,是否ok
GET /goods_index/my_type/_search
2、基于alias对client透明切换index
PUT /my_index_v1/_alias/my_index
client对my_index进行操作
reindex操作,完成之后,切换v1到v2
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index_v1", "alias": "my_index" }},
{ "add": { "index": "my_index_v2", "alias": "my_index" }}
]
}
2.21 内核原理
倒排索引
倒排索引,是适合用于进行搜索的
倒排索引的结构
(1)包含这个关键词的document list
(2)包含这个关键词的所有document的数量:IDF(inverse document frequency)
(3)这个关键词在每个document中出现的次数:TF(term frequency)
(4)这个关键词在这个document中的次序
(5)每个document的长度:length norm
(6)包含这个关键词的所有document的平均长度

倒排索引不可变的好处
(1)不需要锁,提升并发能力,避免锁的问题
(2)数据不变,一直保存在os cache中,只要cache内存足够
(3)filter cache一直驻留在内存,因为数据不变
(4)可以压缩,节省cpu和io开销
倒排索引不可变的坏处:每次都要重新构建整个索引
document写入原理
(1)数据写入buffer
(2)commit point
(3)buffer中的数据写入新的index segment
(4)等待在os cache中的index segment被fsync强制刷到磁盘上
(5)新的index sgement被打开,供search使用
(6)buffer被清空
每次commit point时,会有一个.del文件,标记了哪些segment中的哪些document被标记为deleted了
搜索的时候,会依次查询所有的segment,从旧的到新的,比如被修改过的document,在旧的segment中,会标记为deleted,在新的segment中会有其新的数据

优化写入流程实现NRT近实时
现有流程的问题,每次都必须等待fsync将segment刷入磁盘,才能将segment打开供search使用,这样的话,从一个document写入,到它可以被搜索,可能会超过1分钟!!!这就不是近实时的搜索了!!!主要瓶颈在于fsync实际发生磁盘IO写数据进磁盘,是很耗时的。
写入流程别改进如下:
(1)数据写入buffer
(2)每隔一定时间,buffer中的数据被写入segment文件,但是先写入os cache
(3)只要segment写入os cache,那就直接打开供search使用,不立即执行commit
数据写入os cache,并被打开供搜索的过程,叫做refresh,默认是每隔1秒refresh一次。也就是说,每隔一秒就会将buffer中的数据写入一个新的index segment file,先写入os cache中。所以,es是近实时的,数据写入到可以被搜索,默认是1秒。
POST /my_index/_refresh,可以手动refresh,一般不需要手动执行,没必要,让es自己搞就可以了
比如说,我们现在的时效性要求,比较低,只要求一条数据写入es,一分钟以后才让我们搜索到就可以了,那么就可以调整refresh interval
PUT /my_index
{
"settings": {
"refresh_interval": "30s"
}
}
commit。。。稍后就会讲。。。

优化写入流程实现durability可靠存储
再次优化的写入流程
(1)数据写入buffer缓冲和translog日志文件
(2)每隔一秒钟,buffer中的数据被写入新的segment file,并进入os cache,此时segment被打开并供search使用
(3)buffer被清空
(4)重复1~3,新的segment不断添加,buffer不断被清空,而translog中的数据不断累加
(5)当translog长度达到一定程度的时候,commit操作发生
(5-1)buffer中的所有数据写入一个新的segment,并写入os cache,打开供使用
(5-2)buffer被清空
(5-3)一个commit ponit被写入磁盘,标明了所有的index segment
(5-4)filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上
(5-5)现有的translog被清空,创建一个新的translog
基于translog和commit point,如何进行数据恢复
fsync+清空translog,就是flush,默认每隔30分钟flush一次,或者当translog过大的时候,也会flush
POST /my_index/_flush,一般来说别手动flush,让它自动执行就可以了
translog,每隔5秒被fsync一次到磁盘上。在一次增删改操作之后,当fsync在primary shard和replica shard都成功之后,那次增删改操作才会成功
但是这种在一次增删改时强行fsync translog可能会导致部分操作比较耗时,也可以允许部分数据丢失,设置异步fsync translog
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}

终极版本的es数据写入流程
最后优化写入流程实现海量磁盘文件合并
每秒一个segment file,文件过多,而且每次search都要搜索所有的segment,很耗时
默认会在后台执行segment merge操作,在merge的时候,被标记为deleted的document也会被彻底物理删除
每次merge操作的执行流程
(1)选择一些有相似大小的segment,merge成一个大的segment
(2)将新的segment flush到磁盘上去
(3)写一个新的commit point,包括了新的segment,并且排除旧的那些segment
(4)将新的segment打开供搜索
(5)将旧的segment删除
POST /my_index/_optimize?max_num_segments=1,尽量不要手动执行,让它自动默认执行就可以了

Elasticsearch顶尖高手系列-快速入门篇原视频
视频分享给大家看
链接:https://pan.baidu.com/s/1ma6Qcezr5_Zu0V8RaCLU-A
提取码:9cyw
复制这段内容后打开百度网盘手机App,操作更方便哦