JavaSE实战——IO流
转载请声明出处:http://blog.csdn.net/zhongkelee/article/details/47061013
前言
本文以图文并茂的形式重点记录了这一周学习Java中IO操作的心得,并配以大量练习代码。Java的IO流无外乎就是输入流和输出流,所以基础部分还是比较简单的。
简述
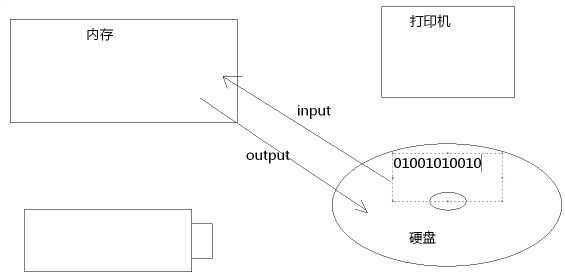
IO:用于处理设备上的数据的技术。设备:内存、硬盘、光盘。java中所涉及的功能对象都存储到java.io包中。
流:系统资源,windows系统本身就可以操作设备。各种语言只是使用了系统平台上的这个资源。并对外提供了各种语言自己的操作功能,这些功能最终调用的是系统资源。使用完资源一定要记住:释放。(也就是说IO一定要写finally!)
IO流也进行分类:
1:输入流(读)和输出流(写)。
2:因为处理的数据不同,分为字节流和字符流。

输入流和输出流相对于内存设备而言。
将外设中的数据读取到内存中:输入-->读
将内存的数写入到外设中:输出-->写
注意:流的操作只有两种:读和写。
字节流:处理字节数据的流对象。设备上的数据无论是图片或者dvd,文字,它们都以二进制存储的。二进制的最终都是以一个8位为数据单元进行体现,所以计算机中的最小数据单元就是字节。意味着,字节流可以处理设备上的所有数据,所以字节流一样可以处理字符数据。
字符流:因为字符每个国家都不一样,所以涉及到了字符编码问题,那么GBK编码的中文用unicode编码解析是有问题的,所以需要获取中文字节数据的同时+ 指定的编码表才可以解析正确数据。为了方便于文字的解析,所以将字节流和编码表封装成对象,这个对象就是字符流。只要操作字符数据,优先考虑使用字符流体系。
流的体系因为功能不同,但是有共性内容,不断抽取,形成继承体系。该体系一共有四个基类,而且都是抽象类。
字节流:InputStream OutputStream
字符流:Reader Writer
在这四个系统中,它们的子类,都有一个共性特点:子类名后缀都是父类名,前缀名都是这个子类的功能名称。
File类
java.io.File类将文件系统中的文件和文件夹封装成了对象。提供了更多的属性和行为可以对这些文件和文件夹进行操作。这些是流对象办不到的,因为流只操作数据。设备上的数据(0、1串)最常见的存储表现形式是文件file。先学习一下文件的基本操作。
查阅API,描述文件或者文件夹(目录路径名)的类是File类。常用方法需要查表。
首先我们来演示一下File构造函数的使用。
package ustc.lichunchun.file.demo;
import java.io.File;
/*
* File对象创建过程、字段信息。
*
* 注意:File文件对象只能操作文件或者文件夹的属性,
* 例如文件或文件夹的创建、删除、获取文件属性(大小、所在目录等),
* 但我们最终建立文件的目的,是往文件里面存数据,File对象是做不了这个的。
* 这时,我们就要用到IO流。
*/
public class FileDemo {
//File类已经提供了相应字段。
//private static final String FILE_SEPARATOR = System.getProperty("file.separator");
public static void main(String[] args) {
//将某一个文件或者文件夹封装成了File对象。可以封装存在的文件或目录,也可以封装不存在的文件或目录。
//注意,这里File对象封装的实际上是1.txt,至于d:\\只是作为全路径目录。
//再比如,new File("abc\\a\\b\\c");实际上封装的是c文件夹以及其全路径目录。
File file = new File("d:\\1.txt");
//File(String parent, String child);这样可以将目录和文件名分开。
File file1 = new File("d:\\", "1.txt");
File dir = new File("d:\\");
File file2 = new File(dir, "1.txt");
//File f = new File("d:"+System.getProperty("file.separator")+"abc"+System.getProperty("file.separator")+"1.txt");
//File f = new File("d:"+FILE_SEPARATOR+"abc"+FILE_SEPARATOR+"1.txt");
File f = new File("d:"+File.separator+"abc"+File.separator+"1.txt");
System.out.println(f);
}
}File类常见方法:
1:创建。
boolean createNewFile():在指定目录下创建文件,如果该文件已存在,则不创建。而对操作文件的输出流而言,比如FileOutputStream,输出流对象已建立,就会创建文件,如果文件已存在,会覆盖。除非续写。
boolean mkdir():创建此抽象路径名指定的目录。
boolean mkdirs():创建多级目录。
2:删除。
boolean delete():删除此抽象路径名表示的文件或目录。
void deleteOnExit():在虚拟机退出时删除。
注意:在删除文件夹时,必须保证这个文件夹中没有任何内容,才可以将该文件夹用delete删除。
window的删除动作,是从里往外删。注意:java删除文件不走回收站。要慎用。
3:获取。
long length():获取文件大小。
String getName():返回由此抽象路径名表示的文件或目录的名称。
String getPath():将此抽象路径名转换为一个路径名字符串。
String getAbsolutePath():返回此抽象路径名的绝对路径名字符串。
String getParent():返回此抽象路径名父目录的抽象路径名,如果此路径名没有指定父目录,则返回 null。
long lastModified():返回此抽象路径名表示的文件最后一次被修改的时间。
File.pathSeparator:返回当前系统默认的路径分隔符,windows默认为 “;”。
File.Separator:返回当前系统默认的目录分隔符,windows默认为 “\”。
4:判断。
boolean exists():判断文件或者文件夹是否存在。
boolean isDirectory():测试此抽象路径名表示的文件是否是一个目录。
boolean isFile():测试此抽象路径名表示的文件是否是一个标准文件。
boolean isHidden():测试此抽象路径名指定的文件是否是一个隐藏文件。
boolean isAbsolute():测试此抽象路径名是否为绝对路径名。
5:重命名。
boolean renameTo(File dest):可以实现移动的效果。剪切+重命名。
String[] list():列出指定目录下的当前的文件和文件夹的名称。包含隐藏文件。如果调用list方法的File 对象中封装的是一个文件,那么list方法返回数组为null。如果封装的对象不存在也会返回null。只有封装的对象存在并且是文件夹时,这个方法才有效。
注意:list(FilenameFilter filter)和listFiles(FileFilter filter)往往是和过滤器实例参数一起使用。
代码示例1:
package ustc.lichunchun.file.demo;
import java.io.File;
public class FileMethodDemo {
public static void main(String[] args) {
/*
* File类,常见方法。
* 1.名字。获取名称。
* String getName();
* 2.大小。获取大小。
* long length();
* 3.类型。获取类型。
* 没有,因为类型可以自定义。
* 4.获取所在目录。
* String getParent();
*/
File file = new File("d:\\abc\\1.txt");
String file_name = file.getName();
System.out.println(file_name);//1.txt-->File对象封装的是1.txt所在路径(而且不是绝对路径)。
long len = file.length();
System.out.println(len);//0
System.out.println(file.getParent());//d:\abc
}
}package ustc.lichunchun.file.demo;
import java.io.File;
import java.io.IOException;
import java.text.DateFormat;
import java.util.Date;
public class FileMethodTest {
public static void main(String[] args) throws IOException {
/*
* File方法 练习:
*
* 1.获取文件的绝对路径。
* String getAbsolutePath();
*
* 2.获取文件的路径。
* String getPath();
*
* 3.获取文件最后一次修改的时间。要求是x年x月x日。时间。
* long lastModified();
*
* 4.文件是否是隐藏的。
* boolean isHidden();
*
* 5.发现File对象封装的文件或者文件夹是可以存在的也可以是不存在的。
* 那么不存在的可否用file的功能创建呢?
* 创建功能。
* boolean createNewFile();
*
* 删除功能。
* boolean delete();
*
* 6.一个File对象封装成的文件或者文件夹到底是否存在呢?
* 判断存在功能。
* boolean exists();
*
* 7.getFreeSpace()方法是什么意思?用Demo验证。getTotalSpace()、getUsableSpace()
* 指定分区中:未分配、总共、已分配字节数。用处:迅雷看看缓存到本地,会先判断哪个盘符剩余空间比较大。
*
* 8.列出可用的文件系统根。
* file[] listRoots();
*
*/
//methodDemo1();
//文件创建与删除
File file = new File("1.txt");
//methodDemo2(file);
//文件夹创建与删除
File file1 = new File("abc\\a\\b\\c");
//methodDemo3(file1);
//揭秘
//methodDemo4();
File file2 = new File("d:\\");
//System.out.println(file2.getFreeSpace());//128448581632
listRootsDemo();
}
public static void methodDemo1() {
File file = new File("abc\\1.txt");
String path = file.getAbsolutePath();//E:\JavaSE_code\day21e\abc\1.txt-->获取文件对象的绝对路径。即使封装的是相对的,获取到的也是绝对的,这时就是所在项目的绝对路径下。
String path1 = file.getPath();//abc\1.txt-->获取的是file对象中的封装的路径。封装的是什么,获取到的就是什么。
System.out.println("AbsolutePath = "+path);
System.out.println("Path = "+path1);
File file1 = new File("E:\\JavaSE_code\\day21e\\IO流_1.txt");
long time = file1.lastModified();
Date date = new Date(time);
String str_date = DateFormat.getDateTimeInstance(DateFormat.LONG,DateFormat.LONG).format(date);
System.out.println(time);//1436701878494
System.out.println(str_date);//2015年7月12日 下午07时51分18秒
boolean b = file.isHidden();
System.out.println("isHidden():" + b);//false
}
public static void methodDemo2(File file) throws IOException {
//1.演示文件的创建。
boolean b = file.createNewFile();//如果文件存在,则不创建,返回false;不存在,就创建,创建成功,返回true。
System.out.println(b);
//2.文件的删除。
boolean b1 = file.delete();
System.out.println(b1);
//3.判断文件是否存在
System.out.println(file.exists());
}
public static void methodDemo3(File file) {
//1.演示文件夹的创建。
//boolean b = file.mkdir();//只能创建单级目录:new File("abc")
boolean b = file.mkdirs();//创建多级目录:new File("abc\\a\\b\\c"),或者创建单级目录:new File("abc")
System.out.println(b);
System.out.println("exists: "+file.exists());
//2.演示文件夹的删除。
boolean b1 = file.delete();//删除文件夹时,必须保证该文件夹没有内容。有内容,必须先把内容删除后,才可以删除当前文件夹。
System.out.println("delete: "+b1);
}
public static void methodDemo4() throws IOException {
//揭秘:你用什么方法创建的,它就是什么。
//千万不要被表面现象所迷惑: abc.txt有可能是文件夹,abc有可能是文件。
//是不是文件,不能主观判断,得用isFile()、isDirectory()判断。
//而且在用is之前,要先判断是否存在!
File file1 = new File("abc");
System.out.println("file: "+file1.isFile());//false
System.out.println("directory: "+file1.isDirectory());//false,如果一个东西不存在的情况下,不可能是文件或者文件夹。
System.out.println("--------------");
File file2 = new File("abc");
boolean b2 = file2.mkdirs();
System.out.println("mkdirs: "+b2);//true
System.out.println("file: "+file2.isFile());//false
System.out.println("directory: "+file2.isDirectory());//true
System.out.println("--------------");
File file3 = new File("edf");
boolean b3 = file3.createNewFile();
System.out.println("createNewFile: "+b3);//true
System.out.println("file: "+file3.isFile());//true,文件不一定非要有扩展名
System.out.println("directory: "+file3.isDirectory());//false
System.out.println("--------------");
File file4 = new File("abc.txt");
boolean b4 = file4.mkdirs();
System.out.println("mkdirs: "+b4);//true
System.out.println("file: "+file4.isFile());//false
System.out.println("directory: "+file4.isDirectory());//true,文件夹也可以包含"."
}
public static void listRootsDemo() {
File[] files = File.listRoots();
for(File file : files)
System.out.println(file);
}
}package ustc.lichunchun.file.demo;
import java.io.File;
public class FileMethodTest2 {
public static void main(String[] args) {
/*
* 9.获取指定文件夹中的所有文件和文件夹的名称。
*/
File dir = new File("d:\\");
String[] names = dir.list();//列出当前目录下的所有文件和文件夹名称,包含隐藏文件。
//list()局限:只获取名称。
//如果目录存在但是没有内容,会返回一个数组,但是长度为0。
if(names != null){
for (String name : names) {
System.out.println(name);
}
}
System.out.println("-------------------------");
File[] files = dir.listFiles();//获取当前目录下的所有文件和文件夹的File对象,更为常用。
for(File f : files){
System.out.println(f.getName()+"......"+f.length());
}
}
}接下来我要介绍的是文件名过滤器和文件过滤器,它们的用途是为了获取指定目录下的指定类型文件。所采用到的设计模式属于策略设计模式,目的就是为了降低容器和过滤条件之间的耦合性。
1.文件名过滤器:FilenameFilter
它的底层源码如下:
public String[] list(FilenameFilter filter) {
String names[] = list();
if ((names == null) || (filter == null)) {
return names;
}
List v = new ArrayList<>();
for (int i = 0 ; i < names.length ; i++) {
if (filter.accept(this, names[i])) {
v.add(names[i]);
}
}
return v.toArray(new String[v.size()]);
} package ustc.lichunchun.filter;
import java.io.File;
import java.io.FilenameFilter;
/*
* 根据文件名称的后缀名进行过滤的过滤器。
*/
public class FilterBySuffix implements FilenameFilter {
private String suffix;
public FilterBySuffix(String suffix) {
super();
this.suffix = suffix;
}
/**
* @param name 被遍历目录dir中的文件夹或者文件的名称。
*/
@Override
public boolean accept(File dir, String name) {
return name.endsWith(suffix);
}
}package ustc.lichunchun.file.demo;
import java.io.File;
import ustc.lichunchun.filter.FilterBySuffix;
public class FilenameFilterDemo {
public static void main(String[] args) {
/*
* 10.能不能只获取指定目录下的.java文件呢?
* 文件名过滤器:list(FilenameFilter filter);
*/
/*
File dir = new File("d:\\");
String[] names = dir.list();
for(String name : names){
if(name.endsWith(".java"))//-->耦合性太强。
System.out.println(name);
}
*/
//文件名过滤器:让容器和过滤条件分离,降低耦合性。
//类似于比较器,都属于策略设计模式。不要面对具体的过滤或者排序动作,我只面对接口。
File dir = new File("d:\\");
//传入一个过滤器。
String[] names = dir.list(new FilterBySuffix(".java"));
for(String name : names){
System.out.println(name);
}
}
}package ustc.lichunchun.filter;
import java.io.File;
import java.io.FilenameFilter;
public class FilterByContain implements FilenameFilter {
private String content;
public FilterByContain(String content) {
super();
this.content = content;
}
@Override
public boolean accept(File dir, String name) {
return name.contains(content);
}
}
package ustc.lichunchun.file.demo;
import java.io.File;
import java.io.FilenameFilter;
import ustc.lichunchun.filter.FilterByContain;
import ustc.lichunchun.filter.FilterBySuffix;
public class FilenameFilterDemo2 {
public static void main(String[] args) {
//需求:不是获取指定后缀名的文件,而是获取文件名中包含指定字段的文件。
File dir = new File("d:\\");
FilenameFilter filter = new FilterBySuffix(".java");//过滤后缀名的过滤器。
filter = new FilterByContain("Demo");//过滤内容的过滤器。
String[] names = dir.list(filter);
for(String name : names){
System.out.println(name);
}
}
}2.文件过滤器:FileFilter
文件过滤器其实更为常用。因为过滤器中pathname.getName().endsWith(".java")可以实现同样的文件名过滤操作。
我再用文件过滤器的方法,实现上面文件名过滤器所示例的,过滤指定类型文件的过滤器:
package ustc.lichunchun.filter;
import java.io.File;
import java.io.FileFilter;
public class FilterBySuffix2 implements FileFilter {
private String suffix;
public FilterBySuffix2(String suffix) {
super();
this.suffix = suffix;
}
@Override
public boolean accept(File pathname) {
return pathname.getName().endsWith(suffix);
}
}package ustc.lichunchun.filter;
import java.io.File;
import java.io.FileFilter;
public class FilterByFile implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.isFile();//文件过滤器。只筛选出文件,不要文件夹。
}
}package ustc.lichunchun.filter;
import java.io.File;
import java.io.FileFilter;
public class FilterByDirectory implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.isDirectory();
}
}package ustc.lichunchun.file.demo;
import java.io.File;
import java.io.FileFilter;
import ustc.lichunchun.filter.FilterByDirectory;
import ustc.lichunchun.filter.FilterByFile;
import ustc.lichunchun.filter.FilterBySuffix2;
public class FileFilterDemo {
public static void main(String[] args) {
File dir = new File("d:\\");
FileFilter filter = new FilterByFile();//过滤出当前目录下所有文件
filter = new FilterByDirectory();//过滤出当前目录下所有文件夹
filter = new FilterBySuffix2(".java");//过滤出当前目录下所有以指定后缀名结尾的文件和文件夹
File[] files = dir.listFiles(filter);
for(File file : files){
System.out.println(file);
}
System.out.println("-------------------------");
}
}(1)接口NumberFilter:表示过滤器接口。接口NumberFilter的抽象方法boolean is(int n)供使用者实现以设置筛选条件。
(2)类NumberArray:表示一组整数的对象(可用int型数组作为其成员来存放一组整数)。类NumberArray的方法print(0输出满足过滤器NumberFilter设置的筛选条件的部分整数。类NumberArray的方法setFilter(NumberFilter nf)用于设置过滤器。
(3)类Filter:表示具体的过滤器,实现接口NumberFilter,实现is()方法用于设置筛选条件,这里要求过滤出偶数。
package ustc.lichunchun.filter;
public class Test {
public static void main(String[] args) {
int[] array = {1,2,3,4,5,6,7,8,9};
NumberFilter nf = new Filter();
NumberArray na = new NumberArray(array, nf);
na.print();
}
}
class NumberArray {
private int[] array;
public NumberArray(int[] array, NumberFilter nf) {
super();
this.array = array;
this.nf = nf;
}
private NumberFilter nf;
public void print(){
for(int i : array){
if(nf.is(i)){
System.out.print(i+ " ");
}
}
System.out.println();
}
public void setFilter(NumberFilter nf){
this.nf = nf;
}
}
class Filter implements NumberFilter {
@Override
public boolean is(int n) {
if(n % 2 == 0)
return true;
return false;
}
}
interface NumberFilter {
boolean is(int n);
}递归及其IO应用
说完了上面的过滤器以后,我们已经可以实现过滤出指定目录下的特定类型文件了。但是现在我又有一个需求:遍历指定目录下的内容(包含子目录中的内容)。这该如何处理呢?再解决这个问题之前,我们下来简单回顾一下算法课中所学的递归思想。
递归:就是函数自身调用自身。
什么时候用递归呢?当一个功能被重复使用,而每一次使用该功能时的参数不确定,都由上次的功能元素结果来确定。简单说:功能内部又用到该功能,但是传递的参数值不确定。(每次功能参与运算的未知内容不确定)。
递归的注意事项:
1:一定要定义递归的条件。
2:递归的次数不要过多。容易出现 StackOverflowError 栈内存溢出错误。
其实递归就是在栈内存中不断的加载同一个函数。
递归示例:
package ustc.lichunchun.recursion;
public class RecursionDemo {
public static void main(String[] args) {
/*
* 递归使用时,一定要定义条件。
* 注意:递归次数过多,会出现栈内存溢出。
*/
//show();
int sum = getSum(3);
System.out.println("sum = "+sum);//3+((3-1)+(3-1-1))
int sum1 = getSum(999999);//java.lang.StackOverflowError
}
public static int getSum(int num){
if(num == 1)
return 1;
return num + getSum(num - 1);
}
/*这也是递归,并且会溢出。
public static void show(){
method();
}
public static void method(){
show();
}
*/
}package ustc.lichunchun.file.test;
import java.io.File;
public class GetAllFilesTest {
public static void main(String[] args) {
/*
* 遍历指定目录下的内容(包含子目录中的内容)
*
* 递归:函数自身调用自身,不断进栈。函数内部又使用到了该函数功能。
* 什么时候使用呢?
* 功能被重复使用,但是每次该功能使用参与运算的数据不同时,可以考虑递归方式解决。
*
*/
File dir = new File("d:\\JavaSE_code");
getAllFiles(dir);
}
public static void getAllFiles(File dir){
System.out.println("dir: "+dir);
//1.获取该目录的文件对象数组
File[] files = dir.listFiles();
//2.对数组进行遍历
if(files != null){//windows一些文件夹是不可以被java访问到的。
for(File file : files){
if(file.isDirectory()){
getAllFiles(file);
}else{
System.out.println("file: "+file);
}
}
}
}
}package ustc.lichunchun.file.test;
import java.io.File;
public class DeleteDirTest {
public static void main(String[] args) {
/*
* 基于递归,做一个练习:删除一个带内容的文件夹。必须从里往外删。
*/
File dir = new File("d:\\JavaSE_code");
//System.out.println(dir.delete());//false,有内容的文件夹不能直接删
deleteDir(dir);
}
public static void deleteDir(File dir){
//1.列出当前目录下的文件以及文件夹。
File[] files = dir.listFiles();
//2.对该数组进行遍历。
for(File file : files){
//3/判断是否有目录。如果有,继续使用该功能遍历,递归!如果不是文件夹,直接删除。
if(file.isDirectory()){
deleteDir(file);
}else{
System.out.println(file + ":" +file.delete());
}
}
//4.删除不含文件了的文件夹
System.out.println(dir + ":" +dir.delete());
}
}File类综合练习
获取一个想要的指定文件的集合。获取JavaSE_code下(包含子目录)的所有的.java的文件对象。并存储到集合中。
思路:
1.既然包含子目录,就需要递归。
2.在递归的过程中,需要过滤器。
3.凡是满足条件的,都添加到集合中。
package ustc.lichunchun.test;
import java.io.File;
import java.io.FileFilter;
import java.util.ArrayList;
import java.util.List;
import ustc.lichunchun.filter.FilterBySuffix2;
public class Test {
public static void main(String[] args) {
/*
* 需求:获取一个想要的指定文件的集合。获取JavaSE_code下(包含子目录)的所有的.java的文件对象。并存储到集合中。
*
* 思路:
* 1.既然包含子目录,就需要递归。
* 2.在递归的过程中,需要过滤器。
* 3.凡是满足条件的,都添加到集合中。
*/
File dir = new File("e:\\JavaSE_code");
List list = fileList(dir, ".java");
for(File file : list){
System.out.println(file);
}
}
/**
* 定义一个获取指定过滤器条件的文件的集合。
*/
public static List fileList(File dir, String suffix){
//1.定义集合
List list = new ArrayList();
//2.定义过滤器。
FileFilter filter = new FilterBySuffix2(suffix);
/*匿名内部类也可以,不过不建议这么做。
FileFilter filter = new FileFilter(){
@Override
public boolean accept(File pathname) {
return pathname.getName().endsWith(suffix);
}
};*/
getFileList(dir, list, filter);
return list;
}
/**
* 对指定目录进行递归。
*
* 多级目录下,都要用到相同的集合和过滤器,那么不要在递归方法中定义,而是不断地进行传递。
*
* @param dir 需要遍历的目录
* @param list 用于存储符合条件的File对象
* @param filter 接收指定的过滤器
*/
public static void getFileList(File dir, List list, FileFilter filter){
//1.通过ListFiles方法,获取dir当前下的所有的文件和文件夹对象。
File[] files = dir.listFiles();
//2.遍历该数组。
for(File file : files){
//3.判断是否是文件夹。如果是,递归。如果不是,那就是文件,就需要对文件进行过滤。
if (file.isDirectory()){
getFileList(file, list, filter);
}else{
//4.通过过滤器对文件进行过滤。
if(filter.accept(file)){
list.add(file);
}
}
}
}
} 其中所用到的文件过滤器上面有,这里就不单独再列出来了。
字节流File文件对象只能操作文件或者文件夹的属性,例如文件或文件夹的创建、删除、获取文件属性(大小、所在目录等),我们最终建立文件的目的,是往文件里面存数据,File对象是做不了这个的。这时,我们就要用到IO流。
InputStream:是表示字节输入流的所有类的超类。
|--FileInputStream:从文件系统中的某个文件中获得输入字节。哪些文件可用取决于主机环境。
用于读取诸如图像数据之类的原始字节流。要读取字符流,请考虑使用 FileReader。
|--FilterInputStream:包含其他一些输入流,它将这些流用作其基本数据源,它可以直接传输数据或提供一些额外的功能。
|--BufferedInputStream:该类实现缓冲的输入流。
|--DataInputStreamStream:操作基本数据类型值的流。
|--ObjectInputStream:对象的序列化。
|--PipedInputStream:管道输出流是管道的发送端。
|--SequenceInputStream:序列流。
|--ByteArrayInputStream:操作内存数组。关闭动作无效。
|--System.in:键盘录入。
OutputStream:此抽象类是表示输出字节流的所有类的超类。
|--FileoutputStream:文件输出流是用于将数据写入File或FileDescriptor的输出流。
注意处理IO异常。续写和换行。
|--FilterOutputStream:此类是过滤输出流的所有类的超类。
|--BufferedOutputStream:该类实现缓冲的输出流。
|--PrintStream:字节打印流,保证数值的表现形式不变,实现自动刷新和换行。
|--DataOutputStream:操作基本数据类型值的流。
|--ObjectOutputStream:对象的反序列化。
|--PipedOutputStream:管道输入流应该连接到管道输出流。
|--ByteArrayOutputStream:操作内存数组。关闭动作无效。
|--System.out:控制台打印到屏幕上。

FileOutputStream
将数据写入到文件中,使用字节输出流:FileOutputStream。
在演示字节输出流之前,有以下三点需要注意:
1.输出流所关联的目的地,如果不存在,会自动创建。如果存在,则替换并覆盖。(这与File对象,如果存在、创建失败有所区别)
2.底层流资源使用完以后一定要记得释放资源。也即IO一定要写finally。
3.一定要在释放资源前先判断输出流对象是否为空。因为try中创建输出流对象失败,则fos依然是null,但是空指针没法调用close()函数释放资源,这回导致抛出NullPointerException异常。
下面演示一下创建字节输出流对象、调用输出流的写功能的代码。
package ustc.lichunchun.bytestream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputStreamDemo {
public static void main(String[] args) throws IOException {
/*
* 将数据写入到文件中。
* 使用字节输出流。
* FileOutputStream。
*/
File dir = new File("tempfile");
if(!dir.exists()){
dir.mkdir();
}
//1.创建字节输出流对象。用于操作文件,在对象初始化时,必须明确数据存储的目的地。
//输出流所关联的目的地,如果不存在,会自动创建。如果存在,则替换并覆盖。(这与File对象,如果存在、创建失败有所区别)
FileOutputStream fos = new FileOutputStream("tempfile\\fos.txt");
//2.调用输出流的写功能。
//String str = "abcde";
//byte[] buf = str.getBytes();
fos.write("abcde".getBytes());
//3.释放资源。
fos.close();
}
}
package ustc.lichunchun.bytestream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class IOExceptionDemo {
/*
* IO异常的处理方式:IO一定要写finally!
*/
public static void main(String[] args) {
File dir = new File("tempfile");
if(!dir.exists()){
dir.mkdir();
}
FileOutputStream fos = null;//如果try中内容失败,fos还是null,所以finally要先判断。
try {
fos = new FileOutputStream("tempfile\\fos.txt");
fos.write("abcdefg".getBytes());
} catch (IOException e) {
System.out.println(e.toString() + "---");
} finally {
if (fos != null) {// 一定要在释放资源前先判断!
try {
fos.close();
} catch (IOException e) {
throw new RuntimeException("关闭失败" + e);//不要把异常抛给main函数、并让主函数声明、虚拟机处理!
}
}
}
}
}package ustc.lichunchun.bytestream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class NewlineDemo {
private static final String LINE_SEPARATOR = System.getProperty("line.separator");
public static void main(String[] args) {
/*
* 续写和换行。
*
* Linux换行符是"\n"
* Windows换行符是"\r\n"
* System.getProperty("line.separator")
*/
File dir = new File("tempfile");
if(!dir.exists()){
dir.mkdir();
}
FileOutputStream fos = null;
try{
fos = new FileOutputStream("tempfile\\fos.txt",true);//传入true实现续写。
String str = LINE_SEPARATOR + "abc";
fos.write(str.getBytes());
}catch(IOException e){
System.out.println(e.toString()+"--");
}finally{
if(fos != null){
try{
fos.close();
}catch(IOException e){
throw new RuntimeException(""+e);
}
}
}
}
}那如何将已有文件的数据读取出来呢?既然是读,使用InputStream,而且是要操作文件,FileInpuStream。
为了确保文件一定在读之前是存在的,可以先将字符串路径封装成File对象。
下面演示创建文件字节读取流对象、逐个读取并打印文本文件中的字节。
package ustc.lichunchun.bytestream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class FileInputStreamDemo {
public static void main(String[] args) throws IOException {
/*
* 将已有文件的数据读取出来。
* 既然是读,使用InputStream
* 而且是要操作文件,FileInpuStream。
*/
//为了确保文件一定在读之前是存在的,将字符串路径封装成File对象。
File file = new File("tempfile\\fos.txt");
if(!file.exists()){
throw new RuntimeException("要读取的文件不存在");
}
//创建文件字节读取流对象时,必须明确与之关联的数据源。
FileInputStream fis = new FileInputStream(file);
//调用读取流对象的读取方法。read();
/*
int by1 = fis.read();
System.out.println("by1 = "+by1);//97
int by2 = fis.read();
System.out.println("by2 = "+by2);//98
int by3 = fis.read();
System.out.println("by3 = "+by3);//99
int by4 = fis.read();
System.out.println("by4 = "+by4);//-1
int by5 = fis.read();
System.out.println("by5 = "+by5);//-1
*/
int by = 0;
while((by = fis.read()) != -1){
System.out.println(by);
}
//关闭资源。
fis.close();
}
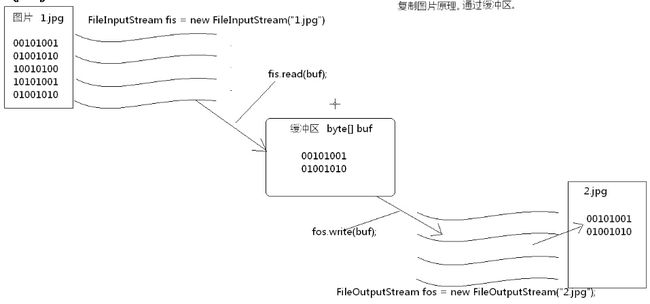
}所以我建议使用下面的这第二种字节流读取方式:创建一个缓冲区字节数组,大小自定义,
然后调用FileInputStream的read(byte[])方法,这样一来,效率会提升不少。
建议这里介绍的三种方法中,选择此种方法。当然,最好是用BufferedInputStream,这我稍后便会阐述。
package ustc.lichunchun.bytestream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class FileInputStreamDemo2 {
private static final int DEFAULT_SIZE = 1024*1024*2;//2MB 缓冲区
public static void main(String[] args) {
//演示第二种读取方式。read(byte[]); --> 第二种方式较好!
File file = new File("tempfile\\fos.txt");
if(!file.exists()){
throw new RuntimeException("要读取的文件不存在");
}
FileInputStream fis = null;
try{
fis = new FileInputStream(file);//流与文件关联
//创建一个缓冲区字节数组。
byte[] buf = new byte[DEFAULT_SIZE];//缓冲区大小一般设置为1024的整数倍。
//调用read(byte[])方法
/*
int len = fis.read(buf);//len记录的是往字节数组里存储的字节个数
System.out.println(len + "..." + new String(buf,0,len));//2...ab
int len1 = fis.read(buf);
System.out.println(len1 + "..." + new String(buf,0,len1));//1...c
int len2 = fis.read(buf);
System.out.println(len2 + "..." + new String(buf));//-1...cb
*/
int len = 0;
while((len = fis.read(buf)) != -1){
System.out.println(new String(buf,0,len));
}
}catch(IOException e){
//一般将异常信息写入到日志文件中,进行记录。
}finally{
if(fis != null){
try{
fis.close();
}catch(IOException e){
//一般可以throw new RuntimeException异常。或者将异常信息写入到日志文件中,进行记录。
}
}
}
}
}
package ustc.lichunchun.bytestream;
import java.io.FileInputStream;
import java.io.IOException;
public class FileInputStreamDemo3 {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("tempfile\\fos.txt");
System.out.println(fis.available());//可以获取与之关联文件的字节数。可以理解为file.length();
byte[] buf = new byte[fis.available()];//创建了一个和文件大小一样的缓冲区,刚刚好。不建议用。
fis.read(buf);
String s = new String(buf);
System.out.println(s);
fis.close();
}
}思路:
读取源数据,将数据写到目的中。用到了流,操作设备上的数据。
读,用到输入流;写,用到输出流。而且操作的还是文件。需要用到字节流中操作文件的流对象。
package ustc.lichunchun.copy;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyTextTest {
public static void main(String[] args) throws IOException {
/*
* 需求:复制一个文件。
* 思路:
* 读取源数据,将数据写到目的中。
* 用到了流,操作设备上的数据。
* 读,用到输入流;写,用到输出流。
* 而且操作的还是文件。需要用到字节流中操作文件的流对象。
*/
copyText();
}
public static void copyText() throws IOException {
//1.创建一个输入流和源数据相关联。
FileInputStream fis = new FileInputStream("复制文本文件图解.bmp");
//2.创建一个输出流,并通过输出流创建一个目的。
FileOutputStream fos = new FileOutputStream("tempfile\\io_copy.bmp");
//读一个,写一个。-->这种方式非常不好,效率太低,千万别用此方法。
int by = 0;
while((by = fis.read()) != -1){
fos.write(by);
}
fos.close();
fis.close();
}
}
package ustc.lichunchun.copy;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyTextByBufTest {
public static void main(String[] args) {
copyTextByBuf();
}
public static void copyTextByBuf() {
FileInputStream fis = null;
FileOutputStream fos = null;
try{
fis = new FileInputStream("tempfile\\fos.txt");
fos = new FileOutputStream("tempfile\\copy_fos.txt");
//创建缓冲区
byte[] buf = new byte[1024];//1KB,这就是缓冲区.
//定义记录字符个数的变量
int len = 0;
//循环读写
while((len = fis.read(buf)) != -1){
fos.write(buf, 0, len);
}
}catch(IOException e){
//异常日志。
}finally{
if(fos != null){
try {
fos.close();
} catch (IOException e) {
//异常日志。
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
//异常日志。
}
}
}
}
}前面在FileInputStream小节中,我已经介绍了利用自定义缓冲区实现高效的字节流读取。
java也考虑到了这一点,在底层将缓冲区封装成了对象,实际上就是在一个类中封装了数组,
对流所操作的数据进行缓存。缓冲区的作用就是为了提高操作数据的效率。
这样可以避免频繁的在硬盘上寻道操作。缓冲区创建时,必须有被缓冲的流对象与之相关联。
原理图解:

需求:利用缓冲区完成复制图片的例子。
package ustc.lichunchun.bytestream.buffer;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyPicByBufferDemo {
public static void main(String[] args) throws IOException {
/*
* java将缓冲区封装成了对象,实际上就是在一个类中封装了一个数组,对流所操作的数据进行缓存。
* 缓冲区的作用就是为了提高操作数据的效率。这样可以避免频繁的在硬盘上寻道操作。
* 缓冲区创建时,必须有被缓冲的流对象。
*
* 利用缓冲区完成复制图片的例子。
*/
copyPicByBuffer();
}
public static void copyPicByBuffer() throws IOException {
//演示缓冲区。
//1.创建具体的流对象。
FileInputStream fis = new FileInputStream("tempfile\\1.jpg");
//2.让缓冲区与指定流相关联。
//对流中的数据进行缓冲。位于内存中的缓冲区的数据读写速度远远大于硬盘上的读写。
BufferedInputStream bufis = new BufferedInputStream(fis);//缓冲区默认读8MB字节
FileOutputStream fos = new FileOutputStream("tempfile\\copy_1.jpg");
BufferedOutputStream bufos = new BufferedOutputStream(fos);
byte[] buf = new byte[1024];
int len = 0;
while((len = bufis.read(buf)) != -1){
bufos.write(buf, 0, len);//使用缓冲区的写入方法将数据先写入到缓冲区中。
bufos.flush();//将缓冲区的数据刷新到底层目的地中。(即使不写,缓冲区满了,java也会自动刷新 )
}
//关闭缓冲区,其实关闭的就是被缓冲的流对象。
bufos.close();
bufis.close();
}
}在计算机中,无论是文本,还是图片、mp3、视频等,所有数据最终都是以字节形式存在。
字节流:能操作以字节为单位的文件的流对象。所以字节流能操作计算机上的一切数据。
package ustc.lichunchun.readcn;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class ReadCNDemo {
public static void main(String[] args) throws IOException {
/*
* 字节流操作中文数据。
*
* String --> String.getbyte() --> byte[] --> FileOutputStream.write(byte[])
* 这里我们使用的是String类的getBytes()方法按平台默认字符集,编码字符串为字节数组,
* 用以将中文字符串按字节流输出到硬盘文件中,并以字节形式存储。
*
* byte[] --> new String(byte[]) --> String --> System.out.println()
* 为了在控制台能够打印出中文字符,而不是逐个字节打印出int值,
* 我们又使用String类的String(byte[] bytes,int offset,int length)构造函数按平台默认字符集,解码字节数组为字符串。
*
* FileInputStream --> read() --> FileOutputStream --> write()
* 如果只是将中文文本文件拷贝一份,或者复制其他类型的媒体文件诸如图片音视频等,我们则不必关心各种类型文件所使用的各种编码方式,
* 只需要通过输入字节流逐个读取硬盘上文件的字节,然后在通过输出字节流输出到相应目的地文件中即可,相应的特定软件会自行解码并打开的。
*
* BufferedXxxStream --> 为了高效。
*
* 在计算机中,无论是文本,还是图片、mp3、视频等,所有数据最终都是以字节形式存在。
* 字节流:能操作以字节为单位的文件的流对象。
* 所以字节流能操作计算机上的一切数据。
* 而字符流只能操作以字符为单位的文本数据。
*
* 注意:
* windows简体中文系统下,默认中文编码表是GBK,其中编码中文时,是两个字节对应一个中文字符。
*/
//writeCNText();
readCNText();
}
public static void writeCNText() throws IOException {
FileOutputStream fos = new FileOutputStream("tempfile\\cn.txt");
fos.write("你A好".getBytes());//按照默认编码表GBK编码,将String编码为byte[]。(System.getProperty("file.encoding")获取)
//getBytes():使用平台的默认字符集将此 String编码为 byte 序列,并将结果存储到一个新的 byte 数组中。
fos.close();
}
public static void readCNText() throws IOException {
FileInputStream fis = new FileInputStream("tempfile\\cn.txt");
/*
//这里对中文文本文件逐个字节读取,并打印到控制台,肯定是不行的,编码方式决定了不可以这样。
int by = fis.read();
System.out.println(by);//196
int by1 = fis.read();
System.out.println(by1);//227
int by2 = fis.read();
System.out.println(by2);//65
int by3 = fis.read();
System.out.println(by3);//186
int by4 = fis.read();
System.out.println(by4);//195
int by5 = fis.read();
System.out.println(by5);//-1
*/
//读取中文,按照字节形式。但是一个中文GBK码表中是两个字节。
//而字节流的read方法一次只读一个字节。如何可以在控制台获取到一个中文呢?
//别读一个就操作,多读一些存起来,再操作。存到字节数组中,将字节数组转成字符串就哦了。
//因为String类有一个构造函数可以通过使用平台的默认字符集解码指定的 byte数组,构造一个新的 String。
byte[] buf = new byte[1024];
int len = 0;
len = fis.read(buf);
String s = new String(buf,0,len);//将字节数组转成字符串,而且是按照默认的编码表(GBK)进行解码。
System.out.println(s);
/*
//字节是硬盘文件存储基本单位,所以复制文件问题中我不需关心媒体或者中文字符到底几个字节,
//我就逐个字节往另一个相同类型文件里存,至于不同编码表,那是打开特定文件的软件的问题,与字节流操作无关。
FileOutputStream fos = new FileOutputStream("tempfile\\copy_cn.txt");
int by = 0;
while((by = fis.read())!=-1){
fos.write(by);
}
//字节流引发的小问题:
//用字节流读取中文太费劲,如果中英文穿插,中文2字节,英文1字节,
//如果每次只读一个中文字符new byte[2],然后我就转成字符串打印,
//"你"字符可以打印出来,但是A和"好"字符的前一半连在一起出来,就出错了。
//也许你会说,我可以加一个判断中英文编码的条件,但是这样做太麻烦。
//像上面我们做的那种打印中文文本的程序,需要读取字节数据,再自己调用String构造函数解码,也太麻烦,并且如何解码也不知道。
//所以我们就考虑用新的流:字符流。
byte[] buf = new byte[2];
int len = 0;
while((len = fis.read(buf)) != -1){
System.out.println(new String(buf,0,len));
}
*/
fis.close();
}
}正如上面这段代码最后一段的注释中所说,对于纯文本数据的文件,用字节流操作中英文数据时由于编码问题,不同语言的字符对应的字节数不同,会显得比较繁琐。这时我们就该考虑字符流了。但是在这之前,我先把调研到的编码相关背景知识总结分享一下。
编码表
在计算机中,无论是文本,还是图片、mp3、视频等,所有数据最终都是以字节形式存在。字节流:能操作以字节为单位的文件的流对象。所以字节流能操作计算机上的一切数据。文本数据、媒体数据等,什么数据字节流都可以搞定。而字符流只能操作以字符为单位的文本数据。
主要的编码表有:ASCII、ISO8859-1、GB2312、GBK、GB18030、Unicode、UTF-8(标识头信息)等。如果想要获取到当前系统使用的默认编码表,可以使用如下代码获取系统平台默认字符集:System.getProperty("file.encoding")--> GBK。
ASCII:美国标准信息交换码,0打头,用一个字节的后7位表示,读一个字节。
ISO8859-1:欧洲码表,用一个字节的8位表示,1打头代表拉丁文,读一个字节。
GB2312:中文编码表,两个字节都是1打头,读两个字节
GBK:扩展版中文编码表,第一个字节1打头,读两个字节10101011 01010110 打头都是1,读到1打头,就读两个字节,再去查GBK表。
Unicode:国际标准码,重新编排码表,统一规定所有文字都是两个字节,Java语言使用的就是unicode。弊端:能用一个字节表示的,都用两个字节装,浪费空间。
UTF-8:对Unicode优化,能用一个字节表示的就不用两个字节,最多用三个字节来表示一个字符。读完相应若干字节后,再去查表。01111010 单字节字符,0打头,读完单字节就去查表;11001010 10101010 两个字节字符,110打头第一个字节,10打头第二个字节,读完两个字节再去查表;11100101 10101001 10010001三个字节字符,1110打头第一个字节,10打头第二、三个字节,读完三个字节再去查表。
字符流为什么不能复制图片?
字符流读完字节数据后,并没有直接往目的地里面写,而是去查表了。但是读到的媒体性字节数据,都有自身千变万化的编码方式,在码表里没有对应内容。那么它就会在表的未知字符区域随便找一些数据写到目的地中,这时,目的数据和源数据就不一致,就不能图片编辑器解析为图片。所以,字符流不能用来操作媒体文件。
编解码详述
编码:字符串 --> 字节数组。(默认都是按照windows系统本地的编码GBK存储的)
解码:字节数组 --> 字符串。
代码示例:
package ustc.lichunchun.encode;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
public class EncodeDemo {
public static void main(String[] args) throws IOException {
/*
* 字符串-->字节数组:编码。
* 字节数组-->字符串:解码。
*
* 字符串的编码,默认都是按照windows系统本地的编码GBK存储的。
* 获取平台默认字符集:System.getProperty("file.encoding");
* (注:字符类型char,在java底层是以unicode码完成的,作为中间转换码,可以忽略不用考虑。)
*
* 你好:
* GBK: -60 -29 -70 -61 一个中文两个字节,每个字节打头的都是1,所以都是负数。
* UTF-8: -28 -67 -96 -27 -91 -67
*
* 1.如果你编码错了,解不出来。
* 2.如果编对了,解错了,有可能还有救。
* 再次按错误的码表编码,获取原字节,然后再选择另一种码表解码即可。
*
* 应用:tomcat服务器提供的Web服务使用的是iso8859-1在服务器端编解码。
*/
test1();//编解码示例
//test2();//有时有救
//test3();//有时没救
//test4();//移动联通问题
}
public static void test1() throws UnsupportedEncodingException {
String str = "你好";
//编码。
//byte[] buf = str.getBytes();//使用平台默认字符集gbk编码
//byte[] buf = str.getBytes("gbk");
byte[] buf = str.getBytes("utf-8");
//printBytes(buf);
//解码。
//String s1 = new String(buf);//使用平台默认字符集gbk解码
//String s1 = new String(buf, "gbk");
String s1 = new String(buf, "utf-8");
System.out.println("s1 = "+s1);
}
public static void test2() throws IOException {
String str = "你好";
byte[] buf = str.getBytes("gbk");//11000100 11100011 10111010 11000011
String s1 = new String(buf, "iso8859-1");//iso都是单字节,所以没有改变原字节。
System.out.println("s1 = "+s1);//????
byte[] buf2 = s1.getBytes("iso8859-1");//获取原字节:11000100 11100011 10111010 11000011
String s2 = new String(buf2,"gbk");
System.out.println("s2 = "+s2);//你好
}
public static void test3() throws IOException {
String str = "你好";//"嘻嘻"、"谢谢"
byte[] buf = str.getBytes("gbk");
String s1 = new String(buf, "utf-8");//没有识别出来。以?替代。
byte[] buf1 = s1.getBytes("gbk");
System.out.println("s1 = "+s1);//???、????、ππ
byte[] buf2 = s1.getBytes("utf-8");//获取原字节。只有"谢谢"可以得到。
printBytes(buf2);//-17 -65 -67 -17 -65 -67 -17 -65 -67
//-17 -65 -67 -17 -65 -67 -17 -65 -67 -17 -65 -67
//-48 -69 -48 -69
String s2 = new String(buf2,"gbk");
System.out.println("s2 = "+s2);
/*
见API文档关于utf-8修改版的编码规范。
你好:
gbk编码:11000100 11100011 10111010 11000011
utf-8解码:???
utf-8编码:11101111 10111111 10111101 11101111 10111111 10111101 11101111 10111111 10111101
嘻嘻:
gbk编码:11001110 11111011 11001110 11111011
utf-8解码:????
utf-8编码:11101111 10111111 10111101 11101111 10111111 10111101 11101111 10111111 10111101 11101111 10111111 10111101
谢谢:
gbk编码:11010000 10111011 11010000 10111011
utf-8解码:ππ
utf-8编码:11010000 10111011 11010000 10111011
所以最后再对utf-8编码后的字节,用gbk解码,"你好"、"嘻嘻"会出现乱码。
*/
}
public static void test4() throws IOException {
String str = "联通";
byte[] buf = str.getBytes("gbk");
for(byte b : buf){
System.out.println(Integer.toBinaryString(b&255));
}
/*
11000001
10101010
11001101
10101000
问题:
在桌面上创建两个txt文本文件,1.txt写上"移动",2.txt写上"联通"。
发现再次打开1.txt完好,2.txt出现乱码。这是为什么呢?
回答:
记事本保存时,会按照windows平台默认GBK编码文本文件并保存。(ANSI也是本地默认字符集的意思)
这可以通过2.txt文本文件大小为4个字节得知。所以编码没有问题。
但是通过上面的小程序可以发现,"联通"的二进制码形式上符合utf-8的编码风格规范,
所以记事本再次打开时,会按照utf-8的格式解码这个文本文件,所以会出现乱码。
*/
}
public static void printBytes(byte[] buf) {
for(byte b : buf){
System.out.print(b+" ");
}
System.out.println();
}
}上述代码示例中的test2()函数,我们有如下的处理过程:
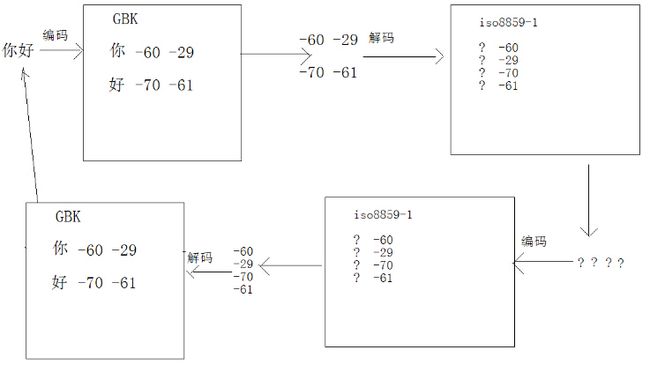
这种原理在实际中,也有应用,比如tomcat服务器端,就是有这样的转换:

练习:按照字节数截取一个字符串。"abc你好"如果截取到半个中文,舍弃。比如截取4字节,abc,截取5个字节abc你。定义功能实现。(友情提示:GB2312编码的一个中文是两个字节,而且两个字节的最高位都是1,也就是说是一个负数。)
思路:
1.提示告诉我中文两个字节都是负数。
2.判断截取的最后一个字节是否是负数。如果不是,直接截取;如果是,就往回判断,前一个是否是负数。并记录住负数的个数。如果连续的负数有奇数个,舍弃最后一个字节;如果连续的负数是偶数个,不舍弃。
package ustc.lichunchun.encode;
import java.io.IOException;
public class Test {
public static void main(String[] args) throws IOException {
/*
* 按照字节数截取一个字符串。"abc你好"如果截取到半个中文,舍弃。比如截取4字节,abc,截取5个字节abc你。
* 定义功能实现。
* 友情提示:GB2312编码的一个中文是两个字节,而且两个字节的最高位都是1,也就是说是一个负数。
*
* 思路:
* 1.提示告诉我中文两个字节都是负数。
* 2.判断截取的最后一个字节是否是负数。
* 如果不是,直接截取。
* 如果是,就往回判断,前一个是否是负数。并记录住负数的个数。如果连续的负数有奇数个,舍弃最后一个字节。
* 如果连续的负数是偶数个,不舍弃。
*
* 拓展1:GBK扩容后,中文既有负数,又有正数。它只保证第一个字节是负数,第二个字节不保证。此程序依然适用。
* 拓展2:如果将字符串编码成utf-8格式,咋办?这时,一个中文3个字节。
*/
//字符串转成字节数组。
String str = "a琲bc你好d琲e";
byte[] buf = str.getBytes("utf-8");
for(int i = 1; i <= buf.length; i++){
String temp = cutStringByCount2(str,i);
System.out.println("截取"+i+"个字节是:"+temp);
}
}
public static String cutStringByCount1(String str, int len) throws IOException {
//1.将字符串转成字符数组。因为要判断截取的字节是否是负数,所以要先有字节。
byte[] bytes = str.getBytes("gbk");
//2.定义计数器,记录住负数的个数。
int count = 0;
//3.对字节数组进行遍历。应该从截取长度的最后一个字节开始判断,并往回判断。
for(int x = len-1; x >= 0; x--){
//4.在遍历过程中,只要满足负数就进行计数。只要不是负数,直接结束遍历。
if(bytes[x]<0){
count++;
}else{
break;
}
}
//5.对遍历后,计数器的值进行判断,奇数,就舍弃最后字节并将字节数组转成字符串。
//偶数,不舍弃,将字节数组转成字符串。
if(count%2 == 0)
return new String(bytes, 0, len);
else
return new String(bytes, 0, len-1);
}
public static String cutStringByCount2(String str, int len) throws IOException {
byte[] bytes = str.getBytes("utf-8");
int count = 0;
for(int x = len-1; x >= 0; x--){
if(bytes[x] < 0){
count++;
}else{
break;
}
}
if(count%3 ==0)
return new String(bytes, 0, len, "utf-8");
else if(count%3 == 1)
return new String(bytes, 0, len-1, "utf-8");
else
return new String(bytes, 0, len-2, "utf-8");
}
}字符流
字符流只能用来操作字符数据--文本。但是由于字符流封装了编码部分,所以操作字符比较方便。字符流=字节流+编码表。
Reader:用于读取字符流的抽象类。子类必须实现的方法只有 read(char[],int,int)和 close()。
|--BufferedReader:从字符输入流中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。
可以指定缓冲区的大小,或者可使用默认的大小。大多数情况下,默认值就足够大了。
|--LineNumberReader:跟踪行号的缓冲字符输入流。此类定义了方法 setLineNumber(int)和 getLineNumber(),
它们可分别用于设置和获取当前行号。
|--InputStreamReader:是字节流通向字符流的桥梁:它使用指定的 charset读取字节并将其解码为字符。
它使用的字符集可以由名称指定或显式给定,或者可以接受平台默认的字符集。
|--FileReader:用来读取字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是适当的。
要自己指定这些值,可以先在 FileInputStream上构造一个InputStreamReader。
|--CharArrayReader:没有调用系统流,只是操作内存中的数组。
|--StringReader:没有调用系统流,只是操作内存中的数组。
Writer:写入字符流的抽象类。子类必须实现的方法仅有 write(char[],int,int)、flush()和 close()。
|--BufferedWriter:将文本写入字符输出流,缓冲各个字符,从而提供单个字符、数组和字符串的高效写入。
|--OutputStreamWriter:是字符流通向字节流的桥梁:可使用指定的 charset将要写入流中的字符编码成字节。
它使用的字符集可以由名称指定或显式给定,否则将接受平台默认的字符集。
|--FileWriter:用来写入字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。
要自己指定这些值,可以先在 FileOutputStream上构造一个OutputStreamWriter。
|--PrintWriter:字符打印流,保证数值的表现形式不变,可以对字节流、字符流自动刷新并换行。
|--CharArrayWriter:没有调用系统流,只是操作内存中的数组。
|--StringWriter:没有调用系统流,只是操作内存中的数组。

注意:只要是输出字符流,都有查表后的缓冲区。所以它的write()方法后面一定要跟随flush()刷新操作!(即使没写但运行通过,那也是因为close()封装了flush方法)
转换流
通过编码表的演示,读者应该很容易发现针对纯文本文件,用字符流的方式处理更为方便。那就很自然的考虑到,我如何才能将字节流转换成字符流呢?下面我就来介绍一下字节和字符,二者之间转换的桥梁——转换流。
转换流:
字节-->字符:解码(看不懂的-->看得懂的):InputStreamReader-->字节通向字符的桥梁,将读到的若干字节进行解码。
字符-->字节:编码(看得懂的-->看不懂的):OutputStreamWriter-->字符通向字节的桥梁,将字符编码成若干字节。
记住:只要是字符输出流,都有查表后的缓冲区。所以它的write()方法后面一定要跟随flush()刷新操作!
缓冲的原因:
每次调用 write方法都会导致在给定字符(或字符集)上调用编码转换器,在写入底层输出流之前,得到的这些字节将在缓冲区中累积。中文最终变成字节才能出去,中文变成什么字节呢?识别中文的码表不止一个,没有指定,会按默认码表GBK。这意味着,会把中文先临时存储起来,去查相应的码表,再把查码表得到的字节存起来缓冲一下,再刷新写出去。之前学的字节流,是因为不用进行查码表、缓冲转换,字节该什么样就什么样,直接读写即可。现在需要拿着字符数据去查码表,把查到的字节数据存起来,再写出去。所以,有了缓冲区,就得做刷新。
转换流代码示例:
package ustc.lichunchun.charstream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class TransStreamDemo {
public static void main(String[] args) throws IOException {
/*
* 需求:通过字符流读取中文数据。
*
* 字符流 = 字节流 + 编码表。
*
* Java内置的码表是Unicode编码。见encode包有关编码解码的代码示例。
*
* 转换流:
* 字节-->字符:解码(看不懂的-->看得懂的):InputStreamReader
* 字符-->字节:编码(看得懂的-->看不懂的):OutputStreamWriter
*/
//字节通向字符的桥梁,将读到的若干字节进行解码。
//readCnText();
//字符通向字节的桥梁,将字符编码成若干字节。
writeCNText();
}
public static void readCnText() throws IOException {
//1.操作字节流的字符流对象,必须先有字节流。
FileInputStream fis = new FileInputStream("tempfile\\cn.txt");
//2.建立字节向字符的桥梁。(解码)
InputStreamReader isr = new InputStreamReader(fis);
int ch = isr.read();//注意这里read()读取的是单个字符,所以要强转(char)int,才可以打印在控制台
System.out.println((char)ch);//(char)20320 = '你'
int ch1 = isr.read();
System.out.println((char)ch1);//(char)65 = 'A'
int ch2 = isr.read();
System.out.println((char)ch2);//(char)22909 = '好'
int ch3 = isr.read();
System.out.println(ch3);//(char)-1 = '?' , 虚拟机返回-1就代表到达文件末尾 了。
isr.close();
}
public static void writeCNText() throws IOException {
//1.创建字节流对象。
FileOutputStream fos = new FileOutputStream("tempfile\\GBK.txt");
//2.创建字符通向字节的桥梁。
OutputStreamWriter osw = new OutputStreamWriter(fos);
//3.使用osw的write方法直接写中文字符串。因为需要拿着字符数据去查表,所以写入字节数据前,都会存储到缓冲区中。
osw.write("你A好");
//4.需要刷新该字符流的缓冲区。将查表得到的字节数据写到fos流中,然后通过Windows底层资源写入到GBK.txt中。
//osw.flush();
//5.关闭此流前,会先刷新一下。
osw.close();
/*
close()底层实现:
void close(){
flush();
close();
}
*/
}
}flush()刷新完,流可以继续使用;
close()刷新完,流直接关闭,流结束了,无法再用。再用,会报Stream closed异常。
转换流的好处:可以指定编码表。
什么时候使用转换流呢?
1.操作文本数据。
2.需要指定编码表。
下面我们使用不同的编码表来演示转换流:
package ustc.lichunchun.charstream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class TransStreamDemo2 {
public static void main(String[] args) throws IOException {
/*
* 使用不同的编码表演示转换流。
*
* 字节 -->字符: InputStreamReader
* 字符 -->字节:OutputStreamWriter
*
*/
//writeText();
readText();
}
public static void writeText() throws IOException {
FileOutputStream fos = new FileOutputStream("tempfile\\u8.txt");
OutputStreamWriter osw = new OutputStreamWriter(fos);//使用默认的编码表GBK。4字节。
osw = new OutputStreamWriter(fos, "UTF-8");//6字节。
osw.write("你好");//记住会有查表、缓冲区的动作
osw.close();
}
public static void readText() throws IOException {
FileInputStream fis = new FileInputStream("tempfile\\u8.txt");
InputStreamReader isr = new InputStreamReader(fis);//默认码表GBK。
isr = new InputStreamReader(fis, "UTF-8");
int ch1 = isr.read();
System.out.println("ch1 = "+(char)ch1);//浣--> 你
int ch2 = isr.read();
System.out.println("ch2 = "+(char)ch2);//犲--> 好
int ch3 = isr.read();
System.out.println("ch3 = "+ch3);//ソ--> -1
isr.close();
}
}二者是转换流的子类,专门用于操作文本文件的字符流对象。
FileWriter --> 用来写入字符文件的便捷类。
FileReader--> 用来读取字符文件的便捷类。
局限性:
1.只能操作纯文本文件。
2.只能使用默认编码。
由字符流的体系结构图我们可以清楚地看到,FileReader类继承自InputStreamReader转换流类。理由是:想要操作文本文件,必须要进行编码转换,而编码转换动作转换流都完成了,所以操作文件的流对象只要继承自转换流就可以读取一个字符了。但是子类有一个局限性,就是子类中使用的编码是固定的,是本机默认的编码表,对于简体中文版的系统默认码表是GBK。
FileReader fr = new FileReader("a.txt");
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt"),"gbk");如果需要制定码表,必须用转换流。
转换流 = 字节流+编码表。
转换流的子类File = 字节流 + 默认编码表。
凡是操作设备上的文本数据,涉及编码转换,必须使用转换流。
package ustc.lichunchun.charstream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class SubTransStreamDemo {
public static void main(String[] args) throws IOException {
/*
* 转换流的子类,专门用于操作文本文件的字符流对象。
* FileWriter --> 用来写入字符文件的便捷类。
* FileReader --> 用来读取字符文件的便捷类。
*/
//writeText();
readText();
}
public static void writeText() throws IOException {
//1.创建一个用于操作文件的字符输出流对象。
FileWriter fw = new FileWriter("tempfile\\fw.txt");//内部使用了默认的码表。而且只能操作文件。
//等效于:
//FileOutputStream fos = new FileOutputStream("tempfile\\fw.txt");
//OutputStreamWriter osw = new OutputStreamWriter(fos);
fw.write("你好");//记住会查表、缓冲区.
fw.close();
}
public static void readText() throws IOException {
FileReader fr = new FileReader("tempfile\\fw.txt");
//等效于:
//FileInputStream fis = new FileInputStream("tempfile\\fw.txt");
//InputStreamReader isr = new InputStreamReader(fis);
int ch = 0;
while((ch = fr.read()) != -1){
System.out.println((char)ch);//发现一次读取一个字符比较慢,接下来我们考虑使用缓冲区读取字符数组。
}
fr.close();
}
}练习:使用自定义字符流缓冲区,复制文本文件示例。
注意:
1.字节流使用的缓冲区是字节数组,字符流使用的缓冲区是字符数组。
2.仅为复制文件,建议使用通用类型的字节流;如果是纯文本文件,并且有多余操作,建议使用字符流。
package ustc.lichunchun.charstream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class SubTransStreamDemo2 {
public static void main(String[] args) throws IOException {
/*
* 使用字符流缓冲区,复制文本文件示例。
*
* 字节流使用的缓冲区是字节数组,
* 字符流使用的缓冲区是字符数组。
*
* 如果仅仅是为了复制,建议使用字节流。
* 但是一旦涉及到中文字符的操作,用字符流较好,
* 比如在while循环体内对读到的文本字符数据的"你"字替换为"我"字,字节流就办不到了。
*
*/
copyText();
}
public static void copyText() throws IOException {
//1.明确数据源,定义字符读取流和数据源关联。
FileReader fr = new FileReader("IO流_2.txt");
//2.明确数据目的,定义字符输出流,创建存储数据的目的。
FileWriter fw = new FileWriter("tempfile\\copy_2.txt");
//3.创建自定义缓冲区。
char[] buf = new char[1024];//char占两个字节,所以声明了一个2KB的数组。
int len = 0;
while((len = fr.read(buf)) != -1){
fw.write(buf, 0, len);
}
fw.close();
fr.close();
}
}BufferedWriter、BufferedReader
BufferedXxx缓冲字符流存在的好处是:为了高效,并且有readLine()、newLine()方法。首先演示一下演示字符流的缓冲区读写操作。
package ustc.lichunchun.charstream.buffer;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class CharStreamBufferDemo {
public static void main(String[] args) throws IOException {
/*
* 演示字符流的缓冲区。
* BufferedReader
* BufferedWriter
*
* BufferedXxx缓冲字符流存在的好处是:
* 为了高效,并且有readLine()、newLine()方法。
*/
//writeTextByBuffered();
readTextByBuffered();
}
public static void writeTextByBuffered() throws IOException {
//1.明确目的。
FileWriter fw = new FileWriter("tempfile\\bufw.txt");
//2.创建缓冲区对象。明确要缓冲的流对象。
BufferedWriter bufw = new BufferedWriter(fw);
/*
bufw.write("abc");//写入到缓冲区。
bufw.write("\r\nhello");
换行的简便写法:newLine(),为什么给封装了呢?
因为文本文件相比于媒体文件最大的特点就是换行,文本体现的形式可以一行一行的体现,
其他类型文件不具备,所以把换行操作封装了。
bufw.newLine();//System.getProperty("line_separator");
*/
for(int x = 1; x <= 4; x++){
bufw.write(x + "abc");
bufw.newLine();
bufw.flush();
}
bufw.close();
}
public static void readTextByBuffered() throws IOException {
FileReader fr = new FileReader("tempfile\\bufw.txt");
BufferedReader bufr = new BufferedReader(fr);
//因为只有文本具备行的特性,所以又有了一个只针对文本的新方法:readLine();不包含终止符'\n'、'\r'。
//问题:test.txt中有几个字符?答案:9 --> \r \n两个字符。
/*
String line1 = bufr.readLine();
System.out.println(line1);//1abc
String line2 = bufr.readLine();
System.out.println(line2);//2abc
String line3 = bufr.readLine();
System.out.println(line3);//3abc
String line4 = bufr.readLine();
System.out.println(line4);//4abc
String line5 = bufr.readLine();
System.out.println(line5);//null-->和以前返回-1不一样了。
*/
String line = null;
while((line = bufr.readLine()) != null){
System.out.println(line);
}
bufr.close();
}
}思路:读取键盘录入,不建议使用Scanner类,因为Scanner = 流 + 正则表达式,它的方法都是按照某种规则在读取数据。System.in对应的是字节流对象,而用户通过键盘输入的是文本数据,所以转换成字符流比较合适,通过桥梁。一次读取键盘录入的一行文本,应该使用下面这两句。
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
bufr.readLine();练习1:建立指定文件的清单文件。将指定目录下的指定文件(包含子目录)的绝对路径写入到一个文件中,该文件就作为指定文件的清单文件。
其中所用到的文件过滤器,上面已经有提及并解决,这里只把过滤器代码贴出来,方便参阅。
package ustc.lichunchun.test;
import java.io.File;
import java.io.FileFilter;
public class FilterBySuffix implements FileFilter {
private String suffix;
public FilterBySuffix(String suffix) {
super();
this.suffix = suffix;
}
@Override
public boolean accept(File pathname) {
return pathname.getName().endsWith(suffix);
}
}
package ustc.lichunchun.test;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Test {
public static void main(String[] args) throws IOException {
/*
* 练习1:建立指定文件的清单文件。将指定目录下的指定文件(包含子目录)的绝对路径写入到一个文件中。
* 该文件就作为指定文件的清单文件。
* (并统计了目前.java文件的代码行数。)
*/
File dir = new File("e:\\JavaSE_code");
List list = fileList(dir, ".java");
//将集合中符合条件的文件对象的绝对路径写入到一个目标文件中。
File destFile = new File("javalist.txt");
write2File(list,destFile);
System.out.println("目前Java代码量:"+countLines(destFile)+" 行!");
}
public static void getFileList(File dir, List list, FileFilter filter){
File[] files = dir.listFiles();
for(File file : files){
if(file.isDirectory()){
getFileList(file, list, filter);
}else{
if(filter.accept(file)){
list.add(file);
}
}
}
}
public static List fileList(File dir, String suffix){
List list = new ArrayList();
FileFilter filter = new FilterBySuffix(suffix);
getFileList(dir, list, filter);
return list;
}
public static void write2File(List list, File destFile) throws IOException {
//1.需要流对象,既然是写入字符,就用字符流缓冲区。
BufferedWriter bufw =null;
try{
bufw = new BufferedWriter(new FileWriter(destFile));
//2.遍历集合。
for(File file : list){
bufw.write(file.getAbsolutePath());
bufw.newLine();
bufw.flush();
}
}finally{
if(bufw != null){
try {
bufw.close();
} catch (IOException e) {
throw new RuntimeException("关闭失败");
}
}
}
}
//统计已经写了的代码行数。
public static int countLines(File destFile) throws IOException {
int count = 0;
BufferedReader bufr = null;
try{
bufr = new BufferedReader(new FileReader(destFile));
String filename = null;
while((filename = bufr.readLine()) != null){
count += countFileLines(filename);
}
}finally{
if(bufr != null){
try {
bufr.close();
} catch (Exception e) {
throw new RuntimeException("关闭失败");
}
}
}
return count;
}
public static int countFileLines(String filename) throws IOException {
int lineCount = 0;
BufferedReader bufr = null;
try{
bufr = new BufferedReader(new FileReader(filename));
String line = null;
while((line = bufr.readLine()) != null){
lineCount++;
}
}finally{
if(bufr != null){
try {
bufr.close();
} catch (Exception e) {
throw new RuntimeException("子文件关闭失败");
}
}
}
return lineCount;
}
} 思路:
1.使用键盘录入技术。
2.操作的是学生信息,信息很多,需要将信息封装成学生对象。
3.总分由高到低,需要排序,需要对学生对象中的总分排序。需要将多个学生对象进行容器存储。哪个容器呢?TreeSet集合。
4.将容器中的学生对象的信息写入到文件中。
使用到的学生类如下:
package ustc.lichunchun.test.domain;
public class Student implements Comparable{
private String name;
private int ma,cn,en;
private int sum;
public Student() {
super();
}
public String getName() {
return name;
}
public Student(String name, int ma, int cn, int en) {
super();
this.name = name;
this.ma = ma;
this.cn = cn;
this.en = en;
this.sum = ma+cn+en;
}
public void setName(String name) {
this.name = name;
}
public int getMa() {
return ma;
}
public void setMa(int ma) {
this.ma = ma;
}
public int getCn() {
return cn;
}
public void setCn(int cn) {
this.cn = cn;
}
public int getEn() {
return en;
}
public void setEn(int en) {
this.en = en;
}
public int getSum() {
return sum;
}
public void setSum(int sum) {
this.sum = sum;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + cn;
result = prime * result + en;
result = prime * result + ma;
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + sum;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (cn != other.cn)
return false;
if (en != other.en)
return false;
if (ma != other.ma)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (sum != other.sum)
return false;
return true;
}
@Override
public int compareTo(Student o) {
int temp = this.sum - o.sum;
return temp==0?this.name.compareTo(o.name):temp;
}
} 1.对于读取键盘录入操作,一定要定义结束标记。(当然,实际开发中,不会要求键盘录入,数据都是网络获取的。)
2.关闭键盘录入须知:如果后面不再使用键盘录入,是可以关闭的;如果后面还要使用,就不要关闭,继续通过System.in就可以获取。因为System.in流是“一次性”的,一旦关闭,本次程序就无法再次使用。
3.由于TreeSet按照默认比较器定义大小从小到大比较,所以需要使用Collections工具类的reverseOrder()方法将比较器逆序。
package ustc.lichunchun.test.tool;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
import ustc.lichunchun.test.domain.Student;
public class GetInfoTool {
/**
* 获取所有学生对象集合,按照学生对象的自然排序。
* @throws IOException
*/
//重载。
public static Set getStudent() throws IOException{
return getStudent(null);
}
/**
* 获取所有学生对象集合,按照指定的比较器排序。
* @param comp
* @return
* @throws IOException
*/
public static Set getStudent(Comparator comp) throws IOException{
//创建一个容器存储学生对象。
Set set = null;
//如果比较器存在,就创建带有比较器的对象。
if(comp != null){
set = new TreeSet(comp);
}else{
set = new TreeSet();
}
//1.键盘输入。
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
//2.获取键盘录入信息。
String line = null;
while((line = bufr.readLine())!=null){//readLine()是阻塞式方法,线程停在那没有动,等待键盘录入。
//键盘录入要加结束标记。
if("over".equals(line)){
break;
}
//因为录入的数据是有规律的。可以通过指定的规则进行分割。
String[] strs = line.split(",");
//将数组中的元素封装成对象。
Student stu = new Student(strs[0],Integer.parseInt(strs[1])
,Integer.parseInt(strs[2])
,Integer.parseInt(strs[3]));
//将学生对象存储到集合中。
set.add(stu);
}
//关闭键盘录入须知:如果后面不再使用键盘录入,是可以关闭的;如果后面还要使用,就不要关闭,继续通过System.in就可以获取。
//因为System.in流是一次性的,一旦关闭,本次程序就无法再次使用。
//bufr.close();
return set;
}
/**
* 将集合中的学生信息写入到文件中。
* @param set
* @param destFile
* @throws IOException
*/
public static void write2File(Set set, File destFile) throws IOException{
BufferedWriter bufw = null;
try{
bufw = new BufferedWriter(new FileWriter(destFile));
//遍历集合。
for(Student stu : set){
bufw.write(stu.getName()+"\t"+stu.getSum());
bufw.newLine();
bufw.flush();
}
}finally{
if(bufw!=null){
try {
bufw.close();
} catch (Exception e) {
throw new RuntimeException("文件关闭失败");
}
}
}
}
} package ustc.lichunchun.test;
import java.io.File;
import java.io.IOException;
import java.util.Collections;
import java.util.Comparator;
import java.util.Set;
import ustc.lichunchun.test.domain.Student;
import ustc.lichunchun.test.tool.GetInfoTool;
public class Test1 {
public static void main(String[] args) throws IOException {
/*
* 练习2:键盘录入多名学生的信息,格式:姓名,数学成绩,语文成绩,英语成绩。
* 按总分由高到低,将学生的信息进行排列到文件中。
*
* 思路:
* 1.使用键盘录入技术。
* 2.操作的是学生信息,信息很多,需要将信息封装成学生对象。
* 3.总分由高到低,需要排序,需要对学生对象中的总分排序。需要将多个学生对象进行容器存储。
* 哪个容器呢?TreeSet集合。
* 4.将容器中的学生对象的信息写入到文件中。
*/
//创建一个逆序的比较器。
Comparator comp = Collections.reverseOrder();
//使用操作学生信息的工具类。
Set set = GetInfoTool.getStudent(comp);
File destFile = new File("tempfile\\info.txt");
GetInfoTool.write2File(set, destFile);
}
} 阶段性总结1:IO流四大体系脉络整理
File: IO技术用于操作设备上的数据,而数据最常见的体现方式是文件。
先了解了文件的操作。创建、删除、存在、隐藏、获取...。
需求:怎么操作文件中的数据呢?
使用IO流对象。而且文件数据都是字节存在。学习了可以操作文件的字节流。
InputStream
|--FileInputStream
OutputStream
|--FileoutputStream
为了提高操作效率。引入缓冲区。
InputStream
|--FileInputStream
|--FilterInputStream
|--BufferedInputStream
OutputStream
|--FileoutputStream
|--FilterOutputStream
|--BufferedOutputStream
发现,文件数据中,媒体文件字节流没问题,但是对于文本文件,比如想要操作文件中的中文数据时,字节流只能操作字节,需要我们字节解码成字符,麻烦。所以就到API找对象,就发现了字符流中有字节和字符的桥梁对象,传说中的转换流。
Reader
|--InputStreamReader:字节-->字符。
Writer
|-OutputStreamWriter:字符-->字节。
它们的出现解决了中文的编码转换问题。为了便捷操作字符文件。找到了转换流的子类,但是它有局限性,只能操作文件,而且是默认编码。如果不操作文件,而且编码不是默认的,需要使用转换流。
Reader
|--InputStreamReader:字节-->字符。
|--FileReader
Writer
|-OutputStreamWriter:字符-->字节。
|--FileWriter
为了提高字符流的操作效率。引入字符流的缓冲区。
Reader
|--InputStreamReader:字节-->字符。
|--FileReader
|--BufferedReader:readLine();
Writer
|--OutputStreamWriter:字符-->字节。
|--FileWriter
|--BufferedWriter:newLine();
通过前面这么长的讲述,不仅介绍了字节流、字符流,还分别利用了相应的缓冲区流对象进行高效读写。那么,java中IO流的缓冲区原理到底是怎样的呢?
练习:用户登录注册案例--IO版
代码基本和集合框架的那篇博客中提到的一致,只是用户登录注册的具体操作实现类,有所不同。在这里,我们的需求是,将已注册的用户名和密码信息持久化的存储到文件中。代码如下:
package ustc.lichunchun.dao.impl;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import ustc.lichunchun.dao.UserDao;
import ustc.lichunchun.pojo.User;
/**
* 这是用户操作的具体实现类--(IO版)
*
* @author 李春春
* @version V1.1
*/
public class UserDaoImpl implements UserDao {
//为了保证文件一加载就创建
private static File file = new File("user.txt");
//静态代码块,随着类的加载而加载,且只加载一次
static {
try {
file.createNewFile();
} catch (IOException e) {
System.out.println("创建文件失败");
// e.printStackTrace();
}
}
@Override
public boolean isLogin(String username, String password) {
boolean flag = false;
BufferedReader bufr = null;
try{
bufr = new BufferedReader(new FileReader(file));
String line = null;
while((line = bufr.readLine())!=null){
//用户名=密码
String[] datas = line.split("=");
if(datas[0].equals(username) && datas[1].equals(password)){
flag=true;
break;
}
}
}catch(FileNotFoundException e){
System.out.println("用户登录找不到信息所在的文件");
//e.printStackTrace();
}catch(IOException e){
System.out.println("用户登录失败");
//e.printStackTrace();
}finally{
if(bufr!=null){
try {
bufr.close();
} catch (IOException e) {
System.out.println("用户登录释放资源失败");
//e.printStackTrace();
}
}
}
return flag;
}
@Override
public void regist(User user) {
/*
* 为了让注册的数据能够有一定的规则,我就自己定义了一个规则:用户名=密码
*/
BufferedWriter bufw = null;
try{
bufw = new BufferedWriter(new FileWriter(file,true));
bufw.write(user.getUsername()+"="+user.getPassword());
bufw.newLine();
bufw.flush();
}catch(IOException e){
System.out.println("用户注册失败");
//e.printStackTrace();
}finally{
if(bufw!=null){
try {
bufw.close();
} catch (IOException e) {
System.out.println("用户注册释放资源失败");
//e.printStackTrace();
}
}
}
}
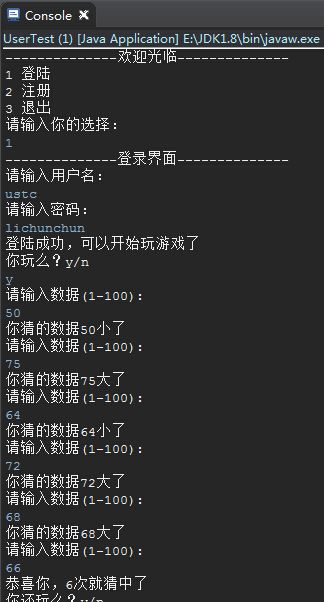
}程序执行结果示例:
缓冲区原理
原理:临时存储数据的方法。减少了对设备操作的频率,提高了效率。其实就是将数据临时缓存到了内存(数组)中。
下面我就带着大家揭秘read()、readLine()方法的缓冲区原理。

1.我们都知道,字符流的缓冲区高效读方法read()、readLine()方法,并且可以通过如下的bufr对象调用:
BufferedReader bufr = new BufferedReader(new InputStreamReader(new FileInputStream("1.txt")));思路:说白了,其实就是内部维护了一个字符数组而已。MyBufferedReader自定义类如下:
package ustc.lichunchun.buffer;
import java.io.IOException;
import java.io.Reader;
public class MyBufferedReader extends Reader{//按照装饰设计模式,应该继承自Reader。
/*
* 模拟一个BufferedReader的高效单字符输入方法read()。
*/
//1.持有一个流对象。
private Reader r;
//2.一初始化就必须明确被缓冲的对象。
public MyBufferedReader(Reader r) {
super();
this.r = r;
}
//3.因为是缓冲区对象,所以内部必须维护一个数组。
private char[] buffer = new char[1024];
//4.定义角标。
private int index = 0;
//5.定义变量,记录住数组中元素的个数。
private int count = 0;
/**
* 读取一个字符的方法,而且是高效的。
* @throws IOException
*/
public int myRead() throws IOException{
//通过被缓冲流对象的read方法,就可以将设备上的数据存储到数组中。
if(count == 0){
count = r.read(buffer);
index = 0;
}
if(count < 0){
return -1;
}
char ch = buffer[index];
index++;//角标每取一次就要自增。
count--;//既然取出一个,数组的数量要减少,一旦减到0,就从设备上获取一批数据存储到数组中。
return ch;
}
/**
* 读取一行文本。
* @throws IOException
*/
public String myReadLine() throws IOException{
//1.定义临时缓冲区,用于存储一行文本。
StringBuilder sb = new StringBuilder();
//2.不断的调用myRead方法从缓冲区中取出数据。
int ch = 0;
while((ch = myRead()) != -1){
//在存储前,要判断行终止符。
if(ch == '\r')
continue;
if(ch == '\n')
return sb.toString();
//对读到的字符进行临时存储。
sb.append((char)ch);
}
//如果文本结尾处有数据,但没有行结束符。数据已被读到,并存储到StringBuilder中,主要判断StringBuilder的长度即可。
if(sb.length() != 0)
return sb.toString();
return null;
}
/**
* 定义一个缓冲区的关闭方法。
* @throws IOException
*/
public void myClose() throws IOException{
//其实就是在关闭缓冲区的流对象。
r.close();
}
//-------------------------------------------------------------------
//因为装饰设计模式,所以集成Reader,所以要复写父类的一些方法。
@Override
public int read(char[] cbuf, int off, int len) throws IOException {
//返回的时候,前后选择一下位置即可。
return 0;
}
@Override
public void close() throws IOException {
r.close();
}
}
package ustc.lichunchun.buffer;
import java.io.FileReader;
import java.io.IOException;
public class MyBufferedReaderDemo {
/**
* 演示自定义的BufferedReader的read()、readLine()、close()方法。
*/
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("tempfile\\bufw.txt");
原先的做法:
BufferedReader bufr = new BufferedReader(fr);
String line = null;
while((line = bufr.readLine()) != null){
System.out.println(line);
}
bufr.close();
//自定义做法:
MyBufferedReader myBufr = new MyBufferedReader(fr);
String line = null;
while((line = myBufr.myReadLine()) != null){
System.out.println(line);
}
myBufr.myClose();
}
}思路:其实只要继承我上面写的MyBufferedReader类,再添加对行号lineNumber的setXxx()、getXxx()方法就可以了。
package ustc.lichunchun.buffer;
import java.io.IOException;
import java.io.Reader;
public class MyLineNumberReader extends MyBufferedReader {
//定义一个行号计数器。
private int lineNumber;
public MyLineNumberReader(Reader r) {
super(r);
}
/**
* 覆盖父类的读一行的方法。
* @throws IOException
*/
public String myReadLine() throws IOException{
lineNumber++;//每读一行,行号自增。
return super.myReadLine();
}
public int getLineNumber() {
return lineNumber;
}
public void setLineNumber(int lineNumber) {
this.lineNumber = lineNumber;
}
}package ustc.lichunchun.buffer;
import java.io.FileReader;
import java.io.IOException;
public class MyLineNumberReaderDemo {
/**
* 演示带行号的缓冲字符输入流MyLineNumberReader。
* @throws IOException
*/
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("tempfile\\bufw.txt");
MyLineNumberReader myLinr = new MyLineNumberReader(fr);
myLinr.setLineNumber(10);//可以自定义设置行号从10开始。
String line = null;
while((line = myLinr.myReadLine()) != null){
System.out.println(myLinr.getLineNumber()+":"+line);
}
myLinr.myClose();
}
}装饰设计模式
IO中的使用到了一个设计模式:装饰设计模式(Wrapper, Decorator)。说白了,就是对一组对象的功能进行增强时,可以使用该模式进行问题的解决。
说到装饰设计模式,就不得不提包装的概念。包装:写一个类(包装类)对被包装对象进行包装。
1.包装类和被包装对象要实现同样的接口;
2.包装类要持有一个被包装对象;
3.包装类在实现接口时,大部分方法是靠调用被包装对象来实现的,对于需要修改的方法我们自己实现。
举例说明。假设我们有一堆字符流的写方法:
Writer
|--TextWriter
|--MediaWriter
在对数据写入操作过程中,希望提升效率。要对操作文本的对象提升效率,就得使用缓冲区技术。
Writer
|--TextWriter:用于操作文本
|--BufferedTextWriter:加入了缓冲技术的操作文本的对象
|--MediaWriter用于操作媒体
|--BufferedMediaWriter
|--AudioWriter
|--BufferedAudioWriter
这样的体系为了进行功能的扩展,产生了很多流对象,那么现在为了提高各个子类流的操作效率,是不是还要各个子类再产生子类呢?是。这时就会发现只为提高功能,进行的继承,会导致集成体系变得很臃肿,扩展性、复用性、灵活性都很差。
重新思考体系的设计问题。既然加入的都是同一种技术--缓冲。前一种是让缓冲和具体的对象相结合。为什么不将该缓冲功能进行单独的封装呢?要提升哪个具体对象,将哪个具体对象交给该缓冲功能进行关联不就可以了吗!
class BufferedWriter extends Writer
{
BufferedWriter(Writer w)
{
}
/*
BufferedWriter(TextWriter w)
{}
BufferedWriter(MediaWriter)
{}
*/
}Writer
|--TextWriter:用于操作文本
|--MediaWriter:用于操作媒体
|--AudioWriter:用于操作音频
|--BufferedWriter:用于提高效率
此后,再用高效的缓冲区技术时,只需将相关写入流和缓冲流相关联即可:
TextWriter tw = new TextWriter();
BufferedWriter bufw = new BufferedWriter(tw);
//tw.write();
bufw.write();解决的问题是:可以给对象提供额外的功能(职责)。比继承这种方式更为灵活。
特点是:装饰类与被装饰类都所属于同一个体系。即装饰类和被装饰类都必须所属同一个接口或者父类。同时,装饰类中持有被装饰类的引用。
拓展:装饰设计模式是对方法增强,继承是对类增强。代理模式也可以对方法进行增强。
练习:PersonDemo演示装饰设计模式。
package ustc.lichunchun.wrapper;
public class PersonDemo {
public static void main(String[] args) {
//Man m = new Man();
Woman m = new Woman();
//SubMan mm = new SubMan();//子类。
NewPerson mm = new NewPerson(m);
mm.chifan();
}
}
class Person{
void chifan(){
System.out.println("吃饭");
}
}
class Man extends Person{
void chifan(){
System.out.println("男人吃饭");
}
}
/*
class SubMan extends Man{
void chifan(){
System.out.println("开胃酒");
super.chifan();
System.out.println("甜点");
System.out.println("来一根");
}
}
*/
class Woman extends Person{
void chifan(){
System.out.println("女人吃饭");
}
}
/**
* 对Man对象进行功能增强,增加一些额外职责。
* 这样,Person下属的所有子类都可以使用NewPerson进行功能的增强。
*/
class NewPerson{
private Person p;
NewPerson(Person p){
this.p = p;
}
void chifan(){
System.out.println("开胃酒");
p.chifan();
System.out.println("甜点");
System.out.println("来一根");
}
}
/*
Person
|--Man
|--Woman
|--NewPerson
*/java.util.Properties属性集隶属于集合框架范畴,我把它放在IO流里重新阐述,是因为这个类是可以持久化的属性集合。
Map
|--Hashtable
|--Properties:用于属性配置文件,键和值都是字符串类型。
Properties的特点有:
1.Hashtable的子类,map集合中的方法都可以用。
2.该集合没有泛型。键值都是字符串。
3.它是一个可以持久化的属性集。键值可以存储到集合中,也可以存储到持久化的设备上。键值的来源也可以是持久化的设备。
4.有和流技术相结合的方法。load(InputStream)、load(Reader)、store(OutputStream,comments)、store(Writer,commments)。
下面这块代码,主要演示了Properties的持久化存储方法,以及如何将其应用在配置文件的读写操作上。
package ustc.lichunchun.properties;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
import java.util.Set;
public class PeopertiesDemo {
public static void main(String[] args) throws IOException {
/*
* Properties属性集简述:
* 演示Properties的特有方法。
* 演示Properties的持久化存储方法。
* 演示加载设备上的.properties数据,并做修改后重新写入配置文件中。
* 练习:程序运行次数,见Test.java
*/
methodDemo3();
}
public static void methodDemo1(){
//Properties的基本存和取。
//创建一个Properties
Properties prop = new Properties();
//存储键值
prop.setProperty("zhangsan", "20");
prop.setProperty("lisi", "23");
prop.setProperty("wangwu", "21");
//用于调试。少用!
prop.list(System.out);
System.out.println("----------------");
//获取键值
Set set = prop.stringPropertyNames();
for(String name : set){
String value = prop.getProperty(name);
System.out.println(name+"..."+value);
}
}
public static void methodDemo2() throws IOException{
Properties prop = new Properties();
prop.setProperty("zhangsan", "20");
prop.setProperty("lisi", "23");
prop.setProperty("wangwu", "21");
/*
* 上面这些数据,如果不通过流存储到硬盘中,程序结束数据就消失了。
* 下面我们来演示Properties中和流相关的特有方法。
*
* 需求:将集合中的数据持久化存储到设备上。
*
*/
//需要输出流对象。
FileOutputStream fos = new FileOutputStream("tempfile\\info.properties");
//专门存储键值对的简单配置文件,相同的键值覆盖。java扩展名是.properties,c++中扩展名是.ini。
//复杂配置文件是.xml,更加通用。
//使用prop的store方法。写入各个项后,自动刷新输出流。但此方法返回后,输出流仍保持打开状态。
prop.store(fos, "my demo, person info");
//关流。
fos.close();
}
public static void methodDemo3() throws IOException{
/*
* 需求:加载设备的数据,修改.properties文件里面的键值信息。
*/
File configFile = new File("tempfile\\info.properties");
//读取流中的数据。
Properties prop = new Properties();
//定义读取流和数据文件关联。
FileInputStream fis = new FileInputStream(configFile);
prop.load(fis);
prop.setProperty("zhangsan", "12");//注意,此时仅修改了内存中的prop中的临时数据,硬盘设备上的键值没变。
//要将改完的数据重新持久化。
FileOutputStream fos = new FileOutputStream(configFile);
prop.store(fos, "");
//prop.list(System.out);
fis.close();
fos.close();
}
} 使用配置文件的场合:使用应用程序过程中出现的不确定数据需要持久化存储时,就需要配置文件来存储。
分析:其实就是需要一个能够持久化计数器这个键值对的集合IO技术,所以用Properties。
package ustc.lichunchun.test;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
public class Test {
public static void main(String[] args) throws IOException {
/*
* 需求:定义一个功能,记录程序运行的次数。满足5次后,给出提示,试用次数已到,请注册!
* 思路:
* 1.需要计数器。
* 2.计数器的值生命周期要比应用程序的周期长,需要对计数器的值进行持久化。
* count=1,里面存储的应该是键值方式,map集合;要和设备上的数据相关联,需要IO技术。
* 集合+IO = Properties。
*
* 使用配置文件的场合:使用应用程序过程中出现的不确定数据需要持久化存储时,就需要配置文件来存储。
*/
boolean b = checkCount();
if(b)
run();
}
public static void run(){
System.out.println("软件运行");
}
public static boolean checkCount() throws IOException {
int count = 0;//记录住每次存储的次数。
boolean isRun = true;
//1.将配置文件封装成File对象。因为要判断文件是否存在。
File configFile = new File("tempfile\\count.properties");
if(!configFile.exists()){//如果不存在,就创建。
configFile.createNewFile();
}
Properties prop = new Properties();//用于存储配置文件中的数据。
//2.定义流对象。
FileInputStream fis = new FileInputStream(configFile);
//FileOutputStream fos = new FileOutputStream(file);
//不可以写在这里,这样每次运行checkCount()到此处,都会重新创建新的file覆盖已有文件。但是新的file中count为0。
//3.将流中的数据加载到集合中。
prop.load(fis);
//4.获取键对应的次数。
String value = prop.getProperty("count");
if(value != null){
count = Integer.parseInt(value);
if(count >= 5){
System.out.println("试用次数已到,请给钱注册!");
isRun = false;
}
}
count++;//对取出的次数进行自增。
//将键count,和自增后的值重新存储到集合中。(键相同,值覆盖)
prop.setProperty("count", Integer.toString(count));
//将集合中的数据存储到配置文件中。
FileOutputStream fos = new FileOutputStream(configFile);
prop.store(fos, "");
fis.close();
fos.close();
return isRun;
}
}阶段性总结2:IO流操作规律总结
流对象,其实很简单,就是读取和写入。但是因为功能的不同,流的体系中提供N多的对象。那么开始时,到底该用哪个对象更为合适呢?这就需要明确流的操作规律。
IO流的操作规律总结:解决的问题,就是开发中具体要使用哪个流对象的问题。
1.明确数据源、数据汇(数据目的)
其实就是在明确要使用的IO体系。四大体系:InputStream OutputStreamReader Writer
需求中操作的是源:意味着是读-->InputStream、Reader
需求中操作的是目的:意味着是写-->OutputStream、Writer
2.明确操作的数据是否是纯文本数据?
(注:.java、.txt、.properties都是纯文本,但是.doc不是纯文本,它里面还可以装表格、图片等)
是,字符流。
是,并且是源:Reader
是,并且是目的:Writer
否,字节流。
通过两个明确,明确了具体要使用的体系。接下来应该明确具体的体系中要使用哪个对象。
3.明确要操作的具体设备。每个设备都有对应的流对象。
源设备:
硬盘:能操作File的流对象都是。File开头。
键盘:System.in。
内存:数组。XxxArray打头。
网络:socket流。
目的设备:
硬盘:能操作File的流对象都是。File开头。
显示器:System.out。
内存:数组。XxxArray打头。
网络:socket流。
到第三步明确,就已经可以找到具体的流对象了。
(这里需要注意,标准输入流System.in在虚拟机运行起来后,就已经打开,并且都是唯一的流,不建议关闭。一旦关闭,整个程序生命周期内再也获取不到。)
(操作内存的读写:ByteArrayInputStream ByteArrayOutputStream、CharArrayReader CharArrayWriter、StringReader StringWriter)
4.需要额外功能吗?
需要高效吗?缓冲区,Buffered开头。
需要编码转换吗?转换流。
IO流操作规律实例:
需求1:通过键盘录入数据,将数据保存到一个文件中。
明确一:有源吗?有。有目的吗?有。
源:InputStream Reader
目的:OutputStream Writer
明确二:是纯文本数据吗?是。
源:Reader
目的:Writer
明确三:具体设备。
源设备:System.in
目的设备:硬盘。
InputStream is = System.in;
FileWriter fw = new FileWriter("a.txt");
将读取的字节存储到数组里read(byte[])
再将字节数组转成字符串
通过fw.write(string)写入到文件中。
但是麻烦。因为明确的源是Reader,所以需要将字节流转成字符流,这样操作文字就便捷了。
明确四:需要功能吗?
需要,转换。字节 --> 字符。InputStreamReader
InputStreamReader isr = new InputStreamReader(System.in);
FileWriter fw = new FileWriter("a.txt");
一次读取一个字符,再将读到的字符写入。
当然也可以定义字符数组缓冲区。
需要其他功能吗?
需要,高效。Buffered
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bufw = new BufferedWriter(new FileWriter("a.txt"));
(PrintWriter pw = new PrintWriter(new FileWriter("a.txt"),true);)
line - bufr.readLine();
bufw.write(String);bufw.flush();
明确一:有源吗?有。有目的吗?有。
源:InputStream Reader
目的:OutputStream Writer
明确二:是纯文本。
源:Reader
目的:Writer
明确三:明确设备。
源设备:
硬盘:FileXxx
目的设备:
显示器:System.out
FileReader fr = new FileReader("a.txt");
OutputStream(PrintStream) out = System.out;
注意:这里其实有一个多态的概念,OutputStream out = System.out;其中System.out是PrintStream类。
fr读取数据到数组中。
如果使用PrintStream直接调用println方法就可以打印了。(实际上处理控制台输出字符可以用:PrintWriter pw = new PrintWriter(System.out,true);pw.println();)
如果使用OutputStream可以调用write方法就可以将数据写入到显示器上。
麻烦。
因为源都是字符数据。可以通过字符流操作,将字符转成字节再给显示器。
需要额外功能吗?
需要转换,字符-->字节。
FileReader fr = new FileReader("a.txt");
OutputStreamWriter osw = new OutputStreamWriter(System.out);
还需要额外功能吗?
需要,高效。
BufferedReader bufr = new BufferedReader(new FileReader("a.txt"));
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(System.out));
(PrintWriter pw = new PrintWriter(System.out,true);)
读取一行数据。
写入一行数据。
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(System.out));
(PrintWriter pw = new PrintWriter(System.out,true);)
录入over结束:
if("over".equals(line)){
break;
}
转成大写:
bufw.write(line.toUppercase()); +newLine() +flush()
(println(line.toUpperCase());)BufferedReader bufr = new BufferedReader(new FileReader("a.txt"));
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("b.txt"),"UTF-8"));本文的最后一部分,我来简要介绍一下,IO包中扩展功能的高级流对象,它们基本都是装饰设计模式。功能流对象:特点、解决的问题、特有方法。
流
|--基本流:就是能够直接读写文件的。
|--高级流:在基本流基础上提供了一些其他的功能。
打印流PrintStream、PrintWriter
打印流其实就是输出流。
PrintStream
字节打印流。特点:打印print()。不抛异常。
打印的目的地:File对象、字符串路径、字节输出流。(前两个都JDK1.5版本才出现。而且在操作文本文件时,可指定字符编码了)
解决问题:方便地打印各种数据值表示形式。它的打印方法可以保证数值的表现形式不变。写的是什么样子,目的就是什么样子。
1:提供了更多的功能,比如打印方法。可以直接打印任意类型的数据。
2:它有一个自动刷新机制,创建该对象,指定参数,对于指定方法可以自动刷新。
3:它使用的本机默认的字符编码.
4:该流的print方法不抛出IOException。
我们从学习java的第一天起,就有在写输出语句,现在可以揭秘了:
System.out.println("hello");
PrintStream ps = System.out;
ps.println("hello");package ustc.lichunchun.otherio.print;
import java.io.File;
import java.io.IOException;
import java.io.PrintStream;
public class PrintStreamDemo {
public static void main(String[] args) throws IOException {
/*
* 演示PrintStream的特有方法。
*/
File dir = new File("tempfile");
if(!dir.exists()){
dir.mkdir();
}
//1.创建PrintStream对象。目的就定为文件。
PrintStream out = new PrintStream("tempfile\\print.txt");//输出流关联这个文件,如果不存在会自动建立。
//2.将数据打印到文件中。
//out.write(97);//a,1字节-->字节流的write(int b)方法一次只写出一个字节,也就是将一个整数的最低8位(8 bits)写出。
//out.write(353);//a,1字节-->之所以print.txt文件打开显示的是a,那是因为记事本只显示文字,记事本自身实现的字节到字符解析,97的低8位二进制对应的ASCII码是'a'。
//out.write(355);//c,1字节-->四字节int型整数355的二进制表示形式,最低8位是99,对应'c'。
//out.write("353".getBytes());//353,3字节-->转成字节数组,byte[],并调用write(byte[] b)方法。
out.print(97);//97,2字节-->print方法保证数值的表现形式。其实原理就是将数值转成字符串。两个字符占2字节。底层代码,PrintStream私有方法write(String):write(String.valueOf(i));
out.close();
}
}当目的是一个字节输出流时,如果使用的println方法,可以在printStream对象上加入一个true参数。这样对于println方法可以进行自动的刷新,而不是等待缓冲区满了再刷新。最终print方法都将具体的数据转成字符串,而且都对IO异常进行了内部处理。
既然操作的数据都转成了字符串,那么使用PrintWriter更好一些。因为PrintWrite是字符流的子类,可以直接操作字符数据,同时也可以指定具体的编码。
字符打印流具备了字节打印流的特点的同时,还有自身的一些特点。开发时尽量用PrintWriter。
方法中直接操作文件的第二参数是编码表。
直接操作输出流的,第二参数是自动刷新。
特点:打印。并且可以对字节流、字符流自动刷新,但必须是println方法。
打印的目的:File对象、字符串路径、字节输出流、字符输出流。
解决问题:可以操作任意类型的数据,print()、println();可以启动自动刷新并实现换行,第二参数true、println()。
示例:读取键盘录入。将数据转成大写显示在屏幕上。要求保持数值的表现形式。
注意:System.in,System.out这两个标准的输入输出流,在jvm启动时已经存在了。随时可以使用。当jvm结束了,这两个流就结束了。但是,当使用了显示的close方法关闭时,这两个流在提前结束了。下面这种写法是标准的键盘录入和屏幕打印格式。
package ustc.lichunchun.otherio.print;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
public class PrintWriterDemo {
/*
* 演示一个小例子。
* 读取键盘录入。将数据转成大写显示在屏幕上。要求保持数值的表现形式。
*/
public static void main(String[] args) throws IOException {
//到了字符流,我们在看write(int b),这次是一次可以写入一个字符。
//由于java默认使用的是Unicode码,所以相当于一次写入两个字节。
/*
* PrintWriter存在的好处是:为了自动刷新功能,并且具备println()简便方法。
*/
//1.键盘录入。
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
//好处:通过缓冲字符输入流的readLine()方法,每次拿到手的都是一个字符串,想怎么操作就怎么操作。
//局限性:实际程序中获取的数据大多来自浏览器页面,不会来自键盘输入。
//2.定义目的。
/*以前的写法*/
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(System.out));
//好处:通过转换流将字节流转成字符流操作,并且利用Buffered实现高效、换行。
//弊端:每次write()方法都要newLine(),如果要实时显示出来,每次还要flush(),麻烦。
/*现在的写法*/
PrintWriter pw = new PrintWriter(System.out,true);
//好处:第二个参数true,对自动换行的println方法可以实现自动刷新,并且PrintWriter构造方法底层封装好了Buffered缓冲高效。
//3.读一行写一行。键盘录入一定要定义结束标记。
String line = null;
while((line = bufr.readLine()) != null){
if("over".equals(line)){
break;
}
pw.println(line.toUpperCase());
//pw.flush();
}
pw.close();
//bufr.close();//不需要关闭键盘录入这种标准输入流。一旦关闭,未执行的后面程序就获取不到。System.in是唯一的。
}
/*
println();
其实等价于:
bufw.write();
bufw.newLine();
bufw.flush();
*/
}1.只有写数据的,没有读数据的。只能操作目的地,不能操作数据源。
2.可以操作任意类型的数据。
3.如果启动了自动刷新,能够自动刷新。
4.该流是可以直接操作文本文件的。
备注:哪些流对象是可以直接操作文本文件的呢?
FileInputStream、FileOutputStream、FileReader、FileWriter、PrintStream、PrintWriter等......
看API,查流对象的构造方法,如果同时有File类型和String类型的参数,一般来说就是可以直接操作文件的。
练习:由于字符打印流可以实现自动刷新和换行,我们来升级一下复制文本文件的代码。
package ustc.lichunchun.otherio.print;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
public class CopyTextFileByPrint {
public static void main(String[] args) throws IOException {
//以前的版本
BufferedReader bufr = new BufferedReader(new FileReader("IO流_4.txt"));
BufferedWriter bufw = new BufferedWriter(new FileWriter("copy.txt"));
String line = null;
while((line = bufr.readLine())!=null){
bufw.write(line);
bufw.newLine();
bufw.flush();
}
bufw.close();
bufr.close();
//打印流的改进版:PrintWriter底层使用了BufferedWriter实现高效。
BufferedReader bufr1 = new BufferedReader(new FileReader("IO流_4.txt"));
PrintWriter pw = new PrintWriter(new FileWriter("copy.txt"),true);
String line1 = null;
while((line1 = bufr1.readLine())!=null){
pw.println(line1);
}
bufr1.close();
pw.close();
}
}序列流SequenceInputStream是一个输入流,主要作用就是将多个读取流合并成一个读取流。实现数据合并。
表示其他输入流的逻辑串联。它从输入流的有序集合开始,并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。这样做,可以更方便的操作多个读取流,其实这个序列流内部会有一个有序的集合容器,用于存储多个读取流对象。该对象的构造函数参数是枚举,想要获取枚举,需要有Vector集合,但不高效。需用ArrayList,但ArrayList中没有枚举,只有自己去创建枚举对象。但是方法怎么实现呢?因为枚举操作的是具体集合中的元素,所以无法具体实现,但是枚举和迭代器是功能一样的,所以,可以用迭代替代枚举。
特点:流对象的有序排列。(一说到有序集合,就要想到List)
解决问题:将多个输入流合并成一个输入流。将多个源合并成一个源。对于多个源的操作会变得简单。
功能:特殊之处在构造函数上。一初始化就合并了多个流进来。
使用场景之一:对多个文件进行数据的合并。多个源对应一个目的。代码如下:
package ustc.lichunchun.otherio.sequence;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.SequenceInputStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Enumeration;
public class SequenceInputStreamDemo {
public static void main(String[] args) throws IOException {
/*
* 演示序列流。SequenceInputStream.
*/
//如何获取一个Enumeration呢?Vector有,但是效率低,使用ArrayList。
ArrayList al = new ArrayList();
//添加三个输入流对象,和指定的具体文件关联。
for (int i = 1; i <= 3; i++) {
al.add(new FileInputStream("tempfile\\"+i+".txt"));
}
//怎么通过ArrayList获取枚举接口?可以使用Collections工具类中的方法。
Enumeration en = Collections.enumeration(al);
//创建序列流对象。需要传递Enumeration。
SequenceInputStream sis = new SequenceInputStream(en);
//创建目的。文件。
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("tempfile\\4.txt"));
//频繁的读写操作。
//创建缓冲区。
byte[] buf = new byte[1024];
int len = 0;
while((len = sis.read(buf))!=-1){
bos.write(buf, 0, len);
}
//关闭流。
bos.close();
sis.close();
}
} 合并原理:多个读取流对应一个输出流。
切割原理:一个读取流对应多个输出流。
注意:文件分割后,一定要有配置文件,描述分割过程和结果,以便他人合并碎片文件之用。
package ustc.lichunchun.splitfile;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.SequenceInputStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Enumeration;
import java.util.Properties;
public class SplitFileTest {
private static final int SIZE = 1024*1024;
public static void main(String[] args) throws IOException {
/*
* 文件切割器。一个读取流,对应多个输出流。而且生成的碎片文件都有有序的编号。
* 文件合并。
*/
//File srcFile= new File("e:\\Yellow.mp3");
File destDir = new File("tempfile\\partfiles");
//splitFile(srcFile,destDir);
mergeFile(destDir);
}
public static void splitFile(File srcFile, File destDir) throws IOException {
if(!srcFile.exists()){
throw new RuntimeException(srcFile.getName()+"源文件不存在");
}
if(!destDir.exists()){
destDir.mkdir();
}
//用读取流关联源文件
FileInputStream fis = new FileInputStream(srcFile);
//定义一个1M的缓冲区。
byte[] buf = new byte[SIZE];
//创建目的。
FileOutputStream fos = null;
int len = 0;
int count = 0;
while((len = fis.read(buf))!=-1){
fos = new FileOutputStream(new File(destDir, (++count)+".part"));
fos.write(buf, 0, len);
fos.close();
}
/*
* 切割文件时,必须记录住被切割文件的名称,以及切割出来碎片文件的个数。以方便于合并。
* 这个信息为了进行描述,使用键值对的方式。用到了properties对象。
*/
Properties prop = new Properties();
//将被切割文件的信息保存到prop集合中。
prop.setProperty("partcount", Integer.toString(count));
prop.setProperty("filename", srcFile.getName());
fos = new FileOutputStream(new File(destDir, (++count)+".properties"));
//将prop集合中的数据存储到文件中。
prop.store(fos, "save part file info");
fos.close();
fis.close();
}
public static void mergeFile(File srcDir) throws IOException {
if(!(srcDir.exists() && srcDir.isDirectory())){
throw new RuntimeException("指定的"+srcDir+"目录不存在,或者不是正确的目录");
}
/**************获取指定目录下的配置文件对象*******************/
File[] files = srcDir.listFiles(new SuffixFilter(".properties"));
if(files.length!=1){
throw new RuntimeException(srcDir+",该目录下没有properties扩展名的文件或者不唯一");
}
//记录配置文件对象。
File configFile = files[0];
/**********************获取配置文件信息**********************/
//获取该文件中的信息。
Properties prop = new Properties();
FileInputStream fis = new FileInputStream(configFile);
prop.load(fis);
String filename = prop.getProperty("filename");
int count = Integer.parseInt(prop.getProperty("partcount"));
/************************获取所有碎片文件********************/
//获取该目录下的所有碎片文件。
File[] partFiles = srcDir.listFiles(new SuffixFilter(".part"));
if(partFiles.length!=count){
throw new RuntimeException("碎片文件不符合要求,个数不对!应该是"+count+"个");
}
/************将碎片文件和流对象关联,并存储到集合中***********/
ArrayList al = new ArrayList();
for(int x = 0; x < partFiles.length; x++){
al.add(new FileInputStream(partFiles[x]));
}
/********************将多个流合并成一个序列流****************/
Enumeration en = Collections.enumeration(al);
SequenceInputStream sis = new SequenceInputStream(en);
FileOutputStream fos = new FileOutputStream(new File(srcDir, filename));
byte[] buf = new byte[SIZE];
int len = 0;
while((len = sis.read(buf))!=-1){
fos.write(buf, 0, len);
}
fis.close();
sis.close();
fos.close();
}
} package ustc.lichunchun.splitfile;
import java.io.File;
import java.io.FilenameFilter;
public class SuffixFilter implements FilenameFilter {
private String suffix;
public SuffixFilter(String suffix) {
super();
this.suffix = suffix;
}
@Override
public boolean accept(File dir, String name) {
return name.endsWith(suffix);
}
}ObjectInputStream、ObjectOutputStream用于操作对象的流对象,我们分别称为对象的序列化和反序列化。
目的:将一个具体的对象进行持久化,写入到硬盘上。
特点:用于直接操作对象。
解决问题:以对象的形式持久化存储、读取数据。可以将对象进行序列化和反序列化。
注意:对象序列化一定要实现Serializable接口。为了给类定义一个serialVersionUID。
功能:ObjectInputStream、readObject() ObjectOutputStream、writeObject()。
关键字:瞬态:transient,用transient修饰后name将不会进行序列化。
注意:静态数据不能被序列化,因为静态数据不在堆内存中,是存储在静态方法区中。
代码示例:
package ustc.lichunchun.domain;
import java.io.Serializable;
/*
* Person类的对象如果需要序列化,就需要实现Serialized标记接口。
* 该接口给需要序列化的类,提供了一个序列版本号。serialVersionID.
* 该版本号的目的在于验证序列化的对象和对应类是否版本匹配。
*/
public class Person implements Serializable{
/**
* 给类显示声明一个序列版本号。
*/
private static final long serialVersionUID = 1L;
private static String name;//静态:不存在于堆内存的对象中,不会被序列化。
private transient int age;//瞬态:防止某些非静态数据被序列化。
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}package ustc.lichunchun.otherio.objectstream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import ustc.lichunchun.domain.Person;
public class ObjectStreamDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException {
/*
* 将一个对象存储到持久化的设备(硬盘)上。
* 去读硬盘上存储的对象数据。
*/
//writeObj();//对象的序列化。
readObj();//对象的反序列化。需要持有相同序列号的Person.class,才可以读取对象,建议显示声明serialVersionID。
}
public static void writeObj() throws IOException {
//1.明确存储对象的文件。
FileOutputStream fos = new FileOutputStream("tempfile\\obj.object");
//2.给操作文件对象加入写入对象的功能。
ObjectOutputStream oos = new ObjectOutputStream(fos);
//3.调用了写入对象的方法。
oos.writeObject(new Person("wangcai",20));
//4.关闭资源。
oos.close();
}
public static void readObj() throws IOException, ClassNotFoundException {
//1.定义流对象关联存储了对象的文件。
FileInputStream fis = new FileInputStream("tempfile\\obj.object");
//2.建立用于读取对象的功能对象。
ObjectInputStream ois = new ObjectInputStream(fis);
Person p = (Person)ois.readObject();
System.out.println(p.toString());
ois.close();
}
}1.静态字段由于不存在于堆内存的对象中,所以不会被序列化,只存活于程序运行过程中的方法区中,程序结束就消亡。序列化的都是对象中的数据。-->反序列化时:name = null。
2.Serializable:用于启动对象的序列化功能,可以强制让指定类具备序列化功能,该接口中没有成员,这是一个标记接口。这个标记接口用于给序列化类提供UID。这个uid是依据类中的成员的数字签名进行运行获取的。如果不需要自动获取一个uid,可以在类中,手动指定一个名称为serialVersionUID id号。依据编译器的不同,或者对信息的高度敏感性。最好每一个序列化的类都进行手动显示的UID的指定。
3.需求:有些非静态字段不需要持久化出去,生命周期只存于内存中。不想被序列化。transient:非瞬态字段。-->反序列化时:age = 0。
解惑:
writeObj()、readObj()分开运行,结果显示的是name=null,age=0,原因:
因为静态的name不跟随对象,所以没有序列化到硬盘上,瞬态的age也不会序列化存到硬盘上。
writeObj()、readObj()一起运行,结果显示的是name=wangcai,age=0,原因:
因为writeObj()后,程序没有结束,静态的name依然存在于内存的方法区中,运行readObj()后,程序在硬盘上反序列化读取对象数据时,即没有读到静态的name,也没有读到瞬态的age,但是toString时候还是可以在程序的生命周期内读到方法区中的name=wangcai的值,所以还可以打印出来。不过记住,在硬盘上并没有持久化name和age。
管道流PipedInputStream、PipedOutputStream
管道读取流和管道写入流可以像管道一样对接上,管道读取流就可以读取管道写入流写入的数据。
上面我们说的这么多的流对象的读、写操作,读写二者之间没有关系,读写分开。如果想把读取的数据写入,需要建立缓冲区。而到了管道流,读取和写入可以像管子一样拧上,两个流可以实现对接,管道输出流可以直接得到输入流提供的数据。
通常,管道输出流是管道的发送端。通常,数据由某个线程写入 PipedOutputStream 对象,并由其他线程从连接的PipedInputStream 读取。不建议对这两个对象尝试使用单个线程,因为这样可能会造成该线程死锁。因为单线程中如果PipedInputStream先开启,但没有read到数据,会一直阻塞等待,造成死锁。
代码示例:
package ustc.lichunchun.otherio.piped;
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
public class PipedStreamDemo {
public static void main(String[] args) throws IOException {
//创建管道对象
PipedInputStream pis = new PipedInputStream();
PipedOutputStream pos = new PipedOutputStream();
//将两个管道流连接上-->这样就明确了源和目的。
pis.connect(pos);
new Thread(new Input(pis)).start();//如果单线程且输入先启动,就死锁了。
new Thread(new Output(pos)).start();//两个线程的话,输入线程阻塞,但是输出线程作为发送端开始执行写功能,然后输入线程就读到了。
}
}
//定义输入任务
class Input implements Runnable{
private PipedInputStream pis;
public Input(PipedInputStream pis) {
super();
this.pis = pis;
}
@Override
public void run() {
byte[] buf = new byte[1024];
int len;
try {
len = pis.read(buf);
String str = new String(buf,0,len);
System.out.println(str);
pis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//定义输出任务
class Output implements Runnable{
private PipedOutputStream pos;
public Output(PipedOutputStream pos) {
super();
this.pos = pos;
}
@Override
public void run() {
//通过write写方法完成。
try {
pos.write("Hi,管道来了!".getBytes());//写入此流的数据字节稍后将用作要连接的管道输入流的输入.
pos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}特点:读取管道和写入管道可以连接。需要使用多线程技术,单线程容易死锁。
功能:connnect()连接输入、输出管道流。
应用场景:和多线程技术相结合,连接网络中的两端,通信。
注意:需要加入多线程技术,因为单线程,先执行read,会发生死锁,因为read方法是阻塞式的,没有数据的read方法会让线程等待。
随机访问RandomAccessFile
随机访问文件RandomAccessFile:工具对象,不属于四大体系。
注意它的构造方法:文件不存在,则创建;存在,则不创建也不覆盖,从文件指针当前位置开始写入,存在就替换。
特点:
1.只能操作文件。
2.既能读,又能写。
3.维护了一个大型byte数组,通过定义指针来操作这个数组。内部封装了字节流的读取和写入。
4.通过对指针的操作可以实现对文件的任意位置的读取和写入。getFilePointer()获取指针的位置,seek()方法设置指针的位置。
5.其实该对象内部封装了字节读取流和字节写入流。
功能:getFilePointer、seek,用于操作文件指针的方法。通过seek(int x)来达到随机访问。
应用场景之一:迅雷多线程下载文件,可以通过指定文件位置的方式,每个线程负责文件某一部分的下载。
注意:实现随机访问,最好是数据有规律。

API文档中所列举的RandomAccessFile的四种访问模式:

代码示例:
package ustc.lichunchun.randomaccess;
import java.io.IOException;
import java.io.RandomAccessFile;
public class RandomAccessFileDemo {
public static void main(String[] args) throws IOException {
/*
* RandomAccessFile可以从文件的任意位置实现读取和写入。通过seek(int x)方法来达到随机访问。
*/
//writeFile();
readFile();
}
public static void writeFile() throws IOException {
//1.创建一个随机访问文件的对象。文件不存在,则创建;存在,则不创建也不覆盖,从文件指针当前位置开始写入,存在就替换。
RandomAccessFile raf = new RandomAccessFile("tempfile\\random.txt", "rw");
//2.写入姓名和年龄。
raf.write("张三".getBytes());
raf.writeInt(97);//保证整数的字节原样完整性。
raf.write("李四".getBytes());
raf.writeInt(99);//保证整数的字节原样完整性。
//3.随机写入。可以实现已有数据的修改。
raf.seek(8);//从8位置开始写。
raf.write("王五".getBytes());
raf.writeInt(100);
System.out.println(raf.getFilePointer());//16
raf.close();
}
public static void readFile() throws IOException {
RandomAccessFile raf = new RandomAccessFile("tempfile\\random.txt", "r");
//随机读取,只要通过设置指针的位置即可。前提:存储的数据有规律。
raf.seek(8*1);
byte[] buf = new byte[4];
raf.read(buf);
String name = new String(buf);
int age = raf.readInt();
System.out.println(name+":"+age);//王五:100
raf.close();
}
}1. 字节流的write(int)方法 ,只写入int最低8位表示的字节。-->啥也不保证,只写入最后一个字节。
2. PrintStream的print(int)方法 ,底层将String.valueOf(int)方法生成的字符串转成字节,按照write(int)方式写入字节。-->保证数值的表现形式完整性。
3. RandomAccessFile的writeInt(int)方法 ,按四个字节将 int 写入该文件,先写高字节。-->保证整数的字节的原样完整性。
4. 对象序列化的writeObject(Object)方法 ,对象的类、类的签名,以及类及其所有超类型的非瞬态和非静态字段的值都将被写入。-->保证对象的封装完整性。
分别具有以上写方法的各种流对象都有针对性的领域应用。
下面我们再来看一下专门操作基本数据类型的DataInputStream、DataOutputStream,这个流对象师专门用于操作基本数据类型值的读取和写入,比如writeBoolean(),想把boolean类型写出去并读回来,功能很简单,想到就可以了。也是一个基本装饰类,给四大体系的基本流提供额外功能而已。
操作基本数据类型值的流DataInputStream/DataOutputStream
作为基本装饰类存在,给四大基本流对象提供操作基本数据值的额外功能。
同样可以实现高效:

代码示例:
package ustc.lichunchun.otherio.datastream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class DataStreamDemo {
public static void main(String[] args) throws IOException {
//writeData();
readData();
}
public static void writeData() throws IOException {
//写入一些基本数据值。
FileOutputStream fos = new FileOutputStream("tempfile\\data.txt");
//fos.write(97);//这个流对象的方法只能写一个字节。
DataOutputStream dos = new DataOutputStream(fos);//作为装饰类存在,给基本流对象提供额外功能。
dos.writeBoolean(true);//true本身在内存中有对应的二进制,写到文件中的是一个字节,文本解析器解析出来不是true。
//但是这与我们无关,我们只需通过DataInputStream,即可读出来。建议写出去时,文件后缀名不要写成.txt
dos.close();
}
public static void readData() throws IOException {
FileInputStream fis = new FileInputStream("tempfile\\data.txt");
DataInputStream dis = new DataInputStream(fis);
boolean b = dis.readBoolean();
System.out.println(b);
dis.close();
}
}源是内存:ByteArrayInputStream、CharArrayReader、StringReader。
目的是内存:ByteArrayOutputStream、CharArrayWriter、StringWriter。
特点:
涉及到具体设备的流,比如硬盘文件读写,是需要使用系统资源的,不用的时候流要关闭。
但是ByteArrayInputStream、ByteArrayOutputStream等流对象没有涉及到到系统底层资源的调用,只是在操作内存中的数组,所以不需要关闭,并且关闭动作也是无效的。此类中的方法在关闭此流后仍可被调用。
解惑:直接操作字节数组就可以了,为什么还要把数组封装到流对象中呢?因为数组本身没有方法,只有一个length属性。为了便于数组的操作,将数组进行封装,对外提供方法操作数组中的元素。
对于数组元素操作无非两种操作:设置(写)和获取(读),而这两操作正好对应流的读写操作。这两个对象就是使用了流的读写思想来操作数组。
代码示例:
package ustc.lichunchun.bytearraystream;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
public class ByteArrayStreamDemo {
public static void main(String[] args) {
//用IO的读写思想操作数组。
//1.确定源。
ByteArrayInputStream bis = new ByteArrayInputStream("abcdef".getBytes());
//2.确定目的。内置了一个可变长度的byte数组。
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int by = 0;
while((by = bis.read())!=-1){
bos.write(by);
}
System.out.println(bos.toString());
//不需要关闭流。
}
}呼!如果你能坚持看到这,真的够nb了!~~累死我了,写这么长。。。
好了,关于JavaSE的IO流基本操作,就分享到此,希望和大家共同进步!后面在网络编程的相关分享中,会有socket的读写,敬请期待!
博主强力推荐IO操作好文:Java Basic Input & Output
转载请声明出处:http://blog.csdn.net/zhongkelee/article/details/47061013
源码下载