挖挖双色球——数据挖掘技术 分享
最近双色球比较热闹,因为河南1彩民独中双色球3.6亿巨奖!
《媒体报道:2009年10月8日,国庆长假结束前的最后一天,在这个注定要被写进中国彩票史的日子,河南省安阳市成为了全国瞩目的焦点。当期中国福利彩票“双色球”第2009118期开奖,全国中出93注头奖,单注奖金409万元,河南一神勇彩民一人独得其中88注头奖,中奖总金额高达3.599亿元,在时隔286期后,一举改写了“甘肃神话”,刷新了中国彩票新纪录。 》
最近网上很多网民对此议论纷纷,这次传统媒体也开始有了质疑声音:《齐鲁晚报:公众对3.6亿巨奖的怀疑不能漠视》 。双色球能猜中吗?本篇博文并不是针对如何猜中双色球的评论,我的能力和知识也无法去评论,当然,作为一个对数字偏爱的人,当然会研究研究双色球这些数字啦!
有媒体曾经采访过沈老师,还说:沈浩老师一直带领着他的研究生从事双色球研究。哈哈!!!
下面我们就一起来挖挖双色球!
要挖双色球,首先要获得双色球数据。双色球网站:www.zhcw.com,往期回顾——>常规项目表,时间:采集日期2009年10月12日。
 建议:大家用IE浏览器,找到常规项目表,Ctrl+C,然后Ctrl+V,收集到Excel里面,自从有了双色球游戏后,从03年到09年,近7年时间,共开出944期双色球!
建议:大家用IE浏览器,找到常规项目表,Ctrl+C,然后Ctrl+V,收集到Excel里面,自从有了双色球游戏后,从03年到09年,近7年时间,共开出944期双色球!

我们能猜中双色球吗?基于常识回答:肯定猜不中,如果能猜中,国家没法玩这个游戏,如果能猜中,他会告诉你,不可能的事情;所以,我们要有基本的科学素养,但是很多人连基本的科学素养的没有!
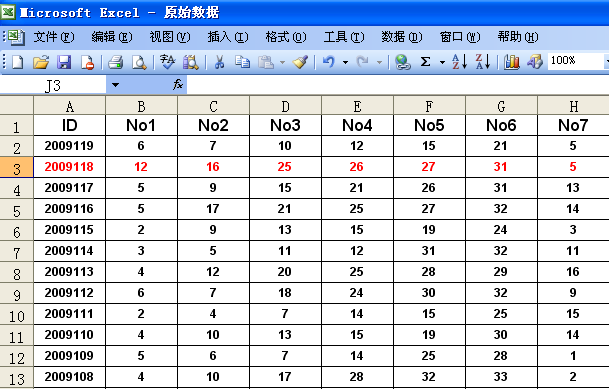 上面这张表就是采集下来的944期双色球数据,看到没有,红色那期就是买中3.6亿的那组号码啦!我们首先删除不用的字段,保留ID期号,记住一定要有ID期号,这是数据的关键字。从数据中我们看到数据已经排好序了,已经没有出球顺序信息了。
上面这张表就是采集下来的944期双色球数据,看到没有,红色那期就是买中3.6亿的那组号码啦!我们首先删除不用的字段,保留ID期号,记住一定要有ID期号,这是数据的关键字。从数据中我们看到数据已经排好序了,已经没有出球顺序信息了。
我们也删掉蓝球No7,因为如果能够猜中红球,多买16注一定中一等奖!所以抓住主要矛盾不研究蓝球,只研究1-33个编号的红球,字段No1到No6。
这里我们假设:双色球数据是干净的,没有数据质量问题!
双色球数据天生适合数据挖掘,因为数据挖掘技术就是从数据中发现知识的过程,我们对双色球一点理论知识都没有,只好挖呗!
数据挖掘技术就是从数据中寻找隐藏在数据中的模式、趋势和相关性!
假设:双色球如果有规律,944期中应该呈现规律!(记住:双色球没有规律,但我们的商业不会像双色球那样没有规律)
首先,我们把Excel采集到的数据导入SPSS软件中,实际上我们现在整理的双色球数据是一张报表数据,我们需要把它转换成为交易数据集,也就是商业自动化采集的数据!
数据挖掘往往都是从数据库数据中挖的,记住:从来我们不是为了数据挖掘而收集数据,而是商业自动化导致海量数据存储,需要数据挖掘发现知识!发现分析模型,商业规则!
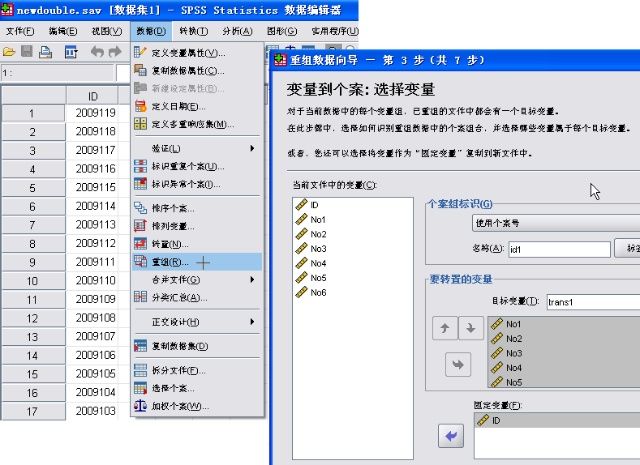 这里我们用SPSS17.0数据重组技术,把数据转换成交易数据集!(现在可以用博易智讯提供的17.0版本,因为是多语言版本,所以可以随心所欲用英文或中文界面和输出了)
这里我们用SPSS17.0数据重组技术,把数据转换成交易数据集!(现在可以用博易智讯提供的17.0版本,因为是多语言版本,所以可以随心所欲用英文或中文界面和输出了)
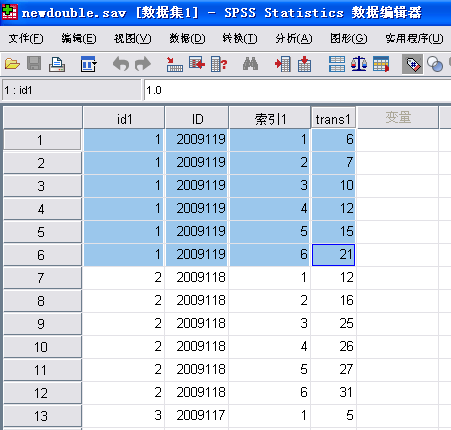 这时候数据已经转换成了交易数据集,过去一期数据占一行六列,现在数据是一期占一列六行;
这时候数据已经转换成了交易数据集,过去一期数据占一行六列,现在数据是一期占一列六行;
下面,我们开始进行数据挖掘!
这里我们采用Clementine挖掘软件工具,(前段时间听博易智讯的马博士说,Clementine已经有了13.0版本,不过我现在采用8.1版本来操作)
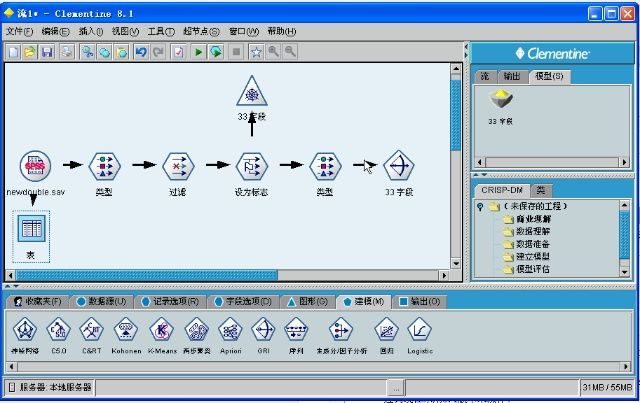 用SPSS类型数据源节点连上数据,当然要读取交易数据集,然后连上“类型”节点,注意,不同版本可能有不同的结果,8.1版会把Trans1字段认为是数值型的,但我们知道双色球1-33个红球,没有1+2=3,只是标记,所以要人工设定为“集合”类型,然后连上“过滤”节点,主要目的是保留ID字段和Trans1字段,删除id1和索引1字段,因为不考虑出球顺序,只要有ID字段和Trans1字段信息全部保留,记住这时候我们也把Trans1字段改名成字段P,方便记忆。
用SPSS类型数据源节点连上数据,当然要读取交易数据集,然后连上“类型”节点,注意,不同版本可能有不同的结果,8.1版会把Trans1字段认为是数值型的,但我们知道双色球1-33个红球,没有1+2=3,只是标记,所以要人工设定为“集合”类型,然后连上“过滤”节点,主要目的是保留ID字段和Trans1字段,删除id1和索引1字段,因为不考虑出球顺序,只要有ID字段和Trans1字段信息全部保留,记住这时候我们也把Trans1字段改名成字段P,方便记忆。
当完成这个基础工作后,我们就可以连上“设为标志”字段,同时要按照ID汇总,另外,如果某期出现这个号码,则是1,否则是0;
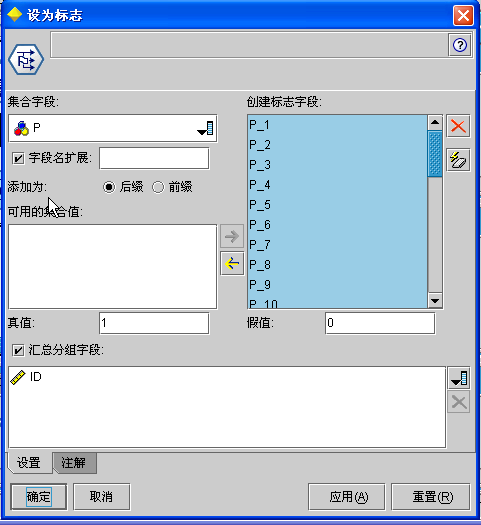 当数据流流到设为标志字段后,我们已经把交易数据集转换成为了分析数据集,一个0-1数据集;
当数据流流到设为标志字段后,我们已经把交易数据集转换成为了分析数据集,一个0-1数据集;
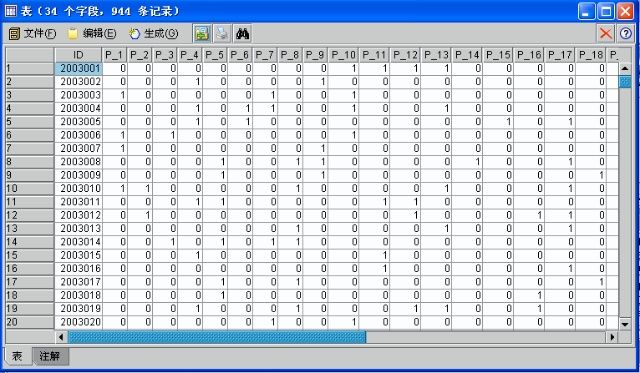 此时,我们并不关系哪个球出现多少次,我们关系的是哪六个球经常一起出现!从上面的数据集角度看,我们并不需要关心哪个字段列分析,我们是希望横着分析,行里面的数据经常出现!
此时,我们并不关系哪个球出现多少次,我们关系的是哪六个球经常一起出现!从上面的数据集角度看,我们并不需要关心哪个字段列分析,我们是希望横着分析,行里面的数据经常出现!
其实我们在市场研究和经营分析领域经常会碰到类似的数据结构,比如:移动公司某个手机号码,在33个业务中定制了哪6个业务;在购物篮数据中,33个物品哪6个商品经常被一起购买;市场研究的多项选择题,33个选项中最多选6个等等。
象这种类型的数据结构都可以采用Link Analysis叫做连接分析,博客上有个朋友提问什么是连接分析,其实一直想回答,但网上有很多描述不想赘述,正好我用这个数据来描述什么是link Analysis。
连接分析,也就Link Analysis,是一种关联分析方法,Link Analysis is the examination of the linkages between effects in a complex system. Analysts typically employ a variety of techniques including OLAP, associations, sequences, clustering, and most important, graphics to examine the relationships between entities in a complex system. They try to discover patterns of activity that can be used to derive useful conclusions. Some applications include forms of fraud detection, criminal network conspiracies, telephone traffic patterns, Web site structure and usage, database visualization, and social network analysis.
这段英文是来自SAS对Link Analysis的解释,属于数据挖掘技术,可视化技术,社会网络分析技术;我前面的文章提到《矩阵就是信息之一,之二》用到了社会网络技术,其实就是Link Analysis分析的一种形式。
现在,我们在Clementine中Link Analysis是Web网络节点,也就网络分析图;现在我们连接上web网络,选择所有33个变量字段,此时叫P1到P33个0-1字段了,标志类型。
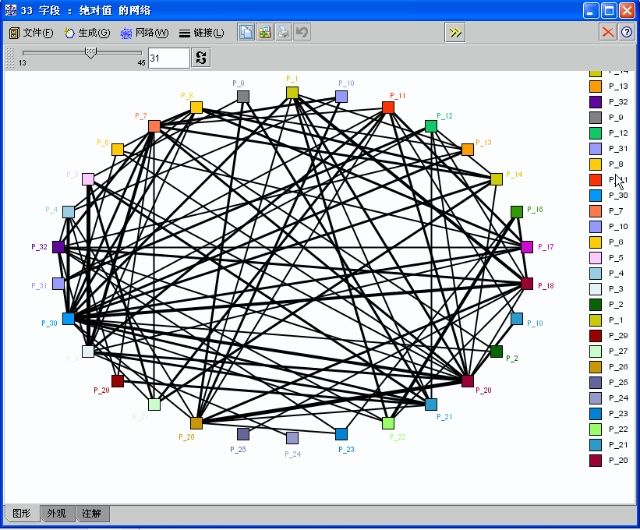 从这个网络分析图(连接分析图)中,我们就可以看出,数据挖掘技术已经嵌入了社会网分析(具体可看前面博文——矩阵就是信息);你可以不断调整关系的强度,看到强连接信息等;
从这个网络分析图(连接分析图)中,我们就可以看出,数据挖掘技术已经嵌入了社会网分析(具体可看前面博文——矩阵就是信息);你可以不断调整关系的强度,看到强连接信息等;
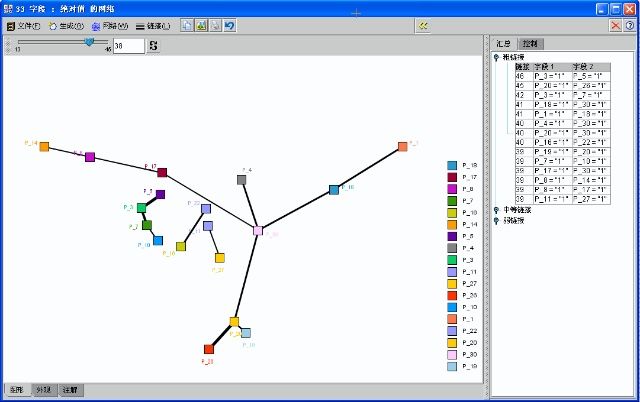 从上图我们就可以看到,P3-P5经常一起出现,P20-P26经常一起出现等等,当然你也等看到P1,P8,P14,P17,P18,P30是一组经常出现的红球!其实到了数据挖掘,我们不仅能够看到图,我们还可以直接从图上点击哪些关系线,直接生成“与”和“或”节点,直接从数据库中把记录抽取出来,也就是看到关系就可以直接挖出来!上图右边显示了“强连接”信息,你就可以看到“啤酒和尿布经常一起被购买”的数据挖掘故事了!
从上图我们就可以看到,P3-P5经常一起出现,P20-P26经常一起出现等等,当然你也等看到P1,P8,P14,P17,P18,P30是一组经常出现的红球!其实到了数据挖掘,我们不仅能够看到图,我们还可以直接从图上点击哪些关系线,直接生成“与”和“或”节点,直接从数据库中把记录抽取出来,也就是看到关系就可以直接挖出来!上图右边显示了“强连接”信息,你就可以看到“啤酒和尿布经常一起被购买”的数据挖掘故事了!
其实,到现在为止,我们还没有用到数据挖掘的建模技术,也就是真正的“发现规则”!有规则吗?我们选择建模面板中的“GRI节点”(一般规则侦测技术——属于Association技术,也是机器学习的建模方法),连上GRI节点,记住:这之前还有重新加入“类型节点”,选择所有字段P1到P33,设置字段方向为“两者”,表明33个字段即可能是预测别人,也可能被别人预测!同时别忘了,把ID字段设为“无”,不要参与分析!
好了,现在执行,看看结果!
 从上面的GRI分析,我们可以看出:前项之后,是后项,也就是说:如果出现了P3、P9、P31则下一个最可能出现P11,依次都可以看到GRI发现的规则;有没有发现六个球的规则呢,没有!如果有我就不写这篇博文啦,哈哈,开个玩笑!
从上面的GRI分析,我们可以看出:前项之后,是后项,也就是说:如果出现了P3、P9、P31则下一个最可能出现P11,依次都可以看到GRI发现的规则;有没有发现六个球的规则呢,没有!如果有我就不写这篇博文啦,哈哈,开个玩笑!
至此,大家可以看到我写“挖挖双色球的文章”主要目的是什么?
1-沈老师的目的,2-所用工具,3-数据基本结构,4-你可以用来挖什么?
我一直坚持说:双色球没有规律,你的商业不会像双色球那样没有规律!
希望对你有帮助!
《媒体报道:2009年10月8日,国庆长假结束前的最后一天,在这个注定要被写进中国彩票史的日子,河南省安阳市成为了全国瞩目的焦点。当期中国福利彩票“双色球”第2009118期开奖,全国中出93注头奖,单注奖金409万元,河南一神勇彩民一人独得其中88注头奖,中奖总金额高达3.599亿元,在时隔286期后,一举改写了“甘肃神话”,刷新了中国彩票新纪录。 》
最近网上很多网民对此议论纷纷,这次传统媒体也开始有了质疑声音:《齐鲁晚报:公众对3.6亿巨奖的怀疑不能漠视》 。双色球能猜中吗?本篇博文并不是针对如何猜中双色球的评论,我的能力和知识也无法去评论,当然,作为一个对数字偏爱的人,当然会研究研究双色球这些数字啦!
有媒体曾经采访过沈老师,还说:沈浩老师一直带领着他的研究生从事双色球研究。哈哈!!!
下面我们就一起来挖挖双色球!
要挖双色球,首先要获得双色球数据。双色球网站:www.zhcw.com,往期回顾——>常规项目表,时间:采集日期2009年10月12日。
建议:大家用IE浏览器,找到常规项目表,Ctrl+C,然后Ctrl+V,收集到Excel里面,自从有了双色球游戏后,从03年到09年,近7年时间,共开出944期双色球!
我们能猜中双色球吗?基于常识回答:肯定猜不中,如果能猜中,国家没法玩这个游戏,如果能猜中,他会告诉你,不可能的事情;所以,我们要有基本的科学素养,但是很多人连基本的科学素养的没有!
上面这张表就是采集下来的944期双色球数据,看到没有,红色那期就是买中3.6亿的那组号码啦!我们首先删除不用的字段,保留ID期号,记住一定要有ID期号,这是数据的关键字。从数据中我们看到数据已经排好序了,已经没有出球顺序信息了。
我们也删掉蓝球No7,因为如果能够猜中红球,多买16注一定中一等奖!所以抓住主要矛盾不研究蓝球,只研究1-33个编号的红球,字段No1到No6。
这里我们假设:双色球数据是干净的,没有数据质量问题!
双色球数据天生适合数据挖掘,因为数据挖掘技术就是从数据中发现知识的过程,我们对双色球一点理论知识都没有,只好挖呗!
数据挖掘技术就是从数据中寻找隐藏在数据中的模式、趋势和相关性!
假设:双色球如果有规律,944期中应该呈现规律!(记住:双色球没有规律,但我们的商业不会像双色球那样没有规律)
首先,我们把Excel采集到的数据导入SPSS软件中,实际上我们现在整理的双色球数据是一张报表数据,我们需要把它转换成为交易数据集,也就是商业自动化采集的数据!
数据挖掘往往都是从数据库数据中挖的,记住:从来我们不是为了数据挖掘而收集数据,而是商业自动化导致海量数据存储,需要数据挖掘发现知识!发现分析模型,商业规则!
这里我们用SPSS17.0数据重组技术,把数据转换成交易数据集!(现在可以用博易智讯提供的17.0版本,因为是多语言版本,所以可以随心所欲用英文或中文界面和输出了)
这时候数据已经转换成了交易数据集,过去一期数据占一行六列,现在数据是一期占一列六行;
下面,我们开始进行数据挖掘!
这里我们采用Clementine挖掘软件工具,(前段时间听博易智讯的马博士说,Clementine已经有了13.0版本,不过我现在采用8.1版本来操作)
用SPSS类型数据源节点连上数据,当然要读取交易数据集,然后连上“类型”节点,注意,不同版本可能有不同的结果,8.1版会把Trans1字段认为是数值型的,但我们知道双色球1-33个红球,没有1+2=3,只是标记,所以要人工设定为“集合”类型,然后连上“过滤”节点,主要目的是保留ID字段和Trans1字段,删除id1和索引1字段,因为不考虑出球顺序,只要有ID字段和Trans1字段信息全部保留,记住这时候我们也把Trans1字段改名成字段P,方便记忆。
当完成这个基础工作后,我们就可以连上“设为标志”字段,同时要按照ID汇总,另外,如果某期出现这个号码,则是1,否则是0;
当数据流流到设为标志字段后,我们已经把交易数据集转换成为了分析数据集,一个0-1数据集;
此时,我们并不关系哪个球出现多少次,我们关系的是哪六个球经常一起出现!从上面的数据集角度看,我们并不需要关心哪个字段列分析,我们是希望横着分析,行里面的数据经常出现!
其实我们在市场研究和经营分析领域经常会碰到类似的数据结构,比如:移动公司某个手机号码,在33个业务中定制了哪6个业务;在购物篮数据中,33个物品哪6个商品经常被一起购买;市场研究的多项选择题,33个选项中最多选6个等等。
象这种类型的数据结构都可以采用Link Analysis叫做连接分析,博客上有个朋友提问什么是连接分析,其实一直想回答,但网上有很多描述不想赘述,正好我用这个数据来描述什么是link Analysis。
连接分析,也就Link Analysis,是一种关联分析方法,Link Analysis is the examination of the linkages between effects in a complex system. Analysts typically employ a variety of techniques including OLAP, associations, sequences, clustering, and most important, graphics to examine the relationships between entities in a complex system. They try to discover patterns of activity that can be used to derive useful conclusions. Some applications include forms of fraud detection, criminal network conspiracies, telephone traffic patterns, Web site structure and usage, database visualization, and social network analysis.
这段英文是来自SAS对Link Analysis的解释,属于数据挖掘技术,可视化技术,社会网络分析技术;我前面的文章提到《矩阵就是信息之一,之二》用到了社会网络技术,其实就是Link Analysis分析的一种形式。
现在,我们在Clementine中Link Analysis是Web网络节点,也就网络分析图;现在我们连接上web网络,选择所有33个变量字段,此时叫P1到P33个0-1字段了,标志类型。
从这个网络分析图(连接分析图)中,我们就可以看出,数据挖掘技术已经嵌入了社会网分析(具体可看前面博文——矩阵就是信息);你可以不断调整关系的强度,看到强连接信息等;
从上图我们就可以看到,P3-P5经常一起出现,P20-P26经常一起出现等等,当然你也等看到P1,P8,P14,P17,P18,P30是一组经常出现的红球!其实到了数据挖掘,我们不仅能够看到图,我们还可以直接从图上点击哪些关系线,直接生成“与”和“或”节点,直接从数据库中把记录抽取出来,也就是看到关系就可以直接挖出来!上图右边显示了“强连接”信息,你就可以看到“啤酒和尿布经常一起被购买”的数据挖掘故事了!
其实,到现在为止,我们还没有用到数据挖掘的建模技术,也就是真正的“发现规则”!有规则吗?我们选择建模面板中的“GRI节点”(一般规则侦测技术——属于Association技术,也是机器学习的建模方法),连上GRI节点,记住:这之前还有重新加入“类型节点”,选择所有字段P1到P33,设置字段方向为“两者”,表明33个字段即可能是预测别人,也可能被别人预测!同时别忘了,把ID字段设为“无”,不要参与分析!
好了,现在执行,看看结果!
从上面的GRI分析,我们可以看出:前项之后,是后项,也就是说:如果出现了P3、P9、P31则下一个最可能出现P11,依次都可以看到GRI发现的规则;有没有发现六个球的规则呢,没有!如果有我就不写这篇博文啦,哈哈,开个玩笑!
至此,大家可以看到我写“挖挖双色球的文章”主要目的是什么?
1-沈老师的目的,2-所用工具,3-数据基本结构,4-你可以用来挖什么?
我一直坚持说:双色球没有规律,你的商业不会像双色球那样没有规律!
希望对你有帮助!