在计算机中所有的数据在存储和计算时都以二进制形式存在。我们平时使用的 a, b, c等字符,也要转换成二进制方式进行存储。具体哪个二进制数字表示哪个字符,是按照约定形成的一套映射标准,这就是编码 。
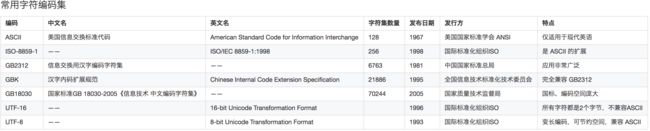
如果没有统一的标准,每个人都按照自己的方式进行字节和字符的映射,那就乱了。因此,1967年 ASCII 码诞生:适用于所有拉丁文字字母、阿拉伯数字、部分符号。然而 ASCII 也不是万能的,首要问题就是它只能表达 128 个字符,且仅适用于英语环境(其扩展能胜任部分西欧语言)。比如中文汉字有近十万个(91251),ASCII 码完全不能适用。
计算机中存储信息的最小单位是字节(byte),即 8 个 bit,能够表示的字符范围是 2^8 = 256 个。而人类社会语言众多符号众多,一个字节根本不足以表示所有符号,所以需要多个字节。个人总结,这种用若干个字节,根据一定的标准映射关系,完成从二进制数据和特定字符集之间的转换过程,就是编码 。
比如:
// 编码过程:将目标字符变成字节流
byte[] bytes = "测试".getBytes("UTF-8");
// 解码过程:字节流恢复成可用字符
String s = new String(bytes, "UTF-8");
在各种系统,网络,空间介质传播信息的时候,按照字节流传递,编码就变得尤为重要了。
Java 中很多地方默认使用 ISO-8859-1,但它不支持中文,要注意。
GBK 和 GB18030 都完全兼容 GB2312,也就是说用 GB2312 生成的编码序列,可以用 GBK 和 GB18030 正常解码
GB18030 基本兼容 GBK
UTF-16 编码效率最高,但是它也有不足:
- 所有字符都用 2 个字节编码,某种情况下浪费空间
- 字节流一旦损坏则很难恢复。
UTF-8 编码效率略低于 UTF-16,但它的优点很明显(所以一般更推荐 UTF-8):
- 无缝兼容 ASCII
- 变长编码,有些情况下不会过度浪费空间
- 另外单个字符的损坏不会影响其他字符(网络传输中很有优势)
ISO-8859-1:
正式编号为ISO/IEC 8859-1:1998,又称Latin-1或“西欧语言”,是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用。
总之,ASCII 码只能用于纯英文环境下,不能用于一些带有附加符号的拉丁文字( Š、š、Ž、ž)以及其他符号,所以在 ASCII 基础上扩展出 ISO-8859-1 编码。大多用于欧洲语言(比如法语、德语、西班牙语等),也可用于其他地区语言(比如印尼语、马来语等)。
ISO-8859-1编码规则如下:

- 0x00-0x7F 属于原 ASCII 区块
- 0x00-0x1F、0x7F、0x80-0x9F在此字符集中未有定义
如下代码验证,可打印如上图展示结果:
public class ISO_8859_1 {
private static final String ISO88591 = "ISO-8859-1";
private static void print() throws Exception {
byte[] bytes = new byte[1];
int count = 0;
for (int code = 0x00; code <= 0xFF; code ++) {
bytes[0] = (byte) code;
System.out.print(new String(bytes, ISO88591) + " ");
if (++count % 16 == 0) {
System.out.println();
count = 0;
}
}
}
public static void main(String[] args) throws Exception {
print();
}
}
GB2312:
GB2312或GB2312–80是中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB 2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。
共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
通常采用 EUC-CN 作为 GB2312 的表示法。EUC-CN 分为 4 个码集(GB2312 只用到码集0、码集1):
码集0:单字节表示,范围是 0x21-0x7E,对应的是 ASCII 的可显示字符范围,这么做主要是为了兼容 ASCII
码集1:双字节表示,第一个字节称为“高位字节”,第二个字节称为“低位字节”。
高位字节:范围是 0xA1-0xF7,用于对字符进行分区处理,每区 94 个字符
低位字节:范围是 0xA1-0xFE,对应各个区块的各个字符,94 个字符
码集1的高位字节用于对字符进行分区处理:
0xA1-0xA9:01-09区(0xA1 = 0x01 + 0xA0,0xA0是基准数值),特殊字符
0xB0-0xD7:16-55区,一级汉字,按拼音排序的汉字
0xD8-0xF7:56–87区,二级汉字,按部首/笔画排序
10–15区及88–94区则未有编码。所以 GB2312 共收录汉字数量应为:(40 + 32) * 94 = 6768 个,但是一级汉字区块里的最后 5 个字符没有编码,所以实际收录汉字数量为:6768 - 5 = 6763 个。
GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB2312不能处理,因此后来GBK及GB18030汉字字符集相继出现以解决这些问题。
代码运行验证可知:
public class GB2312 {
private static final String GB2312 = "GB2312";
private static final int BASE = 0xA0;
private static void printSet0() throws Exception {
byte[] bytes = new byte[1];
for (int code = 0x21; code <= 0x7E; code++) {
bytes[0] = (byte) code;
System.out.print(new String(bytes, GB2312));
}
System.out.println();
}
private static void printSet1(int highBegin, int highEnd) throws Exception {
byte[] bytes = new byte[2];
for (int high = highBegin; high <= highEnd; high++) {
System.out.print(high + ": ");
bytes[0] = (byte) (BASE + high);
for (int low = 1; low <= 94; low++) {
bytes[1] = (byte) (BASE + low);
System.out.print(new String(bytes, GB2312) + "");
}
System.out.println();
}
}
public static void main(String[] args) throws Exception {
System.out.println("\n码集0[ASCII可显示字符]: ");
printSet0();
System.out.println("\n码集1[PART1 特殊符号]: ");
printSet1(1, 9);
System.out.println("\n码集1[PART2 一级汉字]: ");
printSet1(16, 55);
System.out.println("\n码集1[PART3 二级汉字]: ");
printSet1(56, 87);
}
}
GBK:
汉字内码扩展规范,称GBK,全名为《汉字内码扩展规范(GBK)》1.0版,由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司和电子工业部科技与质量监督司1995年12月15日联合以《技术标函[1995]229号》文件的形式公布。 GBK共收录21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。
由于GB1312编码范围实在有限,很多繁体字、新简化字、日语等都不支持,所以推出了 GBK 编码。GBK 编码完全兼容 GB1312,也就是说 GB1312 编码的数据,可以用 GBK 进行正常解码。
编码方式与 GB1312 类似,也包含单字节和双字节两种方式:
单字节:范围 00–7F,与 ASCII 完全一致,注意 GB1312 仅支持部分 ASCII
双字节:完全兼容 GB1312 的双字节,
如下:
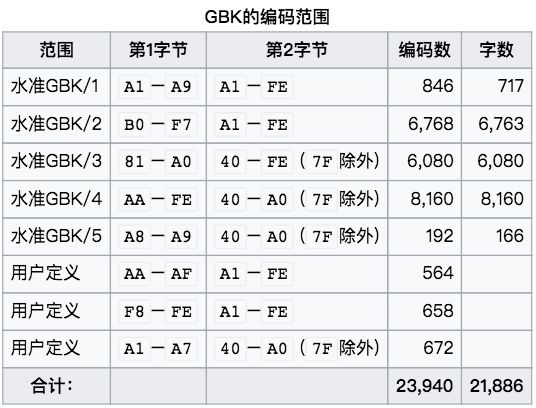
可以看出,GBK/1 和 GBK/2 与 GB1312 完全一致,其他区块是新扩展的编码。
以下是 GBK 编码图,可以看出GBK/1和GBK/2的领域即GB 2312-80用通常方法编码的区域。GB2312中对于AA–AF和F8–FE区域是空的,没有赋予编码。于是GBK就在这些领域里进行拓展。二者剩余部分作为用户定义区。

UTF-8:
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。它废掉所有的地区性编码方案(比如 GB2312、GBK等等),统一使用 2 个字节(这里指的是 UCS-2,UCS-4使用 4 个字节)来表示所有字符,也就是说它能编码范围是 65536。
U+0000 - U+007F:128 个 ASCII 字符
U+0080 - U+07FF:带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文等
U+0800 - U+FFFF:其他基本多文种平面(BMP)中的字符(这包含了大部分常用字,如大部分的汉字)
U+10000 - U+7FFFFFFF:其他极少使用的Unicode 辅助平面的字符
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如“二”字的unicode十六进制编码是:“4E8C”,对应二进制是:“100111010001100”共有15位,也就是说至少需要两个字节来存储。但是问题来了,在一段二进制流中如何区分这个字符是1个字节、还是2个字节?
UTF-8 就是 Unicode 的一种实现方式(还有其他实现方式,比如 UTF-16、UTF-10等),它的特点是用1-4个字节来存储一个字符,且是可变长度。Unicode 和 UTF-8 的转换关系如下:
对于 1 个字节,最高位(第 8 位)是0,则表示这是 1 个 ASCII 字符
对于 1 个字节,以 11 开头,则连续的 1 的个数表示这个字符的字节数,比如 110xxxxx 表示它是双字节 UTF-8 字符的首字节
对于 1 个字节,以 10 开头,则表示它不是首字节,需要向前查找得到当前字符的首字节
UTF-8使用1-6个字节为每个字符编码:
U+0000 - U+007F:1 个字节
U+0080 - U+07FF:2 个字节
U+0800 - U+FFFF:3 个字节
U+10000 - U+1FFFFF:4 个字节
U+200000 - U+3FFFFFF:5 个字节
U+4000000 - U+7FFFFFFF:6 个字节
例如:
例如"汉"字的Unicode编码是6C49。6C49在0800-FFFF之间,所以要用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 1100 0100 1001,将这个比特流按三字节模板的分段方法分为0110 110001 001001,依次代替模板中的x,得到:1110-0110 10-110001 10-001001,即E6 B1 89,这就是UTF8编码。
本文节选整理自其它文章,仅作备忘之用。感谢受用