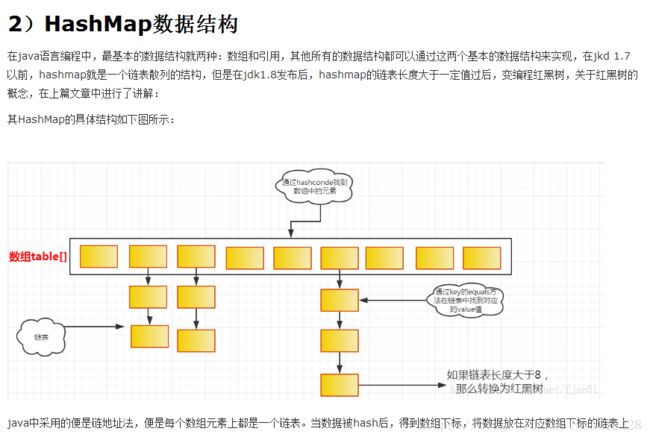
HashMap的长度为什么要是2的n次方
转载,本文非常经典,解释很好,所以转载一波
原文地址 https://blog.csdn.net/sidihuo/article/details/78489820
确定数组index:hashcode % table.length取模
HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标;算法如下:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法;
这个算法实际就是取模,hash%length,计算机中直接求余效率不如位移运算,源码中做了优化hash&(length-1),
hash%length==hash&(length-1)的前提是length是2的n次方;
为什么这样能均匀分布减少碰撞呢?2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1;
例如长度为9时候,3&(9-1)=0 2&(9-1)=0 ,都在0上,碰撞了;
例如长度为8时候,3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞;
其实就是按位“与”的时候,每一位都能 &1 ,也就是和1111……1111111进行与运算
0000 0011 3
& 0000 1000 8
= 0000 0000 0
0000 0010 2
& 0000 1000 8
= 0000 0000 0
-------------------------------------------------------------
0000 0011 3
& 0000 0111 7
= 0000 0011 3
0000 0010 2
& 0000 0111 7
= 0000 0010 2
当然如果不考虑效率直接求余即可(就不需要要求长度必须是2的n次方了);
有人怀疑两种运算效率差别到底有多少,我做个测试:
/**
*
*
*
* 直接【求余】和【按位】运算的差别验证
*
*/
public static void main(String[] args) {
long currentTimeMillis = System.currentTimeMillis();
int a = 0;
int times = 10000 * 10000;
for (long i = 0; i < times; i++) {
a = 9999 % 1024;
}
long currentTimeMillis2 = System.currentTimeMillis();
int b = 0;
for (long i = 0; i < times; i++) {
b = 9999 & (1024 - 1);
}
long currentTimeMillis3 = System.currentTimeMillis();
System.out.println(a + "," + b);
System.out.println("%: " + (currentTimeMillis2 - currentTimeMillis));
System.out.println("&: " + (currentTimeMillis3 - currentTimeMillis2));
}
结果:
783,783
%: 359
&: 93
JDK1.8 优化
HashMap在JDK1.8及以后的版本中引入了红黑树结构,若桶中链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。