ACA - 云计算
ACA - 云计算
Alibaba Cloud Certified Associate - Cloud Computing
Author: Qiangwei Luo (OVEA)
文章目录
- ACA - 云计算
- 简介
- 阿里云在阿里巴巴中的作用
- 具备的优点
- 客户生态——已服务100多万客户
- 设计理念
- 完整的体系架构
- 阿里云服务产品线
- 阿里云平台各种解决方案
- 阿里云基础应用架构建议
- 云服务器ECS
- SLB负载均衡服务
- RDS关系型数据库服务
- OSS对象存储服务
- 案例
- 云服务器ECS
- 定位
- 实现原理
- ECS的弹性伸缩能力
- ECS的优势
- ECS 产品组成
- ECS实例
- ECS计费模式
- 磁盘的种类
- 磁盘的主要操作
- 磁盘的使用限制
- 快照功能
- 快照用途
- 快照的分类
- 快照原理
- 镜像
- 云服务器RDS
- RDS产品概要
- RDS基本信息
- RDS功能
- RDS与自建数据库对比
- RDS相关概念
- DMS简介
- RDS数据迁入
- 迁移类型
- RDS云数据库
- 云存储OSS
- OSS的主要功能
- OSS与传统自建服务器存储对比
- OSS基本概念
- OSS数据组织结构
- OSS访问域名
- OSS访问域名举例
- Object外链地址的构成规则
- Bucket操作
- Object操作
- OSS API调用说明
- OSS API接口列表
- 对象存储服务OSS API使用示例
- 支持的语言
- 基于OSS SDK进行开发的流程
- 静态网站托管
- 负载均衡SLB
- SLB的作用
- SLB核心概念
- SLB术语
- SLB主要功能
- SLB的主要操作
- SLB的一些问题
- 后端ECS实例的一些问题
- 云上安全防护
- 常见威胁
- 阿里云安全体系
- 安全相关的概念
- DDos攻击说明
- 简单的DDos防护的实现流程
- 基础DDos防护的主要功能
- 高防IP
- 高防IP接入流程
- 阿里云云盾-WAF
- 阿里云云盾-安骑士
- 阿里云-云监控
- 10个ACA实验
- 1 - ECS之初体验(Linux)
- 实验概述
- 实验目标
- 学前建议
- 背景知识
- 实验过程
- 2 - 云服务器的数据备份和恢复
- 实验概述
- 实验目标
- 学前建议
- 背景知识
- 阿里云ECS实例云盘
- 阿里云ECS实例快照
- 阿里云ECS实例镜像
- 实验过程
- ECS数据盘分区以及挂载
- ECS数据盘快照的创建
- ECS磁盘回滚
- 3 - 云数据库管理初体验
- 实验概述
- 实验目标
- 学前建议
- 背景知识
- **RDS 简介**
- **RDS 实例链接方式**
- **RDS 数据库账号**
- **RDS 数据库**
- 实验过程
- 创建RDS数据库账号
- RDS数据库创建和登陆
- 导入测试数据
- 查看诊断报告
- 4 - 数据库上云迁移的实现
- 实验概述
- 实验目标
- 学前建议
- 实验过程
- 查看源数据库结构和数据
- 准备好RDS数据库
- 进行数据迁移
- 验证迁移完成
- 5 - 云存储OSS使用初体验
- 实验概述
- 实验目标
- 学前建议
- 背景知识
- 实验过程
- 上传图片文件
- 使用OSS存储图片分享网站
- 6 - 使用OSS API上传和下载文件
- 实验概述
- 实验目标
- 学前建议
- 背景知识
- 实验过程
- 上传文件
- 下载文件
- 删除Object
- 创建OSS Bucket
- 删除OSS Bucket
- 7 - 负载均衡使用初体验
- 实验概述
- 实验目标
- 学前建议
- 背景知识
- 阿里云负载均衡
- 简介
- 架构
- 特点
- 产品优势
- 阿里云负载均衡基础架构
- 实验步骤
- 部署负载均衡后端服务器
- 验证负载均衡工作原理
- 验证负载均衡的监控状态
- 8 - 高并发访问时流量分发和会话保持的实现
- 实验概述
- 实验目标
- 实验步骤
- 9 - 暗骑士初体验
- 实验概述
- 实验目标
- 学前建议
- 背景知识
- 实验步骤
- 配置安骑士
- 用另一台ECS服务器模拟黑客登陆
- 10 - 云监控初体验
- 实验概述
- 实验目标
- 学前建议
- 背景知识
- 实验步骤
- 致谢
简介
致力于打造公共、开放的以数据为中心的云计算服务平台,借助技术创新,不断提升计算能力与规模效益,将云计算变成真正意义上的公共服务,为下一代信息经济构建新的基础设施。
阿里云在阿里巴巴中的作用
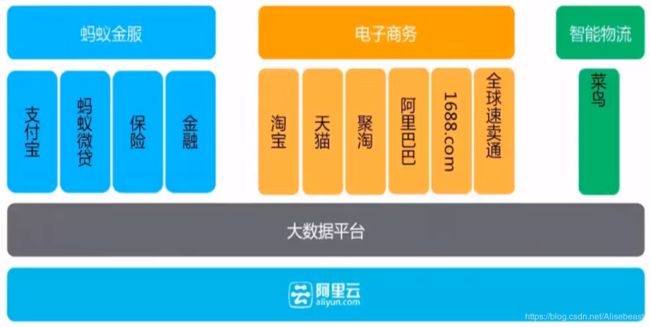
具备的优点
- 优质的CDN网络——遍布全国500多个,海外30多个,总带宽8Tbps
- 多运营商BGP接入
- 规模最大的集群——分布于杭州、青岛、北京、深圳、香港、上海、美国硅谷、新加坡
客户生态——已服务100多万客户

设计理念
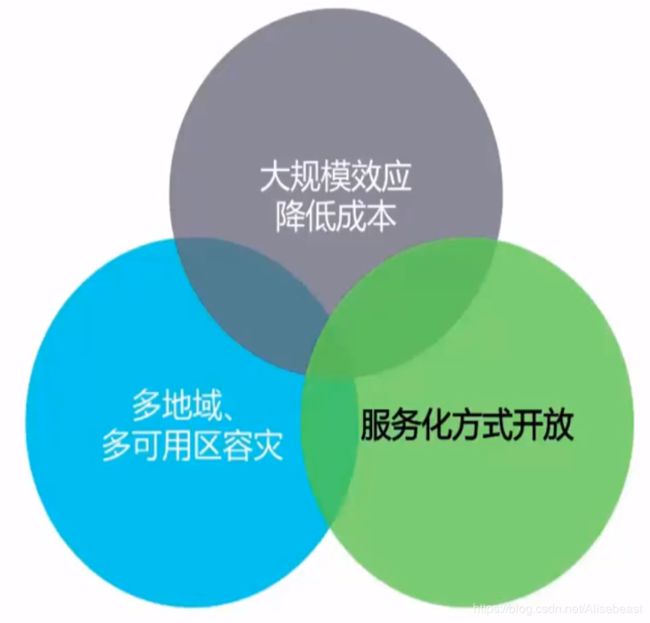
当规模越大时,云服务的价格将会越来越低。
完整的体系架构
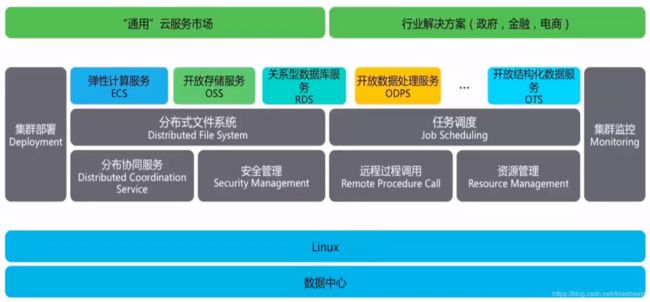
灰色的模块是阿里云的一个平台(飞天?),将一个数据中心变为巨大的计算机。
上面都是安装的软件,ECS、OSS、RDS、ODPS……
最上层则是最终的应用。
阿里云服务产品线
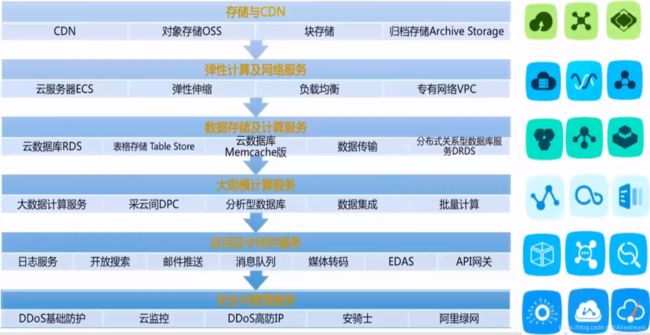
云监控、DDos高防IP、安骑士都是免费保护用户安全的。
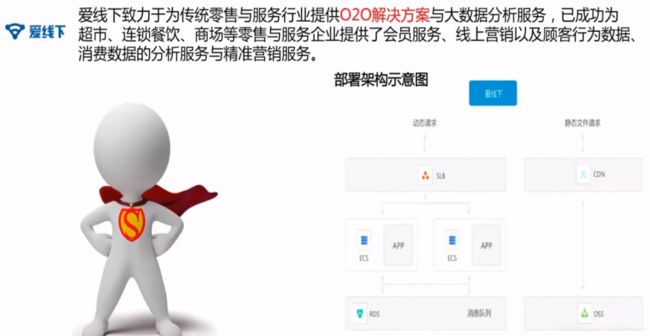
阿里云平台各种解决方案
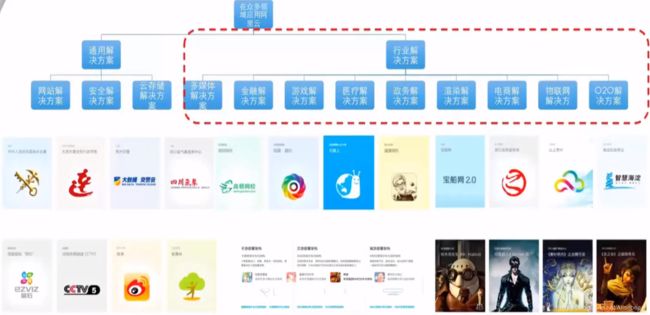
阿里云基础应用架构建议

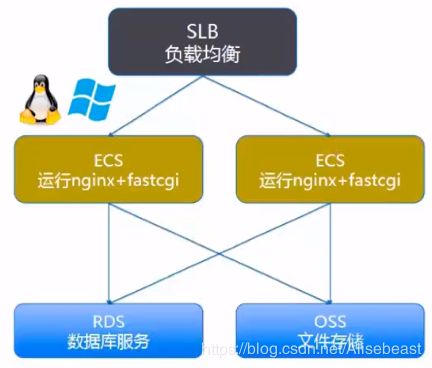
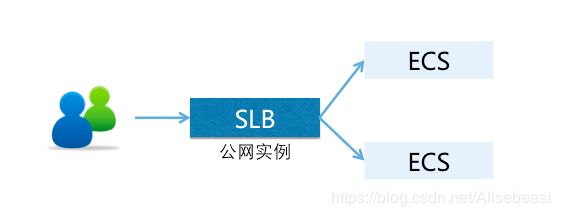
SLB作为流量入口,将流量分配流量到不同的ECS服务器上。
OSS可以存放图片、视频。
结构化类型的数据可以放入RDS中。
云服务器ECS
云服务器(Elastic Compute Service, ECS)是处理能力可弹性伸缩的计算服务,帮助客户快速构建更稳定,安全的应用,提升运维效率,降低IT成本
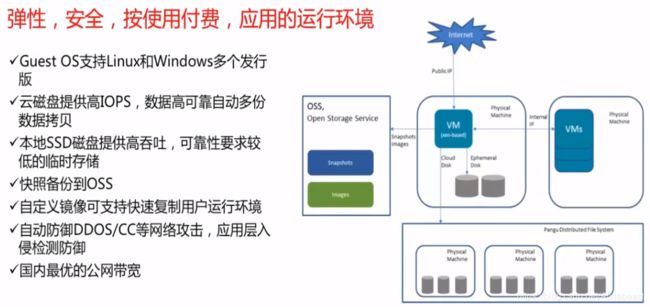
云服务器,不必像传统服务器一样另外购备安全设施。
SLB负载均衡服务
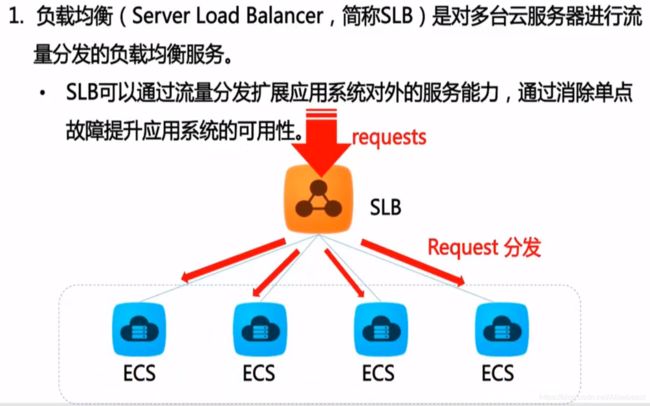
负载均衡(Server Load Balabcer, SLB)是对多台云服务器进行流量分发的负载均衡服务,通过流量分发扩展应用系统对外的服务能力,通过消除单点故障提升应用系统的可用性。
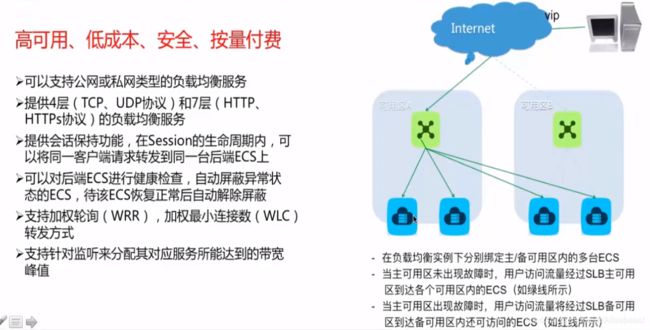
按量付费
RDS关系型数据库服务
云数据库(Relational Database Service, RDS)是一种稳定可靠、可弹性伸缩的在线数据库服务。基于飞天分布式系统和高性能存储,支持MySQL、SQL Server、PostgreSQK和PPAS(高度兼容Oracle)引擎,并且提供了数据库的容灾、备份、恢复、监控、迁移等。

OSS对象存储服务
对象存储(Object Storage Service,OSS),是阿里云对外提供的海量、安全和高可靠的云存储服务。RESTFul API的平台无关性,容量和处理能力的弹性扩展
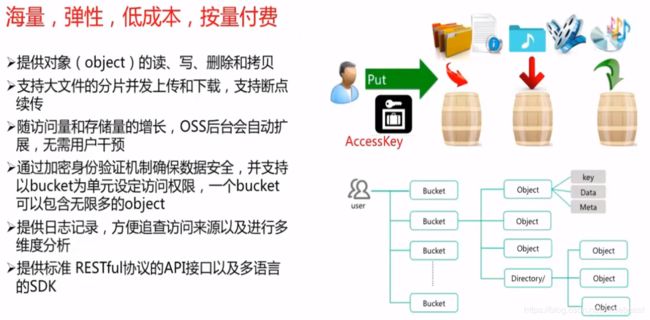
还可以对图片打水印之类的操作~
案例


云服务器ECS
云服务器(Elastic Compute Service,ECS)是一种简单高效、处理能力可弹性伸缩的计算服务,帮助客户快速构建更稳定、安全的应用,提升运维效率,降低IT成本,使客户更专注与核心业务创新。
定位
ECS(云服务器)是阿里云产品体系中,最基础的计算服务,通常作应用程序的运行环境,其最重要的特点是弹性。

弹性是指按需扩展
实现原理
基于阿里云自主研发的大规模分布式计算系统,通过虚拟化技术整理IT资源,为各行业提供互联网基础设施服务设备。
应用程序的基础运行环境
- 每个ECS实例上都运行着用户选择的操作系统(Linux or Windows)
- 用户的应用程序运行在实例的操作系统之上
最简化的弹性架构
- 较好的实践是将ECS和其他云计算产品配合使用,例如,将使用ECS运行webserver,使用RDS作为数据库,OSS作为文件存储。
- 应避免完全将原有物理服务器上的应用都照搬跑在云服务器上。
ECS的弹性伸缩能力
ECS最重要的特点是弹性,支持垂直和水平扩展两种能力

ECS的优势

ECS 产品组成
ECS是由多个并列,又相互关联的产品概念组成,包括
- 实例,instance
- 磁盘,disk
- 快照,snapshot
- 镜像,image
- 镜像,image
- 安全组,security group
还有相关的逻辑位置概念:
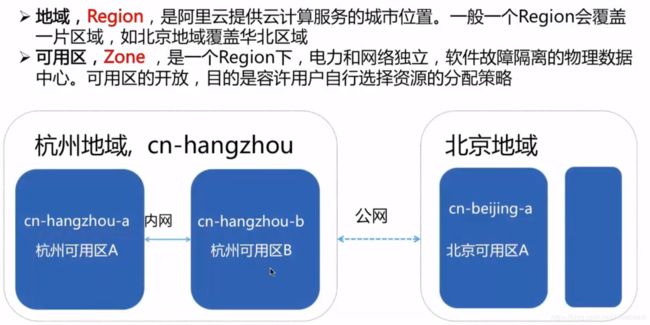
- Region,地域
- Zone,可用区
一个地域有多个可用区。

ECS实例
实例(instance),是ECS产品最核心的部分,由CPU、内存、系统盘和运行的操作系统组成。
实例是ECS最基本的资源,只有基于实例,才能使用网络、存储、快照等其他资源。
阿里云提供了两个实例系列
-
实例系列1采用Intel Xeon CPU、DDR3内存
-
实例系列2采用Intel Xeon E5-2680
v3(Haswell)CPU、DR4内存,并默认为I/O优化实例,同时增加了一些新的指令集,使整数和浮点运算的性能翻倍,整体计算能力更强。
| 系列Ⅱ | 通用型n1 | 通用型n2 | 通用型n3 |
| 特点 | cpu:内存为1:2 最大规格64G内存 |
cpu:内存为1:4 最大规格128G内存 |
cpu:内存为1:8 最大规格128G内存 |
| 适用场景 | 小规模适合小型Web应用、中小型数据库 大规格适合大型多人在线游戏、数据分析和计算等场景 |
适合需要大量内存操作、插好和计算的场景 | |
ECS计费模式
包年包月
- 预付费,平均价格最低
- 可随时升级,但需要升级到购买结束的周期
- 固定带宽随时升级,最少升级一天
- 固定7*24小时服务
按量计费
- 后付费,每小时计费一次
- 每小时价格相对较高,可随时计费
- 不支持实例规格、带宽升级
磁盘的种类
基于飞天分布式文件系统盘古,每份数据存储三个拷贝分布在不同的交换机下、不同的物理服务器上。具有极高的数据可靠性,支持单独挂载。根据存储介质不同,分为三大类
- SSD云盘:采用SSD云盘作为存储介质
- 高效云盘:采用固态硬盘与机械硬盘的混合介质作为存储介质
- 普通云盘:采用机械硬盘作为存储介质
磁盘的主要操作
- 创建磁盘
- 挂载磁盘
- 卸载磁盘
- 释放磁盘
- 回滚磁盘
- 扩容磁盘
- 更换系统盘(系统盘扩容)
磁盘的使用限制
- 每个用户最多可以创建250块磁盘
- 一个实例最多挂载4块数据盘
- 高效云盘和SSD云盘最大支持32TB容量,普通云盘最大支持2TB
- 磁盘只能挂载在同一个可用区的ECS实例上
- 同一时刻,一块磁盘只能挂载在一个ECS实例上
- 系统盘不支持挂载和卸载
快照功能
快照就是磁盘数据在某一个时间点的拷贝
快照用途
- 最常见的用途是备份数据,当应用程序或人为误删除一些数据时,可以通过快照找回
- 通过系统盘快照可以创建出自定义镜像,批量复制出与目前系统完全一样的云服务器实例
- 通过数据盘快照,可以复制出与目前磁盘数据一样的新磁盘
快照的分类
快照分为手动快照和自动快照两大类
- 手动快照由手动创建,用户可以根据业务需要手动为磁盘创建快照,作为数据备份使用
- 自动快照是阿里云自动为用户创建的快照,需要首先进行自动快照策略的设置,然后将自动快照策略应用在相应的磁盘上,阿里云会自动根据设置进行快照的创建,无需用户干预
快照的额度:每块磁盘拥有64个快照,包括手动快照和自动快照,达到额度上限后,如果要继续创建快照,系统会自动将最早的自动快照删掉
- 某块数据盘每天零点进行一次快照备份,可以保护超过两个月的备份数据
- 某块数据盘每隔4小时进行一次快照备份,可以保存10天的备份数据
快照原理
快照机制
ECS的快照是增量快照,只有两个快照之间的变化数据块,才会倍拷贝备份出来。

镜像
ECS镜像是ECS实例可选择的运行环境的模板,包括操作系统和预置的软件和配置。镜像的本质是一个系统盘快照
云服务ECS提供了四种方式获取镜像:
- 阿里云官方的公共镜像
- 镜像市场提供的第三方服务商的镜像
- 根据已有的云服务ECS实例创建的自定义镜像
- 其他阿里云用户共享给客户的镜像
可以把限行环境的镜像文件导入到ECS中生存一个自定义镜像,还可以把自定义镜像复制到其他地域,实现环境和应用的跨地域部署。
云服务器RDS
RDS产品概要
RDS设计目标
- 将耗时耗力的数据库管理任务承担下来,使用户能够专心于开发应用和业务发展
- 用户可根据业务需求对RDS进行弹性伸缩
RDS可靠性保证
- RDS采用主从备份架构,拥有3分以上数据存储,具备高可用和数据可靠性
- RDS承诺99.95%(没有时间范围??)的服务可用性和99.9999%的数据可靠性
RDS基本信息
支持的数据库类型和版本
| 数据库类型 | 版本 | 支持的存储引擎 | 支持的字符集/排序规则 |
|---|---|---|---|
| MySQL | 5.5 5.6 |
InnoDB TokuDB |
utf8 gbk latin1 utf8mb4(完整的UTF-8,仅5.6和以上版本支持) |
| SQL Server | 2008 R2 | Chinese_PRC_CI_AS Chinese_PRC_CS_AS SQL_Latin1_General_CP1_CI_AS SQL_Latin1_General_CP1_CS_AS Chinese_PRC_BIN |
|
| PostgreSQL | 9.4 |
- RDS for MySQL版本融入了RDS DBA团队的MySQL补丁
- 阿里云强烈建议使用InnoDB存储引擎
RDS功能
专业的数据库管理平台DMS
DMS不仅仅是为RDS定制的数据库管理平台,还可以使用户通过浏览器即可安全、方便的进行数据库管理和维护
轻松实现数据回调
RDS能够根据备份文件将数据库恢复至7日内任意时刻
专业的数据库优化建议
RDS提供只管的慢SQL分析报告和完整的SQL运行报告,并提供如主键检查、索引检查等多种优化建议
完善的监控体系
RDS展示近20种性能资源监控视图,可对部分资源项设置阈值报警,并提供WEB操作、SQL审计等多种日志。
RDS与自建数据库对比
| 功能点 | RDS | 自建数据库 |
|---|---|---|
| 服务可用性 | 99.95%(条件?) | 双交换机网络环境,电源输入,高配置主机,双机主从复制,故障恢复,VIP漂移,数据备份,自动数据还原等一系列配套设施需要自行保障 |
| 数据可靠性 | 99.9999%(条件?) | 自行搭建主从复制,自建RAID,MySQL Patch维护等均需自行保障 |
| 系统安全性 | 防DDos攻击,流量清洗;及时修复各种数据库安全漏洞 | 自行部署,价格高昂;自行修复数据库安全漏洞 |
| 数据库备份 | 自动备份 | 自行实现,但需要寻找备份存放空间以及定期验证备份是否可以恢复 |
| 基础运维 | 无需基础运维(如安装机器、部署数据库软件、机器损坏等维护工作) | 需聘请运维工程师维护,花费大量人力成本 |
| 数据库优化 | 提供资源报警、性能监控图、数据库优化建议、SQL运行报告、慢查询分析等数据库优化功能 | 需招聘专职DBA来维护,花费大量人力成本 |
| 部署扩容 | 即时开通,快速部署,弹性扩容,按需开通 | 需硬件采购、机房托管、部署机器等工作,周期较长 |
| 资源利用率 | 按实际结算,100%利用率 | 需考虑峰值,资源利用率低 |
RDS相关概念
- RDS实例(Instance)
- 实例时阿里云关系型数据库的运行环境
- 各实例之间相互独立、资源隔离,相互之间不存在CPU、内存、IOPS等抢占问题
- 同一实例中不同数据库之间时资源共享的
- RDS实例目前支持的最大内存为48GB,最大磁盘容量时1000GB
- RDS只读实例
- 分担数据库压力,增加应用的吞吐量
- RDS可用区
- 单可用区:有效控制云产品间的网络延迟
- 多可用区:轻松实现同城容灾
- 地域(Regin)
- 用户所购买的RDS实例的服务器所处的地理位置
- RDS数据库
- 是用户在一个实例下创建的逻辑单元
- 一个实例可以创建多个数据库,在实例内数据库命名唯一
- MySQL类型实例,最多可创建500个数据库,而SQL Server类型实例最多可创建50个数据库
- 所有数据库都会共享该实例下的资源,如CPU、内存、磁盘容量等
- RDS数据库账号
- 每个数据库账号可以用于多个数据库
- 同时每个数据库的读写权限也可被分配给多个数据库账号
- 一个账号可以创建多个实例
- 对于MySQL和SQL Server类型实例,每个实例最多可创建500个数据库账号
- RDS连接数
- 应用程序可同时连接到RDS实例的连接数量
- RDS磁盘容量
- 用户购买RDS实例时,所选择购买的磁盘大小
- RDS管理控制台
- 管理用户所购买的RDS实例的WEB页面,可对RDS实例进行各种操作
DMS简介
DMS(原iDB Cloud)是一款访问管理云端数据的WEB服务,支持MySQL、SQL Server、PostgreSQL和ADS等数据源,覆盖RDS、ADS和万网等阿里云环境。
DMS提供了数据管理、对象管理、数据流转和实例管理功能。
- 可以在“SQL窗口”和“命令窗口”上通过SQL语句来访问数据,也可以在“打开表”上通过鼠标点击完成数据的便捷操作
- 提供表、索引、视图、存储过程、函数、触发器、事件等对象的丰富操作功能。库、表级别的导入和导出功能令数据流转更加顺畅
- 诊断报告、实时性能、实例会话、锁检测等专业实例管理功能让客户轻松应对
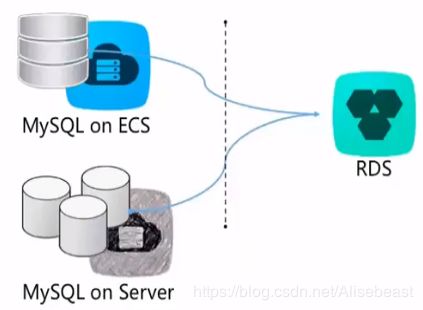
RDS数据迁入
数据迁入RDS
RDS提供专业工具和向导式迁移服务来帮助用户将数据迁入RDS
- mysqldump逻辑备份,数据导入
- DTS数据迁移服务
迁移类型
- 结构迁移
- DTS会将迁移对象的结构定义迁移到目标实例
- 全量迁移
- DTS会将源数据库的数据全部迁移到目标实例
- 增量迁移
- 将迁移过程进行数据变更同步到目标实例
- 如果迁移期间进行了DDL操作,那么这些结构变更不会迁移到目标实例
RDS云数据库
Relational Database Service,关系数据库服务
- 可靠、可弹性伸缩的在线数据库服务
- 基于飞天分布式系统和高性能存储
- 支持MySQL、SQL Server、PostgreSQL和PPAS(高度兼容Oracle)
- 提供容灾、备份、恢复、监控、迁移等方面的全套解决方案,彻底解决数据库运维的烦恼
RDS for SQL Server
不仅覆盖了微软的License支持特性,而且附带高可用架构和任意时间点的数据恢复功能,强力支撑各种企业应用(不用额外支付版权费)
PostgreSQL是是全球最先进的开源数据库
- 作为学院派关系型数据库管理系统的鼻祖
- 优点主要集中在对SQL规范的完整实现,以及丰富多样的数据类型支持(JSON数据、IP数据和几何数据等,大部分商业数据库都不支持)
PPAS(Postgre Plus Advanced Server)
- 稳定、安全且可扩展的企业级关系型数据库
- 基于全球最先进的开源数据库PostgreSQL
- 在性能、应用方案和兼容性等方面进行了增强,提供直接运行Oracle应用的能力
云存储OSS
在物理存储时代,当用户数量和访问量急剧上升地时候,需要进行扩容处理。
扩容容量大可能会浪费,扩容后容量小可能不够用。
对象存储服务(Object Storage Service,OSS)是阿里云对外提供地云存储服务。RESTFul API的平台无关系,容量和处理能力的弹性扩展,按实际容量付费真正使您专注于核心业务。

OSS的主要功能
OSS是一种面向互联网的分布式存储服务,用户可以通过API或者Web页面在任何应用、任何时间、任何低点上传和下载数据,帮您轻松应对海量数据的存储和访问,将存储的难题交给OSS解决。
- 弹性扩展
- 海量的存储空间,随用户使用量的增加,空间弹性增长
- 大规模
- 能支持同时间内高并发、大流量的读写访问
- 图片处理
- 对存储在OSS上的图片,支持缩略、裁剪、水印、压缩和格式转换等图片处理功能
- 按需付费
- 对存储空间、网络流量、请求次数,按照用户实际使用量进行计费,节省用户的成本
OSS与传统自建服务器存储对比
| OSS | 自建服务器存储 | |
|---|---|---|
| 服务可用性 | 99.90% | 自建服务器可用性低 |
| 数据可靠性 | 三重备份,可靠性99.99999999% | 需自行研发备份策略,为达到同步可靠性需增加更多备份服务器成本 |
| 系统安全性 | 提供对称加密用户验证,签名权限控制以及防盗链功能;强大的安全防护系统,抵御“洪水”攻击 | 自行部署,价格高昂 |
| 网络资源 | BGP多线(中国电信、联通、移动、教育网等)骨干网络接入,全国各地流畅访问;无带宽限制,按实际用量付费 | 单线或双线接入速度慢,有带宽限制,峰值时需人工扩容 |
| 存储能力 | 文件存储容量无限 | 服务器存储受硬盘容量限制,需人工扩容 |
| 文件处理能力 | 支持海量数据处理,1个与数十亿个文件处理能力无差别 | Windows系统一个目录下仅支持6万多个文件,Linux系统目录下支持3万多个文件;当一个目录存储文件过多时,IO性能会直线下降 |
| 维护成本 | 无需运营 | 需招聘专职运维人员,花费大量人力成本 |
| 部署扩容 | 无需规则,按实际使用自动扩容,弹性伸缩 | 需硬件采购、机房托管、部署机器等工作,周期较长 |
| 资源利用率 | 按实际结算,100%利用率 | 考虑峰值,资源利用率很低 |
OSS基本概念
- Object
- 用户的每个文件都是一个Object
- 文件大小限制,Put Object方式最大不能超过5GB,使用multipart上传方式Object大小不能超过48.8TB
- Object包含key,data和meta data
- Bucket
- 每个Object必须都包含在Bucket中
- Bucket名在整个OSS中具有全局唯一性,且不能修改
- 一个用户最多可创建10个Bucket
- 每个Bucket中存放的Object的数量和大小综合没有限制
- 一个应用可以对应一个或多个Bucket
- Service
- 提供给用户的虚拟空间,用户可以在这个存储空间中拥有一个或者多个Bucket
- Access ID & Access Key(API密钥)
- 用户标识用户,为访问OSS做签名验证
OSS数据组织结构

OSS访问域名
- 针对OSS的网络请求,除了GetService这个API以外,其他所有的请求的域名都是针对具体bucket的三级域名
- 构成规则是由bucketname和endpoint构成:
- bucketname.endpoint
- endpoint根据bucket所在数据中心的不同,内外网访问方式的不同会有所区分
OSS访问域名举例
- 以青岛节点为例:
- 外网地址:oss-cn-qingdao.aliyuncs.com
- 内网地址:oss-cn-qingdao-internal.aliyuncs.com
- 青岛节点名为hangzhoures的Bucket的访问地址为:
- hangzhoures.oss-cn-hangzhou.aliyuncs.com
- 注意!
- 原地址oss.aliyuncs.com默认指向杭州节点外网地址
- 原内网地址oss-internal.aliyuncs.com默认指向杭州节点内网地址
Object外链地址的构成规则
- 如果Bucket的权限为公共读或者公共读写时,Object的访问规则如下:
- http://
.<数据中心服务域名>/
- http://
- 示意图

Bucket操作

Object操作

OSS API调用说明

OSS API接口列表

对象存储服务OSS API使用示例
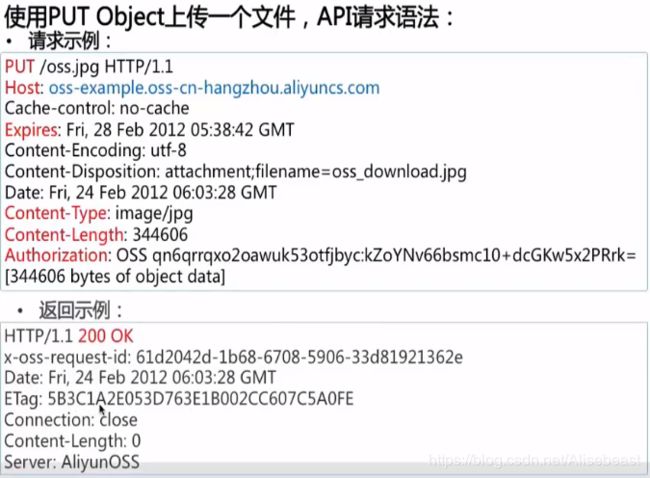
支持的语言

基于OSS SDK进行开发的流程
静态网站托管
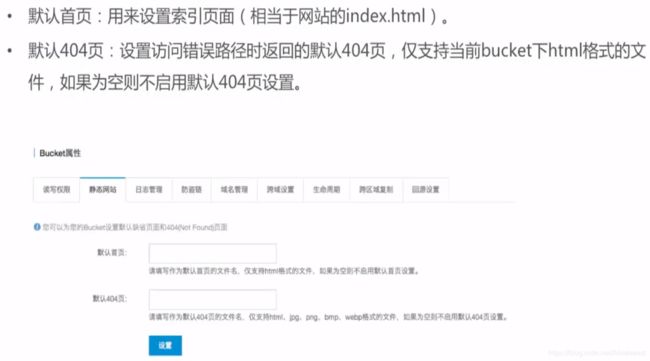
- 如果默认页面为空,则表示不启用静态网页托管,即表示采用静态网页托管必须设置默认首页
- 如果希望启用自己的域名,可以使用CNAME绑定域名
负载均衡SLB
负载均衡(Server Load Balancer)是对多台云服务器进行流量分发的服务。负载均衡可以通过流量分发扩展应用系统对外的服务能力,通过消除单点故障提升应用系统的可用性。
SLB的作用

SLB核心概念
SLB术语

SLB主要功能
- 当前提供4层(TCP、UDP协议)和7层(HTTP、HTTPs协议)的负载均衡服务
- 可以对后端ECS进行健康检查,自动屏蔽异常状态的ECS,待该ECS恢复正常后自动接触屏蔽
- 提供会话保持功能,在Session的生命周期内,可以将同一客户端请求转发到统一后端ECS上
- 支持加权轮询(WRR),加权最小连接数(WLC)转发方式,后端ECS权重越高,被分发的几率也越大
- 支持针对监听来分配其对应服务所能达到的快带峰值
- 支持公网和私网类型的负债均衡服务
- 提供丰富的监控数据,实时了解SLB运行状态
- 结合云盾,提供WAF以及防DDOS攻击的能力,包括CC,SYN,FLOOD等
- 支持统一地域(REGION)跨数据中心容灾,结合DNS还可以支持跨REGION容灾
- 针对HTTPS协议,提供统一的证书管理服务,证书无需上传后端ECS,解密处理在SLB上进行,降低后端ECS CPU的开销
- 提供控制台,API,SDK多种管理方式
SLB的主要操作

SLB的一些问题

后端ECS实例的一些问题


云上安全防护
常见威胁

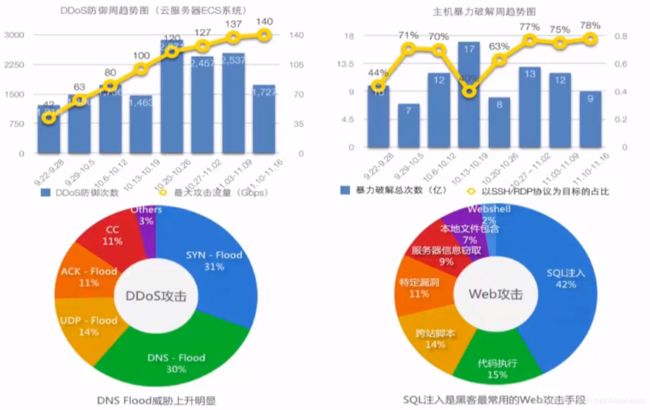
阿里云安全体系
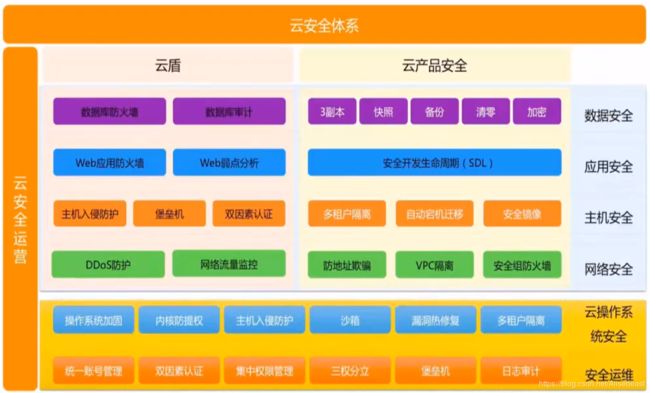
安全相关的概念

DDos攻击说明

简单的DDos防护的实现流程

基础DDos防护的主要功能
- 攻击流量的发现,牵引和自动处理
- 能有效抵御所有各类基于网络层、应用层的各种DDos攻击,包括最新DNS Query Flood、NTP reply Flood
- 大数据分析技术实现全自动检测
- 攻击策略全自动匹配
- 总体响应时间<2秒
- 清洗服务可用性99.99%
高防IP
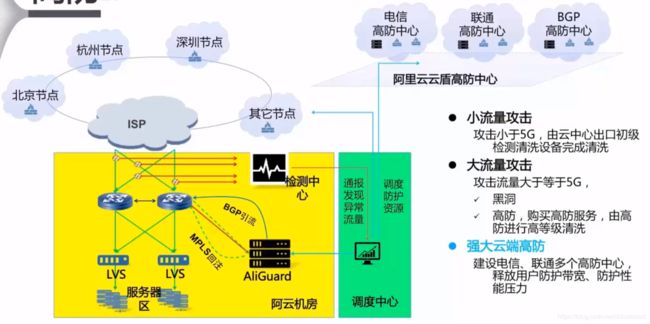
高防IP接入流程
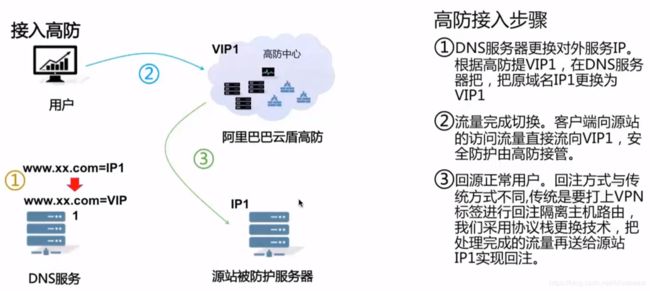
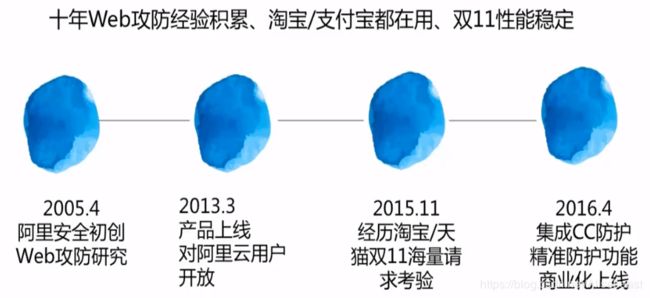
阿里云云盾-WAF

云盾.WAF的发展历程
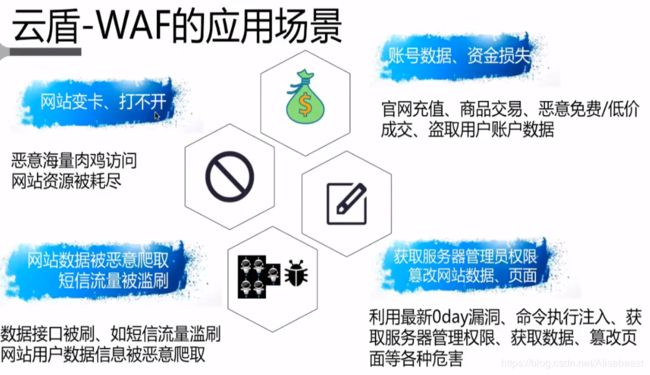
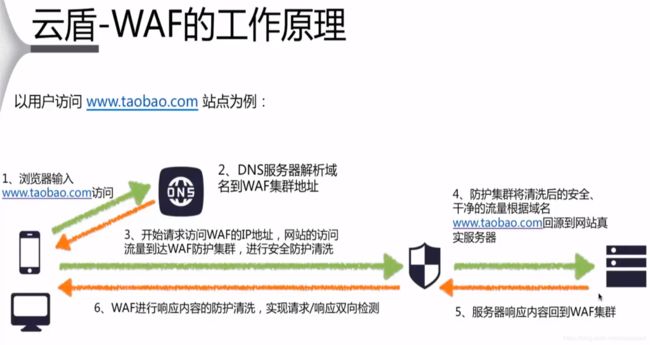
阿里云云盾-安骑士


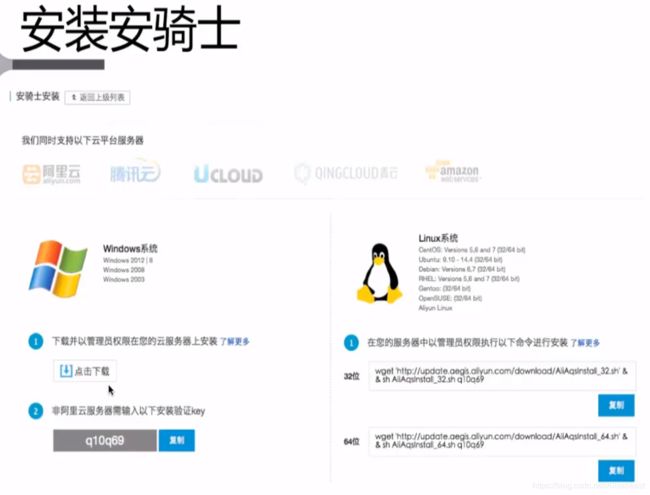
其他平台和物理机也可以安装
阿里云-云监控



10个ACA实验
1 - ECS之初体验(Linux)
实验概述
本实验会自动创建一台ECS实例。首先,远程登陆ECS实例,并部署应用。然后,登陆管理控制台,并对这台ECS实例进行管理操作。
实验目标
完成此实验后,可以掌握的能力有:
-
ECS的基本概念
-
远程访问ECS实例,部署应用。
-
使用管理控制台对ECS进行基本操作:重置ECS实例登陆密码并重启ECS实例。
学前建议
了解Linux的基本操作命令,比如添加和保存文件的命令
背景知识
云服务器(Elastic Compute Service, 简称ECS),是一种简单高效,处理能力可以弹性伸缩的计算服务。ECS的相关术语说明如下:
--实例(Instance):是一个虚拟的计算环境,由CPU、内存、系统盘和运行的操作系统组成;ECS实例作为云服务器最为核心的概念,其他资源,比如磁盘、IP、镜像、快照等,只有与ECS结合后才具有使用意义。
--地域(Region):指ECS实例所在的物理位置。地域内的ECS实例内网是互通的,不同的地域之间ECS实例内网不互通。
--可用区(Zone):指在同一地域内,电力和网络互相独立的物理区域。
--磁盘(Disk):是为ECS实例提供数据块级别的数据存储。可以分为4类: 普通云盘、SSD云盘、高效云盘和本地SSD磁盘
--快照(Snapshot):是某一个时间点上某个磁盘的数据拷贝。
--镜像(Image):是ECS实例运行环境的模板,一般包括操作系统和预装的软件。
--安全组(Security Group):是一种虚拟防火墙,具备状态检测包过滤功能。每个实例至少属于一个安全组。同一个安全组内的实例之间网络互通,不同安全组的实例之间默认内网不通,但是可以授权两个安全组之间互访。
实验过程
太过简单,因此无。
2 - 云服务器的数据备份和恢复
实验概述
本实验将首先指导用户在ECS中对已创建的数据盘进行分区并挂载到ECS上,从而可以使用数据盘进行文件存储;然后,用户创建ECS数据盘的快照,并使用快照进行磁盘的回滚。介绍如何创建自定义镜像。
实验目标
完成此实验后,可以掌握的能力有:
-
对创建的数据盘进行分区,并挂载到ECS中
-
创建ECS数据盘的快照,并使用快照对数据盘进行回滚
-
创建ECS系统盘的快照,并使用快照创建ECS的自定义镜像
学前建议
1.可以熟练的使用Linux基本命令进行操作
2.已完成SL040 ECS之初体验
背景知识
阿里云ECS实例云盘
阿里云ECS实例的云盘提供数据块级别的数据存储,采用三副本的分布式机制,为 ECS 实例提供 99.9999999% 的数据可靠性保证。ECS云盘既可以单独使用,又可以组合使用,从而满足不同应用场景的需求。
ECS云盘分为三种:普通云盘,高效云盘和SSD云盘。
普通云盘:采用机械磁盘作为存储介质
- 产品特点:提供数百的随机读写 IOPS 能力,最大 30 ~ 40 MB/s 的吞吐量;单块普通云盘最大提供 2000 GB 存储空间;可单独挂载到相同可用区内的任意ECS实例上。
- 使用场景:适合数据不被经常访问,低成本,低 I/O 负载或者有随机读写 I/O 的应用场景。
高效云盘:采用固态硬盘与机械硬盘的混合介质作为存储介质
- 产品特点:最高提供 3000 随机读写 IOPS、80 MBps 的吞吐性能;单块高效云盘最大提供 32768 GB 存储空间;可单独挂载到相同可用区内的任意ECS实例上。
- 使用场景:MySQL、SQL Server、PostgreSQL 等中小型关系数据库或对数据可靠性要求高、中度性能要求的中大型开发测试应用。
SSD云盘:
- 产品特点:最高提供 20000 随机读写 IOPS、256 MB/s 的吞吐能力;单块 SSD 云盘最大提供 32768 GB 存储空间;可单独挂载到相同可用区内的任意ECS实例上。
- 使用场景:PostgreSQL、MySQL、Oracle、SQL Server 等中大型关系数据库应用或对数据可靠性要求高的中大型开发测试环境。
- 注意事项:只有挂载到 I/O 优化的实例时,才能获得期望的 IOPS 性能。挂载到非 I/O 优化的实例时无法获得期望的 IOPS 性能。
阿里云ECS实例快照
阿里云ECS产品提供快照功能,所谓快照,就是保留某个时间点上的系统数据状态,数据盘的快照用于数据备份,系统盘的快照用于制作镜像。快照使用增量的方式,两个快照之间只有数据变化的部分才会被拷贝。推荐用户在以下业务场景中使用快照:
-
系统盘、数据盘的日常备份,用户可以利用快照定期的对重要业务数据进行备份,来应对误操作、攻击、病毒等导致的数据丢失风险。
-
更换操作系统,应用软件升级或业务数据迁移等重大操作前,用户可以创建一份或多份数据快照,一旦升级、迁移过程中出现任何问题,可以通过数据快照及时恢复到正常的系统数据状态。
-
生产数据的多副本应用,用户可以通过对生产数据创建快照,从而为数据挖掘、报表查询、开发测试等应用提供近实时的真实生产数据。
创建快照时,服务器的状态只能为“运行中”或“已停止”。阿里云ECS实例的快照提供两种模式:
-
自动快照,用户可以通过创建自动快照策略,自定义快照的创建时间、重复时间和保留时间等参数,阿里云系统将定期为指定的磁盘,自动创建快照。
-
手动快照,用户根据需求,创建磁盘快照。但是,通过手动创建的快照,不会主动删除,会一直保留。
阿里云ECS实例镜像
镜像是云服务器 ECS 实例运行环境的模板,一般包括操作系统和预装的软件。您可以使用镜像创建新的 ECS 实例和更换 ECS 实例的系统盘。目前,阿里提供四种可供使用的镜像类型:
- 公共镜像:由阿里云官方提供的,目前支持Windows和Linux等多个发行版本;
- 镜像市场:通过镜像市场,购买第三方(ISV)提供的镜像;
- 自定义镜像:使用现有的服务器ECS实例创建的自定义镜像;
- 共享镜像:选择其他阿里云用户共享的
实验过程
ECS数据盘分区以及挂载
-
连接到ECS服务器。
-
查询当前系统中的数据盘
fdisk -l

-
对数据盘进行分区
fdisk /dev/vbd

-
查询当前系统磁盘信息
fdisk -l

-
对数据盘进行格式化
mkfs.ext4 /dev/vdb1

-
挂载磁盘到linux中
mkdir -p /extdisk/0000 mount /dev/vdb1 /extdisk/0000 -
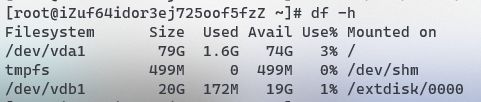
查看磁盘的使用情况
df -h
ECS数据盘快照的创建
-
先在/extdisk/0000写入一些数据备用
echo "Hello , I'm robot~" > /extdisk/0000/lab.txt -
进入ECS实例管理页面创建快照

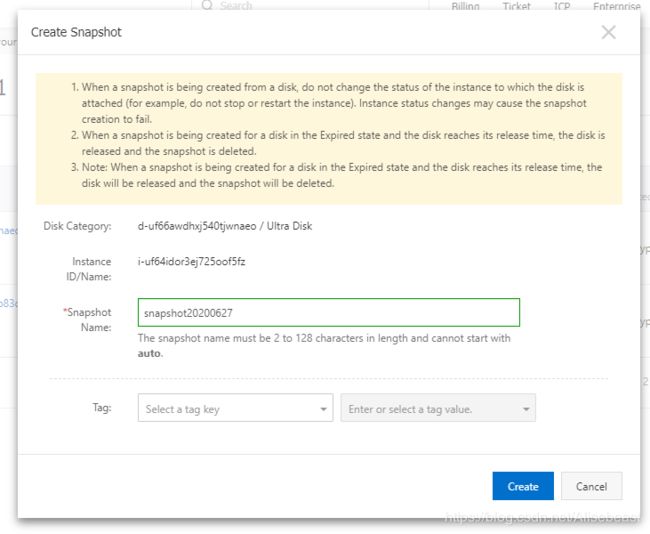

ECS磁盘回滚
-
删除文件/extdisk/0000/lab.txt
rm /extdisk/0000/lab.txt -
使用快照回滚进行恢复
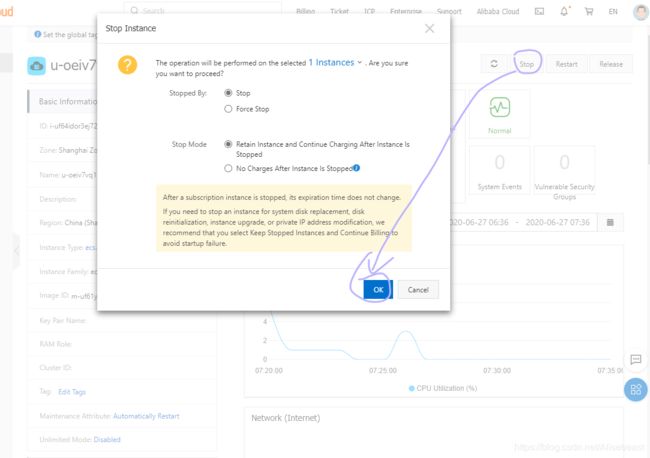
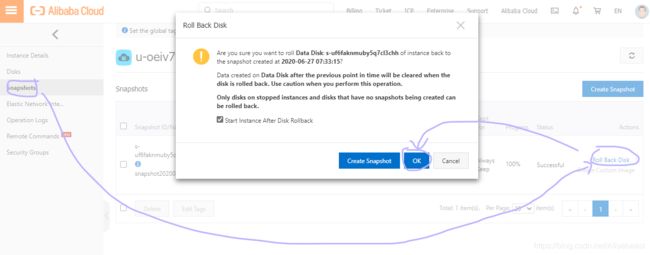
- 重新挂载并检查文件

3 - 云数据库管理初体验
实验概述
本实验将提供一台阿里云RDS数据库,并通过阿里云的管理控制台进行如下操作:
1)创建RDS数据库;
2)创建RDS数据库帐号;
3)将测试数据导入到新建RDS数据库;
4)管理并查看导入数据的信息以及诊断报告;
实验目标
完成此实验后,可以掌握的能力有:
-
RDS的基本概念;
-
创建数据库和数据库账号;
-
导入本地数据;
-
获取诊断报告
学前建议
了解数据库的基本结构
背景知识
RDS 简介
阿里云关系型数据库(Relational Database Service,简称 RDS)是一种稳定可靠、可弹性伸缩的在线数据库服务。基于阿里云分布式文件系统和高性能存储,RDS 支持 MySQL、SQL Server、PostgreSQL 和 PPAS(Postgre Plus Advanced Server,一种高度兼容 Oracle 的数据库)引擎,并且提供了容灾、备份、恢复、监控、迁移等方面的全套解决方案,彻底解决数据库运维的烦恼。
RDS 实例链接方式
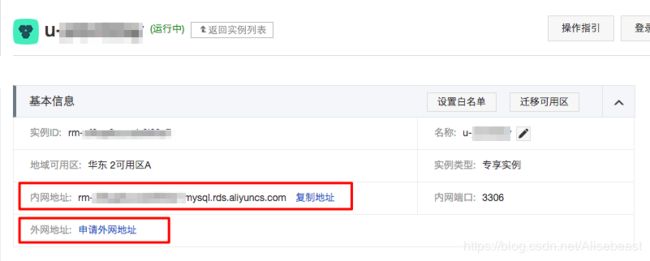
当RDS实例创建成功后,默认提供 内网链接地址 ,用户可以通过 数据传输服务 或 相同地域的ECS实例 连接到RDS实例。若要通过本地服务器 或 不同地域的ECS实例 连接到 RDS实例,用户需 申请外网地址 ,如下图所示:
RDS 数据库账号
在使用RDS 数据库之前,需要在 RDS 实例中创建账号。同一实例下的数据库共享该实例下的所有资源,其中:
> MySQL 版实例和 SQL Server 版实例最多可以创建 500 个账号
> PostgreSQL 版实例和 PPAS 版实例没有账号个数限制
> RDS for SQL Server 2012 只能创建初始账号
注意事项:
1)分配数据库账号权限时,请按最小权限原则和业务角色创建账号,并合理分配只读和读写权限。必要时可以把数据库账号和数据库拆分成更小粒度,使每个数据库账号只能访问其业务之内的数据。如果不需要数据库写入操作,请分配只读权限。
2)请设置数据库账号的密码为强密码,并定期更换
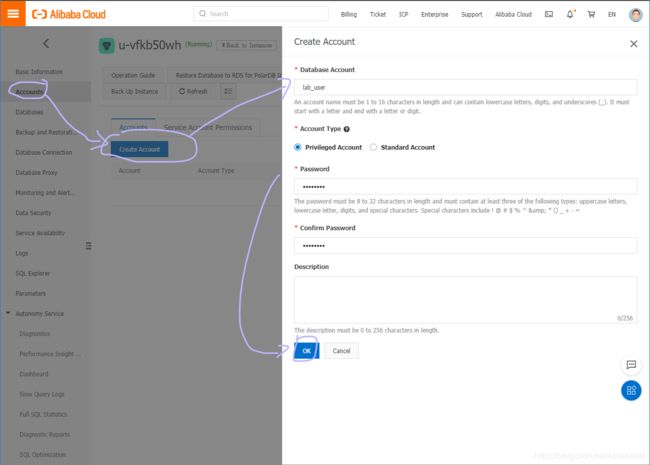
创建数据库账号:

1)数据库账号:由 2~16 个字符的小写字母,数字或下划线组成、开头需为字母,结尾需为字母或数字,如 lab_user 。
2)授权数据库:该账号授权的数据库,选取左边的 未授权数据库 ,单击 授权,添加数据库到 已授权数据库 中。如果尚未创建数据库,该值可以为空。您可以通过 已授权数据库 右上角的权限设置按钮将该账号下的数据库权限批量设置为 全部设读写 或者 全部设只读。
3)密码:该账号对应的密码,由 6~32 个字符的字母、数字、中划线或下划线组成,如 password4example。
确认密码:输入与密码一致的字段,如 password4example,以确保密码正确输入。
4)备注说明:可以备注该账号的相关信息,便于后续账号管理,最多支持 256 个字符(1 个汉字等于 3 个字符)。
RDS 数据库
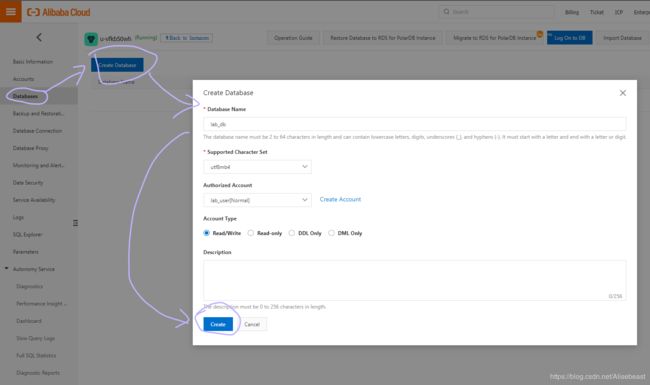
用户可以通过 RDS 管理控制台 创建数据库。数据库名称实例内唯一,实例间互不影响。同一实例下的数据库共享该实例下的所有资源,其中:
> MySQL 版实例最多可以创建 500 个数据库
> SQL Server 2008 R2 版实例最多可以创建 50 个数据库
> PostgreSQL 版实例和 PPAS 版实例没有数据库个数限制
- 创建数据库:
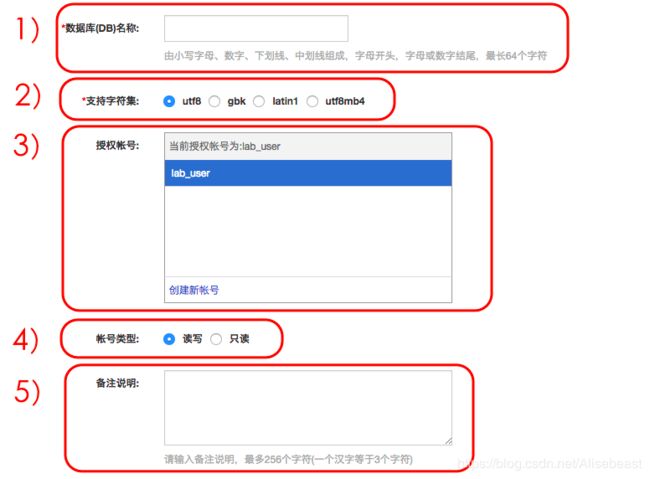
1)数据库(DB)名称:由 2~64 个字符的小写字母、数字、下划线或中划线组成,开头需为字母,结尾需为字母或数字。
2)支持字符集:设置数据库的字符集:utf8、gbk、latin1 和 utf8mb4。
3)授权账号:选择该数据库授权的账号。如果尚未创建账号,该值可以为空。
4)账号类型:选择 授权账号 后可见,设置该数据库授权给 授权账号 的权限,可以设置为 读写 或者 只读 。
5)备注说明:可以备注该数据库的相关信息,便于后续数据库管理,最多支持 256 个字符(1 个汉字等于 3 个字符)。
实验过程
创建RDS数据库账号
此处选择Standard Account(普通账户)
RDS数据库创建和登陆
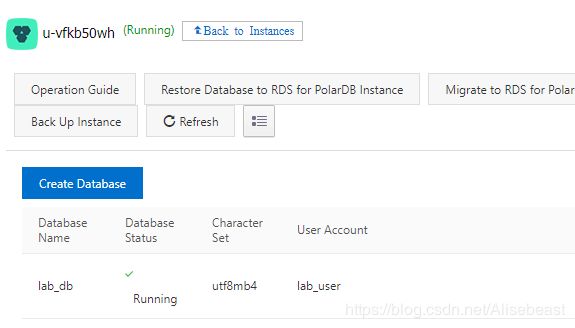


导入测试数据

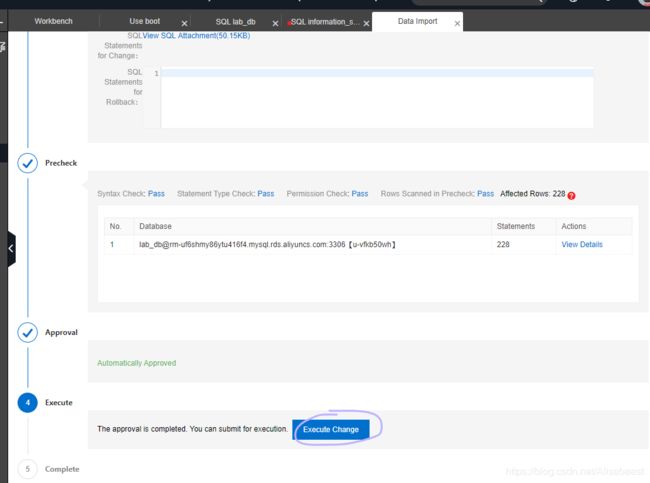
查看诊断报告
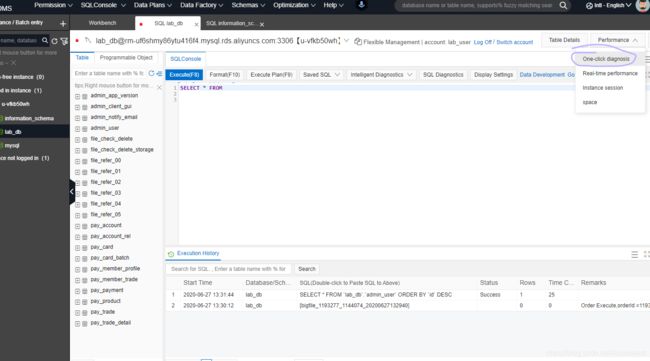
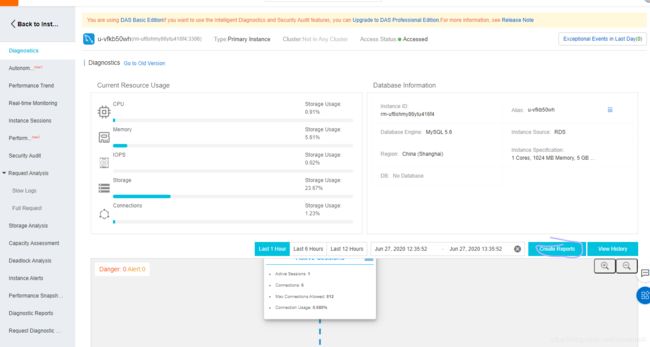
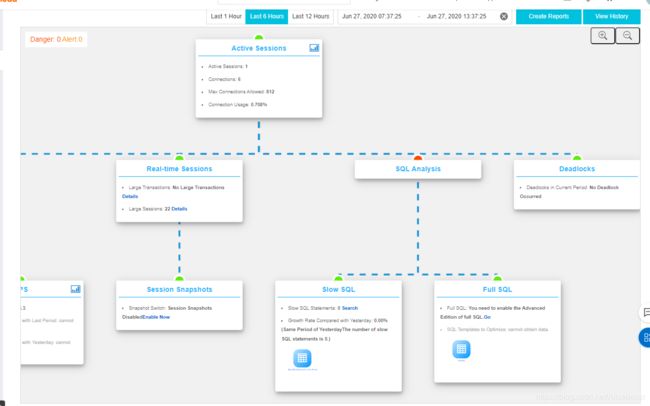
4 - 数据库上云迁移的实现
实验概述
开始实验后,系统会自动创建一台自建MySQL的 源数据库 ECS 实例和一台 目标数据库 RDS。首先,远程登陆到 源数据库 ,查看源数据库中的信息。然后,登陆到阿里云管理控制台,建立目标数据库。最后,使用 数据传输 服务,实现ECS自建数据库迁移到目标数据库RDS。
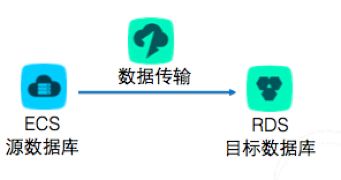
实验目标
完成此实验后,可以掌握的能力有:
-
建立RDS数据库
-
通过数据传输服务,将ECS上自建MySQL数据库迁移到RDS数据库。
学前建议
- 了解RDS数据库的基本概念
- 了解ECS的基本概念
实验过程
查看源数据库结构和数据
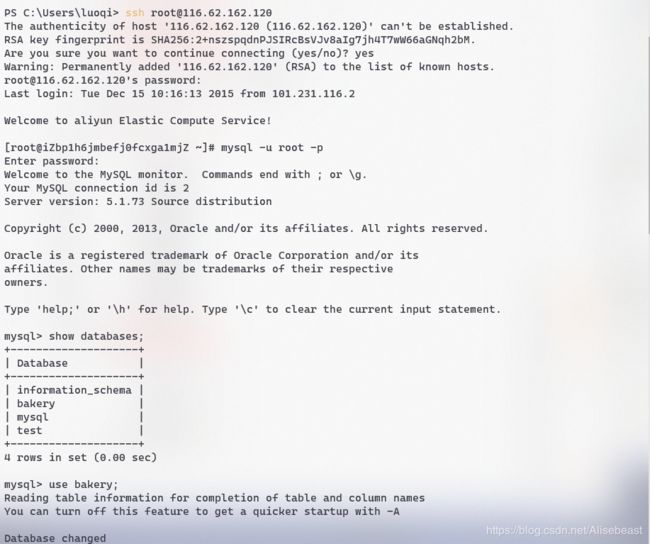
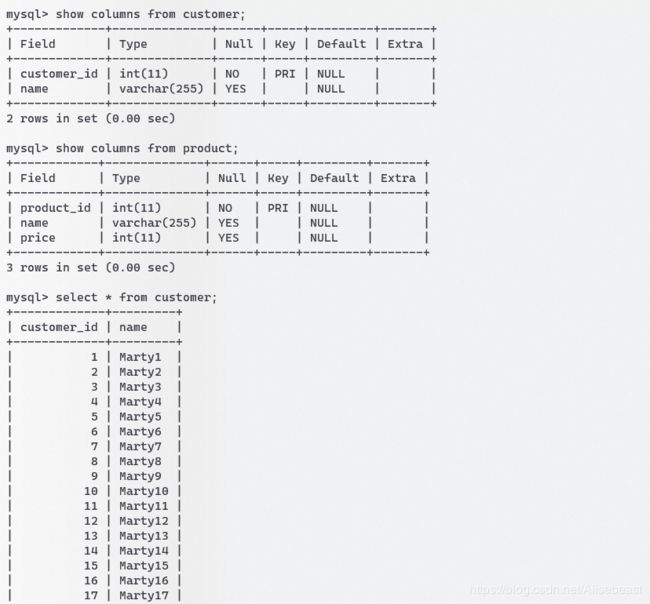

准备好RDS数据库

进行数据迁移
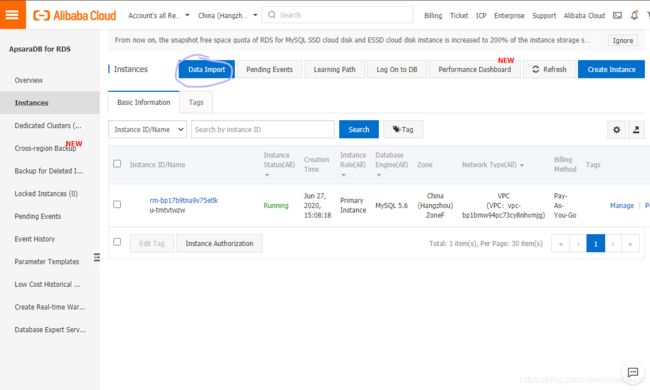
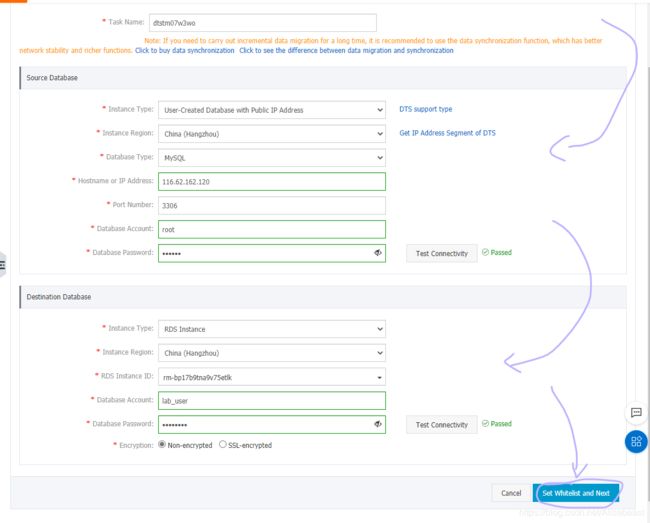

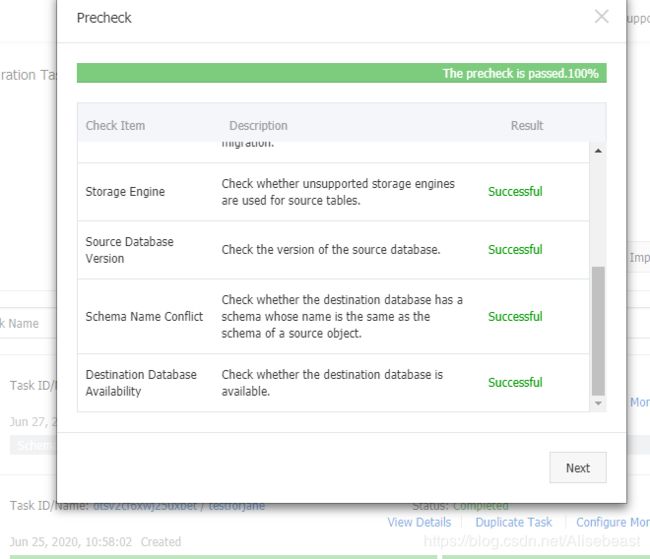


验证迁移完成


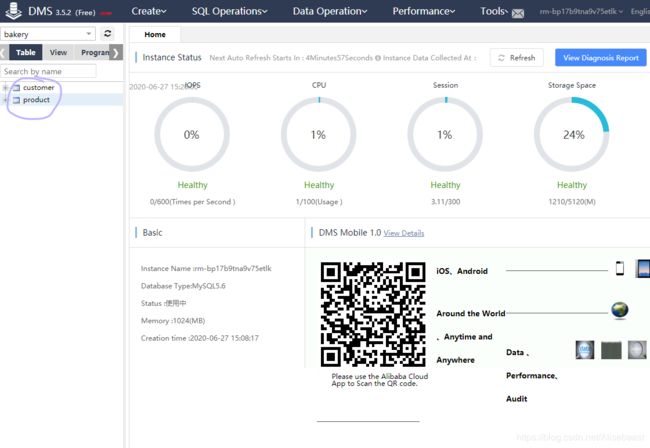
5 - 云存储OSS使用初体验
实验概述
开始实验后,系统会自动去创建一台Linux ECS。其中,创建的ECS中已经部署了web应用和OSS python SDK。在本实验中,已创建的ECS作为web服务器,浏览器中直接访问其IP地址会显示包含四个小图片的页面,并且四个图片都保存在ECS本地。通过调用OSS API将四个图片上传到OSS中,同时删除保存在ECS本地的四个图片,此时访问ECS IP将会看到页面中没有图片可以显示。为了在页面中显示原有的四个图片,实验中需要修改web应用服务器根目录下默认访问页面中的图片地址,将图片地址修改为四个图片分别在OSS中的访问地址。
实验目标
完成此实验后,可以掌握的能力有:
-
通过阿里云管理控制台管理对象存储服务OSS
-
在实际的web开发中使用对象存储服务OSS存储页面中的图片
-
调用OSS API上传图片
学前建议
-
掌握Linux基本命令;
-
了解OSS的基本概念
背景知识
阿里云对象存储(Object Storage Service,简称OSS),是阿里云对外提供的海量、安全、低成本、高可靠的云存储服务。用户可以通过调用API,在任何应用、任何时间、任何地点上传和下载数据,也可以通过用户Web控制台对数据进行简单的管理。OSS适合存放任意文件类型,适合各种网站、开发企业及开发者使用。
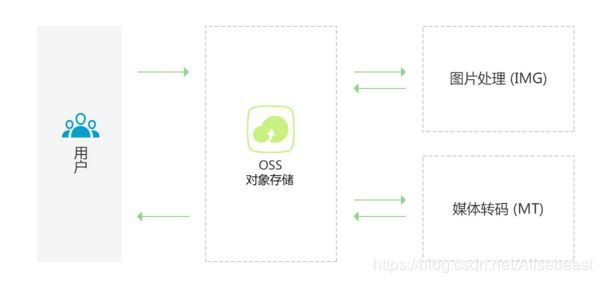
阿里云OSS图片处理服务(Image Service,简称 IMG) ,是阿里云OSS对外提供的海量、安全、低成本、高可靠的图片处理服务。用户将原始图片上传保存在OSS上,通过简单的 RESTful 接口,在任何时间、任何地点、任何互联网设备上对图片进行处理。图片处理服务提供图片处理接口,图片上传请使用OSS上传接口。基于IMG,用户可以搭建出跟图片相关的服务。图片服务处理的图片来自于OSS,所以图片的上传实际是上传到OSS的同名Bucket中。
在真实的工作场景中,一般将图片、音频、视频等存储到OSS服务中,这样可以极大的提高用户的页面访问速度。
实验过程
上传图片文件
- 修改配置文件
vim /alidata/www/default/cfg.json
![]()
根据自己的情况填写以下信息
-
id:云中沙箱 实验资源 分配的 AK ID 值
-
secret:云中沙箱 实验资源 分配的 AK Secret 值
-
endpoint:请根据下面的 OSS地域与Endpoint对应关系表,输入 实验资源 所分配 地域 相对应的 外网Endpoint 。例如:分配的 地域
为 华东1(杭州),则输入 oss-cn-hangzhou.aliyuncs.com。
-
bucket:云中沙箱 实验资源 分配的 OSS资源 Bucket 名称
-
object_dir:云中沙箱 实验资源 分配的 OSS资源 Object路径。
OSS地域与外网Endpoint对应关系表:
地域 外网Endpoint 华东 1 (杭州) oss-cn-hangzhou.aliyuncs.com 华东 2 (上海) oss-cn-shanghai.aliyuncs.com 华北 1 (青岛) oss-cn-qingdao.aliyuncs.com 华北 2 (北京) oss-cn-beijing.aliyuncs.com 华南 1 (深圳) oss-cn-shenzhen.aliyuncs.com
- 上传图片到OSS

python oss_upload.py 01.png

使用OSS存储图片分享网站
-
删除ECS中的图片资源文件
cd /alidata/www/default rm -rf *.png -
将index.html的图片访问信息修改为OSS的URL访问地址



6 - 使用OSS API上传和下载文件
实验概述
实验开始后,系统会自动去创建一台Linux ECS。且ECS实例已经部署了OSS python SDK。用户可以使用OSS Python SDK来访问OSS服务,包括上传文件,下载文件,查看文件列表等。默认这些程序是写在一个脚本文件里,通过Python程序可以执行。OSS上传方式大致可以分为两类:简单上传和分块上传。本实验通过OSS的Python SDK,使用简单上传的方式实现小文件的上传和下载;最后指导您实现如何去删除OSS Bucket。
实验目标
完成此实验后,可以掌握的能力有:
-
使用OSS python SDK来调用OSS API
-
掌握OSS简单上传的方式
-
掌握OSS分块上传的方式
-
使用OSS python SDK快速删除OSS Object
学前建议
-
了解Linux的基本命令操作;
-
了解Python语言的基本使用方法;
背景知识
阿里云对象存储(Object Storage Service,简称OSS),是阿里云对外提供的海量、安全、低成本、高可靠的云存储服务。使用 OSS,您可以通过网络随时存储和调用包括文本、图片、音频和视频等在内的各种结构化或非结构化数据文件。以下的术语为OSS相关的基本概念:
- Bucket,是一个用户用来管理所存储Object的存储空间。 每个用户可以拥有多个Bucket。Bucket的名称在OSS的范围内必须是全局唯一的,一旦创建之后无法修改名称。Bucket内部的Object数目是没有限制的。
- Object,是OSS存储数据的基本单元,称为OSS的对象,也被称为OSS的文件。根据不同的上传方式,Object的大小限制是不一样的。Object由元信息(Object Meta),用户数据(Data)和文件名(Key)组成。Object由一个在Bucket内部唯一的Key来标示。Object操作在OSS上具有原子性,操作要么成功要么失败,不会存在有中间状态的Object。OSS保证用户一旦上传完成之后读到的Object是完整的,OSS不会返回给用户一个只上传成功了部分的Object。分片上传最大支持48.8TB的Object,其他的上传方式最大支持5GB。
- Region,表示OSS的数据中心所在的区域,物理位置。 一旦指定之后就不允许更改,该Bucket下所有的Object都存储在对应的数据中心。
- Endpoint,表示OSS对外服务的访问域名。OSS以HTTP REST API的形式对外提供服务,当访问不同的Region的时候,需要不同的域名。
用户可以通过调用API,在任何应用、任何时间、任何地点上传和下载数据,也可以通过阿里云Web控制台对数据进行简单的管理。目前阿里云OSS支持如下几种语言版本的SDK调用API:Python SDK,Java SDK,Android SDK,iOS SDK,JavaScript SDK,.NET SDK,PHP SDK,Ruby SDK,C SDK,Go SDK,Media-C SDK。本实验中主要介绍如何使用Python SDK调用OSS API实现文件的简单上传,下载和删除等操作。
OSS作为对象存储提供商,常用的使用场景如下:
- 适用于图片、音视频、日志等海量文件的存储,支持各种终端设备,Web网站程序和移动应用直接向OSS写入或读取数据,支持 流式写入 和 文件写入 两种方式。

- 开发者不仅可以直接使用OSS,利用BGP带宽,实现超低延时的数据直接下载;OSS也可以配合阿里云CDN加速服务,为图片、音视频、移动应用更新分发,提供最佳体验等场景。

- 上传文件到OSS后,可以配合媒体转码服务(MTS),图片处理服务(IMG)进行云端的数据处理。
实验过程
上传文件
-
配置配置文件
cd aliyun-lab vim configure.jsonid-参数值为本实验中,实验资源 分配的AK ID; secret-参数值为本实验中,实验资源 分配的AK Secret; endpoint-参数值为本实验中,实验资源 的“地域”对应的“外网Endpoint”数值。比如:提供的“地域”为“华东 1(杭州)”,则选择“华东 1(杭州)”的“外网Endpoint”。
OSS 地域与外网 Endpoint 的对应关系如下表:
地域 外网Endpoint 华东 1 (杭州) oss-cn-hangzhou.aliyuncs.com 华东 2 (上海) oss-cn-shanghai.aliyuncs.com 华北 1 (青岛) oss-cn-qingdao.aliyuncs.com 华北 2 (北京) oss-cn-beijing.aliyuncs.com 华南 1 (深圳) oss-cn-shenzhen.aliyuncs.com
![]()
-
修改object_upload.py脚本
# -*- encoding:utf8 -*- #Date: Fri. Feb 25th 2016 #Author: Tansy B. import oss2 import json import sys __access_key = '' __access_secret = '' __oss_endpoint = '' __bucket_name = '' #目标bucket名 __file_name = '' #本地文件,如果是在脚本相同的路径中,则只需填写文件名。否则,提供完整的文件路径。 __object_name = '' #上传的object名称 if __name__ == '__main__': #判断输入的Access Key Id, Access key secret以及endpoint是否为空。 json_data = open('configure.json','r') cfg = json.load(json_data) if cfg['id'] =='' or cfg['secret'] == '': print ('Please set up your access_key, access_secret') sys.exit(1) if cfg['endpoint'] == '': print('Please enter your oss endpoint') sys.exit(1) #从configure.json中读取如下参数值: __access_id = cfg['id'] __access_secret = cfg['secret'] __oss_endpoint = cfg['endpoint'] json_data.close() #获取用户输入的bucket名称,并在bucket后增加AK的ID信息,避免出现bucket重复的情况 if len(sys.argv) < 4 : print "Missing bucket, local file or object name!\n" print "Usage: python object_upload.py\n" -
执行脚本,上传文件到OSS
python object_upload.py <oss bucket名称> lab.txt <oss object路径>/lab_object.txt

下载文件
-
修改下载脚本object_download.py
# -*- encoding:utf8 -*- #Date: Fri. Feb 26th 2016 #Author: Tansy B. import oss2 import json import sys __access_key = '' __access_secret = '' __service_endpoint = '' __bucket_name = '' #目标Bucket名 __object_name = '' #Bucket中目标object名 __local_name = '' #下载到本地的文件名 if __name__ == '__main__': #判断输入的Access Key Id, Access key secret以及endpoint是否为空。 json_data = open('configure.json','r') cfg = json.load(json_data) if cfg['id'] =='' or cfg['secret'] == '': print ('Please set up your access_key, access_secret') sys.exit(1) if cfg['endpoint'] == '': print('Please enter your oss endpoint') sys.exit(1) #从configure.json中读取如下参数值: __access_id = cfg['id'] __access_secret = cfg['secret'] __oss_endpoint = cfg['endpoint'] json_data.close() #获取用户输入的bucket名称,并在bucket后增加AK的ID信息,避免出现bucket重复的情况 if len(sys.argv) < 4 : print "Missing bucket, local file or object name!\n" print "Usage: python object_download.py -
下载文件
python object_download.py <oss bucket 名称> <oss object路径>/lab_object.txt lab_local.txt

删除Object
-
修改object_delete.py脚本
# -*- encoding:utf8 -*- #Date: Fri. Feb 26th 2016 #Author: Tansy B. import oss2 import json import sys __access_key = '' __access_secret = '' __service_endpoint = '' __bucket_name = '' #目标bucket名 __object_name = '' #删除object名 if __name__ == '__main__': #判断输入的Access Key Id, Access key secret以及endpoint是否为空。 json_data = open('configure.json','r') cfg = json.load(json_data) if cfg['id'] =='' or cfg['secret'] == '': print ('Please set up your access_key, access_secret') sys.exit(1) if cfg['endpoint'] == '': print('Please enter your oss endpoint') sys.exit(1) #从configure.json中读取如下参数值: __access_id = cfg['id'] __access_secret = cfg['secret'] __oss_endpoint = cfg['endpoint'] json_data.close() #获取用户输入的bucket名称,并在bucket后增加AK的ID信息,避免出现bucket重复的情况 if len(sys.argv) < 3 : print "Missing bucket, local file or object name!\n" print "Usage: python object_delete.py -
执行脚本,删除OSS文件
python object_delete.py <Bucket 名称> <Object路径>/lab_object.txt

创建OSS Bucket
-
编写脚本bucket_create.py
# -*- encoding:utf8 -*- #Date: Fri. Feb 24th 2016 #Author: Tansy B. import oss2 import json import sys __access_id = '' __access_secret = '' __oss_endpoint = '' __bucket_name =''# 新建的bucket名 if __name__ == '__main__': #判断输入的Access Key Id, Access key secret以及endpoint是否为空。 json_data = open('configure.json','r') cfg = json.load(json_data) if cfg['id'] =='' or cfg['secret'] == '': print ('Please set up your access_key, access_secret') sys.exit(1) if cfg['endpoint'] == '': print('Please enter your oss endpoint') sys.exit(1) #从configure.json中读取如下参数值: __access_id = cfg['id'] __access_secret = cfg['secret'] __oss_endpoint = cfg['endpoint'] json_data.close() #获取用户输入的bucket名称,并在bucket后增加AK的ID信息,避免出现bucket重复的情况 if len(sys.argv) == 1: print 'Missing bucket name!\n' print 'Usage: python bucket_create.py\n' print 'For example: python bucket_create.py lab\nlab is a new oss bucket name' sys.exit(1) else: __bucket_name = sys.argv[1] + '-' + __access_id.lower() #用于鉴权并连接OSS的Service和Bucket auth = oss2.Auth(__access_id, __access_secret) service = oss2.Service(auth,__oss_endpoint) bucket = oss2.Bucket(auth, __oss_endpoint, __bucket_name) #创建一个新的bucket print 'Start Creating a bucket' #调用OSS API的create_bucket()创建bucket result = bucket.create_bucket() print 'Your bucket Create Successfully' print 'Your new bucket is: ', __bucket_name
删除OSS Bucket
-
编写脚本
# -*- encoding:utf8 -*- #Date: Fri. Feb 26th 2016 #Author: Tansy B. import oss2 import json import sys __access_key = '' __access_secret = '' __service_endpoint = '' __bucket_name = ''# 删除的bucket名 if __name__ == '__main__': #判断输入的Access Key Id, Access key secret以及endpoint是否为空。 json_data = open('configure.json','r') cfg = json.load(json_data) if cfg['id'] =='' or cfg['secret'] == '': print ('Please set up your access_key, access_secret') sys.exit(1) if cfg['endpoint'] == '': print('Please enter your oss endpoint') sys.exit(1) #从configure.json中读取如下参数值: __access_id = cfg['id'] __access_secret = cfg['secret'] __oss_endpoint = cfg['endpoint'] json_data.close() #获取用户输入的bucket名称,并在bucket后增加AK的ID信息,避免出现bucket重复的情况 if len(sys.argv) == 1: print 'Missing bucket name!\n' print 'Usage: python bucket_delete.py\n' print 'For example: python bucket_delete.py lab\nlab is a new oss bucket name' sys.exit(1) else: __bucket_name = sys.argv[1] #用于鉴权并连接OSS的Service和Bucket auth = oss2.Auth(__access_id, __access_secret) service = oss2.Service(auth,__oss_endpoint) bucket = oss2.Bucket(auth, __oss_endpoint, __bucket_name) #删除Bucket print 'Start Deleting Bucket...\n' try: #调用delete_bucket()删除bucket bucket.delete_bucket() print 'You successfully delete the bucket' #删除的bucket必须为空 except oss2.exceptions.BucketNotEmpty: print 'The bucket',__bucket_name,'is not empty. You need to empty the bucket at first.\n' #展示不空的bucket中存在的所有object for obj in oss2.ObjectIterator(bucket, delimiter='/'): if obj.is_prefix(): print('directory: ' + obj.key) else: print('Object List: ' + obj.key) #删除的bucket必须存在 except oss2.exceptions.NoSuchBucket: print 'The bucket',__bucket_name,'does not exist'
7 - 负载均衡使用初体验
实验概述
拥有大量用户的企业,经常会面临如下的难题:在高并发的情况下,经常会导致服务器响应速度慢,严重的情况会直接导致服务器停止服务。此时,会导致企业的业务中断,影响客户的正常访问。
本实验通过使用阿里云负载均衡SLB以及对负载均衡SLB后端服务器ECS的权重进行修改,可以快速解决上述的问题。
实验目标
完成此实验后,可以掌握的能力有:
-
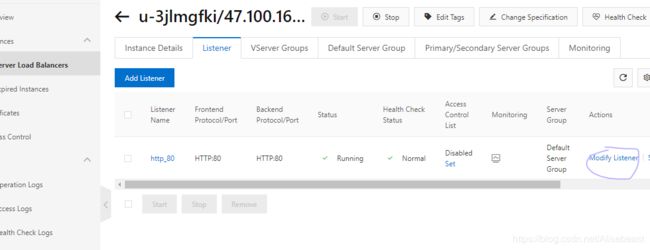
配置负载均衡SLB的监听规则,并将ECS实例部署到SLB后端;
-
通过设置负载均衡SLB后端服务器ECS的权重值,分配用户访问后端ECS实例的比例。
学前建议
- 熟悉阿里云管理控制台的使用方式。
背景知识
负载均衡采用集群部署,可实现会话同步,以消除服务器单点故障,提升冗余,保证服务的稳定性。
阿里云当前提供四层(TCP协议和UDP协议)和七层(HTTP和HTTPS协议)的负载均衡服务。
- 四层采用开源软件LVS(Linux Virtual Server)+ keepalived的方式实现负载均衡,并根据云计算需求对其进行了个性化定制。
- 七层采用Tengine实现负载均衡。Tengine是由淘宝网发起的Web服务器项目,它在Nginx的基础上,针对有大访问量的网站需求,添加了很多高级功能和特性。
阿里云负载均衡
简介
**负载均衡(Server Load Balancer)**是将访问流量根据转发策略分发到后端多台云服务器(ECS实例)的流量分发控制服务。负载均衡扩展了应用的服务能力,增强了应用的可用性。
负载均衡通过设置虚拟服务地址,将添加的ECS实例虚拟成一个高性能、高可用的应用服务池,并根据转发规则,将来自客户端的请求分发给云服务器池中的ECS实例。
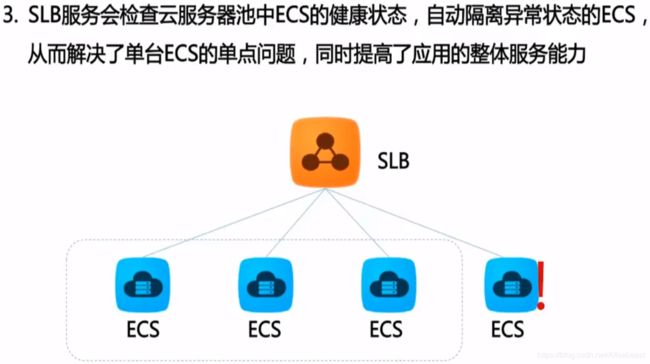
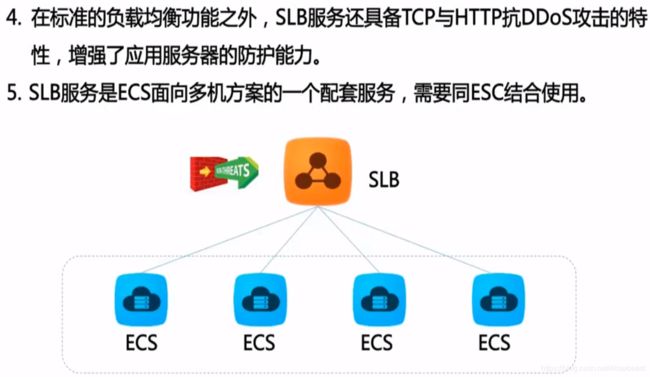
负载均衡默认检查云服务器池中ECS实例的健康状态,自动隔离异常状态的ECS实例,消除了单台ECS实例的单点故障,提高了应用的整体服务能力。此外,负载均衡还具备抗DDoS攻击的能力,增强了应用服务的防护能力。
架构
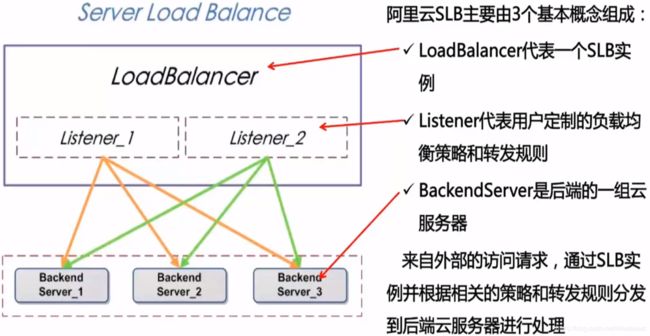
负载均衡服务主要有三个核心概念:
负载均衡实例 (Server Load Balancer instances)
一个负载均衡实例是一个运行的负载均衡服务,用来接收流量并将其分配给后端服务器。要使用负载均衡服务,您必须创建一个负载均衡实例,并至少添加一个监听和两台ECS实例。
监听 (Listeners)
监听用来检查客户端请求并将请求转发给后端服务器。监听也会对后端服务器进行健康检查。
后端服务器(Backend Servers)
一组接收前端请求的ECS实例。您可以单独添加ECS实例到服务器池,也可以通过虚拟服务器组或主备服务器组来批量添加和管理。

特点
1)负载均衡服务通过设置虚拟服务地址(IP),将位于同一地域(Region)的多台云服务器(Elastic Compute Service,简称ECS)资源虚拟成一个高性能、高可用的应用服务池;根据应用指定的方式,将来自客户端的网络请求分发到云服务器池中。
2)负载均衡服务会检查云服务器池中ECS的健康状态,自动隔离异常状态的ECS,从而解决了单台ECS的单点问题,同时提高了应用的整体服务能力。在标准的负载均衡功能之外,负载均衡服务还具备TCP与HTTP抗DDoS攻击的特性,增强了应用服务器的防护能力。
3)负载均衡服务是ECS面向多机方案的一个配套服务,需要同ECS结合使用。
产品优势
-
高可用
采用全冗余设计,无单点,支持同城容灾。搭配DNS可实现跨地域容灾,可用性高达99.95%。
根据应用负载进行弹性扩容,在流量波动情况下不中断对外服务。
-
可扩展
您可以根据业务的需要,随时增加或减少后端服务器的数量,扩展应用的服务能力。
-
低成本
与传统硬件负载均衡系统高投入相比,成本可下降60%。
-
安全
结合云盾,可提供5Gbps的防DDOS攻击能力。
阿里云负载均衡基础架构
负载均衡采用集群部署,可实现会话同步,以消除服务器单点故障,提升冗余,保证服务的稳定性。
阿里云当前提供四层(TCP协议和UDP协议)和七层(HTTP和HTTPS协议)的负载均衡服务。
- 四层采用开源软件LVS(Linux Virtual Server)+ keepalived的方式实现负载均衡,并根据云计算需求对其进行了个性化定制。
- 七层采用Tengine实现负载均衡。Tengine是由淘宝网发起的Web服务器项目,它在Nginx的基础上,针对有大访问量的网站需求,添加了很多高级功能和特性。
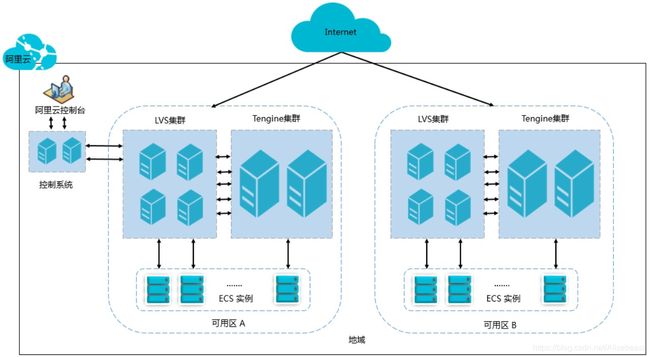
如下图所示,各个地域的四层负载均衡实际上是由多台LVS机器部署成一个LVS集群来运行的。采用集群部署模式极大地保证了异常情况下负载均衡服务的可用性、稳定性与可扩展性。

实验步骤
部署负载均衡后端服务器
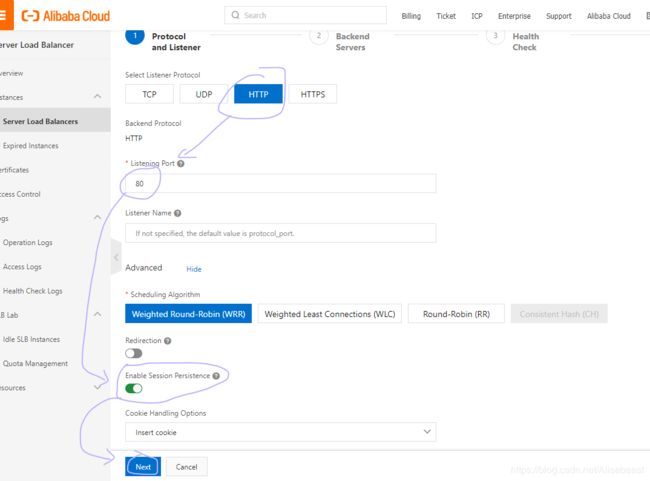
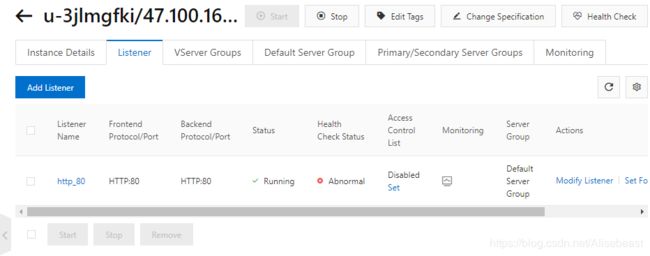
此处Enable Session Persistence(开启会话保持)应该为关闭,因为开启了之后,同一个IP在一段时间内会一直分配到同一个ECS服务器
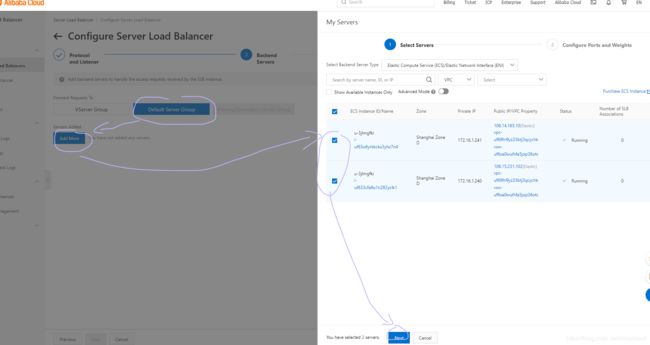




验证负载均衡工作原理
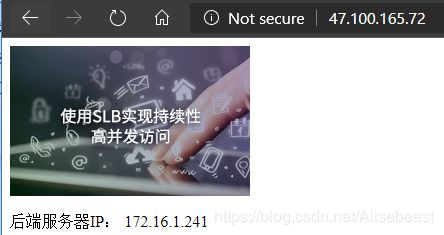
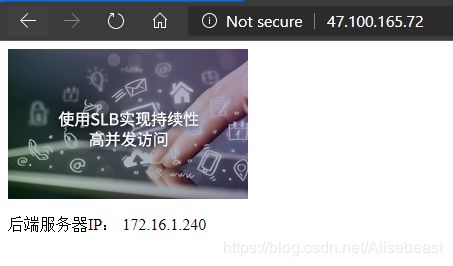
验证负载均衡的监控状态
Enable Session Persistence trun on(开启会话保持),然后访问均衡负载IP

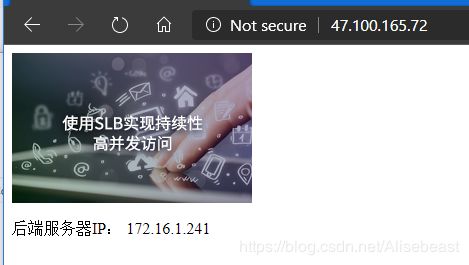
关闭IP为172.16.1.241的服务器

8 - 高并发访问时流量分发和会话保持的实现
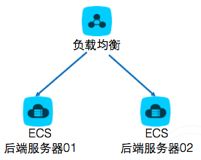
实验概述
开始实验后,系统会自动创建两台ECS实例,以及一台阿里云负载均衡服务。两台WEB服务器分别部署了不同的图片。首先登陆阿里云管理控制台,在负载均衡服务中添加监听配置,从而实现服务器的流量分发,将用户的请求分发到不同的WEB服务器上。然后,开启阿里云负载均衡服务的会话保持功能,从而实现在某个时间段内将来自同一IP地址的访问请求,发送到相同的服务器上。
实验目标
完成此实验后,可以掌握的能力有:
-
在高并发的情况下,使用阿里云负载均衡服务的加权轮询,实现服务器的流量分发功能;
-
使用阿里云负载均衡服务,实现服务器在短时间内的会话保持功能。
#### 学前建议
- 了解负载均衡的基本概念
实验步骤
其实这个实验和前一个实验基本一致,操作步骤和会话保持的功能都实验过了,因此就不多说了。
9 - 暗骑士初体验
实验概述
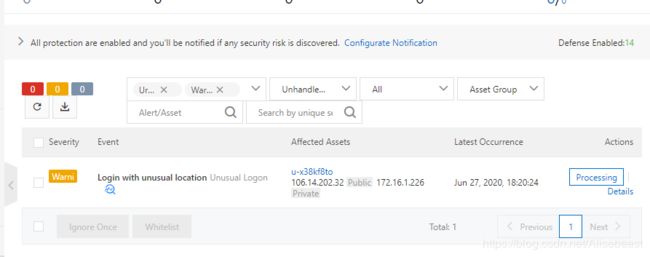
本实验将介绍并使用安骑士的基本功能“木马查杀”,“补丁管理”,“安全管理”和“安全运维”。云中沙箱平台会自动创建一台已部署Phpwind站点的ECS云服务器实例。首先,模拟“暴力破解”ECS密码的情况,查看“拦截信息”。然后,设置“常用登陆地”,查看异地登录情况。最后,简要介绍安骑士的“补丁管理”,“木马查杀”等。
实验目标
完成此实验后,可以掌握的能力有:
-
通过管理控制台,使用安骑士服务;
-
安骑士的不同版本之间的区别。
学前建议
-
了解ECS的基本功能
-
了解安全方面的基础知识。
背景知识
越来越多的企业开始使用阿里云的各种服务,比如ECS,RDS,负载均衡等等。随之而来的是用户最关心的安全问题:比如,因为用户使用通用软件的漏洞而被黑客入侵;Web服务器(内部/外部)被黑客入侵窃取网站的核心数据等。
因此,阿里云推出云盾服务。云盾是阿里巴巴集团多年来安全技术研究积累的成果,它结合阿里云云计算平台强大的数据分析能力,为中小网站提供如安全漏洞检测、网页木马检测以及面向云服务器用户提供的主机入侵检测、防DDoS等一站式安全服务。阿里云对于安全方面,可谓“十年攻防,一朝成盾”:

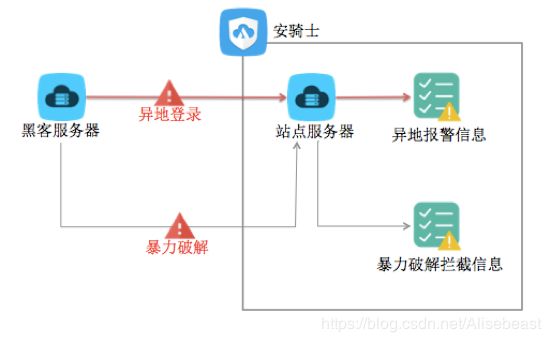
服务器安全(安骑士)是云盾的一款服务器安全运维管理产品。通过安装在服务器上的轻量级Agent插件与云端防护中心的规则联动,实时感知和防御入侵事件,从而保障服务器的安全。
服务器安全(安骑士)的架构图,如下图:
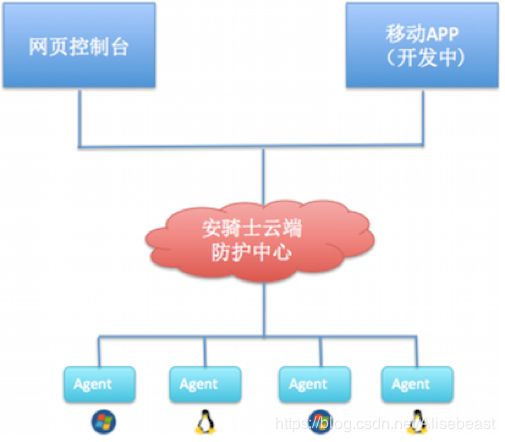
阿里云平台默认为用户开通安骑士的 基础版,若用户希望可以通过安骑士深度维护云服务器,可以购买 专业版,增强版 或 企业版。不同版本提供不同的服务。

安骑士主要提供五大服务:
- 木马查杀:服务器安全(安骑士)Agent将自动识别服务器的Web目录,对服务器的Web目录进行后门文件扫描,每天凌晨将会对Web目录进行一次扫描,同时若Web目录文件发生变化也会触发单次单文件扫描。
- 补丁管理:支持通用Web软件漏洞扫描和Windows系统漏洞扫描,当前扫描周期为1天。不仅如此,当前漏洞补丁均为云盾自研补丁,快于官方补丁推出。用户可以通过控制台的 一键修复 功能,实现漏洞批量修复和回滚。
- 安全巡检:支持 手动巡检 和 周期巡检 两种方式。手动巡检 主要对服务器常见系统配置缺陷进行检测,包括对可疑系统账户、弱口令、注册表等进行检测。用户也可设置周期检测时间定期对自己的服务器进行安全体检。
- 主机防火墙:支持TCP,UDP和HTTP三种协议的自定义访问控制;共享云盾恶意IP库,直接将恶意IP进行拦截;支持Web攻击拦截策略自定义;不但可以记录4层和7层策略的命中情况,而且允许近1个月的记录查看和数据导出。
- 安全运维:支持Shell命令(Linux)、BAT命令(Windows),非交互式命令;支持在服务器安全(安骑士)控制台一键下发脚本命令,支持运行账户切换、权限切换;支持对运行结果在线查看和导出结果查看。
实验步骤
本次实验将会配置站点服务器,并模拟黑客攻击,测试安骑士的效果。
配置安骑士
添加本地IP到暗骑士白名单




用另一台ECS服务器模拟黑客登陆


10 - 云监控初体验
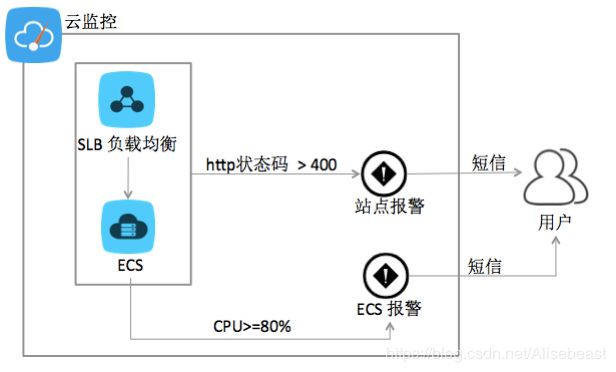
实验概述
本实验会自动创建一台已部署Nginx的ECS实例和一台负载均衡SLB实例。首先,使用阿里云云监控的 云服务监控 服务,配置并查看ECS实例和SLB实例的监控数据。然后,设置ECS实例的报警规则,并验证报警规则生效。之后,使用 站点监控 服务,监控已部署Nginx的站点的状态,并设置站点报警规则,验证报警规则。最后,清理云监控中的监控资源。
实验目标
完成此实验后,可以掌握的能力有:
-
使用云监控的管理控制台,监控ECS等阿里云产品
-
创建报警规则,及时获取阿里云服务或站点的异常状态;
-
使用站点监控,对网站进行监控。
-
清理云监控中的监控资源
学前建议
了解ECS和SLB的基本操作
背景知识
云监控(CloudMonitor)作为云服务的监控管理入口,能让用户快速了解各产品实例的状态和性能。云监控从站点监控、云服务监控、自定义监控三个方面来为用户提供服务。通过云监控管理控制台,用户可以看到当前服务的监控项数据图表,清晰了解服务运行情况。并通过设置报警规则,管理监控项状态,及时获取异常信息。云监控目前免费限量为用户提供监控服务。
云监控为用户提供了非常丰富的使用场景:
- 云服务监控:用户购买和使用云监控支持的阿里云服务后,可监控多种阿里云云服务的各项基础指标,比如:ECS的CPU使用率、内存使用率、公网流出流速(带宽)等。确保实例的正常使用,避免因为对资源的过度使用造成用户业务无法正常运转。云监控会根据用户设置的报警规则,在监控数据达到报警阈值时,发送报警信息。用户可以及时获取异常通知,并查询服务异常的原因。
目前,云服务监控对用户开放的产品包括云服务器ECS、云数据库RDS、负载均衡、云数据库Memcache版、对象存储OSS、CDN、弹性公网IP、云数据库Redis版、消息服务、日志服务等,其它云产品的监控会陆续加入进来。
- 站点监控:支持提供多种协议的监控设置,可探测您站点的可用性、响应时间、丢包率。让用户全面了解站点的可用性,并在发生异常时,可以及时处理。
站点监控目前支持8种协议的探测,探测点包括:杭州、青岛、北京,探测频率支持:1分钟、5分钟、15分钟。
-
自定义监控:补充“云服务监控”的不足,如果云监控服务未能提供您需要的监控项,那么,用户可以创建新的监控项并采集监控数据上报到云监控,云监控会对新的监控项提供“监控图表”展示和“报警”功能。
本实验主要介绍如何使用云服务监控,以及使用“站点监控”对用户自建的网站进行监控。通过设置报警规则,用户可以及时发现站点的异常情况,并做出及时的处理。
实验步骤
此处也不多说了,因为和上一个实验差别不大,实验了更多渠道的监控功能,例如网站指定状态码报警(比如出现404,403之类的),还有其他的监控报警功能,负载均衡监听什么的。
致谢
感谢阿里云让我免费获得了这次参加ACA认证的机会,欢迎大家也一起加入~
加入阿里云高校计划~