Spring Data JPA介绍与Spring的整合
一、JPA 、Hibernate、Spring Data JPA与Spring Data简介
Spring Data JPA官网介绍:https://spring.io/projects/spring-data-jpa
1、什么是JPA?
JPA(Java Persistence API)是Sun官方提出的Java持久化API规范。可以通过JDK 5.0注解或者XML描述【对象-关系表】之间的映射关系,并将实体对象持久化到数据库中。主要是为了简化现有的持久化开发工作和整合ORM技术,使得应用程序以统一的方式访问持久层。
2、什么是Hibernate?
Hibernate 是一个开源的全自动的ORM框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,Hibernate 是一个实现了 ORM 思想的框架,封装了 JDBC。
3、什么是Spring Data JPA?
Spring Data JPA是Spring提供的一套简化JPA开发的框架,它是在JPA规范下提供了Repository层的实现,按照约定好的【方法命名规则】写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
Spring Data JPA的功能实现默认使用的Hibernate,也可以使用其他持久层框架。
4、什么是Spring Data?
Spring Data项目是为了简化构建基于Spring框架应用的数据访问技术,是Spring官方提供的一套数据层的综合解决方案。(或者可以封装其他的持久层解决方案的一个解决方案)。它支持关系型数据库、非关系型数据库、Map-Reduce框架、云数据服务等。
Spring Data 包含很多个子模块:
- Commons - 提供共享的基础框架,适合各个子项目使用,支持跨数据库持久化
- Hadoop - 基于 Spring 的 Hadoop 作业配置和一个 POJO 编程模型的 MapReduce 作业
- Key-Value - 集成了 Redis 和 Riak ,提供多个常用场景下的简单封装
- Document - 集成文档数据库:CouchDB 和 MongoDB 并提供基本的配置映射和资料库支持
- Graph - 集成 Neo4j 提供强大的基于 POJO 的编程模型
- Graph Roo AddOn - Roo support for Neo4j
- JDBC Extensions - 支持 Oracle RAD、高级队列和高级数据类型
- JPA - 简化创建 JPA 数据访问层和跨存储的持久层功能
- Mapping - 基于 Grails 的提供对象映射框架,支持不同的数据库
- Examples - 示例程序、文档和图数据库
- Guidance - 高级文档

Spring Data JPA是Spring Data的一个模块。
5、它们之间的关系
JPA是一套ORM规范接口,接口是需要实现才能工作。而 Hibernate就是实现了JPA接口的ORM框架。
Spring Data JPA 可以理解为 JPA 规范的再次封装抽象,底层默认还是使用了 Hibernate 对JPA 技术实现。
Spring Data JPA是Spring Data的一个模块。
按照时间线来说就明白了
- 开发 Hibernate 的团队开发了 Hibernate
- 制订 J2ee 规范的团队邀请 Hibernate 的核心在 Hibernate 基础上制订了 JPA (Java Persistent API)标准。从功能上看,JPA 是 Hibernate 的子集。
- Spring 的团队使用 Spring 对 JPA 做了封装,就是 Spring Data JPA 了。
总之,JPA 是一个 API 标准,除了 Hibernate 外,还有其它厂商的实现,例如 Eclipse 的 TopLink。Spring Data Jpa 是个对 JPA 的封装,帮助程序员以 Spring 的方式来使用 JPA。
6、一些名词含义
ORM(Object Relational Mapping):通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。本质就是将关系和对象通过映射文件进行联系。我们在程序中只需要操作对象即可操作对应的数据库表的数据。
POJO(Plain Ordinary Java Object)简单的Java对象,实际就是普通JavaBeans。
HQL(Hibernate Query Language)是面向对象的查询。
JPQL(Java Persistence Query Language)查询语言,通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。
JPA 规范提供了 JPQL ,Hibernate 提供了 HQL来查询数据库。JPQL的原型就是Hibernate 的HQL。


上面内容更多参考这两篇文章,整的明明白白
Hibernate和Spring Data JPA有什么区别?
JPA和SpringDataJPA简介
二、Spring与Spring Data JPA的整合
在实际的工程中,推荐采用 Spring Data JPA + ORM(如:Hibernate)进行开发,这样在切换不同的ORM提供了方面,同时也使得Repository变得简单。程序低耦合。
1、创建一个maven java项目,在 pom.xml 中导入包的依赖

4.0.0
cn.jq.springdatajpademo
springdatajpademo
1.0-SNAPSHOT
org.springframework
spring-context
5.2.7.RELEASE
org.springframework
spring-web
5.2.7.RELEASE
org.springframework
spring-webmvc
5.2.7.RELEASE
org.springframework
spring-tx
5.2.7.RELEASE
org.springframework
spring-aspects
5.2.7.RELEASE
org.springframework
spring-orm
5.2.7.RELEASE
org.springframework
spring-jdbc
5.2.7.RELEASE
org.slf4j
slf4j-log4j12
1.7.25
commons-logging
commons-logging
1.2
org.hibernate
hibernate-core
5.2.17.Final
com.alibaba
druid
1.1.21
org.springframework.data
spring-data-jpa
2.3.1.RELEASE
mysql
mysql-connector-java
5.1.46
com.fasterxml.jackson.core
jackson-databind
2.10.3
com.fasterxml.jackson.datatype
jackson-datatype-jsr310
2.10.3
org.springframework
spring-test
5.2.7.RELEASE
test
junit
junit
4.12
test
org.apache.felix
maven-bundle-plugin
true
2、jdbc.properties :
jdbc.driverClassName=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/springdatajpa_demo?useUnicode=true&characterEncoding=utf8&useSSL=true
jdbc.username=root
jdbc.password=123456
druid.initialSize=5
druid.minIdle=5
druid.maxActive=20
druid.maxWait=5
hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
hibernate.show_sql=true
hibernate.format_sql=true
hibernate.hbm2ddl.auto=update3、log4j.properties :
log4j.rootLogger = debug,stdout, D
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.Threshold = INFO
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p %m%n
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = ./log4j.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern=%d %p %m%n4、spring.xml:
${hibernate.dialect}
${hibernate.show_sql}
${hibernate.format_sql}
${hibernate.hbm2ddl.auto}
5、pojo层
import com.fasterxml.jackson.annotation.JsonFormat;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalDateTimeSerializer;
import org.springframework.format.annotation.DateTimeFormat;
import javax.persistence.*;
import java.time.LocalDateTime;
/**
* 用户的实体类
* 配置映射关系
*
* 1.实体类和表的映射关系
* @Entity:声明实体类
* @Table : 配置实体类和表的映射关系
* name : 配置数据库表的名称
* 2.实体类中属性和表中字段的映射关系
*
*
*/
@Entity
@Table(name = "t_user")
public class User {
/**
* @Id:声明主键的配置
* @GeneratedValue:配置主键的生成策略
* strategy
* GenerationType.IDENTITY :自增,mysql
* * 底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增)
* GenerationType.SEQUENCE : 序列,oracle
* * 底层数据库必须支持序列
* GenerationType.TABLE : jpa提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增
* GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略
* @Column:配置属性和字段的映射关系
* name:数据库表中字段的名称
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String password;
private Integer age;
@JsonFormat(shape = JsonFormat.Shape.STRING, timezone = "GMT+8", pattern = "yyyy-MM-dd HH:mm:ss")
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@JsonSerialize(using = LocalDateTimeSerializer.class)
@Column(name = "create_time")
private LocalDateTime createtime; /** 创建时间*/
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public LocalDateTime getCreatetime() {
return createtime;
}
public void setCreatetime(LocalDateTime createtime) {
this.createtime = createtime;
}
// 空构造
public User() {
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
", age=" + age +
", createtime=" + createtime +
'}';
}
}
6、dao层
import cn.jq.springdatajpademo.model.User;
import org.springframework.data.repository.Repository;
/**
* 符合SpringDataJpa的dao层接口规范
* Repository<操作的实体类类型,实体类中主键属性的类型>
* * Repository标记接口,并没有提供任何操作方法
*/
public interface UserDao extends Repository {
// 定义一个方法(方法名有一定的规则), 不需要做任何的sql实现
User getById(Long id);
} 7、测试类
import cn.jq.springdatajpademo.dao.UserDao;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
/**
* @Description:
* @Auther: leijq
* @Date: 2020-07-06 22:54
* @Version: V1.0
*/
@RunWith(SpringJUnit4ClassRunner.class) //声明spring提供的单元测试环境
@ContextConfiguration(locations = "classpath:spring.xml")//指定spring容器的配置信息
public class UserDaoTest {
@Autowired
private UserDao userDao;
@Test
public void testGetById() {
// 先注释,运行UserDaoTest类,生成表,手动在表中添加一些记录,然后再测试testGetById
// User user = userDao.getById(1L);
// System.out.println(user);
}
}
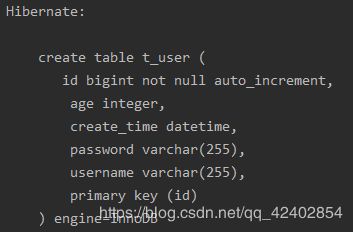

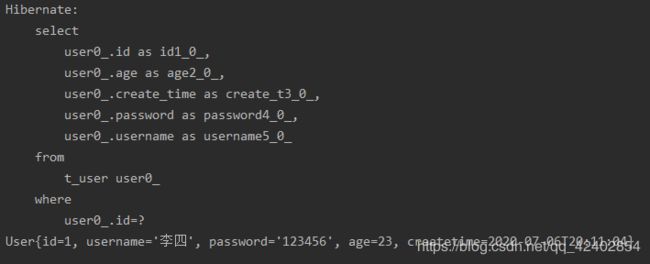
8、测试demo
1)模糊查询
Like需要自己写%,Containing不需要自己写%。
== UserDao ==
List findUsersByUsernameLike(String username);
List findUsersByUsernameContaining(String username);
== test ==
@Test
public void testFindUsersByUsernameLike(){
List users = userDao.findUsersByUsernameLike("%李%");
System.out.println(users);
}
@Test
public void testFindUsersByUsernameContaining(){
List users = userDao.findUsersByUsernameContaining("李");
System.out.println(users);
} 2)关联查询
新建一个Role类,User类做好关联,数据库添加点数据。关联对象和它的属性之间用 _ 连接
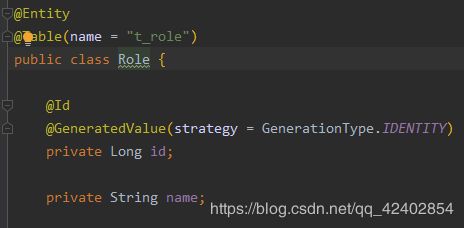
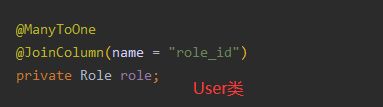
== UserDao ==
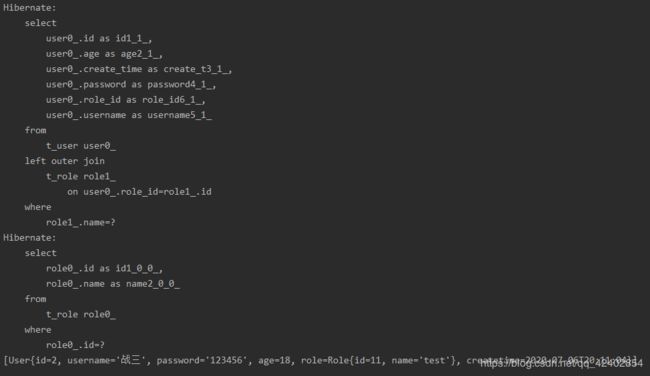
List getUsersByRole_Name(String name);
== test ==
@Test
public void testGetUsersByRole_Name() {
List users = userDao.getUsersByRole_Name("test");
System.out.println(users);
} 
3)自定义JPQL查询语言通过 @query注解来实现
对于复杂的功能,比如,子查询等,需要我们自定义JPQL查询语言
(1)没参数的@query查询:查找age最大User记录
@Query("select u from User u where u.age = (select max(age) from User)")
List listUserByMaxAge(); (2)带参数的@query查询,使用占位符:注意:参数的顺序必须一一对应
@Query("select u from User u where u.username = ?1 and u.password = ?2")
User getUser(String username, String password);(3)带参数的@query查询,使用具名参数:注意:对参数顺序没要求,和@Param注解一起使用
@Query("select u from User u where u.username = :username and u.password =:password")
User getUser2(@Param("username") String username, @Param("password") String password);(4)带参数的@query查询,使用like的时候,是可以用%的,
注意:hibernate和mybatis都是不可以使用的,springdata可以。
@Query("select u from User u where u.username like %?1%")
List listByLike(String username);
@Query("select u from User u where u.username like %:username%")
List listByLike2(@Param("username") String username); (5)使用@query执行原生的sql查询:
@Query(value = "select * from t_user where username like %:username%", nativeQuery = true)
List listByLike3(@Param("username") String username); 9、实现JPQL的修改和删除
在@Query注解的上面加上@Modifying注解,就可以执行update和delete的jpql语句。
== UserDao ==
@Modifying
@Query("update User u set u.age = ?1 where u.id = ?2")
void updateAgeById(Integer age, Long id);
@Modifying
@Query("delete from User u where u.id = ?1")
void deleteById(Long id);
== test ==
@Test
public void test() {
userService.updateAgeById(99, 1L);
userService.deleteById(2L);
}注意:由于Springdata执行update和delete语句需要可写事务支持的,而上面整合使用声明式事务处理,事务是放在service层,所以必须在service层里调用它才可以,如果使用dao层调用会报错。
![]()
Springdata需要事务,那么为什么查询可以直接执行呢?默认情况下Springdata也是有事务的,只不过这个事务是只读事务,不能修改和删除数据库里的记录。另外还要注意一个问题,注解@Modifying是不能做insert语句的,jpql不支持!
三、测试类的实现分析
1、dao层接口继承的Repository接口
查看 Repository接口的源码:该接口中没有定义任何方法,即称之为标记接口

这个标记接口的作用:是把继承它的子接口,比如:UserDao标记为 Repository Bean,Spring就会为这个接口创建代理实现类,并且放入到IOC反转容器里,就像以前自己写的 UserDao的实现类 UserDaoImpl一样。
2、extends Repository
import org.springframework.data.repository.RepositoryDefinition;
@RepositoryDefinition(domainClass = User.class, idClass = Long.class)
public interface UserDao {
// 定义一个方法(方法名有一定的规则), 不需要做任何的sql实现
User getById(Long id);
}3、在dao层的接口中定义方法
遵守一些规定:
1)查询的方法:find或get或read开头
2)查询条件:用关键字链接,涉及属性首写字母大写
3)支持级联查询,关联对象和它的属性之间用 _ 连接
| Keyword | Sample | JPQL snippet |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4、Repository接口的子接口(重点内容)

到此,Spring Data JPA与Spring的简单使用搞定,对于Repository接口的子接口掌握的重点
—— Stay Hungry. Stay Foolish. 求知若饥,虚心若愚。