【算法】牛客网算法初级班(与哈希函数有关的三个结构与并查集)
和哈希函数有关的三个结构与并查集
目录
哈希函数与哈希表
布隆过滤器详解
一致性哈希结构
并查集结构与应用(岛问题)
如果所有的键都是小整数,我们可以用一个数组来实现无序的符号表,将键作为数组的索引而数组中键i处储存的就是它对应的值。
使用散列的查找算法分为两步:
- 用散列函数将被查找的键转化为数组的一个索引。理想情况下,不同的键都能转化为不同的索引值。
- 处理碰撞冲突的过程。两种解决碰撞的方法:拉链法和线性探测法。
散列表是算法在时间和空间上作出权衡的经典例子。
认识哈希函数和哈希表
- 输入域无穷大,输出域有限
- 哈希函数不是随机函数,相同的输入得到相同的输出
- 不同的输入也可能导致相同的输出,即哈希碰撞
- 离散性
散列函数
散列函数的计算过程就是将键转化为数组索引的过程。如果我们有一个能够保存M个键值对的数组,那么我们就需要一个能够将任意键转化为该数组范围内的索引([0,M-1]范围内的整数)的散列函数。
散列函数和键的类型有关。严格地说,对于每种类型的键我们都需要一个与之对应的散列函数。
- 正整数:将整数散列最常用的方法是除留余数法。选择大小为素数M的数组,对于任意正整数k,计算k除以M的余数。如果M不是素数,可能无法利用键中包含的所有信息,可能导致无法均匀地散列散列值。
- 浮点数:如果键是0到1之间的实数,可以将它乘以M并四舍五入得到一个0到M-1之间的索引值。但是有缺陷,因为这种情况下,键的高位起的作用更大,最低位对散列的结果没有影响。修正这个问题的方法是将键表示为二进制数然后再使用除留余数法。
- 字符串:可以将其当做大整数。Java的CharAt()函数能够返回一个char值,即一个非负16位整数。如果R比任何字符的值都大,这种计算相当于将字符串当做一个N位的R进制值,将它除以M并取余。一种叫Horner方法的经典算法用N次乘法、加法和取余来计算一个字符串的散列值。只要R足够小,不造成溢出,那么结果就能如我们所愿,落在0~M-1之间。
- 组合键:如果键的类型含有多个整型变量,可以将它们混合起来。
Java的约定:每种数据类型都需要相应的散列函数,于是Java令所有数据类型都继承了一个能够返回一个32比特整数的hashCode()方法。每一种数据类型的hashCode()方法都必须和equals()方法一致。也就是说,如果a.equals(b)返回true,那么a.hashCode()的返回值必然和b.hashCode()的返回值相同。相反,如果两个对象的hashCode()方法的返回值不同,那么这两个对象是不同的。但是如果两个对象的hashCode()方法的返回值相同,这两个对象也可能不同,还需要使用equals()方法进行判断。
将hashCode()的返回值转化为一个数组索引:因为我们需要的是数组的索引而不是一个32位的整数。在实现中会将默认的hashCode()方法和除留余数法结合起来产生一个0到M-1的整数,方法如下:
private int hash(Key x){
return ( x.hasdCode() & 0x7fffffff ) % M;
}这段代码会屏蔽符号位(将一个32位整数变为一个31位非负整数),然后用除留余数发计算它除以M的余数。在使用这样的代码时我们一般会将数组的大小M取为素数以充分利用原散列值的所有位。
自定义的hashCode方法:在Java中,所有的数据类型都继承hashCode()方法,因此还有一个更简单的做法:将对象中的每个变量的hashCode()返回值转化为32位整数并计算得到散列值。对于原始类型的对象,可以将其转化为对应的数据类型然后再条用hashCode()方法。
软缓存:如果散列值的计算很耗时,我们或可以将每个键的散列值缓存起来,即在每个键中使用一个hash变量来保存它的hashCode()的返回值。第一次调用hashCode()方法时,需要计算对象的散列值,但之后对hashCode()方法的调用会直接返回hash变量的值。Java的String对象的hashCode()方法就是使用了这种方法来减少计算量。
总的来说,要为一个数据类型实现一个优秀的散列方法需要满足三个条件:
- 一致性——等价的键必然产生相等的散列值
- 高效性——计算简便
- 均匀性——均匀地散列所有的键。
保证均匀性的最好办法也许就是保证键的每一位都在散列值的计算中起到了相同的作用;实现散列函数最常见的错误也许就是忽略了键的高位。
(均匀散列假设)我们使用的散列函数能够均匀并独立地将所有的键散布于0到M-1之间。
基于拉链法的散列表
一个散列函数能够将键转化为数组索引。散列算法的第二步是碰撞处理,也就是处理两个或多个键的散列值相同的情况。一种直接的办法是将大小为M的数组中的每个元素指向一条链表,链表中的每个结点都存储了散列值为该元素的索引和键值对。这种办法称为拉链法,因为发生冲突的元素都被存储在链表中。这种方法的基本思想就是选择足够大的M,使得所有链表都尽可能短以保证高效的查找。查找分两步:首先根据散列值找到相应的链表、然后沿着链表顺序查找相应的键。
拉链法的一种实现方法是使用原始的链表数据类型,另一种更简单的方法是采用一般性的策略,为M个元素分别构建符号表来保存散列到这里的键。因为要用M条链表保存N个键,无论键在各个链表中的分布如何,链表的平均长度肯定是N/M。
在一张含有M条链表和N个键的散列表中,任意一条链表中的键的数量均在N/M的常数因子范围内的概率无限趋近于1。
在一张含有M条链和N个键的散列表中,未命中查找和插入操作所需的比较次数为~N/M。
散列的最主要目的在于均匀地将键散步开来,因此在计算散列后键的顺序信息就丢失了。基于拉链法的散列表的实现简单。在键的顺序并不重要的应用中,它可能是最快的(也是使用最广泛的)符号表实现。
基于线性探测法的散列表
实现散列表的另一种方式是用大小为M的数组保存N个键值对,其中M>N。需要依靠数组中的空位解决碰撞冲突,基于这种策略的所有方法被统称为开放地址散列表。开放地址散列表中最简单的方法叫做线性探测法:当碰撞发生时(当一个键的散列表已经被另一个不同的键占用),我们直接检查散列表中的下一个位置(将索引值加1)。这样的线性探测可能会产生三种结果:
- 命中,该位置的键和被查找的键相同
- 未命中,键为空(该位置没有键)
- 继续查找,该位置的键和被查找的键不同
我们用散列函数找到键在数组中的索引,检查其中的键和被查找的键是否相同。如果不同则继续查找(将索引增大,到达数组结尾时折回数组的开头),直到找到该键或者遇到一个空元素,习惯将检查一个数组位置是否含有被查找的键的操作称为探测。
开放地址类的散列表的核心思想是与其将内存用作链表,不如将它们作为散列表的空元素。这些空元素可以作为查找结束的标志。
和拉链法一样,开放地址类的散列表的性能也依赖于α=N/M的比值,但意义有所不同。我们将α成为散列表的使用率。对于基于拉链法的散列表,α是每条链表的长度,因此一般大于1;对于基于线性探测的散列表,α是表中已被占用的空间的比例,它是不可能大于1的。为了保证性能,动态调整数组的大小来保证使用率在1/8到1/2之间。
线性探测的平均成本取决于元素在插入数组后聚集成的一组连续的条目,叫做键簇。显然,短小的键簇才能保证较高的效率。
在一张大小为M并含有N=αM个键的基于线性探测的散列表中,基于均匀散列假设,命中和未命中的查找所需的探测次数分别为:![]() 和
和![]() ,特别是当α约为1/2时,查找命中所需的探测次数约为3/2,未命中所需的约为5/2.当α趋近于1时,这些估计值的精确度会下降,但不需要担心这些情况,因为我们会保证散列表的使用率小于1/2。
,特别是当α约为1/2时,查找命中所需的探测次数约为3/2,未命中所需的约为5/2.当α趋近于1时,这些估计值的精确度会下降,但不需要担心这些情况,因为我们会保证散列表的使用率小于1/2。
调整数组的大小
对于拉链法,如果能够准确地估计用例所需的散列表的大小为N,调整数组的工作并不是必须的,只需要根据查找耗时和(1+N/M)成正比来选取一个适当的M即可。而对于线性探测法,调整数组的大小是必须的,因为当用例插入的键值对数量超过预期时它的查找时间不仅会变得非常长,还会在散列表被填满时进入无限循环。
均摊分析:当我们动态调整数组大小时,需要找出均摊成本的上限。假设一张散列表能够自己调整数组的大小,初始为空。基于均匀散列假设,执行任意顺序的t次查找、插入和删除操作所需的时间和t成正比,所使用的内存量总是在表中的键的总数的常数因子范围内。
内存使用
符号表的内存使用:
方法 N个元素所需的内存(引用类型)
基于拉链法的散列表 ~48N+32N
基于线性探测的散列表 在~32N和~128N之间
各种二叉查找树 ~56N
在实践中,两种方法的性能差别主要是因为拉链法为每个键值对都分配了一小块内存而线性探测则为整张表使用了两个很大的数组。
只用2GB内存在20亿个整数中找出出现次数最多的数
题目:
有一个包含20亿个全是32为整数的大文件,在其中找到出现次数最多的数。
要求:
内存显示为2GB。
解答:
想要在很多整数中找到出现次数最多的数,通常的做法是使用哈希表对出现的每一个数做词频统计,哈希表的key是某一个整数,value是这个数出现的次数。就本题来说,一共有20亿个数,哪怕只是一个数出现了20亿次,用32位的整数也可以表示其出现的次数而不会产生溢出,所以和洗标的key需要占用4B,value也是4B,那么哈希表的一条记录(key,value)需要占用8B,当哈希表记录数为2亿个时,需要至少1.6GB的内存。
但如果20亿个数中不同的数超过2亿种,最极端的情况是20亿个数都不同,那么在哈希表中可能需要产生20亿条记录,这样内存会不够用,所以一次性用哈希表统计20亿个数的办法是由很大风险的。
解决办法是把包含20亿个数的大文件用哈希函数分成16个小文件,根据哈希函数的性质,同一种数不可能被哈希到不同的小文件上,同时每个小文件中不同的数一定不会大于2亿种,假设哈希函数足够好。然后对每一个小文件用哈希表来统计其中每种数出现的次数,这样我们就得到了16个小文件中各自出现次数最多的数,还有各自的次数统计。接下来只要选出这16个小文件各自的第一名中谁出现的次数最多即可。
把一个大的集合通过哈希函数分配到多台机器中,或者分配到多个文件里,这种技巧是处理大数据面试题时最常用的技巧之一。但是到底分配到多少台机器、分配到多少文件,在解题时一定要确定下来。可能是在于面试官沟通的过程中由面试官指定,也可能是根据具体的限制来确定。
设计RandomPool结构
题目:设计一种结构,在该结构中有如下三个功能:
- insert(key):将某个key加入到该结构,做到不重复的加入。
- delete(key):将原本在结构中的某个key移除。
- getRandom():等概率随机返回结构中的任何一个key.
要求:Insert、delete和getRandom方法的时间复杂度都是O(1).
思考:
这种结构假设叫Pool,具体实现如下;
- 包含两个哈希表keyIndexMap和indxKeyMap。
- keyIndexMap用来记录key和index的对应关系。
- indexKeyMap用来记录index到key对应关系。
- 包含一个整数size,用来记录目前Pool的大小,初始时size为0。
- 执行insert(newKey)操作时,将(newKey,size)放入keyIndexMap,将(size,newKey)放入indexKeyMap,然后把size加1,即每次执行insert操作之后size自增。
- 执行delete(deleteKey)操作时(关键步骤),假设Pool最新加入的key记为lastKey,lastKey对应的index信息记为lastIndex。要删除的key为deleteKey,对应的index信息记为deleteIndex。那么先把lastKey的index信息换成deleteKey,即在keyIndexMap中把记录(lastKey,lastIndex)变为(lastKey,deleteIndex),并在indexKeyMap中把记录(deleteIndex,deleteKey)变为(deleteIndex,lastKey)。然后在keyIndexMap中删除记录(deleteKey,deletIndex),并在indexKeyMap中把记录(lastIndex,lastKey)删除。最后size减1,。这么做相当于把lastKey放到了deleteKey的位置上,保证记录的index还是连续的。
- 进行getRandom操作,根据当前的size随机得到一个index,步骤6可保证index在范围[0~size-1]上,都对应着有效的key,然后把index对应的key返回即可。
代码:
import java.util.HashMap;
/**
* 设计RandomPool结构
*/
public class RandomPool {
public class Pool {
private HashMap keyIndexMap;
private HashMap indexKeyMap;
private int size;
public Pool() {
this.keyIndexMap = new HashMap<>();
this.indexKeyMap = new HashMap<>();
this.size = 0;
}
public void insert(K key) {
if (!this.keyIndexMap.containsKey(key)) {
this.keyIndexMap.put(key, this.size);
this.indexKeyMap.put(this.size++, key);
}
}
public void delete(K key) {
if (this.keyIndexMap.containsKey(key)) {
int deleteIndex = this.keyIndexMap.get(key);
int lastIndex = --this.size;
K lastKey = this.indexKeyMap.get(lastIndex);
this.keyIndexMap.put(lastKey, deleteIndex);
this.indexKeyMap.put(deleteIndex, lastKey);
this.keyIndexMap.remove(key);
this.indexKeyMap.remove(lastIndex);
}
}
public K getRandom() {
if (this.size == 0) {
return null;
}
int randomIndex = (int) (Math.random() * this.size);
return this.indexKeyMap.get(randomIndex);
}
}
}
认识位图
int[] int_arr = new int[2];//8bytes 64bits
int_arr[0]://32位
int_arr[1];//32位
//求第17位上的信息
int kth = 17;
int bit = ((int_arr[kth/32] >>(kth%32))&1);//kth/32表示在哪个整数,kth%32表示在整数的哪一位,得到kth位的状态
//设置kth位的状态
int kth = 60;
int set = 1;//0/1
int_arr[kth/32] = ( int_arr[kth/32] | (1<<(kth%32) ) );//将第60位设置为1
可以使用基础数据类型构建N位的数据类型
认识布隆过滤器
题目:
不安全网页的黑名单包含100亿个黑名单网页,每个网页的URL最多占用64B。现在想要实现一种网页过滤系统,可以根据网页的URL判断网页是否在黑名单上,请设计该系统。
要求:
- 该系统允许有万分之一一下的判断失误率
- 使用的额外空间不要超过30GB
思考:
如果把黑名单中所有的URL通过数据库或哈希表保存下来,就可以对每条URL进行查询,但是如果URL有64B,数据量是100亿个,所以至少需要640GB空间,不满足需求2.
如果面试者遇到网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统等题目,又看到系统容忍一定程度的失误率,但是对空间要求比较严格,那么很可能是面试官希望面试者具备布隆过滤器的知识。一个布隆过滤器精确地代表一个集合,并可以精确判断一个元素是否在集合中。注意,只是精确代表和精确判断,到底有多少精确呢?则完全在于你具体的设计,但想做到完全正确是不可能的。布隆过滤器的优势在于使用很少的空间就可以将准确率做到很高的程度。
假设有一个长度为m的bit类型的数组,即数组中的每一个位置只占一个bit,每一个bit只有0和1两种状态。在假设一共有k个哈希函数,这些函数的输出域S都大于或等于m,并且这些哈希函数都足够优秀,彼此之间也完全独立。那么对同一个输入对象(假设是一个字符串记为URL),经过k个哈希函数算出来的结果也是独立的,可能相同,也可能不相同,但彼此独立。对算出来的每一个结果都对m取余(%m),然后在bit array上把相应的位置设置为1(涂黑)。
把bit类型的数组记为bitMap。至此,一个输入对象对bitMap的影响过程就结束了,也就是bitMap中的一些未知会被涂黑。接下来按照该方法处理所有的输入对象,每个对象都可能把bitMap中的一些白位置涂黑,也可能遇到已经涂黑的位置,遇到已经涂黑的位置让其继续为黑即可。处理完所有的输入对象后,可能bitMap中已经有相当多的位置被涂黑。至此,一个布隆过滤器生成完毕,这个布隆过滤器代表之前所有输入对象组成的集合。
如何检查某一个对象是否是之前的某一个输入对象呢?假设一个对象为a,想检查它是否是之前的输入对象,就把a通过k个哈希函数算出k个值,然后把k个值取余(%m),就得到在[0,m-1]范围上的k个值。接下来在bitMap上看这些位置是不是都为黑。如果有一个不为黑,说明a一定不在这个集合里。如果都为黑,说明a在这个集合里,但可能有误判。具体一点,如果a的确是输入对象,那么在生成布隆过滤器时,bitMap中相应的k个位置一定已经涂黑了,所以在检查阶段,a一定不会被漏过,这个不会产生误判。会产生误判的是,a明明不是输入对象,但如果在生成布隆过滤器的阶段因为输入对象太多,而bitMap过小,则会导致bitMap绝大多数的位置都已经变黑。那么在检查a时,可能a对应的k个位置都是黑的,从而错误地认为a是输入对象。通俗地说,布隆过滤器的失误类型是“宁可错杀三千,绝不放过一个”。使用布隆过滤器的另一个好处是不用顾忌单个样本的大小,它丝毫不会影响布隆过滤器的大小。
如果bitMap的大小m相对于输入对象的个数n过小,失误率会变大。根据n的大小和想要达到的失误率p,如何确定布隆过滤器的大小m和哈希函数的个数k,最后是布隆过滤器的失误率分析。
黑名单中样本的个数为100亿个,记为n;失误率不能超过0.01%,记为p;每个样本的大小为64B,这个信息不会影响布隆过滤器的大小,只和选择哈希函数有关,一般的哈希函数都可以接收64B的输入对象。
所以n=100亿,p=0.01%,布隆过滤器的大小m由以下公式确定:
![]()
根据公式计算出m=19.19n,向上取整为20n,即需要2000亿个bit,也就是25GB。
哈希函数的个数由以下公式确定:
![]()
计算出哈希函数的个数为k=14个。
然后用25GB的bitMap再单独实现14个哈希函数,根据如上描述生成布隆过滤器即可。因为我们在确定布隆过滤器大小的过程中选择了向上取整,所以还要用如下公式确定布隆过滤器真实的失误率为:
![]()
根据这个公式算出真实的失误率为0.006%,这是比0.01%更低的失误率,哈希函数本身不占用什么空间,所以使用空间就是bitMap的大小(即25GB),服务器的内存都可以达到这个级别,所有要求达标。
代码:
/**
* 布隆过滤器
*/
public class SimpleBloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[]{7, 11, 13, 31, 37, 61};
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public SimpleBloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
public static void main(String[] args) {
String value = "[email protected]";
SimpleBloomFilter filter = new SimpleBloomFilter();
System.out.println(filter.contains(value));
filter.add(value);
System.out.println(filter.contains(value));
}
}
认识一致性哈希
题目:
工程师常使用服务器集群来设计和实现数据缓存,以下是常见的策略:
- 无论是添加、查询还是删除数据,都先将数据的id通过哈希函数转换成一个哈希值,记为key。
- 如果目前机器有N台,则计算key%N值,这个值就是该数据所属的的机器编号,无论是添加、删除还是查询操作,都只在这台机器上进行。
请分析这种缓存策略可能带来的问题,并提出改进的方案。
思考:
题目中描述的缓存策略的潜在问题是如果增加或删除机器时(N变化)代价会很高,所有的数据都不得不根据id重新计算一遍哈希值,并将哈希值对新的机器数进行取模操作,然后进行大规模的数据迁移。
为了解决这些问题,引入一致性哈希算法。假设数据的id通过哈希函数转换成的哈希值范围是2^32,也就是O~(2^32)-1的数字空间中。我们将这些数字头尾相连,想象成一个闭合的环形,那么一个数字id在计算出哈希值之后认为对应到环中的一个位置上。
接下来,想象有三台机器也处于这样一个环中,这三台机器在环中的位置根据机器id计算出的哈希值来决定。那么一条数据如何确定归属哪台机器呢?首先把该数据的id用哈希值算出哈希值,并映射到环中的相应位置,然后顺时针找寻离这个位置最近的机器,那台机器就是该数据的归属。
普通hash求余算法最为不妥的地方就是在有机器的添加或者删除之后会照成大量的对象存储位置失效,这样就大大的不满足单调性了。下面来分析一下一致性哈希算法是如何处理的。
1. 节点(机器)的删除
以上面的分布为例,如果NODE2出现故障被删除了,那么按照顺时针迁移的方法,object3将会被迁移到NODE3中,这样仅仅是object3的映射位置发生了变化,其它的对象没有任何的改动。如下图:

2. 节点(机器)的添加
如果往集群中添加一个新的节点NODE4,通过对应的哈希算法得到KEY4,并映射到环中,如下图:

通过按顺时针迁移的规则,那么object2被迁移到了NODE4中,其它对象还保持这原有的存储位置。通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
机器负载不均时的处理。如果机器较少,很可能造成机器在整个换上的分布不均匀,从而导致机器之间的负载不均衡。为了解决数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一台机器通过不同的哈希函数计算出多个哈希值,对多个位置都放置一个服务节点,称为虚拟节点。具体做法可以在机器ip或主机名的后面增加编号或端口号来实现。通过调整虚拟节点所占的比例来调整机器的负载量。虚拟节点广泛应用于分布式系统中。
虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品( replica ),一实际个节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。
补充:
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简 单哈希算法带来的问题,使得分布式哈希(DHT)可以在P2P环境中真正得到应用。
一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
岛问题
题目:
一个矩阵中只有0和1两种值,每个值都可以和自己的上下左右四个位置相连,如果有一片1连在一起,这一部分叫做一个岛,求一个矩阵中有多少个岛?
例如:
0 0 1 0 1 0
1 1 1 0 1 0
1 0 0 1 0 0
0 0 0 0 0 0
这个矩阵中有三个岛
思考:
从上到下遍历整个矩阵,遇到0就跳过,遇到1则开始感染,将其上下左右等于1的数字变为2,遍历结束,有几次感染过程,即有几个岛。时间复杂度为O(N^2)。
代码:
/**
* 岛屿的个数
*/
public class Islands {
public static int countIslands(int[][] m) {
if (m == null || m[0] == null) {
return 0;
}
int N = m.length;
int M = m[0].length;
int res = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
//如果第i行第j列等于1,则开始感染
if (m[i][j] == 1) {
res++;
infect(m, i, j, N, M);
}
}
}
return res;
}
/**
* 感染过程,第一次遇见值为1的时候,就对周边的1进行感染。
* 根据几次感染的次数对岛屿的个数进行估计
* @param m
* @param i
* @param j
* @param N 共计N行,标记越界
* @param M 共计M列,标记越界
*/
private static void infect(int[][] m, int i, int j, int N, int M) {
if (i < 0 || i >= N || j < 0 || j >= M || m[i][j] != 1) {
return;
}
m[i][j] = 2;
infect(m, i + 1, j, N, M);
infect(m, i - 1, j, N, M);
infect(m, i, j + 1, N, M);
infect(m, i, j - 1, N, M);
}
}
认识并查集结构
关于动态连通性
我们看一张图来了解一下什么是动态连通性:
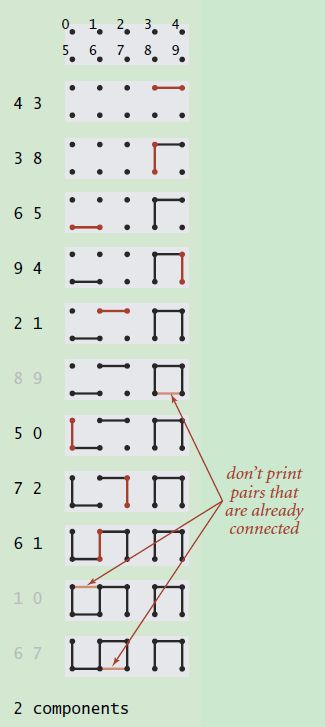
 转存失败重新上传取消
转存失败重新上传取消
假设我们输入了一组整数对,即上图中的(4, 3) (3, 8)等等,每对整数代表这两个points/sites是连通的。那么随着数据的不断输入,整个图的连通性也会发生变化,从上图中可以很清晰的发现这一点。同时,对于已经处于连通状态的points/sites,直接忽略,比如上图中的(8, 9)。
动态连通性的应用场景:
- 网络连接判断:
如果每个pair中的两个整数分别代表一个网络节点,那么该pair就是用来表示这两个节点是需要连通的。那么为所有的pairs建立了动态连通图后,就能够尽可能少的减少布线的需要,因为已经连通的两个节点会被直接忽略掉。
- 变量名等同性(类似于指针的概念):
在程序中,可以声明多个引用来指向同一对象,这个时候就可以通过为程序中声明的引用和实际对象建立动态连通图来判断哪些引用实际上是指向同一对象。
对问题建模:
在对问题进行建模的时候,我们应该尽量想清楚需要解决的问题是什么。因为模型中选择的数据结构和算法显然会根据问题的不同而不同,就动态连通性这个场景而言,我们需要解决的问题可能是:
- 给出两个节点,判断它们是否连通,如果连通,不需要给出具体的路径
- 给出两个节点,判断它们是否连通,如果连通,需要给出具体的路径
就上面两种问题而言,虽然只有是否能够给出具体路径的区别,但是这个区别导致了选择算法的不同,本文主要介绍的是第一种情况,即不需要给出具体路径的Union-Find算法,而第二种情况可以使用基于DFS的算法。
建模思路:
最简单而直观的假设是,对于连通的所有节点,我们可以认为它们属于一个组,因此不连通的节点必然就属于不同的组。随着Pair的输入,我们需要首先判断输入的两个节点是否连通。如何判断呢?按照上面的假设,我们可以通过判断它们属于的组,然后看看这两个组是否相同,如果相同,那么这两个节点连通,反之不连通。为简单起见,我们将所有的节点以整数表示,即对N个节点使用0到N-1的整数表示。而在处理输入的Pair之前,每个节点必然都是孤立的,即他们分属于不同的组,可以使用数组来表示这一层关系,数组的index是节点的整数表示,而相应的值就是该节点的组号了。该数组可以初始化为:
-
for(int i = 0; i < size; i++) -
id[i] = i;
即对于节点i,它的组号也是i。
初始化完毕之后,对该动态连通图有几种可能的操作:
- 查询节点属于的组
数组对应位置的值即为组号
- 判断两个节点是否属于同一个组
分别得到两个节点的组号,然后判断组号是否相等
- 连接两个节点,使之属于同一个组
分别得到两个节点的组号,组号相同时操作结束,不同时,将其中的一个节点的组号换成另一个节点的组号
- 获取组的数目
初始化为节点的数目,然后每次成功连接两个节点之后,递减1
API
我们可以设计相应的API:
 转存失败重新上传取消
转存失败重新上传取消
注意其中使用整数来表示节点,如果需要使用其他的数据类型表示节点,比如使用字符串,那么可以用哈希表来进行映射,即将String映射成这里需要的Integer类型。
分析以上的API,方法connected和union都依赖于find,connected对两个参数调用两次find方法,而union在真正执行union之前也需要判断是否连通,这又是两次调用find方法。因此我们需要把find方法的实现设计的尽可能的高效。所以就有了下面的Quick-Find实现。
Quick-Find 算法:
public class UF
{
private int[] id; // access to component id (site indexed)
private int count; // number of components
public UF(int N)
{
// Initialize component id array.
count = N;
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
}
public int count()
{ return count; }
public boolean connected(int p, int q)
{ return find(p) == find(q); }
public int find(int p)
{ return id[p]; }
public void union(int p, int q)
{
// 获得p和q的组号
int pID = find(p);
int qID = find(q);
// 如果两个组号相等,直接返回
if (pID == qID) return;
// 遍历一次,改变组号使他们属于一个组
for (int i = 0; i < id.length; i++)
if (id[i] == pID) id[i] = qID;
count--;
}
}
举个例子,比如输入的Pair是(5, 9),那么首先通过find方法发现它们的组号并不相同,然后在union的时候通过一次遍历,将组号1都改成8。当然,由8改成1也是可以的,保证操作时都使用一种规则就行。
 转存失败重新上传取消
转存失败重新上传取消
上述代码的find方法十分高效,因为仅仅需要一次数组读取操作就能够找到该节点的组号,但是问题随之而来,对于需要添加新路径的情况,就涉及到对于组号的修改,因为并不能确定哪些节点的组号需要被修改,因此就必须对整个数组进行遍历,找到需要修改的节点,逐一修改,这一下每次添加新路径带来的复杂度就是线性关系了,如果要添加的新路径的数量是M,节点数量是N,那么最后的时间复杂度就是MN,显然是一个平方阶的复杂度,对于大规模的数据而言,平方阶的算法是存在问题的,这种情况下,每次添加新路径就是“牵一发而动全身”,想要解决这个问题,关键就是要提高union方法的效率,让它不再需要遍历整个数组。
Quick-Union 算法:
考虑一下,为什么以上的解法会造成“牵一发而动全身”?因为每个节点所属的组号都是单独记录,各自为政的,没有将它们以更好的方式组织起来,当涉及到修改的时候,除了逐一通知、修改,别无他法。所以现在的问题就变成了,如何将节点以更好的方式组织起来,组织的方式有很多种,但是最直观的还是将组号相同的节点组织在一起,想想所学的数据结构,什么样子的数据结构能够将一些节点给组织起来?常见的就是链表,图,树,什么的了。但是哪种结构对于查找和修改的效率最高?毫无疑问是树,因此考虑如何将节点和组的关系以树的形式表现出来。
如果不改变底层数据结构,即不改变使用数组的表示方法的话。可以采用parent-link的方式将节点组织起来,举例而言,id[p]的值就是p节点的父节点的序号,如果p是树根的话,id[p]的值就是p,因此最后经过若干次查找,一个节点总是能够找到它的根节点,即满足id[root] = root的节点也就是组的根节点了,然后就可以使用根节点的序号来表示组号。所以在处理一个pair的时候,将首先找到pair中每一个节点的组号(即它们所在树的根节点的序号),如果属于不同的组的话,就将其中一个根节点的父节点设置为另外一个根节点,相当于将一颗独立的树编程另一颗独立的树的子树。直观的过程如下图所示。但是这个时候又引入了问题。
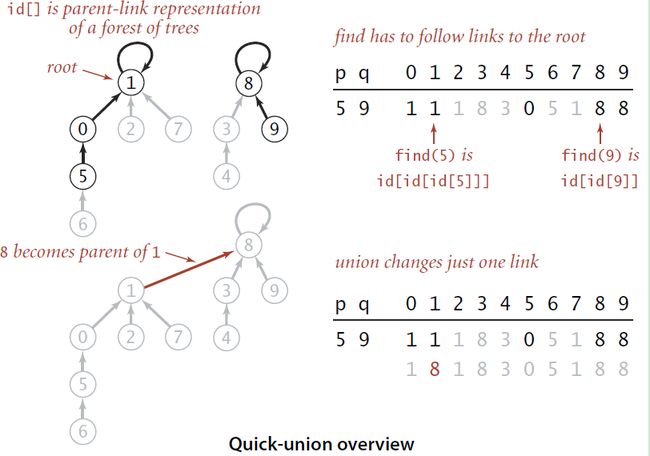 转存失败重新上传取消
转存失败重新上传取消
在实现上,和之前的Quick-Find只有find和union两个方法有所不同:
private int find(int p)
{
// 寻找p节点所在组的根节点,根节点具有性质id[root] = root
while (p != id[p]) p = id[p];
return p;
}
public void union(int p, int q)
{
// Give p and q the same root.
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
id[pRoot] = qRoot; // 将一颗树(即一个组)变成另外一课树(即一个组)的子树
count--;
}
树这种数据结构容易出现极端情况,因为在建树的过程中,树的最终形态严重依赖于输入数据本身的性质,比如数据是否排序,是否随机分布等等。比如在输入数据是有序的情况下,构造的BST会退化成一个链表。在我们这个问题中,也是会出现的极端情况的,如下图所示。
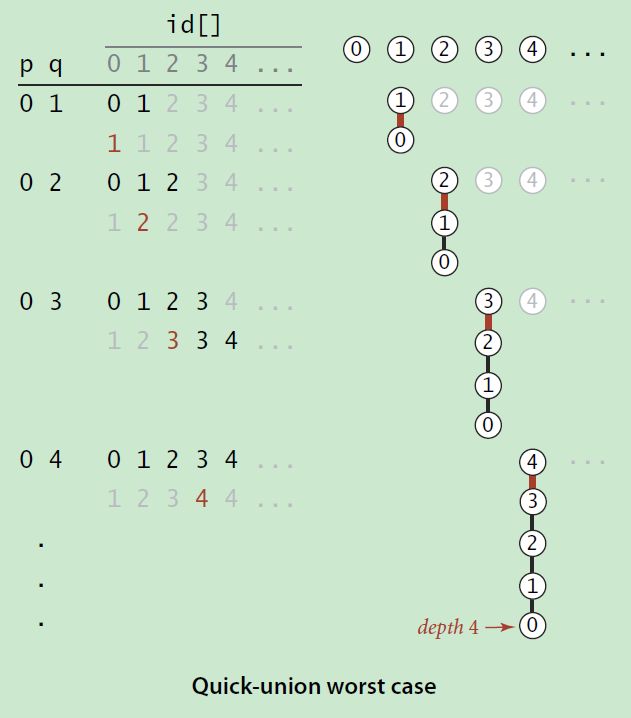 转存失败重新上传取消
转存失败重新上传取消
为了克服这个问题,BST可以演变成为红黑树或者AVL树等等。
然而,在我们考虑的这个应用场景中,每对节点之间是不具备可比性的。因此需要想其它的办法。在没有什么思路的时候,多看看相应的代码可能会有一些启发,考虑一下Quick-Union算法中的union方法实现:
public void union(int p, int q)
{
// Give p and q the same root.
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
id[pRoot] = qRoot; // 将一颗树(即一个组)变成另外一课树(即一个组)的子树
count--;
}
上面 id[pRoot] = qRoot 这行代码看上去似乎不太对劲。因为这也属于一种“硬编码”,这样实现是基于一个约定,即p所在的树总是会被作为q所在树的子树,从而实现两颗独立的树的融合。那么这样的约定是不是总是合理的呢?显然不是,比如p所在的树的规模比q所在的树的规模大的多时,p和q结合之后形成的树就是十分不和谐的一头轻一头重的”畸形树“了。
所以我们应该考虑树的大小,然后再来决定到底是调用:
id[pRoot] = qRoot 或者是 id[qRoot] = pRoot
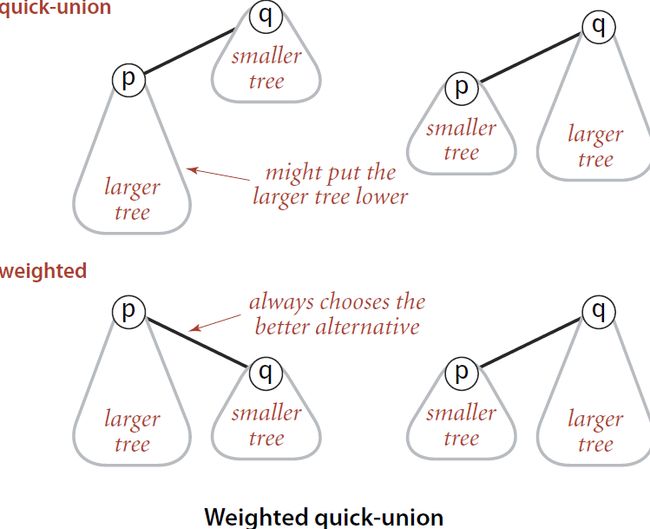 转存失败重新上传取消
转存失败重新上传取消
即总是size小的树作为子树和size大的树进行合并。这样就能够尽量的保持整棵树的平衡。
所以现在的问题就变成了:树的大小该如何确定?
我们回到最初的情形,即每个节点最一开始都是属于一个独立的组,通过下面的代码进行初始化:
-
for (int i = 0; i < N; i++) -
id[i] = i; // 每个节点的组号就是该节点的序号
以此类推,在初始情况下,每个组的大小都是1,因为只含有一个节点,所以我们可以使用额外的一个数组来维护每个组的大小,对该数组的初始化也很直观:
-
for (int i = 0; i < N; i++) -
sz[i] = 1; // 初始情况下,每个组的大小都是1
而在进行合并的时候,会首先判断待合并的两棵树的大小,然后按照上面图中的思想进行合并,实现代码:
public void union(int p, int q)
{
int i = find(p);
int j = find(q);
if (i == j) return;
// 将小树作为大树的子树
if (sz[i] < sz[j]) { id[i] = j; sz[j] += sz[i]; }
else { id[j] = i; sz[i] += sz[j]; }
count--;
}
Quick-Union 和 Weighted Quick-Union 的比较:
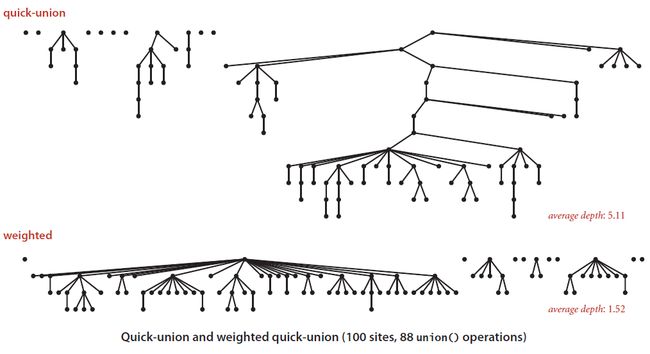 转存失败重新上传取消
转存失败重新上传取消
可以发现,通过sz数组决定如何对两棵树进行合并之后,最后得到的树的高度大幅度减小了。这是十分有意义的,因为在Quick-Union算法中的任何操作,都不可避免的需要调用find方法,而该方法的执行效率依赖于树的高度。树的高度减小了,find方法的效率就增加了,从而也就增加了整个Quick-Union算法的效率。
上图其实还可以给我们一些启示,即对于Quick-Union算法而言,节点组织的理想情况应该是一颗十分扁平的树,所有的孩子节点应该都在height为1的地方,即所有的孩子都直接连接到根节点。这样的组织结构能够保证find操作的最高效率。
那么如何构造这种理想结构呢?
在find方法的执行过程中,不是需要进行一个while循环找到根节点嘛?如果保存所有路过的中间节点到一个数组中,然后在while循环结束之后,将这些中间节点的父节点指向根节点,不就行了么?但是这个方法也有问题,因为find操作的频繁性,会造成频繁生成中间节点数组,相应的分配销毁的时间自然就上升了。那么有没有更好的方法呢?还是有的,即将节点的父节点指向该节点的爷爷节点,这一点很巧妙,十分方便且有效,相当于在寻找根节点的同时,对路径进行了压缩,使整个树结构扁平化。相应的实现如下,实际上只需要添加一行代码:
private int find(int p)
{
while (p != id[p])
{
// 将p节点的父节点设置为它的爷爷节点
id[p] = id[id[p]];
p = id[p];
}
return p;
}
至此,动态连通性相关的Union-Find算法基本上就介绍完了,从容易想到的Quick-Find到相对复杂但是更加高效的Quick-Union,然后到对Quick-Union的几项改进,让我们的算法的效率不断的提高。
这几种算法的时间复杂度如下所示:
| Algorithm |
Constructor |
Union |
Find |
| Quick-Find |
N |
N |
1 |
| Quick-Union |
N |
Tree height |
Tree height |
| Weighted Quick-Union |
N |
lgN |
lgN |
| Weighted Quick-Union With Path Compression |
N |
Very near to 1 (amortized) |
Very near to 1 (amortized) |
对大规模数据进行处理,使用平方阶的算法是不合适的,比如简单直观的Quick-Find算法,通过发现问题的更多特点,找到合适的数据结构,然后有针对性的进行改进,得到了Quick-Union算法及其多种改进算法,最终使得算法的复杂度降低到了近乎线性复杂度。
如果需要的功能不仅仅是检测两个节点是否连通,还需要在连通时得到具体的路径,那么就需要用到别的算法了,比如DFS或者BFS。
总结:
并查集的几个关键点:
- 以树作为节点的组织结构,结构的形态很是否采取优化策略有很大关系,未进行优化的树结构可能会是“畸形”树(严重不平衡,头重脚轻,退化成链表等),按尺寸(正规说法叫做秩,后文全部用秩来表示)进行平衡,同时辅以路径压缩后,树结构会高度扁平化。
- 虽然组织结构比较复杂,数据表示方式却十分简洁,主要采用数组作为其底层数据结构。一般会使用两个数组(parent-link array and size array),分别用来保存当前节点的父亲节点以及当前节点所代表子树的秩。第一个数组(parent-link array)无论是否优化,都需要使用,而第二个数组(size array),在不需要按秩合并优化或者不需要保存子树的秩时,可以不使用。根据应用的不同,可能需要第三个数组来保存其它相关信息,比如HDU-3635中提到的“转移次数”。
- 主要操作包括两部分,union以及find。union负责对两颗树进行合并,合并的过程中可以根据具体应用的性质选择是否按秩优化。需要注意的是,执行合并操作之前,需要检查待合并的两个节点是否已经存在于同一颗树中,如果两个节点已经在一棵树中了,就没有合并的必要了。这是通过比较两个节点所在树的根节点来实现的,而寻找根节点的功能,自然是由find来完成了。find通过parent-link数组中的信息来找到指定节点的根节点,同样地,也可以根据应用的具体特征,选择是否采用路径压缩这一优化手段。然而在需要保存每个节点代表子树的秩的时候,则无法采用路径压缩,因为这样会破坏掉非根节点的尺寸信息(注意这里的“每个”,一般而言,在按秩合并的时候,需要的信息仅仅是根节点的秩,这时,路径压缩并无影响,路径压缩影响的只是非根节点的秩信息)。
实现并查集所需的几个步骤:
1. 初始化元素 init()
2. 实现元素与元素间的联合操作 union()
3. 实现查找元素所在树的根节点 find()
4. 解决一个问题,判定两个元素是否在同一棵树上(两个元素是否相互连接)isConnected()
代码:
import java.util.HashMap;
import java.util.List;
import java.util.Stack;
/*
并查集
*/
public class UnionFind {
public static class Element {
public V value;
public Element(V value) {
this.value = value;
}
}
// V 用户的元素类型
public static class UnionFindSet {
public HashMap> elementMap;
public HashMap, Element> fatherMap;
public HashMap, Integer> rankMap;
public UnionFindSet(List list) {
elementMap = new HashMap>();
fatherMap = new HashMap, Element>();
rankMap = new HashMap, Integer>();
for (V value : list) {
//初始化过程
Element element = new Element(value);
elementMap.put(value, element);
fatherMap.put(element, element);
rankMap.put(element, 1);
}
}
private Element findHead(Element element) {
Stack> path = new Stack<>();
while (element != fatherMap.get(element)) {
path.push(element);
element = fatherMap.get(element);
}
while (!path.isEmpty()) {
fatherMap.put(path.pop(), element);
}
return element;
}
public boolean isSameSet(V a, V b) {
if (elementMap.containsKey(a) && elementMap.containsKey(b)) {
return findHead(elementMap.get(a)) == findHead(elementMap.get(b));
}
return false;
}
public void union(V a, V b) {
if (elementMap.containsKey(a) && elementMap.containsKey(b)) {
Element aF = findHead(elementMap.get(a));
Element bF = findHead(elementMap.get(b));
if (aF != bF) {
int aSetSize = rankMap.get(aF);
int bSetSize = rankMap.get(bF);
if (aSetSize >= bSetSize) {
fatherMap.put(bF, aF);
rankMap.put(aF, aSetSize + bSetSize);
rankMap.remove(bF);
} else {
fatherMap.put(aF, bF);
rankMap.put(bF, aSetSize + bSetSize);
rankMap.remove(aF);
}
}
}
}
}
}
代码2:
public class UnionFind_2 {
private int[] parent; //标注当前元素的父节点的位置
private int[] rank;//标注当前元素的层级数
private int size;//并查集中的元素个数
public UnionFind_2(int size) {
this.size = size;
parent = new int[size];
rank = new int[size];
init();
}
public void init() {
for (int i = 0; i < size; i++) {
//初始化时所有的节点的父节点指向本身,所有的元素层级均为1
parent[i] = i;
rank[i] = 1;
}
}
/**
* 寻找当前节点的根节点元素
*
* @param target
* @return
*/
public int find(int target) {
if (target >= size)
throw new ArrayIndexOutOfBoundsException();
if (target == parent[target])
return target;
return find(parent[target]);
}
/**
* 连接两个元素
*
* @param p
* @param q
*/
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
if (rank[pRoot] > rank[qRoot]) {//p所在的树的盖度比q所在树的高度高,这时应该让q的根节点元素连接到p的根节点元素
parent[qRoot] = pRoot;//此时树的高度不变
} else if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;//此时树的高度不变
} else {
parent[pRoot] = qRoot;//此时树的高度+1
rank[qRoot] += 1;
}
}
/**
* 判断两个节点是否连接
*
* @param p
* @param q
* @return
*/
public boolean isConnected(int p, int q) {
//如果两个节点的根节点一致则说明这两个结点是相连接的
return find(p) == find(q);
}
public static void main(String[] args) {
int size = 10;
// Step 1: init()
UnionFind_2 uf = new UnionFind_2(size);
// Step 2: union()
uf.union(1, 2);
uf.union(3, 4);
uf.union(0, 9);
uf.union(4, 7);
uf.union(6, 5);
uf.union(5, 8);
uf.union(3, 9);
uf.union(1, 8);
// Step 3: find()
System.out.println(uf.find(0)); // 9
System.out.println(uf.find(1)); // 5
System.out.println(uf.find(2)); // 5
System.out.println(uf.find(3)); // 9
System.out.println(uf.find(4)); // 9
System.out.println(uf.find(5)); // 5
System.out.println(uf.find(6)); // 5
System.out.println(uf.find(7)); // 9
System.out.println(uf.find(8)); // 5
System.out.println(uf.find(9)); // 9
// Step 4: isConnected
System.out.println(uf.isConnected(0, 1)); // false
System.out.println(uf.isConnected(1, 2)); // true
System.out.println(uf.isConnected(3, 4)); // true
System.out.println(uf.isConnected(5, 6)); // true
System.out.println(uf.isConnected(7, 8)); // false
System.out.println(uf.isConnected(8, 9)); // false
System.out.println(uf.isConnected(2, 4)); // false
System.out.println(uf.isConnected(3, 5)); // false
System.out.println(uf.isConnected(5, 6)); // true
System.out.println(uf.isConnected(7, 9)); // true
}
}
参考资料:
https://blog.csdn.net/dm_vincent/article/details/7655764
https://blog.csdn.net/dm_vincent/article/details/7769159
https://blog.csdn.net/xiaoping0915/article/details/79727603
https://www.jianshu.com/p/b67668670bef
https://www.jianshu.com/p/361a6bb76024