BERT重计算:用22.5%的训练时间节省5倍的显存开销(附代码)

一只小狐狸带你解锁 炼丹术&NLP 秘籍
作者:夕小瑶、rumor酱
前言
虽然TPU的显存令人羡慕,但是由于众所周知的原因,绝大部分人还是很难日常化使用的。英伟达又一直在挤牙膏,至今单卡的最大显存也仅仅到32G(参考V100、DGX-2)。然而,训练一个24层的BERT Large模型的时候,如果sequence length开满512,那么batch size仅仅开到8(有时候能到10)就把这寥寥32G的显存打满了。如果想训练一个48层乃至100层的BERT Large,那完全是土豪们的游戏了,需要疯狂的模型并行+分布式多机训练。
但!是!万能的小夕前不久在Daxiang Dong大佬的安利下,发现了@陈天奇 大佬2016年的一篇宝藏paper!

简单的划一下重点:
这篇paper用时间换空间的思想,在前向时只保存部分中间节点,在反向时重新计算没保存的部分。论文通过这种机制,在每个batch只多计算一次前向的情况下,把n层网络的占用显存优化到了 。在极端情况下,仍可用 的计算时间换取到 的显存占用。在论文的实验中,他们成功将将1000层的残差网络从48G优化到了7G。且,这种方法同样可以直接应用于RNN结构中。
看完摘要,瞬间感觉在小破卡上训练BERT Large有救了!!!
此外,来快速过一遍paper中最重要的三点结论:
梯度计算等价,理论上没有精度损失

可以节省4倍+的显存开销

训练速度仅仅会被拖慢30%
 image-20200420140806122
image-20200420140806122
不过论文发表在2016年,当时还没有BERT,不过Baidu Paddle团队补了一个BERT的实验结果,发现在BERT上面只用22.5%的训练速度损失就能换来5倍+的显存开销节省!相关实验在本文末尾,不着急,接下来我们先一起分析一下在训练阶段时显存为什么容易不足。
感谢Baidu Paddle团队提供本节图文素材和测试数据
训练阶段显存为何不足
深度学习中,网络的一次训练包含前向计算、后向计算和优化三个步骤。
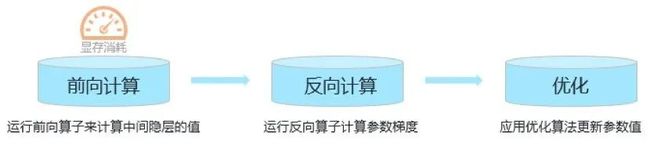
在这个过程中,前向计算会输出大量的隐层变量Tensor,当模型层数加深时,Tensor数量可达成千上万个。如Bert Large模型,单个Tensor可达到1GB,这些Tensor在显存中累积,显存很快就爆掉了╮( ̄▽ ̄"")╭
下图是Bert Large模型在一次训练过程中的显存使用情况,可以明显看到在前向计算过程中,显存累积趋势是一个陡峭的上升直线。而在反向计算过程中,这些隐层Tensor又会很快地被消耗掉,又是一个陡峭的下降曲线,显存直接降到低位。
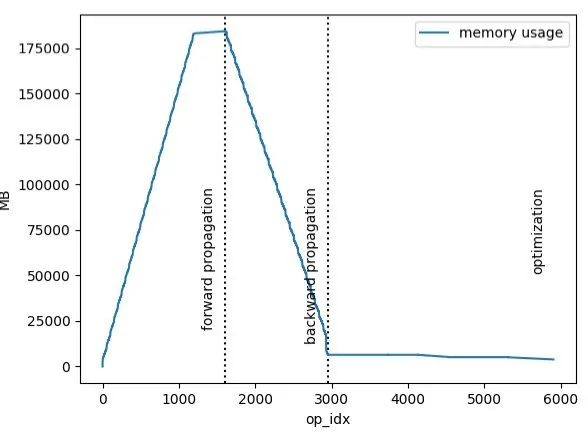
那么问题来了,为什么不直接删除这些前向计算的Tensor呢?
答案很简单,因为这些隐层的Tensor在反向的时会被用到(手动狗头
来个简单的证明。
假设前向计算中有一个矩阵乘法计算:
Y = W × X
对W求梯度:
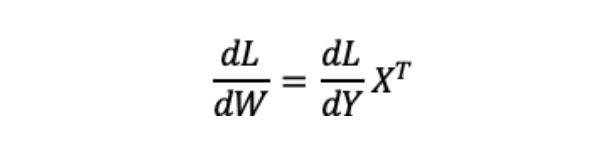
很容易发现,对W求梯度的公式里有X,而X就是那个巨能吃显存的隐层Tensor╮( ̄▽ ̄"")╭
那我们是否可以暂时扔掉这些隐层Tensor,在反向计算时再把它们重新生成出来呢?当然可以,这正是上面这篇paper的思想。
重计算
顾名思义,"重计算"就是让每个训练迭代过程做两次前向计算,看起来有点奇怪,实际上却非常有效!对于刚刚那个吃显存的Bert Large,支持重计算机制后,显存占用直接从175GB降低到20GB,陡峭的显存上升直线变成了缓慢增长的Z形曲线,如下图所示。
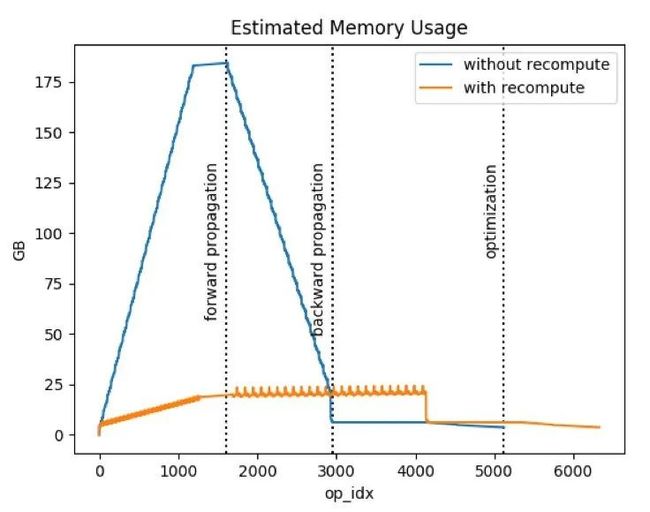
核心思想是将前向计算分割成多个段,将每个段的起始Tensor作为这个段的检查点(checkpoints)。前向计算时,除了检查点以外的其他隐层Tensor占有的显存可以及时释放。反向计算用到这些隐层Tensor时,从前一个检查点开始,重新进行这个段的前向计算,就可以重新获得隐层Tensor。
重计算机制有点像玩单机游戏。每过一个关卡就会保存一个检查点,而隐层Tensor就相当于游戏中任何一个时刻的图像。普通的训练方式是打通一遍游戏,并且将游戏中所有时刻的图像保存下来;而重计算机制的思路是先把游戏通关,保存检查点,后面当收到某一时刻图像的请求时,再重打一遍这一关卡就可以了。

如下图,举一个简单的例子,添加重计算机制前,前向计算中需要存储的隐层是4个红点;添加重计算机制后,需要存储的隐层变为2个蓝点, 从而节省了这部分内存。
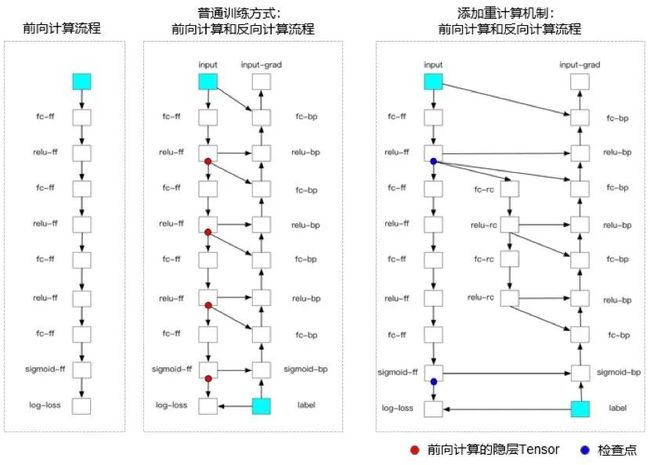
虽然时间也是宝贵的,但重计算方法的性价比很高。在论文的实验中,作者用30%的计算时间换取了4倍的内存空间。并且重计算只是重复了一次前向的过程,理论上精度没有任何损失。
那么这么宝藏的算法有没有开源实现呢?
开源实现
调研了一波,似乎TF没有原生支持,但是生态里有第三方实现;pytorch和paddlepaddle中都有原生API支持
Pytorch:
torch.utils.checkpointPaddlePaddle:
optimizer.RecomputeOptimizer
不过pytorch的文档比较略,也没有提供更细致的示例和相关数据,有兴趣的小伙伴自行试一下。paddle框架中提供了详细到哭的文档,甚至还有一个现成的BERT+重计算的例子,以及非常详细的实验测试结果。这里直接贴过来(真香系列
Paddle中实现显存重计算大体分为三步:
定义一个经典的优化器,如SGD优化器;
在外面包一层重计算优化器;
设置检查点。
以MLP为例,只需要增加两行代码就可以进入重计算模式
import paddle.fluid as fluid
# 定义MLP
def mlp(input_x, input_y, hid_dim=128, label_dim=2):
print(input_x)
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim)
prediction = fluid.layers.fc(input=[fc_1], size=label_dim, act='softmax')
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
sum_cost = fluid.layers.reduce_mean(cost)
return sum_cost, fc_1, prediction
input_x = fluid.layers.data(name="x", shape=[32], dtype='float32')
input_y = fluid.layers.data(name="y", shape=[1], dtype='int64')
cost, fc_1, pred = mlp(input_x, input_y)
# 定义RecomputeOptimizer
sgd = fluid.optimizer.SGD(learning_rate=0.01)
recompute_optimizer = fluid.optimizer.RecomputeOptimizer(sgd)
# 设置checkpoints
recompute_optimizer._set_checkpoints([fc_1, pred])
# 运行优化算法
recompute_optimizer.minimize(cost)
该示例github链接:https://github.com/PaddlePaddle/examples/blob/master/community_examples/recompute/demo.py
此外,官方还给出了一个BERT中做重计算的示例
github链接:https://github.com/PaddlePaddle/Fleet/tree/develop/examples/recompute/bert
BERT实验结论(划重点
根据上面paddle官方提供的BERT示例和实验结果,得出以下几个结论
结论一
在32GB显存的Tesla V100显卡上应用重计算机制,可以训练更大、更深的深度学习模型。当num_tokens为4096(batch size=32,seqlen=128)时,可以训练100层的Bert网络。
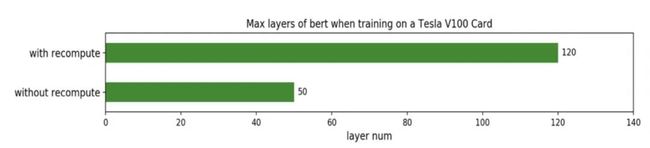
从Github的实验结果也可以看出,显存上的收益比速度的损失要大很多:

在batch_size上提升了5倍,速度只降低了约1/5,且精度没有损失。
结论二
模型训练的batch size最大可提升为原来的5倍+,且只有少量的速度损失。
重计算机制在Bert Large这一模型上收益最大,最大batch size从93提升到562!而在VGG-16这种比较浅的模型上,重计算机制的收益则比较小。这充分符合重计算机制的设计理念:为了训练更大、更深的模型。
结论三
在古董显卡Tesla K40显卡(12G显存)上,训练BERT Large时batch size可以开到130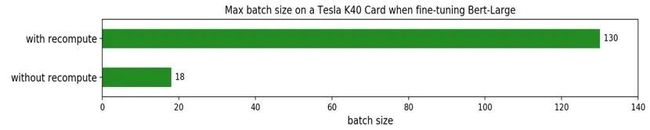
最后,希望本文可以帮助大家在小破卡上尽情训练BERT Large~
个人微信:加时请注明 (昵称+公司/学校+方向)

也欢迎小伙伴加入NLP交流群,刚刚创的,想和大家讨论NLP!

