mysql技术
mysql5.7解压版启动服务和开启服务
1.mysql5.7首先要创建data文件夹使用命令为
在bin目录下执行 mysqld –intialize-insecure –user=mysql
2.添加服务
mysqld -nt-install mysql
3.删除服务
mysqld remove
4.开启服务
net start mysql
5.停止服务
net stop mysql
6.修改密码(3种方法)
(1)mysqladmin -uroot password “new password”
(2) 如果 MySQL 正在运行,首先杀之: killall -TERM mysqld。
运行mysqld_safe –skip-grant-tables &
如果此时不想被远程连接:mysqld_safe –skip-grant-tables –skip-networking &
使用mysql连接server(mysql -u root mysql)
更改密码: update mysql.user set authentication_string=password(‘new password’) where user=’root’ and Host = ‘localhost’;
*特别提醒注意的一点是,新版的mysql数据库下的user表中已经没有Password字段了而是将加密后的用户密码存储于authentication_string字段
mysql> flush privileges;(更新权限)
mysql> quit;
修改完毕。重启
killall -TERM mysqld。
mysqld_safe &
然后mysql就可以连接了
但是此时操作似乎功能不完全,还要alter user…
alter user ‘root’@’localhost’ identified by ‘123’;
也可以:set password for ‘root’@’localhost’=password(‘123’);
日期类型
Year类型:一个字节,表示1901-2155【0000,表示错误时选择】
如果输入2位,“00-69”表示2000-2069(计算机元年1970年)
如果输入“70-99”表示1970-1999年,如果嫌麻烦,就写4位
Date类型:典型格式1983-09-27
日期类型:”1000-01-01–9999-12-31”
时间类型time:典型格式:HH:mm:ss
时间类型:’-838:59:59’–’+838:59:59’
Datetime类型:典型格式:1983-09-22 13:43:33
范围:1000-01-01 00:00:00–9999-12-31 23:59:59
注意:在开发中,很少用到时间日期类型来表示一个需要的精确到秒的列
原因:虽然日期时间类型能够精确到秒,而且方便查看,但是我们一般使用时间戳。
时间戳:是1970-01-01 00:00:00到当前的秒数,用int存储
创建表
create table jary(
id int primary key auto_increment,
name char(5) not null default ”,
age tinyint unsigned not null default ‘0’,
salary decimal(7,2) not null default ‘1888’
)engine=Innodb,charset=utf8;
select 5种子句介绍
where 条件查询
where 表达式中可以使用in,between and, or,and,not等关键字
group by 分组
分组,一般和统计函数配合使用(max,min,sum,count,avg)
having 筛选(对where查询出来的结果再次筛选)
数据在表中,表在硬盘或者内存以文件形式存在,
having就是针对查询的结果发挥作用
order by 排序
作用:排序
可以针对字段,升序【asc】,降序【desc】排序
有可能一个字段排不出结果,可以选用其他字段继续排序。
order by 字段1【asc/desc】,字段2【asc/desc】。。。
limit 限制结果条数
limit【offer】 N
offer:偏移量
N :取出条目
这几种子句组合查询时,它的书写顺序是按照where,group,having,order by,limit顺序,否则会出现查询出来的数据不准确或者错误提示
例子:查询2们成绩不及格的同学及其他们的平局分
这个查询综合性很强

经过反复试查,最后得出的语句为
select name,sum(score<60) as bjg,avg(score) as pj from stu1 group by name having bjg>=2;

子查询
where型子查询
把内层查询结果作为外层查询的比较条件
典型题:查询最大商品,最贵商品
from型子查询
把内层的查询结果当成临时表,供外层sql再次查询
典型题:查询每个栏目下的最新/最贵商品
exists型子查询
把外层的查询结果拿到内层,看内层的条件是否成立
典型题:查询有商品的栏目

Union:联合
作用:把2次或多次查询结果合并起来
要求:二次查询的列数要一致
推荐:查询的每一列,相对应的列类型也一样
可以来自多张表
多次sql语句取出的列名可以不一致,此时已第一个sql的列名为准
左连接或右链接,内链接
左连接:
select 列名1,列名2,列N from
tableA left join tableB on tableA 列=tableB(on后面是条件)
此处表连接成一张大表,完全当成普通表看
where ,group,having,..照常写
右连接:
select 列名1,列名2,列N from
tableA right join tableB on tableA 列=tableB(on后面是条件)
此处表连接成一张大表,完全当成普通表看
where ,group,having,..照常写
内连接:
select 列名1,列名2,列N from
tableA inner join tableB on tableA 列=tableB(on后面是条件)
此处表连接成一张大表,完全当成普通表看
where ,group,having,..照常写
它们之间的关系:
左连接:以左表为准,右表去匹配符合条件的左表数据,找不到匹配就用null补齐
右连接:以右表为准,左表去匹配符合条件的右表数据
左右连接可以相互转换,
推荐使用左连接代替右连接,兼容性好一些
内连接:查询左右表都有的数据即:不要左右连接中null的那部分
内连接时左右连接的交集
思考:能否查出左右连接的并集呢
答:目前不能,目前mysql不支持外连接。可以用union来实现
表管理之增删改
增加一列
alter table 表名 add 列声明
增加的列默认是在表的最后一列
可以用after来声明新增的列在哪一些后面
alter table 表名 add 列声明 after 列名
修改表的列名
alter table 表名 change 待修改列名 列声明
删除表的列
alter table 表名 drop 列名
视图
视图的定义:由查询结果形成的一张虚拟表
视图的创建语法:create view 视图名 as select语句
视图的删除语法:drop view 视图名
视图的一些重要参数
create [algorithm=merge|temptable|undefined] view viewname as select………
merge(合并的意思),会对
使用场景:
1、权限控制
可以进行权限控制,把表的权限封闭,但是开放相应的视图权限,视图里只开放部分数据
2、大数据分表时可以用到
比如:表的行数超过200万行时,就会变慢
可以把一张的表的数据拆成4张表来存放
News 表
Newsid升序排列
News1,news2,news3,news4表
把一张表的数据分散到四张表中,分散的方法很多,最常用的可以用id取模来计算
id%4+1=[1,2,3,4]
比如:id=17则17%4+1=2则table的名字就是new2,
select * from news2 where id=17;
还可以用视图,把4张表形成一张视图
create view news as select from n1 union select from n2 union……
视图和表的关系
视图是表的查询结果,所以表的数据改变了,影响视图的结果
视图数据改变了,也会影响表的数据的改变,但是视图并不是总能增删改的(当视图数据和表的数据一一对应时,可以修改)
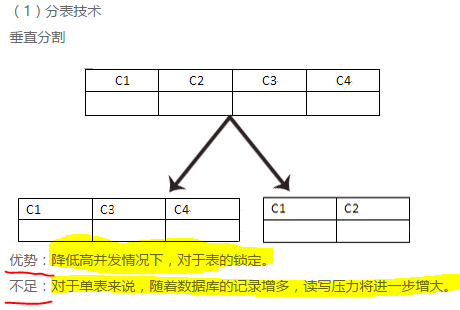
补充mysql分区分表技术解决大数据存储性能的问题。
面对当今大数据存储,设想当mysql中一个表的总记录超过1000W,会出现性能的大幅度下降吗?
答案是肯定的,一个表的总记录超过1000W,在操作系统层面检索也是效率非常低的
面对海量数据时,优化的方法有2种:
1,分表技术(垂直分表和水平分表)

字符集与校对集
mysql的字符集设置非常灵活
可以设置服务器默认的字符集
数据库默认字符集
表的默认字符集
列字符集
如果某一级别没有指定字符集,则继承上一级
触发器trigger(枪击,引线的意思)
触发器的定义:监控某种情况并触发某种操作
应用场景:完成下单与减少库存的逻辑(用户下单后就减少库存
),这二个逻辑可以看作一个整体,某种情况的发生变化,就触发某个操作。
触发器:能监控表的,增,删,改;触发操作:增,删,改
触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/before) 4.触发事件(insert/update/delete)
创建触发器的语句:create trigger triggerName
After/before insert/update/delete on 表名
for each row
begin sql语句(一句或多句insert/update/delete范围内)
end
删除触发器的语法:
Drop trigger 触发器名
如何在触发器引用行的值
对于insert而言,新增的行,用new来表示,行中的每一列的值,用new.列名来表示
对于delete而言:原本有一行,后来被删除,想引用被删除的这一行,用old来表示,old.列名可以引用被删除的行的值。
触发器实例练习:
首先我们来创建两张表:
商品表
create table g
(
id int primary key auto_increment,
name varchar(20),
num int
);
订单表
create table o
(
oid int primary key auto_increment,
gid int,
much int
);
insert into g(name,num) values(‘商品1’,10),(‘商品2’,10),(‘商品3’,10);
现在,我们来创建一个触发器:
需要先执行该语句:delimiter (意思是告诉mysql语句的结尾换成以 结束)
create trigger tg2
after insert on o
for each row
begin
update g set num=num-3 where id=1;
end$
这时候我们只要执行:
insert into o(gid,much) values(1,3)$
会发现商品1的数量变为7了,说明在我们插入一条订单的时候,触发器自动帮我们做了更新操作。
但现在会有一个问题,因为我们触发器里面num和id都是写死的,所以不管我们买哪个商品,最终更新的都是商品1的数量。比如:我们往订单表再插入一条记录:insert into o(gid,much) values(2,3),执行完后会发现商品1的数量变4了,而商品2的数量没变,这样显然不是我们想要的结果。我们需要改改我们之前创建的触发器。
我们如何在触发器引用行的值,也就是说我们要得到我们新插入的订单记录中的gid或much的值。
对于insert而言,新插入的行用new来表示,行中的每一列的值用new.列名来表示
添加订单,库存减少
create trigger tg2
after insert on o
for each row
begin
update g set num=num-new.much where id=new.gid;
end$
现在还存在两种情况:
1.当用户撤销一个订单的时候,我们这边直接删除一个订单,我们是不是需要把对应的商品数量再加回去呢?
2.当用户修改一个订单的数量时,我们触发器修改怎么写?
对于delete而言:原本有一行,后来被删除,想引用被删除的这一行,用old来表示,old.列名可以引用被删除的行的值。
那我们的触发器就该这样写:
create trigger tg3
after delete on o
for each row
begin
update g set num = num + old.much where id = old.gid;(注意这边的变化)
end 创建完毕。再执行deletefromowhereoid=2
会发现商品2的数量又变为10了。
第二种情况:
监视地点:o表
监视事件:update
触发时间:after
触发事件:update
对于update而言:被修改的行,修改前的数据,用old来表示,old.列名引用被修改之前行中的值;修改的后的数据,用new来表示,new.列名引用被修改之后行中的值。
那我们的触发器就该这样写:
create trigger tg4
after update on o
for each row
begin
update g set num = num+old.much-new.much where id = old/new.gid;
end$
先把旧的数量恢复再减去新的数量就是修改后的数量了。
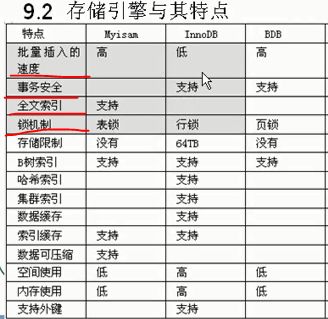
存储引擎
举例,一部电影可以是mp4,wmv,avi,rmvb等,同样的一部电影在硬盘上有不同的存储格式,所占用的空间与清晰程度也不一样
表里的数据存储在硬盘上具体如何存储的?
表的存储方式也是不一样。同样的数据在数据库中的不同管理方式,就是存储引擎
事例理解:地铁站有二个自行车管理员,李小心和张马虎,李小心是党用户来存车的时候,查看存车人和车的特征,取车时会看是否一致;而张马虎就不管这些,只管出门交5毛钱就行。
常用表的引擎有:Innodb(李小心的事例,安全性高,但是效率低)和myisam(张马虎事例,安全性差,但是效率高)
事务
事务的特性:
原子性(atomicity),操作语句要么全部成功,要么全部失败。
一致性(consistency):在事务的前后数据应保持一致。
隔离性(isolation):某个事务的操作对其他事务不可见的。
持久性(durability):当事务完成后,其影响应该保存下来,不能撤销。
mysql默认是开启事务自动提交的,setAutoCommit=0手动提交
开启事务:start transaction;
提交事务:commit(),也可以回滚 rollback
数据库存储引擎:myisam不支持事务,innodb支持事务
数据库的备份和恢复

例四,如何导出所有库
mysqldump -u 用户名 -p 密码 库名 表名 >/back/mysql
上面的操作不是很完整安全,应该如下写法:
mysqldump -u 用户名 -p 密码 库名 -l -F >/back/mysql
参数-l表示备份的时候锁表,不能再修改数据,
参数-F表示(flush logs)可以重新生成新的bin日志文件
数据库恢复
进入mysql中,执行source < 备份.sql
不进入mysql中 执行mysql -u 用户名 -p 库名 < 备份库名.sql
索引
索引的好处:加快了查询速度
索引的不足:降低了增删改的速度
增大了文件的大小(索引的大小比文件数据还要大几倍)
当一个公司的服务器更换,数据要导出,数据量很大500万行
这时候就要先去掉索引,再导入,最后再统一建索引的思路,要不会很慢,无法忍受的慢
加索使用原则:不要过度索引,这样会降低增删改的速度
索引条件列(where后面最频繁的条件比较适宜索引)
索引散列值,过于集中的不适合建索引例如性别‘男’和 ‘女’;
索引分为
普通索引:index 仅仅是加快查询速度
唯一索引:unique index 行上的值,不能重复
主键索引:primary key 主键不能重复
*全文索引:***fulltext index 文章内容的查找(目前只有myisam引擎支持fulltext类型的索引,innodb可以通过使用sphinx插件支持全文索引,并且效果更好,sphinx是一个开源软件,可以优化mysql的各种查询)
全文索引支持的字段类型:varchar,text,char
修改表的存储引擎
alter table jary type=’myisam’;之前添加全文索引总是报错,修改成myisam后建立全文索引成功
目前知道MySQL 5.6.4里才添加了InnoDB引擎的Full-Text索引支持
mysql 5.6.4支持nosql:
在最新的 mysql-5.6.4-labs-innodb-memcached 中,实现了简单的给予 key/value的nosql功能,其主要原理
就是mysqld除了监听3306端口之外,同时监听11211端口。使mysqld和memcached服务处在同一进程中。通过
数据库、表与字段的映射,将缓存在memcache的数据插入到映射的表中。
全文索引针对于文本内容的查找
全文索引的用法:Match(全文索引字段) against(“keyword”);
select * from 表名 where match(全文索引字段) against(‘keyword’);
全文索引的停止词:全文索引不针对非常频繁的词做索引(this,is,you,me等等)
全文索引在mysql的默认情况下,对于中文字符意义不大
创建索引的语法(不要创建主键索引,因为主键已经带有索引功能)
//create index 索引名 on table(字段名);
show index from 表名;//查看表的索引
//drop index 索引名 on 表名;//删除表的索引
创建唯一索引
//create unique index un_name on t1(name);
删除唯一索引
//drop index un_name on t1;
但是我们最常用的方法是使用alter table
建立索引
alter table t1 add index/unique/fulltext 索引名(字段名);
删除索引
alter table t1 drop index index_name;
删除主键索引
首先要确定主键索引不是自增的,如果是自增的就不能删除
移除主键自增的命令
alter table t1 modify id int not null;
然后执行
alter table t1 drop primary key;
存储过程procedure(用在比较大的项目中,小项目用不到)
概念:类似于函数,就是把一段代码封装起来,当执行这段代码的时候,可以通过调用该存储过程来实现,在封装的语句体中,可以使用if/else,case,while等控制结构;可以进行sql编程
查看现有的存储过程
show procedure status;
删除存储过程
Drop procedure 存储过程名字
调用存储过程
call 存储过程名();
实例:
创建存储过程(begin…..end之间就是要封装的语句类似于函数体)
create procedure p1()
begin
select * from jary;
end$
调用存储过程
call p();
mysql的优化(主要是索引)
索引在遇到条件语句and 或者 or时,要求二边的字段,要么加索引,要么都不加索引,否则一方加索引是不会生效的
还有一点就是在进行模糊查询 like语句时,添加‘%’时,要把‘%’放在keyword的后面,放前面的话,索引就不会生效
表操作中的一个实用命令,创建一个表复制另一个表的表结构
create table t1 like t2;
然后把t2中的数据插入到t1中
insert into t1 select * from t2;
查看索引的使用情况的语句
如果索引正常在工作,Handler_read_key的值将很高,这个值代表了一个行被索引值读的次数。
Handle_read_rnd_next的值高则意味着查询运行低效,并且应该建立索引补救,到底哪一列需要加索引呢,就需要我们结合慢查询去观察才能发现
表的优化
分析表:检测一个或多个表是否有错误
check table 表名
优化表:如果已经删除了表的一大部分,或者如果已经修改了可变长度行的表,则需要做定期优化。optimize可以将表中的空间碎片进行合并,但是此命令只对myisam和innodb、BDB引擎的表其作用
optimize table t1;

常用sql的优化
1,大批量插入数据
当使用load命令导入数据时,适当的设置可以提高导入速度
对已myisam存储引擎的表,可以通过以下方式快速导入大量的数据
当使用msyqldump的导出速度比较慢,我们使用infile和outfile配合load data进行快速的导入和导出
导出outfile的使用,使用mysql的帮助语法 msyql> ? outfile;导出的只是数据文件不包括表结构
select * from 表名 into outfile ‘导出的文件目录/文件名’;
例如:select * from t1 into outfile ‘/temp/test.txt’;
![]()
导入数据时用infile
导入数据前先把users表的数据清空
truncate users;
然后执行下面语句把数据导入到users表中
load data infile ‘users.txt’ into table users;

大量数据时,我们可以速度更快,那就是先把普通索引关掉,等导入数据后再重新创建索引,最好只关闭普通索引,不关闭唯一索引(如果确保表中不可能有重复的行的话也可以关掉,否则不要关闭)
alter table 表名 disable keys (关闭索引)
load data infile ‘users.txt’ into table users;(导入数据)
alter table 表名 enable keys (开启索引)
关闭唯一索引也可以提高导入效率(前提是表中的所有行中没有重复,否则千万不要关闭)
set unique_checks=0 (关闭唯一索引)
导入数据
set unique_checks=1(开启唯一索引)
对于innodb引擎的表,数据导入的优化
因为innodb表是按照主键顺序保存的,所以将导入的数据主键的顺序排列,可以提高导入数据的效率

关闭事务的自动提交可以提高导入效率
导入前关闭自动提交 set autocommint =0
导入数据
恢复自动提交 set autocommit=1
insert语句的优化
优化嵌套查询
在查询中最好少用嵌套查询这样可能用不到索引,我们要用左连接,或者多表查询来解决
使用嵌套不能使用索引的例子

表t1没有用到主键索引
数据库的优化
1,优化表的类型
2,通过拆分提高表的访问效率
3,使用中间表提高统计查询速度
sphinx全文检索
mysql内置函数
字符串函数
concat()