Linux性能优化笔记
CPU性能监控解析
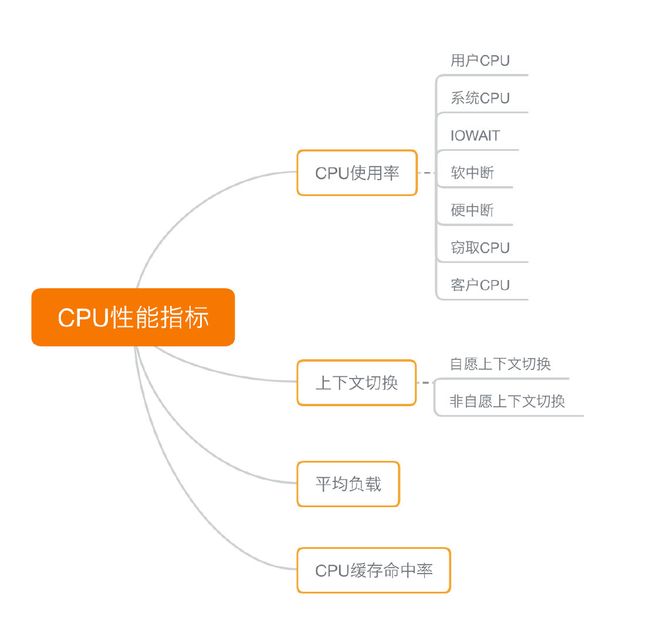
首先,最容易想到的应该是 CPU 使用率,这也是实际环境中最常见的一个性能指标。
CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户CPU、系统CPU、等待I/O CPU、软中断和硬中断等。
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
- 等待 I/O 的CPU使用率,通常也称为iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
- 除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
第二个比较容易想到的,应该是平均负载(Load Average),也就是系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去1分钟、过去5分钟和过去15分钟的平均负载。
理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑CPU个数,就表示负载比较重了。
第三个,进程上下文切换,包括:
- 无法获取资源而导致的自愿上下文切换;
- 被系统强制调度导致的非自愿上下文切换。
上下文切换,本身是保证 Linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
除了上面几种,还有一个指标,CPU缓存的命中率。由于CPU发展的速度远快于内存的发展,CPU的处理速度就比内存的访问速度快得多。这样,CPU在访问内存的时候,免不了要等待内存的响应。为了协调这两者巨大的性能差距,CPU缓存(通常是多级缓存)就出现了。
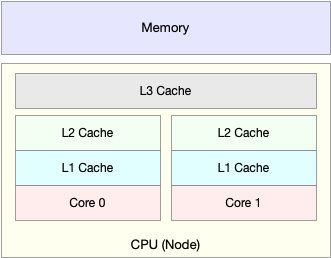
就像上面这张图显示的,CPU缓存的速度介于CPU和内存之间,缓存的是热点的内存数据。根据不断增长的热点数据,这些缓存按照大小不同分为 L1、L2、L3 等三级缓存,其中 L1 和 L2 常用在单核中, L3 则用在多核中。
从 L1 到 L3,三级缓存的大小依次增大,相应的,性能依次降低(当然比内存还是好得多)。而它们的命中率,衡量的是CPU缓存的复用情况,命中率越高,则表示性能越好。
这些指标都很有用,需要我们熟练掌握,可以当成CPU性能分析的“指标筛选”清单。
性能工具
掌握了 CPU 的性能指标,我们还需要知道,怎样去获取这些指标,也就是工具的使用。
首先,分析平均负载。先用 uptime, 查看了系统的平均负载;而在平均负载升高后,又用 mpstat 和 pidstat ,分别观察了每个 CPU 和每个进程 CPU 的使用情况,进而找出了导致平均负载升高的进程(压测工具 stress)。
第二个,分析上下文切换。先用 vmstat ,查看了系统的上下文切换次数和中断次数;然后通过 pidstat ,观察了进程的自愿上下文切换和非自愿上下文切换情况;最后通过 pidstat ,观察了线程的上下文切换情况,找出了上下文切换次数增多的根源(基准测试工具 sysbench)。
第三个,分析进程 CPU 使用率升高。先用 top ,查看了系统和进程的CPU使用情况,发现 CPU 使用率升高的进程;再用 perf top ,观察 具体进程 的调用链,最终找出 CPU 升高的根源 。
第四个,分析系统的 CPU 使用率升高。先用 top 观察到了系统CPU升高,如果通过 top 和 pidstat ,却找不出高 CPU 使用率的进程。重新审视 top 的输出,又从 CPU 使用率不高但处于 Running 状态的进程入手,找出了可疑之处,最终通过 perf record 和 perf report ,进一步发现可能是短时进程在捣鬼。
另外,对于短时进程,一个专门的工具 execsnoop,它可以实时监控进程调用的外部命令。
第五个,分析不可中断进程和僵尸进程。先用 top 观察到了 iowait 升高的问题,并发现了大量的不可中断进程和僵尸进程;接着我们用 dstat 发现是这是由磁盘读导致的,于是又通过 pidstat 找出了相关的进程。但我们用 strace 查看进程系统调用却失败了,最终还是用 perf 分析进程调用链,才发现根源在于磁盘直接 I/O 。
最后一个,分析软中断。通过 top 观察到,系统的软中断 CPU 使用率升高;接着查看 /proc/softirqs, 找到了几种变化速率较快的软中断;然后通过 sar 命令,发现是网络小包的问题,最后再用 tcpdump ,找出网络帧的类型和来源(最终确定是一个 SYN FLOOD 攻击导致的)。
活学活用,把性能指标和性能工具联系起来
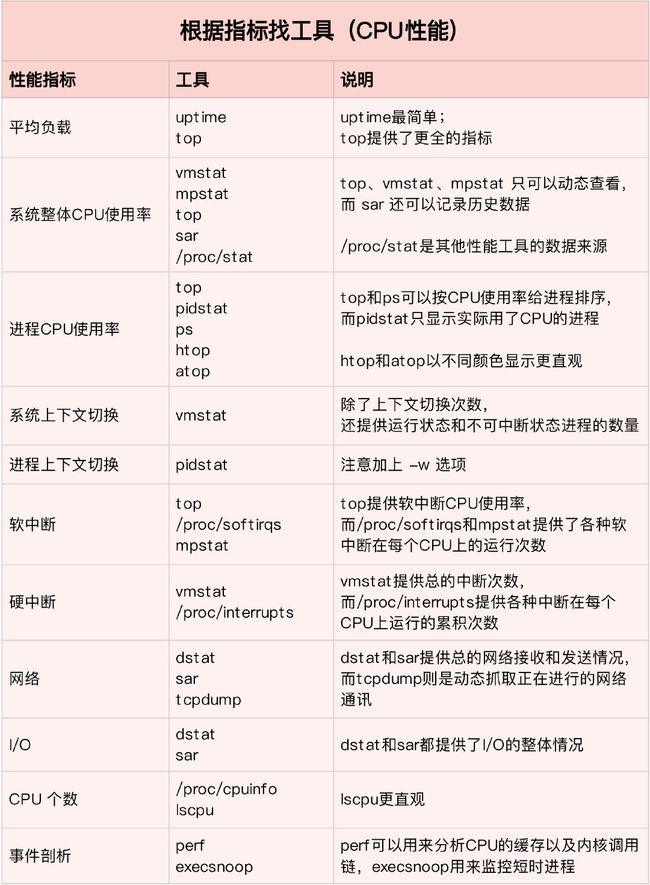
根据不同的性能指标,对提供指标的性能工具进行分类和理解。这样,在实际排查性能问题时,你就可以清楚知道,什么工具可以提供你想要的指标,而不是毫无根据地挨个尝试,撞运气。
比如用 top 发现了软中断 CPU 使用率高后,下一步自然就想知道具体的软中断类型。那在哪里可以观察各类软中断的运行情况呢?当然是 proc 文件系统中的 /proc/softirqs 这个文件。
紧接着,比如说,我们找到的软中断类型是网络接收,那就要继续往网络接收方向思考。系统的网络接收情况是什么样的?什么工具可以查到网络接收情况呢?在我们案例中,用的正是 dstat。
CPU 性能指标“指标工具”指南:
如何迅速分析CPU的性能瓶颈
在实际生产环境中,我们通常都希望尽可能快地定位系统的瓶颈,然后尽可能快地优化性能,也就是要又快又准地解决性能问题。想弄清楚性能指标的关联性,就要通晓每种性能指标的工作原理。
举个例子,用户 CPU 使用率高,我们应该去排查进程的用户态而不是内核态。因为用户 CPU 使用率反映的就是用户态的 CPU 使用情况,而内核态的 CPU 使用情况只会反映到系统 CPU 使用率上。
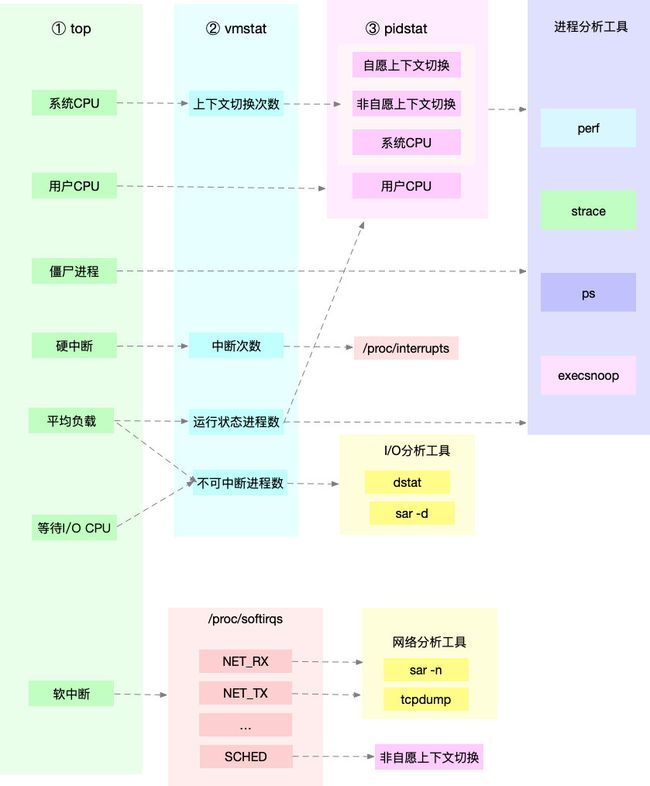
这张图里,列出了 top、vmstat 和 pidstat 分别提供的重要的 CPU 指标,并用虚线表示关联关系,对应出了性能分析下一步的方向。
通过这张图你可以发现,这三个命令,几乎包含了所有重要的 CPU 性能指标,比如:
- 从 top 的输出可以得到各种 CPU 使用率以及僵尸进程和平均负载等信息。
- 从 vmstat 的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数。
- 从 pidstat 的输出可以得到进程的用户 CPU 使用率、系统 CPU 使用率、以及自愿上下文切换和非自愿上下文切换情况。
另外,这三个工具输出的很多指标是相互关联的,举几个例子你可能会更容易理解。
第一个例子,pidstat 输出的进程用户 CPU 使用率升高,会导致 top 输出的用户 CPU 使用率升高。所以,当发现 top 输出的用户 CPU 使用率有问题时,可以跟 pidstat 的输出做对比,观察是否是某个进程导致的问题。
而找出导致性能问题的进程后,就要用进程分析工具来分析进程的行为,比如使用 strace 分析系统调用情况,以及使用 perf 分析调用链中各级函数的执行情况。
第二个例子,top 输出的平均负载升高,可以跟 vmstat 输出的运行状态和不可中断状态的进程数做对比,观察是哪种进程导致的负载升高。
- 如果是不可中断进程数增多了,那么就需要做 I/O 的分析,也就是用 dstat 或 sar 等工具,进一步分析 I/O 的情况。
- 如果是运行状态进程数增多了,那就需要回到 top 和 pidstat,找出这些处于运行状态的到底是什么进程,然后再用进程分析工具,做进一步分析。
最后一个例子,当发现 top 输出的软中断 CPU 使用率升高时,可以查看 /proc/softirqs 文件中各种类型软中断的变化情况,确定到底是哪种软中断出的问题。比如,发现是网络接收中断导致的问题,那就可以继续用网络分析工具 sar 和 tcpdump 来分析。
平均负载
![]()
21:46:38 //当前时间
up 25 days, 23:07 //系统运行时间
1 user //正在登录用户数
而最后三个数字呢,依次则是过去1分钟、5分钟、15分钟的平均负载(Load Average)。
执行top或者uptime命令,来了解系统的负载情况。比如像上面这样,在命令行里输入了uptime命令,系统也随即给出了结果。
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。
所谓可运行状态的进程,是指正在使用CPU或者正在等待CPU的进程,也就是我们常用ps命令看到的,处于R状态(Running 或 Runnable)的进程。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的I/O响应,也就是我们在ps命令中看到的D状态(Uninterruptible Sleep,也称为Disk Sleep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。
平均负载为多少时合理
平均负载最理想的情况是等于 CPU个数。所以在评判平均负载时,首先你要知道系统有几个 CPU,这可以通过 top 命令或者从文件 /proc/cpuinfo 中读取
举个例子,假设我们在一个单 CPU 系统上看到平均负载为 1.73,0.60,7.98,那么说明在过去 1 分钟内,系统有 73% 的超载,而在 15 分钟内,有 698% 的超载,从整体趋势来看,系统的负载在降低。
当平均负载高于 CPU 数量70%的时候,你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。
平均负载与CPU使用率
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高。
案例分析
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
而 sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。我们的案例会用到这个包的两个命令 mpstat 和 pidstat。
- mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有CPU的平均指标。
- pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
首先,我们在第一个终端运行 stress 命令,模拟一个 CPU 使用率 100% 的场景:
$ stress --cpu 1 --timeout 600
接着,在第二个终端运行uptime查看平均负载的变化情况:
# -d 参数表示高亮显示变化的区域
$ watch -d uptime
..., load average: 1.00, 0.75, 0.39
最后,在第三个终端运行mpstat查看 CPU 使用率的变化情况:
# -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
$ mpstat -P ALL 5
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95
13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
从终端二中可以看到,1 分钟的平均负载会慢慢增加到 1.00,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。
那么,到底是哪个进程导致了 CPU 使用率为 100% 呢?你可以使用 pidstat 来查询:
# -d 展示 I/O 统计数据,-p 指定进程号 间隔5秒后输出一组数据
$ pidstat -u 5 1
13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command
13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stress
从这里可以明显看到,stress进程的CPU使用率为100%。
CPU上下文切换
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间, CPU 特权等级的 Ring 0 和 Ring 3。
- 内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
- 用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
系统调用(属于同进程内的CPU上下文切换)过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
进程执行完终止场景
其一,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行
其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
其四,当有优先级更高的进程运行时
最后一个,发生硬件中断时,CPU上的进程会被中断挂起,转而执行内核中的中断服务程序。
线程上下文切换
线程是调度的基本单位,而进程则是资源拥有的基本单位。
同进程内的线程切换(因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据),要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
中断上下文切换
中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级
查看上下文切换
我们可以使用 vmstat 这个工具,来查询系统的上下文切换情况。
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。
比如,下面就是一个 vmstat 的使用示例:
# 每隔5秒输出1组数据
$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7005360 91564 818900 0 0 0 0 25 33 0 0 100 0 0
我们一起来看这个结果,你可以先试着自己解读每列的含义。在这里,我重点强调下,需要特别关注的四列内容:
- cs(context switch)是每秒上下文切换的次数。
- in(interrupt)则是每秒中断的次数。
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待CPU的进程数。
- b(Blocked)则是处于不可中断睡眠状态的进程数。
查看每个进程的详细情况,就需要使用我们前面提到过的 pidstat 了。加上 -w 选项,你就可以查看每个进程上下文切换的情况了。
比如说:
# 每隔5秒输出1组数据
$ pidstat -w 5
Linux 4.15.0 (ubuntu) 09/23/18 _x86_64_ (2 CPU)
08:18:26 UID PID cswch/s nvcswch/s Command
08:18:31 0 1 0.20 0.00 systemd
08:18:31 0 8 5.40 0.00 rcu_sched
...
这个结果中有两列内容是我们的重点关注对象。一个是 cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
这两个概念你一定要牢牢记住,因为它们意味着不同的性能问题:
- 所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- 而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
案例分析
在第一个终端里运行 sysbench ,模拟系统多线程调度的瓶颈:
# 以10个线程运行5分钟的基准测试,模拟多线程切换的问题
$ sysbench --threads=10 --max-time=300 threads run
接着,在第二个终端运行 vmstat ,观察上下文切换情况:
# 每隔1秒输出1组数据(需要Ctrl+C才结束)
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
6 0 0 6487428 118240 1292772 0 0 0 0 9019 1398830 16 84 0 0 0
8 0 0 6487428 118240 1292772 0 0 0 0 10191 1392312 16 84 0 0 0
可以发现,cs 列的上下文切换次数从之前的 35 骤然上升到了 139 万。同时,注意观察其他几个指标:
- r 列:就绪队列的长度已经到了 8,远远超过了系统 CPU 的个数 2,所以肯定会有大量的 CPU 竞争。
- us(user)和 sy(system)列:这两列的CPU 使用率加起来上升到了 100%,其中系统 CPU 使用率,也就是 sy 列高达 84%,说明 CPU 主要是被内核占用了。
- in 列:中断次数也上升到了1万左右,说明中断处理也是个潜在的问题。
综合这几个指标,可以知道,系统的就绪队列过长,也就是正在运行和等待CPU的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。
那么到底是什么进程导致了这些问题呢?
继续分析,在第三个终端再用 pidstat 来看一下, CPU 和进程上下文切换的情况:
# 每隔1秒输出1组数据(需要 Ctrl+C 才结束)
# -w参数表示输出进程切换指标,而-u参数则表示输出CPU使用指标
$ pidstat -w -u 1
08:06:33 UID PID %usr %system %guest %wait %CPU CPU Command
08:06:34 0 10488 30.00 100.00 0.00 0.00 100.00 0 sysbench
08:06:34 0 26326 0.00 1.00 0.00 0.00 1.00 0 kworker/u4:2
08:06:33 UID PID cswch/s nvcswch/s Command
08:06:34 0 8 11.00 0.00 rcu_sched
08:06:34 0 16 1.00 0.00 ksoftirqd/1
08:06:34 0 471 1.00 0.00 hv_balloon
08:06:34 0 1230 1.00 0.00 iscsid
08:06:34 0 4089 1.00 0.00 kworker/1:5
08:06:34 0 4333 1.00 0.00 kworker/0:3
08:06:34 0 10499 1.00 224.00 pidstat
08:06:34 0 26326 236.00 0.00 kworker/u4:2
08:06:34 1000 26784 223.00 0.00 sshd
从pidstat的输出可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 100%。但上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的 pidstat ,以及自愿上下文切换频率最高的内核线程 kworker 和 sshd。
不过,pidstat 输出的上下文切换次数,加起来也就几百,比 vmstat 的 139 万明显小了太多。这是怎么回事呢?难道是工具本身出了错吗?
在怀疑工具之前,再来回想一下,前面讲到的几种上下文切换场景。其中有一点提到, Linux 调度的基本单位实际上是线程,而 sysbench 模拟的也是线程的调度问题,那么,是不是 pidstat 忽略了线程的数据呢?
通过运行 man pidstat 发现,pidstat 默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。
所以,可以在第三个终端里, Ctrl+C 停止刚才的 pidstat 命令,再加上 -t 参数,重试一下看看:
# 每隔1秒输出一组数据(需要 Ctrl+C 才结束)
# -wt 参数表示输出线程的上下文切换指标
$ pidstat -wt 1
08:14:05 UID TGID TID cswch/s nvcswch/s Command
...
08:14:05 0 10551 - 6.00 0.00 sysbench
08:14:05 0 - 10551 6.00 0.00 |__sysbench
08:14:05 0 - 10552 18911.00 103740.00 |__sysbench
08:14:05 0 - 10553 18915.00 100955.00 |__sysbench
08:14:05 0 - 10554 18827.00 103954.00 |__sysbench
...
现在就能看到了,虽然 sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。看来,上下文切换罪魁祸首,还是过多的 sysbench 线程。
前面在观察系统指标时,除了上下文切换频率骤然升高,还有一个指标也有很大的变化。是的,正是中断次数。中断次数也上升到了1万,但到底是什么类型的中断上升了,现在还不清楚。接下来继续抽丝剥茧找源头。
既然是中断,,它只发生在内核态,而 pidstat 只是一个进程的性能分析工具,并不提供任何关于中断的详细信息,怎样才能知道中断发生的类型呢?
没错,那就是从 /proc/interrupts 这个只读文件中读取。/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况。
我们还是在第三个终端里, Ctrl+C 停止刚才的 pidstat 命令,然后运行下面的命令,观察中断的变化情况:
# -d 参数表示高亮显示变化的区域
$ watch -d cat /proc/interrupts
CPU0 CPU1
...
RES: 2450431 5279697 Rescheduling interrupts
...
观察一段时间,可以发现,变化速度最快的是重调度中断(RES),这个中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)。
但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。
CPU 使用率
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的 CPU 和任务统计信息
节拍率是内核态运行,属于内核空间节拍率;用户空间节拍率( USER_HZ)是一个固定设置
[root@dVM_0_9_centos ~]# grep ‘CONFIG_HZ=’ /boot/config-$(uname -r)
CONFIG_HZ=1000
为了计算 CPU 使用率,性能工具一般都会取间隔一段时间(比如3秒)的两次值,作差后,再计算出这段时间内的平均 CPU 使用率,即

这个公式是各种性能工具所看到的CPU 使用率的实际计算方法。
性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证它们用的是相同的间隔时间。
比如,对比一下 top 和 ps 这两个工具报告的 CPU 使用率,默认的结果很可能不一样,因为 top 默认使用 3 秒时间间隔,而 ps 使用的却是进程的整个生命周期。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
分析进程的 CPU 问题工具
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数。
其他知识点
**进程的 PID 在变,这说明什么呢?**在我看来,要么是这些进程在不停地重启,要么就是全新的进程,这无非也就两个原因:
- 第一个原因,进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启了。
- 第二个原因,这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现
pidstat 中, %wait 表示进程等待 CPU 的时间百分比。
top 中 ,iowait% 则表示等待 I/O 的 CPU 时间百分比。
用 pstree 就可以用树状形式显示所有进程之间的关系:
$ pstree | grep stress
|-docker-containe-+-php-fpm-+-php-fpm---sh---stress
| |-3*[php-fpm---sh---stress---stress]
给请求加入 verbose=1 参数后,就可以查看 stress 的输出。你先试试看,在终端运行:
$ curl http://192.168.0.10:10000?verbose=1
Server internal error: Array
(
[0] => stress: info: [19607] dispatching hogs: 0 cpu, 0 io, 0 vm, 1 hdd
[1] => stress: FAIL: [19608] (563) mkstemp failed: Permission denied
[2] => stress: FAIL: [19607] (394) <-- worker 19608 returned error 1
[3] => stress: WARN: [19607] (396) now reaping child worker processes
[4] => stress: FAIL: [19607] (400) kill error: No such process
[5] => stress: FAIL: [19607] (451) failed run completed in 0s
)
分析 CPU 性能事件,运行 perf record -g 命令 ,并等待一会儿(比如15秒)后按 Ctrl+C 退出。然后再运行 perf report 查看报告:
# 记录性能事件,等待大约15秒后按 Ctrl+C 退出
$ perf record -g
# 查看报告
$ perf report
execsnoop 就是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
进程的状态,包括运行(R)、空闲(I)、不可中断睡眠(D)、可中断睡眠(S)、僵尸(Z)以及暂停(T)等。
dstat ,它的好处是,可以同时查看 CPU 和 I/O 这两种资源的使用情况,便于对比分析。
进程想要访问磁盘,就必须使用系统调用,所以接下来,重点就是找出 app 进程的系统调用了。
strace 正是最常用的跟踪进程系统调用的工具。
Linux软中断
Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
这两个阶段你也可以这样理解:
- 上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行;
- 而下半部则是由内核触发,也就是我们常说的软中断,特点是延迟执行。
实际上,上半部会打断CPU正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个 CPU 都对应一个软中断内核线程,名字为 “ksoftirqd/CPU编号”,比如说, 0 号CPU对应的软中断内核线程的名字就是 ksoftirqd/0。
不过要注意的是,软中断不只包括了刚刚所讲的硬件设备中断处理程序的下半部,一些内核自定义的事件也属于软中断,比如内核调度和RCU锁(Read-Copy Update 的缩写,RCU 是 Linux 内核中最常用的锁之一)等。
查看软中断和内核线程
proc 文件系统是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。其中:
- /proc/softirqs 提供了软中断的运行情况;
- /proc/interrupts 提供了硬中断的运行情况。
工具介绍与使用
sar、 hping3 和 tcpdump,先简单介绍一下:
- sar 是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
- hping3 是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等。
- tcpdump 是一个常用的网络抓包工具,常用来分析各种网络问题。
hping3 命令,来模拟客户端请求SYN FLOOD 攻击
# -S参数表示设置TCP协议的SYN(同步序列号),-p表示目的端口为80
# -i u100表示每隔100微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把100调小,比如调成10甚至1
$ hping3 -S -p 80 -i u100 192.168.0.30
系统响应明显变慢了。
sar 可以用来查看系统的网络收发情况,还有一个好处是,不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的 PPS,即每秒收发的网络帧数。
sar 命令,并添加 -n DEV 参数显示网络收发的报告
# -n DEV 表示显示网络收发的报告,间隔1秒输出一组数据
$ sar -n DEV 1
15:03:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
15:03:47 eth0 12607.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01
15:03:47 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00
15:03:47 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
15:03:47 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05
对于 sar 的输出界面,我先来简单介绍一下,从左往右依次是:
- 第一列:表示报告的时间。
- 第二列:IFACE 表示网卡。
- 第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。
- 第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
tcpdump 命令,网络抓包
例如Nginx 监听在 80 端口,它所提供的 HTTP 服务是基于 TCP 协议的,所以我们可以指定 TCP 协议和 80 端口精确抓包。
接下来,运行 tcpdump 命令,通过 -i eth0 选项指定网卡 eth0,并通过 tcp port 80 选项指定 TCP 协议的 80 端口:
# -i eth0 只抓取eth0网卡,-n不解析协议名和主机名
# tcp port 80表示只抓取tcp协议并且端口号为80的网络帧
$ tcpdump -i eth0 -n tcp port 80
15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0
...
从 tcpdump 的输出中,你可以发现
- 192.168.0.2.18238 > 192.168.0.30.80 ,表示网络帧从 192.168.0.2 的 18238 端口发送到 192.168.0.30 的 80 端口,也就是从运行 hping3 机器的 18238 端口发送网络帧,目的为 Nginx 所在机器的 80 端口。
- Flags [S] 则表示这是一个 SYN 包。
内存性能监控解析
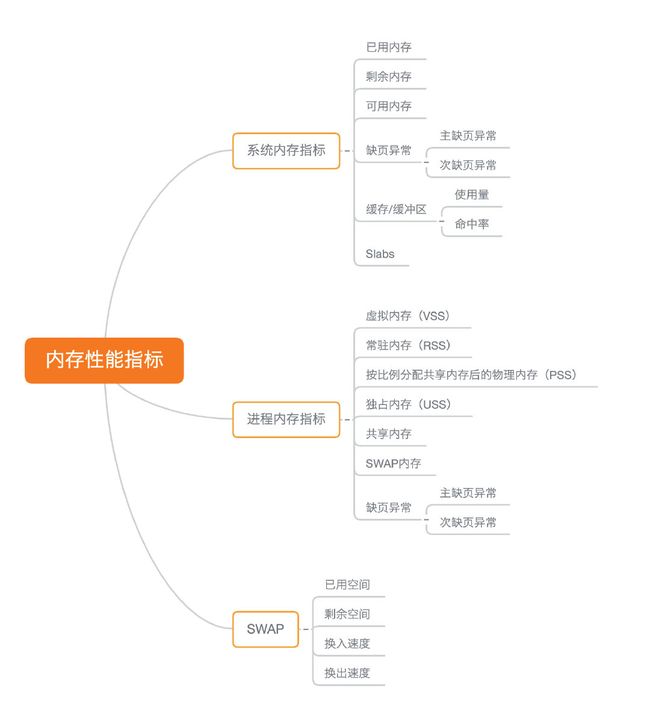
首先,你最容易想到的是系统内存使用情况
- 已用内存和剩余内存很容易理解,就是已经使用和还未使用的内存。
- 共享内存是通过tmpfs实现的,所以它的大小也就是tmpfs使用的内存大小。tmpfs其实也是一种特殊的缓存。
- 可用内存是新进程可以使用的最大内存,它包括剩余内存和可回收缓存。
- 缓存(Cache)包括两部分,一部分是磁盘读取文件的页缓存,用来缓存从磁盘读取的数据,可以加快以后再次访问的速度。另一部分,则是Slab分配器中的可回收内存。
- 缓冲区(Buffer)是对原始磁盘块的临时存储,用来缓存将要写入磁盘的数据。
第二类应该是进程内存使用情况,比如进程的虚拟内存、常驻内存、共享内存以及Swap内存等。
- 虚拟内存,包括了进程代码段、数据段、共享内存、已经申请的堆内存和已经换出的内存等。这里要注意,已经申请的内存,即使还没有分配物理内存,也算作虚拟内存。
- 常驻内存是进程实际使用的物理内存,不过,它不包括Swap和共享内存。
- 共享内存,既包括与其他进程共同使用的真实的共享内存,还包括了加载的动态链接库以及程序的代码段等。
- Swap内存,是指通过Swap换出到磁盘的内存。
第三类重要指标就是Swap的使用情况,比如Swap的已用空间、剩余空间、换入速度和换出速度等。
- 已用空间和剩余空间很好理解,就是字面上的意思,已经使用和没有使用的内存空间。
- 换入和换出速度,则表示每秒钟换入和换出内存的大小。
内存思维导图:
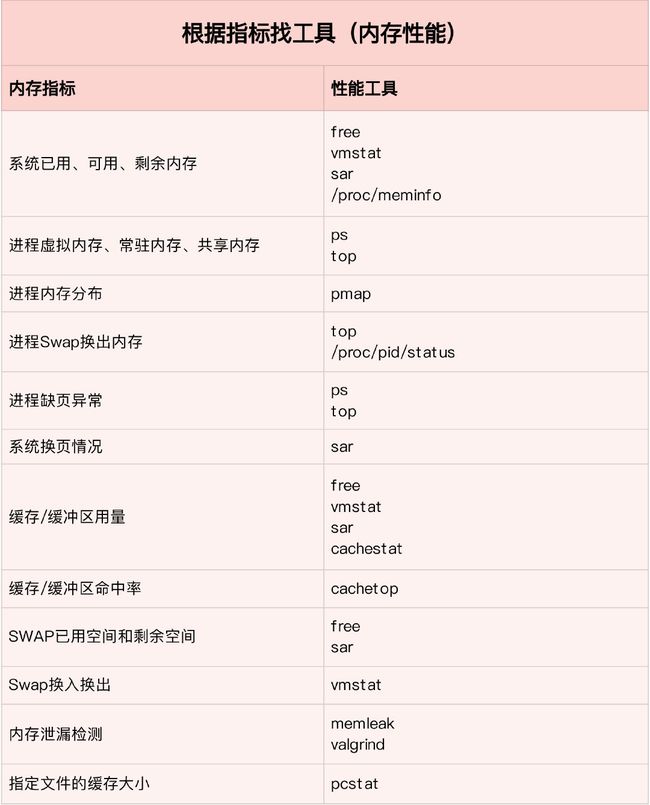
内存性能工具
最常用的内存工具free,可以查看系统的整体内存和Swap使用情况。相对应的,可以用top或ps,查看进程的内存使用情况。
通过proc文件系统,找到了内存指标的来源;通过vmstat,动态观察了内存的变化情况。与free相比,vmstat除了可以动态查看内存变化,还可以区分缓存和缓冲区、Swap换入和换出的内存大小。
cachestat ,查看整个系统缓存的读写命中情况,并用 cachetop 来观察每个进程缓存的读写命中情况。
例如:分析内存泄漏,可以用vmstat,发现了内存使用在不断增长,又用memleak,确认发生了内存泄漏。通过memleak给出的内存分配栈,我们找到了内存泄漏的可疑位置。
分析Swap,可以用sar发现了缓冲区和Swap升高的问题。通过cachetop,找到了缓冲区升高的根源;通过对比剩余内存跟/proc/zoneinfo的内存阈(可以发现Swap升高是内存回收导致的)。
通过/proc文件系统,找出了Swap所影响的进程。
性能指标和工具的联系
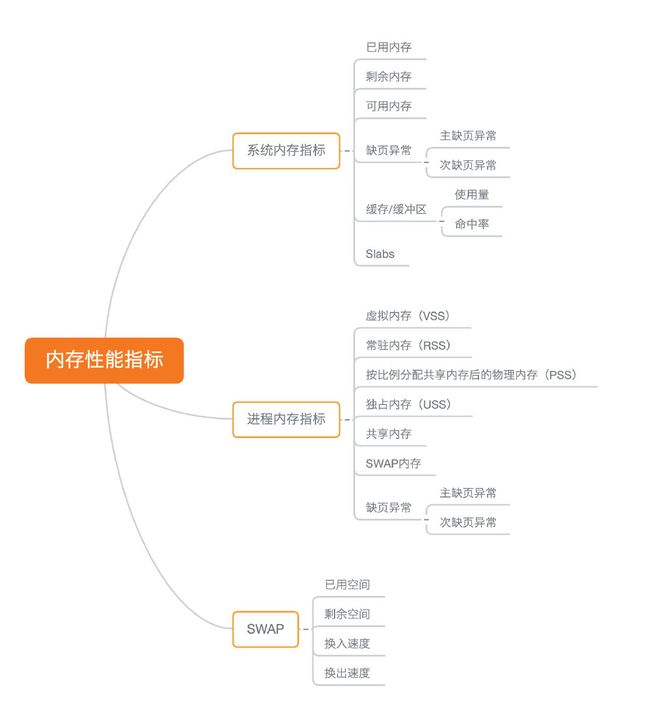
如何迅速分析内存的性能瓶颈
在实际生产环境中,我们希望的是,尽可能快地定位系统瓶颈,然后尽可能快地优化性能,也就是要又快又准地解决性能问题。
具体的分析思路主要有这几步。
- 先用free和top,查看系统整体的内存使用情况。
- 再用vmstat和pidstat,查看一段时间的趋势,从而判断出内存问题的类型。
- 最后进行详细分析,比如内存分配分析、缓存/缓冲区分析、具体进程的内存使用分析等。
分析过程流程图:
第一个例子,当通过free,发现大部分内存都被缓存占用后,可以使用vmstat或者sar观察一下缓存的变化趋势,确认缓存的使用是否还在继续增大。
如果继续增大,则说明导致缓存升高的进程还在运行,那就能用缓存/缓冲区分析工具(比如cachetop、slabtop等),分析这些缓存到底被哪里占用。
第二个例子,当free一下,发现系统可用内存不足时,首先要确认内存是否被缓存/缓冲区占用。排除缓存/缓冲区后,可以继续用pidstat或者top,定位占用内存最多的进程。
找出进程后,再通过进程内存空间工具(比如pmap),分析进程地址空间中内存的使用情况就可以了。
第三个例子,当通过vmstat或者sar发现内存在不断增长后,可以分析中是否存在内存泄漏的问题。
比如可以使用内存分配分析工具 memleak ,检查是否存在内存泄漏。如果存在内存泄漏问题,memleak会输出内存泄漏的进程以及调用堆栈。
小结
常见的优化思路有这么几种。
- 最好禁止 Swap。如果必须开启Swap,降低swappiness的值,减少内存回收时Swap的使用倾向。
- 减少内存的动态分配。比如,可以使用内存池、大页(HugePage)等。
- 尽量使用缓存和缓冲区来访问数据。比如,可以使用堆栈明确声明内存空间,来存储需要缓存的数据;或者用Redis 这类的外部缓存组件,优化数据的访问。
- 使用cgroups等方式限制进程的内存使用情况。这样,可以确保系统内存不会被异常进程耗尽。
- 通过 /proc/pid/oom_adj ,调整核心应用的oom_score。这样,可以保证即使内存紧张,核心应用也不会被OOM杀死。
内存映射
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存。
虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同字长(也就是单个CPU指令可以处理数据的最大长度)的处理器,地址空间的范围也不同。比如最常见的 32 位和 64 位系统,我画了两张图来分别表示它们的虚拟地址空间,如下所示:
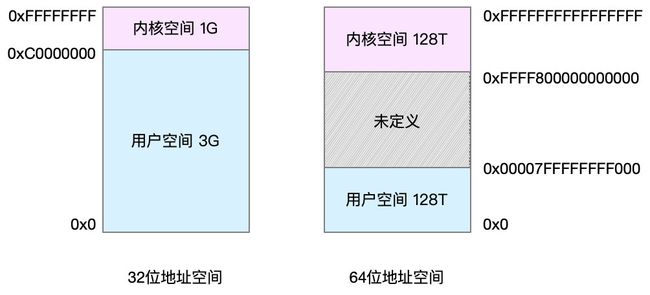
通过这里可以看出,32位系统的内核空间占用 1G,位于最高处,剩下的3G是用户空间。而 64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
进程在用户态时,只能访问用户空间内存;只有进入内核态后,才可以访问内核空间内存。
并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。
内存映射,其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系,如下图所示:
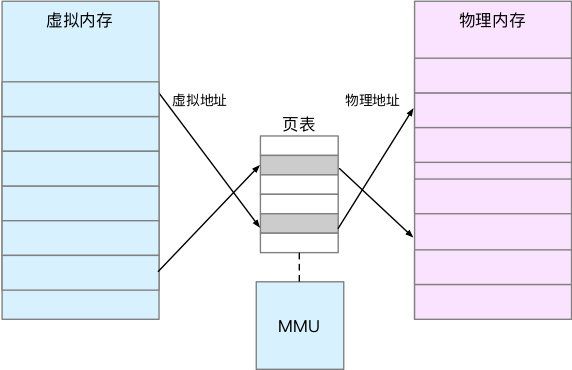
页表实际上存储在 CPU 的内存管理单元 MMU中,这样,正常情况下,处理器就可以直接通过硬件,找出要访问的内存。
另外, TLB 其实就是 MMU 中页表的高速缓存。由于进程的虚拟地址空间是独立的,而 TLB 的访问速度又比 MMU 快得多,所以,通过减少进程的上下文切换,减少TLB的刷新次数,就可以提高TLB 缓存的使用率,进而提高CPU的内存访问性能。
MMU 规定了一个内存映射的最小单位页,通常是 4 KB大小。这样,每一次内存映射,都需要关联 4 KB 或者 4KB 整数倍的内存空间。
为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage)。
内存分配与回收
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
对小块内存(小于128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
而大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块空闲内存分配出去。
当这两种调用发生后,其实并没有真正分配内存。这些内存,都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
在用户空间,malloc 通过 brk() 分配的内存,在释放时并不立即归还系统,而是缓存起来重复利用。在内核空间,Linux 则通过 slab 分配器来管理小内存。你可以把slab 看成构建在伙伴系统上的一个缓存,主要作用就是分配并释放内核中的小对象。
在应用程序用完内存后,还需要调用 free() 或 unmap() ,来释放这些不用的内存。
如何查看内存使用情况
查看系统内存使用工具 free 。下面是一个 free 的输出示例:
# 注意不同版本的free输出可能会有所不同
$ free
total used free shared buff/cache available
Mem: 8169348 263524 6875352 668 1030472 7611064
Swap: 0 0 0
可以看到,free 输出的是一个表格,其中的数值都默认以字节为单位。表格总共有两行六列,这两行分别是物理内存 Mem 和交换分区 Swap 的使用情况,而六列中,每列数据的含义分别为:
- 第一列,total 是总内存大小;
- 第二列,used 是已使用内存的大小,包含了共享内存;
- 第三列,free 是未使用内存的大小;
- 第四列,shared 是共享内存的大小;
- 第五列,buff/cache 是缓存和缓冲区的大小;
- 最后一列,available 是新进程可用内存的大小。
这里尤其注意一下,最后一列的可用内存available 。available不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。
查看进程的内存使用情况,可以用 top 或者 ps 等工具。
内存Buffer和Cache
- Buffer既可以用作“将要写入磁盘数据的缓存”,也可以用作“从磁盘读取数据的缓存”。
- Cache既可以用作“从文件读取数据的页缓存”,也可以用作“写文件的页缓存”。
通常,我们用缓存命中率,来衡量缓存的使用效率。命中率越高,表示缓存被利用得越充分,应用程序的性能也就越好。
你可以用 cachestat 和 cachetop 这两个工具,观察系统和进程的缓存命中情况。其中,
- cachestat 提供了整个系统缓存的读写命中情况。
- cachetop 提供了每个进程的缓存命中情况。
不过要注意,Buffers 和 Cache 都是操作系统来管理的,应用程序并不能直接控制这些缓存的内容和生命周期。所以,在应用程序开发中,一般要用专门的缓存组件,来进一步提升性能。
比如,程序内部可以使用堆或者栈明确声明内存空间,来存储需要缓存的数据。再或者,使用 Redis 这类外部缓存服务,优化数据的访问效率。
其他知识点:
指定文件在内存中的缓存大小。你可以使用 pcstat 这个工具,来查看文件在内存中的缓存大小以及缓存比例。
dd 作为一个磁盘和文件的拷贝工具,经常被拿来测试磁盘或者文件系统的读写性能。
strace工具用来观察系统调用。
pgrep 命令来查找案例进程的 PID 号。
strace -p $(pgrep app)
Swap
缓存和缓冲区,就属于可回收内存。它们在内存管理中,通常被叫做文件页(File-backed Page)。
应用程序动态分配的堆内存,也就是我们在内存管理中说到的匿名页(Anonymous Page)。
系统会通过三种方式回收内存。我们来复习一下,这三种方式分别是 :
- 基于 LRU(Least Recently Used)算法,回收缓存;
- 基于 Swap 机制,回收不常访问的匿名页;
- 基于 OOM(Out of Memory)机制,杀掉占用大量内存的进程。
OOM 机制按照 oom_score 给进程排序。oom_score 越大,进程就越容易被系统杀死。
当系统发现内存不足以分配新的内存请求时,就会尝试直接内存回收。这种情况下,如果回收完文件页和匿名页后,内存够用了,当然皆大欢喜,把回收回来的内存分配给进程就可以了。但如果内存还是不足,OOM就要登场了。
OOM 发生时,你可以在 dmesg 中看到 Out of memory 的信息,从而知道是哪些进程被 OOM 杀死了。比如,你可以执行下面的命令,查询 OOM 日志:
$ dmesg | grep -i "Out of memory"
Out of memory: Kill process 9329 (java) score 321 or sacrifice child
当然了,如果你不希望应用程序被 OOM 杀死,可以调整进程的 oom_score_adj,减小 OOM 分值,进而降低被杀死的概率。
有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求。这个过程通常被称为直接内存回收。
专门的内核线程用来定期回收内存,就是kswapd0。
小结
在内存资源紧张时,Linux通过直接内存回收和定期扫描的方式,来释放文件页和匿名页,以便把内存分配给更需要的进程使用。
- 文件页的回收比较容易理解,直接清空,或者把脏数据写回磁盘后再释放。
- 而对匿名页的回收,需要通过Swap换出到磁盘中,下次访问时,再从磁盘换入到内存中。
你可以设置/proc/sys/vm/min_free_kbytes,来调整系统定期回收内存的阈值(也就是页低阈值),还可以设置/proc/sys/vm/swappiness,来调整文件页和匿名页的回收倾向。
在 NUMA 架构下,每个 Node 都有自己的本地内存空间,而当本地内存不足时,默认既可以从其他 Node 寻找空闲内存,也可以从本地内存回收。
你可以设置 /proc/sys/vm/zone_reclaim_mode ,来调整NUMA本地内存的回收策略。
文件系统与I/O
索引节点和目录项
在Linux中一切皆文件。不仅普通的文件和目录,就连块设备、套接字、管道等,也都要通过统一的文件系统来管理。
Linux文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。
索引节点和目录项纪录了文件的元数据,以及文件间的目录关系。
目录项、索引节点以及文件数据的关系示意图:
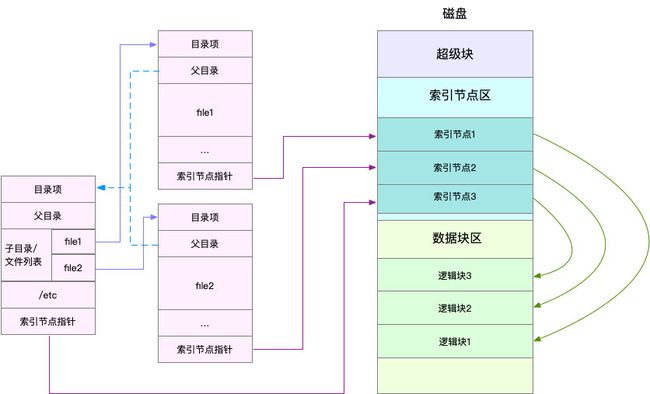
第一,目录项本身就是一个内存缓存,而索引节点则是存储在磁盘中的数据。在前面的Buffer和Cache原理中,我曾经提到过,为了协调慢速磁盘与快速CPU的性能差异,文件内容会缓存到页缓存Cache中。
那么,你应该想到,这些索引节点自然也会缓存到内存中,加速文件的访问。
第二,磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。
虚拟文件系统
为了支持各种不同的文件系统,Linux内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
Linux文件系统的架构图:
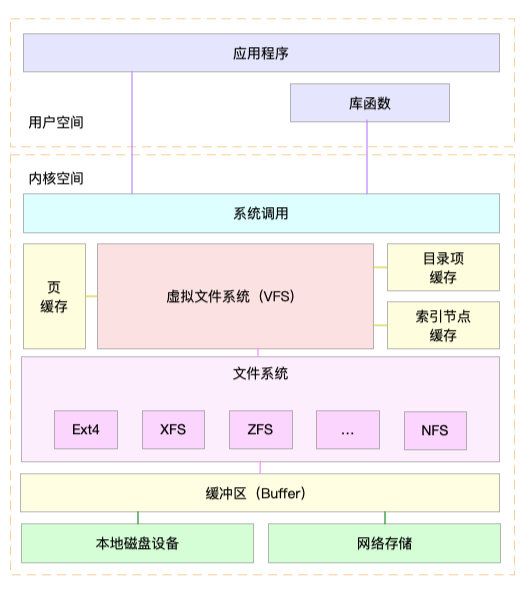
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc文件系统、/sys文件系统、NFS等)挂载进来。
文件系统I/O
把文件系统挂载到挂载点后,你就能通过挂载点,再去访问它管理的文件了。VFS 提供了一组标准的文件访问接口。这些接口以系统调用的方式,提供给应用程序使用。
就拿cat 命令来说,它首先调用 open() ,打开一个文件;然后调用 read() ,读取文件的内容;最后再调用 write() ,把文件内容输出到控制台的标准输出中:
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
文件读写方式的各种差异,导致 I/O的分类多种多样。最常见的有,缓冲与非缓冲I/O、直接与非直接I/O、阻塞与非阻塞I/O、同步与异步I/O等。 接下来,我们就详细看这四种分类。
第一种,根据是否利用标准库缓存,可以把文件I/O分为缓冲I/O与非缓冲I/O。
第二,根据是否利用操作系统的页缓存,可以把文件I/O分为直接I/O与非直接I/O。
直接I/O、非直接I/O,本质上还是和文件系统交互。如果是在数据库等场景中,你还会看到,跳过文件系统读写磁盘的情况,也就是我们通常所说的裸I/O。
第三,根据应用程序是否阻塞自身运行,可以把文件I/O分为阻塞I/O和非阻塞I/O:
- 所谓阻塞I/O,是指应用程序执行I/O操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
- 所谓非阻塞I/O,是指应用程序执行I/O操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。
比方说,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问;而如果不做任何设置,默认的就是阻塞访问。
第四,根据是否等待响应结果,可以把文件I/O分为同步和异步I/O:
- 所谓同步I/O,是指应用程序执行I/O操作后,要一直等到整个I/O完成后,才能获得I/O响应。
- 所谓异步I/O,是指应用程序执行I/O操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O完成后,响应会用事件通知的方式,告诉应用程序。
再比如,在访问管道或者网络套接字时,设置了O_ASYNC选项后,相应的I/O就是异步I/O。这样,内核会再通过SIGIO或者SIGPOLL,来通知进程文件是否可读写。
你可能发现了,这里的好多概念也经常出现在网络编程中。比如非阻塞I/O,通常会跟select/poll配合,用在网络套接字的I/O中。
无论是普通文件和块设备、还是网络套接字和管道等,它们都通过统一的VFS 接口来访问。
性能观测
容量
查看文件系统的磁盘空间使用情况。可以给df加上-h选项,以获得更好的可读性:
$ df -h /dev/sda1
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 29G 3.1G 26G 11% /
除了文件数据,索引节点也占用磁盘空间。你可以给df命令加上 -i 参数,查看索引节点的使用情况,如下所示:
$ df -i /dev/sda1
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda1 3870720 157460 3713260 5% /
索引节点的容量,(也就是Inode个数)是在格式化磁盘时设定好的,一般由格式化工具自动生成。当你发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。
所以,一般来说,删除这些小文件,或者把它们移动到索引节点充足的其他磁盘中,就可以解决这个问题。
其他知识点
在文件系统的下层,为了支持各种不同类型的存储设备,Linux又在各种存储设备的基础上,抽象了一个通用块层。
通用块层,为文件系统和应用程序提供了访问块设备的标准接口;同时,为各种块设备的驱动程序提供了统一的框架。此外,通用块层还会对文件系统和应用程序发送过来的 I/O 请求进行排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
通用块层的下一层,自然就是设备层了,包括各种块设备的驱动程序以及物理存储设备。
文件系统、通用块层以及设备层,就构成了 Linux 的存储 I/O 栈。存储系统的 I/O ,通常是整个系统中最慢的一环。所以,Linux 采用多种缓存机制,来优化 I/O 的效率,比方说,
- 为了优化文件访问的性能,采用页缓存、索引节点缓存、目录项缓存等多种缓存机制,减少对下层块设备的直接调用。
- 同样的,为了优化块设备的访问效率,使用缓冲区来缓存块设备的数据。
执行 stace 命令时,加上 -f 参数,可以读取多线程情况
在 SHELL 中,特殊标量 $? 表示上一条命令退出时的返回值。在 Linux 中,返回值为 0 ,才表示命令执行成功。返回值为1,显然表明执行失败。
# -t表示显示线程,-a表示显示命令行参数
$ pstree -t -a -p 27458
# -d选项表示展示进程的I/O情况
$ pidstat -d 1
案例分析
看看系统有没有性能问题。要观察哪些性能指标呢?
可以先用 top ,来观察 CPU 和内存的使用情况;然后再用 iostat ,来观察磁盘的 I/O 情况。
# -d表示显示I/O性能指标,-x表示显示扩展统计(即所有I/O指标)
$ iostat -x -d 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 64.00 0.00 32768.00 0.00 0.00 0.00 0.00 0.00 7270.44 1102.18 0.00 512.00 15.50 99.20
观察 iostat 的最后一列,你会看到,磁盘 sda 的 I/O 使用率已经高达 99%,很可能已经接近 I/O 饱和。
再看前面的各个指标,每秒写磁盘请求数是 64 ,写大小是 32 MB,写请求的响应时间为 7 秒,而请求队列长度则达到了 1100。
超慢的响应时间和特长的请求队列长度,进一步验证了 I/O 已经饱和的猜想。此时,sda 磁盘已经遇到了严重的性能瓶颈。
到这里,也就可以理解,为什么前面看到的 iowait 高达 90% 了,这正是磁盘 sda 的 I/O 瓶颈导致的。接下来的重点就是分析 I/O 性能瓶颈的根源了。那要怎么知道,这些 I/O请求相关的进程呢?
使用 pidstat 加上 -d 参数,就可以显示每个进程的 I/O 情况。所以,可以在终端中运行如下命令来观察:
$ pidstat -d 1
15:08:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
15:08:36 0 18940 0.00 45816.00 0.00 96 python
15:08:36 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
15:08:37 0 354 0.00 0.00 0.00 350 jbd2/sda1-8
15:08:37 0 18940 0.00 46000.00 0.00 96 python
15:08:37 0 20065 0.00 0.00 0.00 1503 kworker/u4:2
从 pidstat 的输出,你可以发现,只有 python 进程的写比较大,而且每秒写的数据超过 45 MB,比上面 iostat 发现的 32MB 的结果还要大。很明显,正是 python 进程导致了 I/O 瓶颈。
再往下看 iodelay 项。虽然只有 python 在大量写数据,但你应该注意到了,有两个进程 (kworker 和 jbd2 )的延迟,居然比 python 进程还大很多。
综合pidstat的输出来看,还是python进程的嫌疑最大。接下来,来分析 python 进程到底在写什么。
知道了进程的 PID 号,具体要怎么查看写的情况呢?
读写文件必须通过系统调用完成。观察系统调用情况,就可以知道进程正在写的文件。想起 strace 了吗,它正是我们分析系统调用时最常用的工具。
接下来,我们在终端中运行strace 命令,并通过 -p 18940 指定 python 进程的 PID 号:
$ strace -p 18940
strace: Process 18940 attached
...
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f7aee9000
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f682e8000
write(3, "2018-12-05 15:23:01,709 - __main"..., 314572844
) = 314572844
munmap(0x7f0f682e8000, 314576896) = 0
write(3, "\n", 1) = 1
munmap(0x7f0f7aee9000, 314576896) = 0
close(3) = 0
stat("/tmp/logtest.txt.1", {st_mode=S_IFREG|0644, st_size=943718535, ...}) = 0
从 write() 系统调用上,我们可以看到,进程向文件描述符编号为 3 的文件中,写入了 300MB 的数据。看来,它应该是我们要找的文件。不过,write() 调用中只能看到文件的描述符编号,文件名和路径还是未知的。
再观察后面的 stat() 调用,你可以看到,它正在获取 /tmp/logtest.txt.1 的状态。 这种“点+数字格式”的文件,在日志回滚中非常常见。我们可以猜测,这是第一个日志回滚文件,而正在写的日志文件路径,则是/tmp/logtest.txt。
当然,这只是猜测,自然还需要验证。
这里,可以用工具 lsof,它专门用来查看进程打开文件列表,不过,这里的“文件”不只有普通文件,还包括了目录、块设备、动态库、网络套接字等。
接下来,我们在终端中运行下面的 lsof 命令,看看进程 18940 都打开了哪些文件:
$ lsof -p 18940
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 18940 root cwd DIR 0,50 4096 1549389 /
python 18940 root rtd DIR 0,50 4096 1549389 /
…
python 18940 root 2u CHR 136,0 0t0 3 /dev/pts/0
python 18940 root 3w REG 8,1 117944320 303 /tmp/logtest.txt
FD 表示文件描述符号,TYPE 表示文件类型,NAME 表示文件路径。这也是我们需要关注的重点。
再看最后一行,这说明,这个进程打开了文件 /tmp/logtest.txt,并且它的文件描述符是 3 号,而3 后面的 w ,表示以写的方式打开。
这跟刚才 strace 完我们猜测的结果一致,看来这就是问题的根源:进程 18940 以每次 300MB 的速度,在“疯狂”写日志,而日志文件的路径是 /tmp/logtest.txt。
网络性能指标
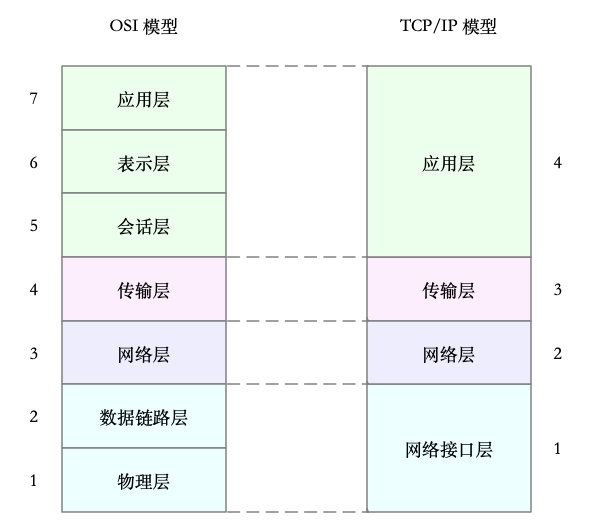
说到网络,可以联想到经常提起的七层负载均衡、四层负载均衡,或者三层设备、二层设备等等。那么,这里说的二层、三层、四层、七层又都是什么意思呢?
实际上,这些层都来自国际标准化组织制定的开放式系统互联通信参考模型(Open System Interconnection Reference Model),简称为 OSI 网络模型。
为了帮你更形象理解TCP/IP 与 OSI 模型的关系,我画了一张图,如下所示:
Linux网络栈
有了 TCP/IP 模型后,在进行网络传输时,数据包就会按照协议栈,对上一层发来的数据进行逐层处理;然后封装上该层的协议头,再发送给下一层。
比如,以通过 TCP 协议通信的网络包为例,通过下面这张图,可以看到,应用程序数据在每个层的封装格式。
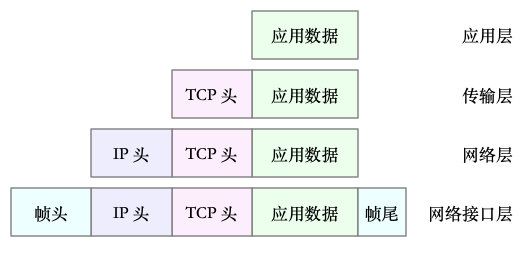
其中:
- 传输层在应用程序数据前面增加了 TCP 头;
- 网络层在 TCP 数据包前增加了 IP 头;
- 而网络接口层,又在 IP 数据包前后分别增加了帧头和帧尾。
Linux 内核中的网络栈,其实也类似于 TCP/IP 的四层结构。如下图所示,就是 Linux 通用 IP 网络栈的示意图:
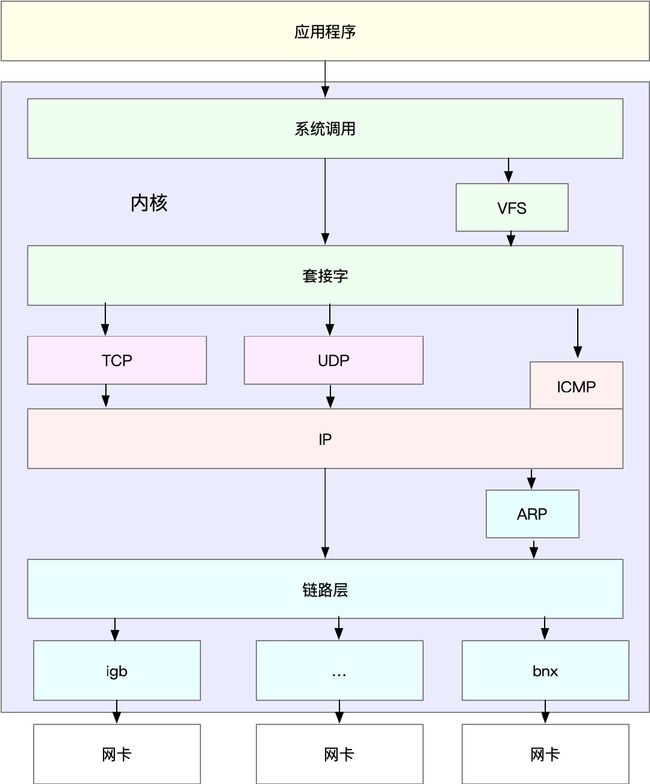
我们从上到下来看这个网络栈,你可以发现,
- 最上层的应用程序,需要通过系统调用,来跟套接字接口进行交互;
- 套接字的下面,就是我们前面提到的传输层、网络层和网络接口层;
- 最底层,则是网卡驱动程序以及物理网卡设备。
这里我简单说一下网卡。网卡是发送和接收网络包的基本设备。在系统启动过程中,网卡通过内核中的网卡驱动程序注册到系统中。而在网络收发过程中,内核通过中断跟网卡进行交互。
网卡硬中断只处理最核心的网卡数据读取或发送,而协议栈中的大部分逻辑,都会放到软中断中处理。
Linux网络收发流程
了解了 Linux 网络栈后,我们再来看看, Linux 到底是怎么收发网络包的。
注意,以下内容都以物理网卡为例。事实上,Linux 还支持众多的虚拟网络设备,而它们的网络收发流程会有一些差别。
网络包的接收流程
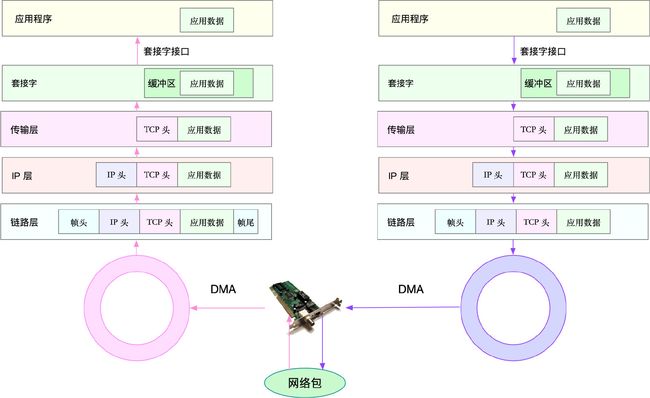
我们先来看网络包的接收流程。
当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中;然后通过硬中断,告诉中断处理程序已经收到了网络包。
接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中;然后再通过软中断,通知内核收到了新的网络帧。
接下来,内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧。比如,
- 在链路层检查报文的合法性,找出上层协议的类型(比如 IPv4 还是 IPv6),再去掉帧头、帧尾,然后交给网络层。
- 网络层取出 IP 头,判断网络包下一步的走向,比如是交给上层处理还是转发。当网络层确认这个包是要发送到本机后,就会取出上层协议的类型(比如 TCP 还是 UDP),去掉 IP 头,再交给传输层处理。
- 传输层取出 TCP 头或者 UDP 头后,根据 <源 IP、源端口、目的 IP、目的端口> 四元组作为标识,找出对应的 Socket,并把数据拷贝到 Socket 的接收缓存中。
最后,应用程序就可以使用 Socket 接口,读取到新接收到的数据了。
流程图:
性能指标
实际上,我们通常用带宽、吞吐量、延时、PPS(Packet Per Second)等指标衡量网络的性能。
- 带宽,表示链路的最大传输速率,单位通常为 b/s (比特/秒)。
- 吞吐量,表示没丢包时的最大数据传输速率,单位通常为 b/s(比特/秒)或者 B/s(字节/秒)。吞吐量受带宽限制,而吞吐量/带宽,也就是该网络的使用率。
- 延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)。
- PPS,是 Packet Per Second(包/秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。
除了这些指标,网络的可用性(网络能否正常通信)、并发连接数(TCP连接数量)、丢包率(丢包百分比)、重传率(重新传输的网络包比例)等也是常用的性能指标。
网络配置
可以使用 ifconfig 或者 ip 命令,来查看网络的配置。
ifconfig 和 ip 分别属于软件包 net-tools 和 iproute2,iproute2 是 net-tools 的下一代。通常情况下它们会在发行版中默认安装。但如果你找不到 ifconfig 或者 ip 命令,可以安装这两个软件包。
以网络接口 eth0 为例,你可以运行下面的两个命令,查看它的配置和状态:
$ ifconfig eth0
eth0: flags=4163 mtu 1500
inet 10.240.0.30 netmask 255.240.0.0 broadcast 10.255.255.255
inet6 fe80::20d:3aff:fe07:cf2a prefixlen 64 scopeid 0x20
ether 78:0d:3a:07:cf:3a txqueuelen 1000 (Ethernet)
RX packets 40809142 bytes 9542369803 (9.5 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 32637401 bytes 4815573306 (4.8 GB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ ip -s addr show dev eth0
2: eth0: mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 78:0d:3a:07:cf:3a brd ff:ff:ff:ff:ff:ff
inet 10.240.0.30/12 brd 10.255.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20d:3aff:fe07:cf2a/64 scope link
valid_lft forever preferred_lft forever
RX: bytes packets errors dropped overrun mcast
9542432350 40809397 0 0 0 193
TX: bytes packets errors dropped carrier collsns
4815625265 32637658 0 0 0 0
你可以看到,ifconfig 和 ip 命令输出的指标基本相同,只是显示格式略微不同。比如,它们都包括了网络接口的状态标志、MTU 大小、IP、子网、MAC 地址以及网络包收发的统计信息。
这些具体指标的含义,在文档中都有详细的说明,不过,这里有几个跟网络性能密切相关的指标,需要你特别关注一下。
第一,网络接口的状态标志。ifconfig 输出中的 RUNNING ,或 ip 输出中的 LOWER_UP ,都表示物理网络是连通的,即网卡已经连接到了交换机或者路由器中。如果你看不到它们,通常表示网线被拔掉了。
第二,MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了 VXLAN 等叠加网络),你可能需要调大或者调小 MTU 的数值。
第三,网络接口的 IP 地址、子网以及 MAC 地址。这些都是保障网络功能正常工作所必需的,你需要确保配置正确。
第四,网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。
套接字信息
可以用 netstat 或者 ss ,来查看套接字、网络栈、网络接口以及路由表的信息。
查询套接字信息:
# head -n 3 表示只显示前面3行
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
$ netstat -nlp | head -n 3
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 840/systemd-resolve
# -l 表示只显示监听套接字
# -t 表示只显示 TCP 套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
$ ss -ltnp | head -n 3
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=840,fd=13))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1459,fd=3))
netstat 和 ss 的输出也是类似的,都展示了套接字的状态、接收队列、发送队列、本地地址、远端地址、进程 PID 和进程名称等。
其中,接收队列(Recv-Q)和发送队列(Send-Q)需要你特别关注,它们通常应该是 0。当你发现它们不是 0 时,说明有网络包的堆积发生。当然还要注意,在不同套接字状态下,它们的含义不同。
当套接字处于连接状态(Established)时,
- Recv-Q 表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)。
- 而 Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)。
当套接字处于监听状态(Listening)时,
- Recv-Q 表示 syn backlog 的当前值。
- 而 Send-Q 表示最大的 syn backlog 值。
而 syn backlog 是 TCP 协议栈中的半连接队列长度,相应的也有一个全连接队列(accept queue),它们都是维护 TCP 状态的重要机制。
顾名思义,所谓半连接,就是还没有完成 TCP 三次握手的连接,连接只进行了一半,而服务器收到了客户端的 SYN 包后,就会把这个连接放到半连接队列中,然后再向客户端发送 SYN+ACK 包。
而全连接,则是指服务器收到了客户端的 ACK,完成了 TCP 三次握手,然后就会把这个连接挪到全连接队列中。这些全连接中的套接字,还需要再被 accept() 系统调用取走,这样,服务器就可以开始真正处理客户端的请求了。
协议栈统计信息
类似的,使用 netstat 或 ss ,也可以查看协议栈的信息:
$ netstat -s
...
Tcp:
3244906 active connection openings
23143 passive connection openings
115732 failed connection attempts
2964 connection resets received
1 connections established
13025010 segments received
17606946 segments sent out
44438 segments retransmitted
42 bad segments received
5315 resets sent
InCsumErrors: 42
...
$ ss -s
Total: 186 (kernel 1446)
TCP: 4 (estab 1, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 0
Transport Total IP IPv6
* 1446 - -
RAW 2 1 1
UDP 2 2 0
TCP 4 3 1
...
这些协议栈的统计信息都很直观。ss 只显示已经连接、关闭、孤儿套接字等简要统计,而netstat 则提供的是更详细的网络协议栈信息。
比如,上面 netstat 的输出示例,就展示了 TCP 协议的主动连接、被动连接、失败重试、发送和接收的分段数量等各种信息。
网络吞吐和 PPS
接下来,如何查看系统当前的网络吞吐量和 PPS。在这里,推荐使用sar,在前面的 CPU、内存和 I/O 模块中,已经多次用到它。
给 sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等等。执行下面的命令,你就可以得到网络接口统计信息:
# 数字1表示每隔1秒输出一组数据
$ sar -n DEV 1
Linux 4.15.0-1035-azure (ubuntu) 01/06/19 _x86_64_ (2 CPU)
13:21:40 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
13:21:41 eth0 18.00 20.00 5.79 4.25 0.00 0.00 0.00 0.00
13:21:41 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
13:21:41 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
这儿输出的指标比较多,我来简单解释下它们的含义。
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包/秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是KB/秒。
- rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包/秒。
- %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth。
其中,Bandwidth 可以用 ethtool 来查询,它的单位通常是 Gb/s 或者 Mb/s,不过注意这里小写字母 b ,表示比特而不是字节。通常提到的千兆网卡、万兆网卡等,单位也都是比特。如下可以看到, 下面的eth0 网卡就是一个千兆网卡:
$ ethtool eth0 | grep Speed
Speed: 1000Mb/s
连通性和延时
最后,我们通常使用 ping ,来测试远程主机的连通性和延时,而这基于 ICMP 协议。比如,执行下面的命令,你就可以测试本机到 114.114.114.114 这个 IP 地址的连通性和延时:
# -c3表示发送三次ICMP包后停止
$ ping -c3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=54 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=47 time=244 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=67 time=244 ms
--- 114.114.114.114 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 244.023/244.070/244.105/0.034 ms
ping 的输出,可以分为两部分。
- 第一部分,是每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时间,或者跳数)以及往返延时。
- 第二部分,则是三次 ICMP 请求的汇总。
比如上面的示例显示,发送了 3 个网络包,并且接收到 3 个响应,没有丢包发生,这说明测试主机到 114.114.114.114 是连通的;平均往返延时(RTT)是 244ms,也就是从发送 ICMP 开始,到接收到 114.114.114.114 回复的确认,总共经历 244ms。
网络的 I/O 模型
I/O 模型优化
两种 I/O 事件通知的方式:水平触发和边缘触发,它们常用在套接字接口的文件描述符中。
- 水平触发:只要文件描述符可以非阻塞地执行 I/O ,就会触发通知。也就是说,应用程序可以随时检查文件描述符的状态,然后再根据状态,进行 I/O 操作。
- 边缘触发:只有在文件描述符的状态发生改变(也就是 I/O 请求达到)时,才发送一次通知。这时候,应用程序需要尽可能多地执行 I/O,直到无法继续读写,才可以停止。如果 I/O 没执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了。
异步、非阻塞 I/O 的解决思路,你应该听说过,其实就是我们在网络编程中经常用到的 I/O 多路复用(I/O Multiplexing)。
接下来,回过头来看 I/O 多路复用的方法。
第一种,使用非阻塞 I/O 和水平触发通知,比如使用 select 或者 poll。
根据刚才水平触发的原理,select 和 poll 需要从文件描述符列表中,找出哪些可以执行 I/O ,然后进行真正的网络 I/O 读写。由于 I/O 是非阻塞的,一个线程中就可以同时监控一批套接字的文件描述符,这样就达到了单线程处理多请求的目的。
所以,这种方式的最大优点,是对应用程序比较友好,它的 API 非常简单。
但是,应用软件使用 select 和 poll 时,需要对这些文件描述符列表进行轮询,这样,请求数多的时候就会比较耗时。并且,select 和 poll 还有一些其他的限制。
select 使用固定长度的位相量,表示文件描述符的集合,因此会有最大描述符数量的限制。比如,在 32 位系统中,默认限制是 1024。并且,在select 内部,检查套接字状态是用轮询的方法,再加上应用软件使用时的轮询,就变成了一个 O(n^2) 的关系。
而 poll 改进了 select 的表示方法,换成了一个没有固定长度的数组,这样就没有了最大描述符数量的限制(当然还会受到系统文件描述符限制)。但应用程序在使用 poll 时,同样需要对文件描述符列表进行轮询,这样,处理耗时跟描述符数量就是 O(N) 的关系。
除此之外,应用程序每次调用 select 和 poll 时,还需要把文件描述符的集合,从用户空间传入内核空间,由内核修改后,再传出到用户空间中。这一来一回的内核空间与用户空间切换,也增加了处理成本。
第二种,使用非阻塞 I/O 和边缘触发通知,比如 epoll。
既然 select 和 poll 有那么多的问题,就需要继续对其进行优化,而 epoll 就很好地解决了这些问题。
- epoll 使用红黑树,在内核中管理文件描述符的集合,这样,就不需要应用程序在每次操作时都传入、传出这个集合。
- epoll 使用事件驱动的机制,只关注有 I/O 事件发生的文件描述符,不需要轮询扫描整个集合。
不过要注意,epoll 是在 Linux 2.6 中才新增的功能(2.4 虽然也有,但功能不完善)。由于边缘触发只在文件描述符可读或可写事件发生时才通知,那么应用程序就需要尽可能多地执行 I/O,并要处理更多的异常事件。
第三种,使用异步 I/O(Asynchronous I/O,简称为 AIO)。异步I/O 允许应用程序同时发起很多 I/O 操作,而不用等待这些操作完成。而在 I/O完成后,系统会用事件通知(比如信号或者回调函数)的方式,告诉应用程序。这时,应用程序才会去查询 I/O 操作的结果。
异步 I/O 也是到了 Linux 2.6 才支持的功能,并且在很长时间里都处于不完善的状态,比如 glibc 提供的异步 I/O 库,就一直被社区诟病。同时,由于异步 I/O 跟我们的直观逻辑不太一样,想要使用的话,一定要小心设计,其使用难度比较高。
工作模型优化
了解了 I/O 模型后,请求处理的优化就比较直观了。使用 I/O 多路复用后,就可以在一个进程或线程中处理多个请求,其中,又有下面两种不同的工作模型。
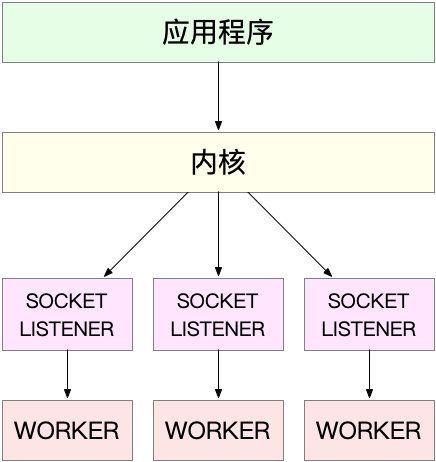
第一种,主进程+多个 worker 子进程,这也是最常用的一种模型。这种方法的一个通用工作模式就是:
- 主进程执行 bind() + listen() 后,创建多个子进程;
- 然后,在每个子进程中,都通过 accept() 或 epoll_wait() ,来处理相同的套接字。
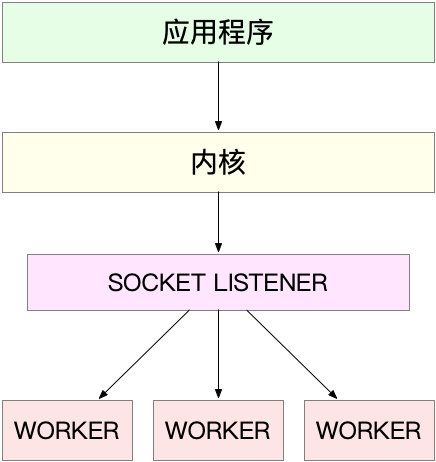
第二种,监听到相同端口的多进程模型。在这种方式下,所有的进程都监听相同的接口,并且开启 SO_REUSEPORT 选项,由内核负责将请求负载均衡到这些监听进程中去。这一过程如下图所示。
DNS 服务
DNS 服务通过资源记录的方式,来管理所有数据,它支持 A、CNAME、MX、NS、PTR 等多种类型的记录。比如:
- A 记录,用来把域名转换成 IP 地址;
- CNAME 记录,用来创建别名;
- 而 NS 记录,则表示该域名对应的域名服务器地址。
简单来说,当我们访问某个网址时,就需要通过 DNS 的 A 记录,查询该域名对应的 IP 地址,然后再通过该 IP 来访问 Web 服务。
如果没有命中缓存,DNS 查询实际上是一个递归过程,那有没有方法可以知道整个递归查询的执行呢?
其实除了 nslookup,另外一个常用的 DNS 解析工具 dig ,就提供了 trace 功能,可以展示递归查询的整个过程。
其他知识点:
tcpdump
tcpdump 和 Wireshark 就是最常用的网络抓包和分析工具,更是分析网络性能必不可少的利器。
- tcpdump 仅支持命令行格式使用,常用在服务器中抓取和分析网络包。
- Wireshark 除了可以抓包外,还提供了强大的图形界面和汇总分析工具,在分析复杂的网络情景时,尤为简单和实用。
可以用 tcpdump 抓包,查看 ping 在收发哪些网络包。
执行下面的命令:
$ tcpdump -nn udp port 53 or host 35.190.27.188
具体解释一下这条命令。
- -nn ,表示不解析抓包中的域名(即不反向解析)、协议以及端口号。
- udp port 53 ,表示只显示 UDP协议的端口号(包括源端口和目的端口)为53的包。
- host 35.190.27.188 ,表示只显示 IP 地址(包括源地址和目的地址)为35.190.27.188的包。
- 这两个过滤条件中间的“ or ”,表示或的关系,也就是说,只要满足上面两个条件中的任一个,就可以展示出来。
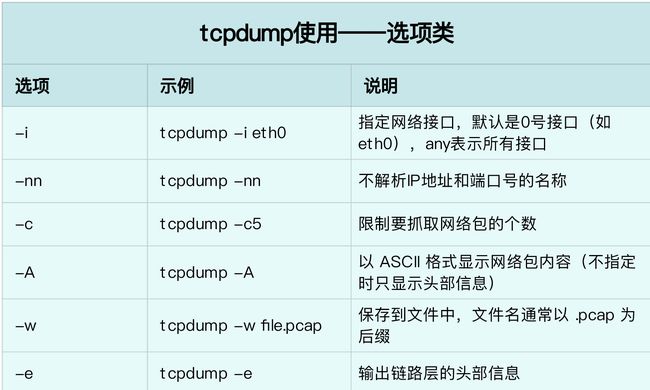
用过 -nn 选项,表示不用对 IP 地址和端口号进行名称解析。其他常用选项,用下面这张表格来解释。
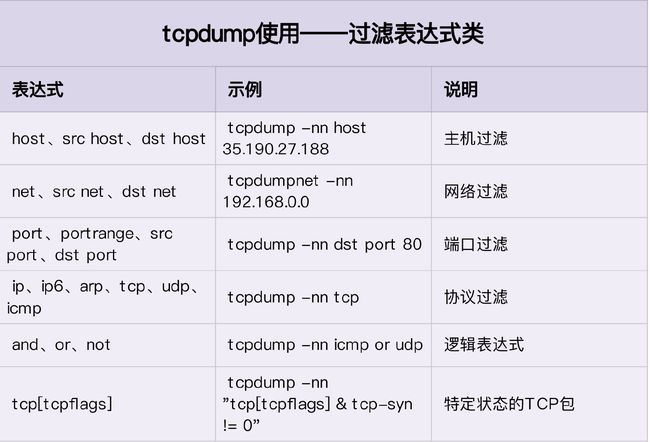
接下来,再来看常用的过滤表达式。例如 udp port 53 or host 35.190.27.188 ,表示抓取 DNS 协议的请求和响应包,以及源地址或目的地址为 35.190.27.188 的包。
其他常用的过滤选项,可参考下面这个表格。
最后,再次强调 tcpdump 的输出格式
时间戳 协议 源地址.源端口 > 目的地址.目的端口 网络包详细信息
其中,网络包的详细信息取决于协议,不同协议展示的格式也不同。所以,更详细的使用方法,还是需要去查询 tcpdump 的 man 手册(执行 man tcpdump 也可以得到)。
对比之下,Wireshark 则通过图形界面,以及一系列的汇总分析工具,提供了更友好的使用界面,让你可以用更快的速度,摆平网络性能问题。接下来,我们就详细来看看它。
Wireshark
Wireshark 也是最流行的一个网络分析工具,它最大的好处就是提供了跨平台的图形界面。跟 tcpdump 类似,Wireshark 也提供了强大的过滤规则表达式,同时,还内置了一系列的汇总分析工具。
比如,可以执行下面的命令,把抓取的网络包保存到 ping.pcap 文件中:
$ tcpdump -nn udp port 53 or host 35.190.27.188 -w ping.pcap
接着,把它拷贝到你安装有 Wireshark 的机器中,比如你可以用 scp 把它拷贝到本地来:
$ scp host-ip/path/ping.pcap .
然后,再用 Wireshark 打开它。打开后,你就可以看到下面这个界面:

从 Wireshark 的界面里,你可以发现,不仅以更规整的格式,展示了各个网络包的头部信息;还用了不同颜色,展示 DNS 和 ICMP 这两种不同的协议。你也可以一眼看出,中间的两条 PTR 查询并没有响应包。
接着,在网络包列表中选择某一个网络包后,在其下方的网络包详情中,你还可以看到,这个包在协议栈各层的详细信息。比如,以编号为 5 的 PTR 包为例:
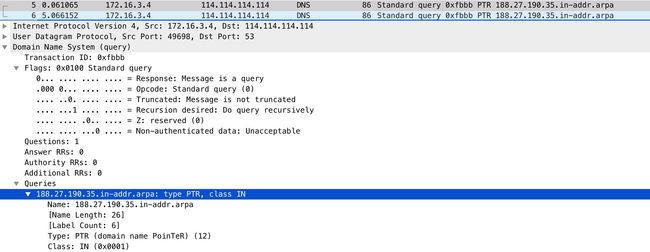
可以看到,IP 层(Internet Protocol)的源地址和目的地址、传输层的 UDP 协议(Uder Datagram Protocol)、应用层的 DNS 协议(Domain Name System)的概要信息。
继续点击每层左边的箭头,就可以看到该层协议头的所有信息。比如点击 DNS 后,就可以看到 Transaction ID、Flags、Queries 等 DNS 协议各个字段的数值以及含义。
当然,Wireshark 的功能远不止如此。
HTTP 例子
接下来理解 TCP 三次握手和四次挥手的工作原理。
TCP 三次握手和四次挥手很类似,作为对比, 你通常看到的 TCP 三次握手和四次挥手的流程,基本是这样的:
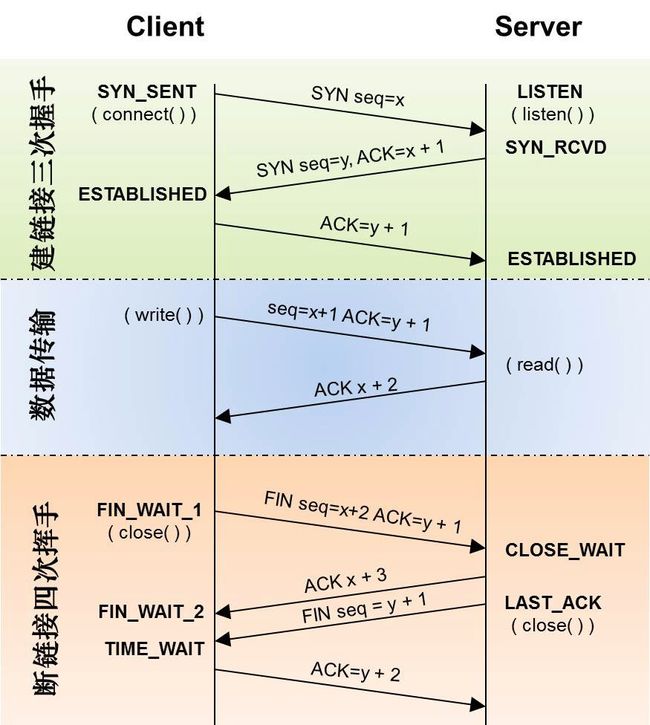
不过,抓包跟上面的四次挥手,并不完全一样,实际挥手过程只有三个包,而不是四个。
其实,之所以有三个包,是因为服务器端收到客户端的 FIN 后,服务器端同时也要关闭连接,这样就可以把 ACK 和 FIN 合并到一起发送,节省了一个包,变成了“三次挥手”。
而通常情况下,服务器端收到客户端的 FIN 后,很可能还没发送完数据,所以就会先回复客户端一个 ACK 包。稍等一会儿,完成所有数据包的发送后,才会发送 FIN 包。这也就是四次挥手了。
当然,Wireshark 的使用方法绝不只有这些,更多的使用方法,同样可以参考 官方文档 以及 WIKI。
网络性能优化
传输层
TCP 协议的优化
TCP 提供了面向连接的可靠传输服务。要优化 TCP,我们首先要掌握 TCP 协议的基本原 理,比如流量控制、慢启动、拥塞避免、延迟确认以及状态流图等。
第一类,在请求数比较大的场景下,你可能会看到大量处于 TIME_WAIT 状态的连接,它 们会占用大量内存和端口资源。这时,我们可以优化与 TIME_WAIT 状态相关的内核选 项,比如采取下面几种措施。
- 增大处于 TIME_WAIT 状态的连接数量 net.ipv4.tcp_max_tw_buckets ,并增大连接跟踪表的大小 net.netfilter.nf_conntrack_max。
- 减小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,让系统尽快释放它们所占用的资源。
- 开启端口复用 net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中。
- 增大本地端口的范围 net.ipv4.ip_local_port_range 。这样就可以支持更多连接,提高 整体的并发能力。
- 增加最大文件描述符的数量。你可以使用 fs.nr_open ,设置系统的最大文件描述符数; 或在应用程序的 systemd 配置文件中,配置 LimitNOFILE ,设置应用程序的最大文件 描述符数。
第二类,为了缓解 SYN FLOOD 等,利用 TCP 协议特点进行攻击而引发的性能问题,你可以考虑优化与 SYN 状态相关的内核选项,比如采取下面几种措施。
- 增大 TCP 半连接的最大数量 net.ipv4.tcp_max_syn_backlog ,或者开启 TCP SYN Cookies net.ipv4.tcp_syncookies ,来绕开半连接数量限制的问题(注意,这两个选 项不可同时使用)。
- 减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数 net.ipv4.tcp_synack_retries。
第三类,在长连接的场景中,通常使用 Keepalive 来检测 TCP 连接的状态,以便对端连接断开后,可以自动回收。但是,系统默认的 Keepalive 探测间隔和重试次数,一般都无法满足应用程序的性能要求。所以,这时候你需要优化与 Keepalive 相关的内核选项,比 如:
- 缩短最后一次数据包到 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_time; 缩短发送 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_intvl;
- 减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数 net.ipv4.tcp_keepalive_probes。 讲了这么多 TCP 优化方法。
UDP协议 的优化。
UDP 提供了面向数据报的网络协议,它不需要网络连接,也不提供可靠性保障。所以, UDP 优化,相对于 TCP 来说,要简单得多。这里我也总结了常见的几种优化方案。
增大套接字缓冲区大小以及 UDP 缓冲区范围。
根据 MTU 大小,调整 UDP 数据包的大小,减少或者避免分片的发生。
网络层
接下来,我们再来看网络层的优化。
网络层,负责网络包的封装、寻址和路由,包括 IP、ICMP 等常见协议。在网络层,最主要的优化,其实就是对路由、 IP 分片以及 ICMP 等进行调优。
第一种,从路由和转发的角度出发,你可以调整下面的内核选项。
- 在需要转发的服务器中,比如用作 NAT 网关的服务器或者使用 Docker 容器时,开启 IP 转发,即设置 net.ipv4.ip_forward = 1。
- 调整数据包的生存周期 TTL,比如设置 net.ipv4.ip_default_ttl = 64。注意,增大该值会降低系统性能。
- 开启数据包的反向地址校验,比如设置 net.ipv4.conf.eth0.rp_filter = 1。这样可以防止 IP 欺骗,并减少伪造 IP 带来的 DDoS 问题。
第二种,从分片的角度出发,最主要的是调整 MTU(Maximum Transmission Unit)的 大小。
第三种,从 ICMP 的角度出发,为了避免 ICMP 主机探测、ICMP Flood 等各种网络问 题,你可以通过内核选项,来限制 ICMP 的行为。
- 可以禁止 ICMP 协议,即设置 net.ipv4.icmp_echo_ignore_all = 1。这样, 外部主机就无法通过 ICMP 来探测主机。
- 可以禁止广播 ICMP,即设置 net.ipv4.icmp_echo_ignore_broadcasts = 1。
链路层
链路层负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网 络帧等。自然,链路层的优化,也是围绕这些基本功能进行的。接下来,我们从不同的几 个方面分别来看。
将 这些中断处理程序调度到不同的 CPU 上执行,就可以显著提高网络吞吐量。
比如,你可以为网卡硬中断配置 CPU 亲和性(smp_affinity),或者开启 irqbalance 服务。
再如,你可以开启 RPS(Receive Packet Steering)和 RFS(Receive Flow Steering),将应用程序和软中断的处理,调度到相同 CPU 上,这样就可以增加 CPU 缓存命中率,减少网络延迟。
另外,现在的网卡都有很丰富的功能,原来在内核中通过软件处理的功能,可以卸载到网卡中,通过硬件来执行。