Spark自学之路(一)——Spark简介
Spark
Spark简介
- 最初由美国加州伯克利大学的AMP实验室于2009年开发,是基于内存计算的大数据计算框架,可用于构建大型,低延迟的数据分析应用程序
- 2014年打破了hadoop保持的基准排序记录
Spark具有以下特点:
- 运行速度快:使用DAG执行引擎以支持循环数据流与内存计算
- 容易使用:支持使用scala,java,python和R语言进行编程,可以通过spark shell进行交互式编程
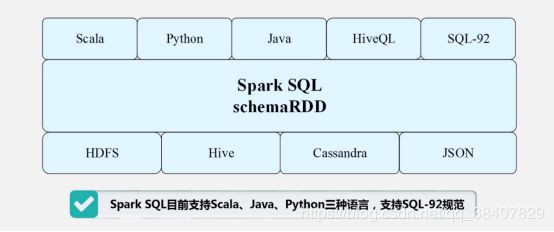
- 通用性:Spark提供了完整而强大的技术栈,包括sql查询,流式计算、机器学习和图算法组件
- 运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可以运行于Amazon EC2等云环境中,并且可以访问HDFS.cassandra、hbase、hive等多种数据源
Scala简介
Scala是一门现代的多范式编程语言,运行于java平台,并兼容现有的java程序
Scala的特性:
- 具有强大的并发性,支持函数编程,可以更好地支持分布式系统
- 语法简介,能提供优雅的API
Spark与Hadoop的对比
Hadoop存在以下一些缺点:
- 表达能力有限
- 磁盘io开销大
- 延迟高
- 任务之间的衔接涉及到io开销
- 在一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务
Spark主要具有以下优点:
- Spark的计算模式也属于mapreduce,但不局限与map和reduce操作,还提供了多种数据集操作类型,编程模式比Hadoop mapreduce更灵活
- 提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
- 将计算数据、中间结果都存储在内存中,大大减少了IO开销(适合迭代次数比较多的数据挖掘和机器学习算法)
| MapReduce |
Spark |
| 数据存储结构:磁盘HDFS文件 系统的split |
使用内存构建弹性分布式数据集RDD 虽数据进行运算和cache |
| 编程范式:map + reduce |
DAG:Transformation +action |
| 计算中间结果落在磁盘,io及序列化、反序列化代价大 |
计算中间结果在内存中维护 存取速度比磁盘高几个数量级 |
| Task以进程的方式维护,需要数秒时间才能启动热内 |
Task以线程的方式维护 对于小数据集读取能够到达亚秒级的延迟 |

Spark生态系统
大数据处理主要包括一下三个类型:
- 复杂的批量数据处理:通常时间跨度在树十分钟到数小时之间
- 基于历史数据的交互式查询:数十秒到数分钟之间
- 基于实时数据流的数据处理:数百毫秒到数秒之间,
当同时存在以上三种场景时,就需要同时部署三种不同软件
比如:mapreduce/impala/storm
这样做难免会带来一些问题:
- Spark的设计遵循“一个软件栈满足不同的应用场景”的理念
- 既能提供内存计算框架,也可以支持sql及时查询、实时流式计算,机器学习和图计算等
- 同时支持批处理、交互式查询和流数据处理

| 应用场景 |
时间跨度 |
其他框架 |
Spark生态系统中的组件 |
| 复杂的批量数据处理 |
小时级 |
Mapreduce hive |
Spark |
| 基于历史数据的交互式查询 |
分钟级,秒级 |
Impala Dremel、drill |
Spark SQL |
| 基于实时数据流的数据处理 |
毫秒,秒级 |
Storm,s4 |
Spark streaming |
| 基于历史数据的数据挖掘 |
|
Mahout |
MLlib
|
| 图结构数据的处理 |
|
Pregel,hama |
GraphX |
Spark 运行框架
基本概念
- RDD:是(Resillient Distributed Dataset)弹性分布式数据集的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模式。
- DAG:是Directed Acyclis Graph(有向无环图)的简称,反应RDD之间的依赖关系
- Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行Task
- Application:用户编写的Spark应用程序
- Task:运行在Executor上的工作单元
- Job:一个job包含多个RDD及作用于相应RDD上的各种操作
- Stage:是Job的基本调度单位,一个job会分为多组task,每组task被称为stage,或者taskstage,代表一组关联的、相互之间没有shuffle依赖关系的任务组成的任务集
架构设计
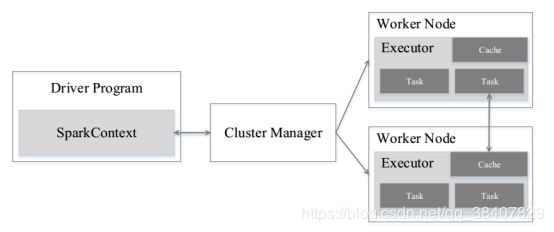
集群资源管理器可以是Spark自带的资源管理器,也可以是yarn或mesos等资源管理器。
与Hadoop Mapreduce计算框架相比,Spark的Executor有两个优点:
- 利用多线程执行具体的任务(H m采用进程模式),减少任务的启动开销
- Executor中有一个BlockManager存储模块(类似KV系统),会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到hdfs等文件系统,因此有效减少io开销;或者在交互式查询,预先将表缓存到该存储系统上,从而可以提高读写io性能
在 Spark 中,一个 Application 由一个 Driver 和若干个 Job 构成,一个 Job 由多个 Stage 构成,一个 Stage 由多个没有 Shuffle 关系的 Task 组成。当执 行一个 Application 时,Driver 会向集群管理器申请资源,启动 Executor,并向 Executor 发送 应用程序代码和文件,然后在 Executor 上执行 Task,运行结束后,执行结果会返回给 Driver, 或者写到 HDFS 或者其他数据库中。
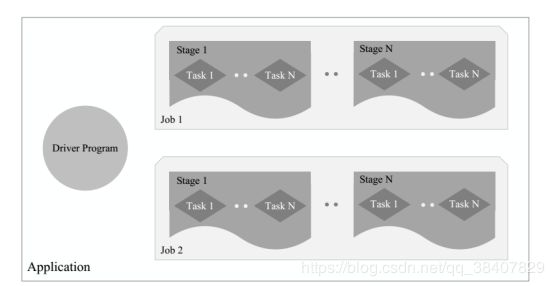
Spark运行基本流程

- 当一个Spark Application 被提交时,首先需要为这个应用构建起基本的运行环境,即由Driver创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向在资源管理器注册并申请运行Executor的资源
- 资源管理器为Executor分配资源,并启动Executor 进程,Executor运行情况将随着心跳发送到资源管理器上。
- Sparkcontext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler进行解析,将DAG图分解成Stage,并且计算出各个stage之间的依赖关系,然后把一个个taskset提交给底层调度器taskScheduleer进行处理;Executor向sparkcontext申请task,taskScheduler将task发放给executor进行,同时。Sparkcontext将应用程序代码发放给executor
- Task在Executor上运行,把执行结果反馈给taskexecutor。然后反馈给DAGScheduler,运行完毕后写入数据并释放资源
(1)每个 Application 都有自己专属的 Executor 进程,并且该进程在 Application 运行期 间一直驻留。Executor 进程以多线程的方式运行 Task; (2)Spark 运行过程与资源管理器无关,只要能够获取 Executor 进程并保持通信即可; (3)Task 采用了数据本地性和推测执行等优化机制。数据本地性是尽量将计算移到数据存储的地方
RDD的设计与运行原理
设计背景
存在许多迭代算法和交互式数据挖掘工具,不同计算阶段之间会重用中间结果。MapReduce把中间结果写入到HDFS中,带来了大量的数据复制,磁盘io和序列化开销。
不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中甲数据存储
RDD的概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存在的集群中不同节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD执行确定的转换操作(map,join和group by)而创建得到新的RDD。
.
RDD执行过程
- RDD读入外部数据源进行创建
- RDD经过一系列的转换(transformation)操作每一次都会产生不同的RDD供下一个转换操作使用。
- 最后一个RDD经过“动作”(Action)操作进行计算并输出到外部数据源。

转换操作,并不会发生真正的计算,只是记录转换的轨迹
动作操作,才会触发从头到尾的真正的计算,并得到结果。
血缘关系,DAG拓扑排序结果
优点:惰性调用、管道化,避免同步等待、不需要保存中间结果,每次操作变得简单
RDD特性
- 高效的容错性:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只记录粗粒度的操作。
- 中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免了不必要大的读写磁盘开销。
- 存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化。
RDD的依赖关系
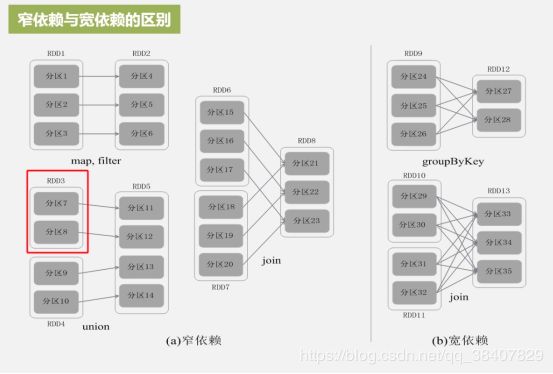
RDD之间的依赖关系(宽依赖、窄依赖)是划分stage的依据
窄依赖:一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区
宽依赖:一个父RDD的一个分区对应于一个子RDD的多个分区
Stage的划分
- 在DAG中进行反向解析,遇到宽依赖就断开
- 遇到窄依赖就把当前的RDD加入到stage中
- 将窄依赖尽量划分到同一个stage中,可以实现流水线计算从而使得数据可以在内存中进行交换,避免了磁盘开销

ShuffleMapStage
- 不是最终的stage,在他之后还有其他stage,所以,他的输出一定需要经历过Shuffle过程,并作为后续stage的输入
- 这种stage是以shuffle为输出边界其输出边界可以是从外部获取数据,也可以是另一种shufflemapstage的输出,其输出可以是另一个stage的开始
- 在一个job里面可能有该类型的stage,也可能没有该类型的stage
ResultStage
- 最终的stage,没有输出,而是直接产生结果后存储
- 这种stage是直接输出结果,其输入边界可以是从外部获取数据,也可以是另一个shufflemapStage
- 在一个job中必定有该类型stage
- 因此,一个job含有一个或多个stage,其中至少包含有一个resultStage
RDD运行过程
- 创建RDD对象
- SparkContext负责计算RDD之间的依赖关系,构建DAG
- DAGScheduler负责把DAG图分解成多个stage,每个stage中包含了多个task,每个task会被taskScheduler分发给各个WorkerNode上的Executor去执行
Spark SQL
Shark hive on Spark
为了实现与HIVE的兼容,Shark在hiveql方面重用了hive中hiveql的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MapReduce作业替换成了spark作业,通过hive的hiveql解析,把hi veql翻译成spark上的RDD操作
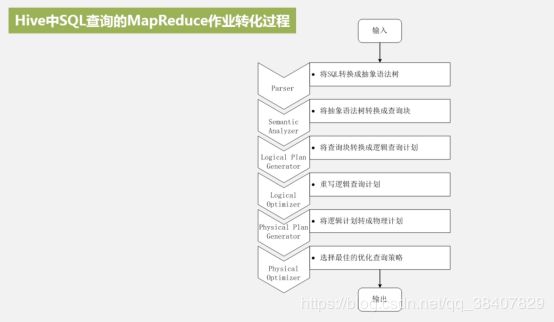
问题:
- 执行计划完全依赖于Hive,不方便添加新的优化策略
- 因为Spark是线程级并行,而MapReduce是进程吉并行,因此Spark在兼容Hive的实现上存在线程安全问题,导致shark不得不使用另一套独立维护的打了补丁的hive源码分支。
Saprk SQL

SparkSQl在hive兼容层面仅依赖HiveSQL解析、hive元数据,也就是说,从HQL被解析成抽象语法树起,就全部由SparkSQL接管。SparkSQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。