Mybatis源码解析之执行流程解析
Mybatis源码解析之核心类分析
Mybatis源码解析之初始化分析
本篇文章将在前两篇文章的基础上解析Mybatis执行sql的流程。
一、 映射集mappers解析
对于在原生mybatis中的sql执行,需要在配置文件中通过标签引入mapper.xml文件。前文已经提到,对于xml配置文件,mybatis在XMLConfigBuilder#parseConfiguration(Xnode)方法中进行解析,对于mappers节点的解析在mapperElement(root.evalNode("mappers"));进行处理。
1. XMLConfigBuilder#mapperElement(XNode)
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
可以看到,mybatis可以通过package属性批量引入,也可以通过url或resource或mapperClass来单个引入。虽然引入的方式不同,但实现方式大同小异,都是将文件处理成输入流后通过XMLMapperBuilder的parse方法进行解析。
2. XMLMapperBuilder#parse()
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
//从根节点mapper开始解析节点
configurationElement(parser.evalNode("/mapper"));
//标记该文件以及解析完成
configuration.addLoadedResource(resource);
//namespace处理
bindMapperForNamespace();
}
//处理抛出IncompleteElementException对应的节点
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
3. XMLMapperBuilder#bindMapperForNamespace()
private void bindMapperForNamespace() {
String namespace = builderAssistant.getCurrentNamespace();
if (namespace != null) {
Class boundType = null;
try {
boundType = Resources.classForName(namespace);
} catch (ClassNotFoundException e) {
//ignore, bound type is not required
}
if (boundType != null) {
if (!configuration.hasMapper(boundType)) {
// Spring may not know the real resource name so we set a flag
// to prevent loading again this resource from the mapper interface
// look at MapperAnnotationBuilder#loadXmlResource
configuration.addLoadedResource("namespace:" + namespace);
configuration.addMapper(boundType);
}
}
}
}
绑定xml对应的mapper接口类,并加入到mapperRegistry属性中。
3. XMLMappedBuilder#configurationElement(XNode)
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e);
}
}
分别对mapper底下的节点进行解析。
cache – 给定命名空间的缓存配置。
cache-ref – 其他命名空间缓存配置的引用。
resultMap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
parameterMap – 已废弃!老式风格的参数映射。内联参数是首选,这个元素可能在将来被移除,这里不会记录。
sql – 可被其他语句引用的可重用语句块。
insert – 映射插入语句
update – 映射更新语句
delete – 映射删除语句
select – 映射查询语句
以cache-ref节点为例,在处理过程中有可能会由于引用的cache还没有处理等问题抛出IncompleteElementException,此时会将该节点加入incompleteCacheRefs列表中。而该列表中的节点在parsePendingCacheRefs();进行处理。其它的resultMap和select|insert|update|delete节点也类似。
private void cacheRefElement(XNode context) {
if (context != null) {
configuration.addCacheRef(builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
CacheRefResolver cacheRefResolver = new CacheRefResolver(builderAssistant, context.getStringAttribute("namespace"));
try {
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException e) {
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}
二、statement节点解析
重点针对statement节点(即select|insert|update|delete节点)的解析逻辑进行解析。从上一章的代码进行追踪,我们发现主要的解析代码在XMLStatementBuilder的parseStatementNode方法中。
1. XMLStatementBuilder#parseStatementNode()
public void parseStatementNode() {
//节点的属性
String id = context.getStringAttribute("id");
String databaseId = context.getStringAttribute("databaseId");
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
return;
}
Integer fetchSize = context.getIntAttribute("fetchSize");
Integer timeout = context.getIntAttribute("timeout");
String parameterMap = context.getStringAttribute("parameterMap");
String parameterType = context.getStringAttribute("parameterType");
Class parameterTypeClass = resolveClass(parameterType);
String resultMap = context.getStringAttribute("resultMap");
String resultType = context.getStringAttribute("resultType");
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
Class resultTypeClass = resolveClass(resultType);
String resultSetType = context.getStringAttribute("resultSetType");
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
String nodeName = context.getNode().getNodeName();
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// Include Fragments before parsing
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
// Parse selectKey after includes and remove them.
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// Parse the SQL (pre: and were parsed and removed)
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
String resultSets = context.getStringAttribute("resultSets");
String keyProperty = context.getStringAttribute("keyProperty");
String keyColumn = context.getStringAttribute("keyColumn");
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
insert节点的属性:
属性 描述
id 在命名空间中唯一的标识符,可以被用来引用这条语句。
parameterType 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过 TypeHandler 推断出具体传入语句的参数,默认值为 unset。
parameterMap 这是引用外部 parameterMap 的已经被废弃的方法。使用内联参数映射和 parameterType 属性。
resultType 从这条语句中返回的期望类型的类的完全限定名或别名。注意如果是集合情形,那应该是集合可以包含的类型,而不能是集合本身。使用 resultType 或 resultMap,但不能同时使用。
resultMap 外部 resultMap 的命名引用。结果集的映射是 MyBatis 最强大的特性,对其有一个很好的理解的话,许多复杂映射的情形都能迎刃而解。使用 resultMap 或 resultType,但不能同时使用。
flushCache 将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:false。
useCache 将其设置为 true,将会导致本条语句的结果被二级缓存,默认值:对 select 元素为 true。
timeout 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)。
fetchSize 这是尝试影响驱动程序每次批量返回的结果行数和这个设置值相等。默认值为 unset(依赖驱动)。
statementType STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。
resultSetType FORWARD_ONLY,SCROLL_SENSITIVE 或 SCROLL_INSENSITIVE 中的一个,默认值为 unset (依赖驱动)。
databaseId 如果配置了 databaseIdProvider,MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。
resultOrdered 这个设置仅针对嵌套结果 select 语句适用:如果为 true,就是假设包含了嵌套结果集或是分组了,这样的话当返回一个主结果行的时候,就不会发生有对前面结果集的引用的情况。这就使得在获取嵌套的结果集的时候不至于导致内存不够用。默认值:false。
resultSets 这个设置仅对多结果集的情况适用,它将列出语句执行后返回的结果集并每个结果集给一个名称,名称是逗号分隔的。
update|delete|insert节点属性:
属性 描述
id 命名空间中的唯一标识符,可被用来代表这条语句。
parameterType 将要传入语句的参数的完全限定类名或别名。这个属性是可选的,因为 MyBatis 可以通过 TypeHandler 推断出具体传入语句的参数,默认值为 unset。
parameterMap 这是引用外部 parameterMap 的已经被废弃的方法。使用内联参数映射和 parameterType 属性。
flushCache 将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:true(对应插入、更新和删除语句)。
timeout 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)。
statementType STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。
useGeneratedKeys (仅对 insert 和 update 有用)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系数据库管理系统的自动递增字段),默认值:false。
keyProperty (仅对 insert 和 update 有用)唯一标记一个属性,MyBatis 会通过 getGeneratedKeys 的返回值或者通过 insert 语句的 selectKey 子元素设置它的键值,默认:unset。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。
keyColumn (仅对 insert 和 update 有用)通过生成的键值设置表中的列名,这个设置仅在某些数据库(像 PostgreSQL)是必须的,当主键列不是表中的第一列的时候需要设置。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。
databaseId 如果配置了 databaseIdProvider,MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。
2. MapperBuilderAssistant#addMappedStatement(String, SqlSource, StatementType, SqlCommandType, Integer, Integer, String, Class, String, Class, ResultSetType, boolean, boolean, boolean, KeyGenerator, String, String, String, LanguageDriver, String)
public MappedStatement addMappedStatement(
String id,
SqlSource sqlSource,
StatementType statementType,
SqlCommandType sqlCommandType,
Integer fetchSize,
Integer timeout,
String parameterMap,
Class parameterType,
String resultMap,
Class resultType,
ResultSetType resultSetType,
boolean flushCache,
boolean useCache,
boolean resultOrdered,
KeyGenerator keyGenerator,
String keyProperty,
String keyColumn,
String databaseId,
LanguageDriver lang,
String resultSets) {
if (unresolvedCacheRef) {
throw new IncompleteElementException("Cache-ref not yet resolved");
}
id = applyCurrentNamespace(id, false);
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
.resource(resource)
.fetchSize(fetchSize)
.timeout(timeout)
.statementType(statementType)
.keyGenerator(keyGenerator)
.keyProperty(keyProperty)
.keyColumn(keyColumn)
.databaseId(databaseId)
.lang(lang)
.resultOrdered(resultOrdered)
.resultSets(resultSets)
.resultMaps(getStatementResultMaps(resultMap, resultType, id))
.resultSetType(resultSetType)
.flushCacheRequired(valueOrDefault(flushCache, !isSelect))
.useCache(valueOrDefault(useCache, isSelect))
.cache(currentCache);
ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id);
if (statementParameterMap != null) {
statementBuilder.parameterMap(statementParameterMap);
}
MappedStatement statement = statementBuilder.build();
configuration.addMappedStatement(statement);
return statement;
}
三、SqlSession执行过程
InputStream inputStream = Resources.getResourceAsStream("mybatis-coonfig.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
//sqlSession.update(String statement, Object parameter);
在上一篇博客的demo基础上通过sqlSession.update对数据库进行操作,我们以update方法为例进行分析。
1. 时序图
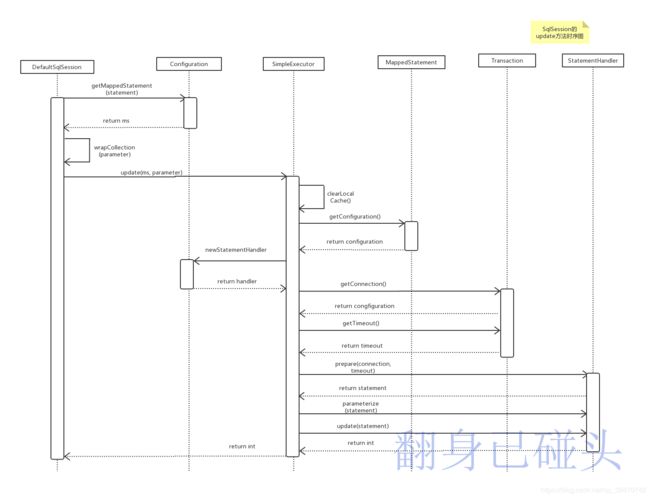
1. DefaultSqlSession#update(String, Object)
public int update(String statement, Object parameter) {
try {
dirty = true;
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
主要功能是从configuration根据statement id获取对应的mappedStatement,这一点和上面对mapper.xml解析并作为configuration的属性相吻合。
2. BaseExecutor#update(MappedStatement, Object)
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
清理本地缓存,缓存的具体处理后续专门分析。
具体逻辑交给子类的doUpdate去继承重写。
3. SimpleExecutor#doUpdate(MappedStatement, Object)
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
获取处理器StatementHandler,然后组装statement属性,以交给StatementHandler处理。
4. Configuration#newStatement(Executor, MappedStatement, Object, RowBounds, ResultHandler, BoundSql)
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
该方法返回的StatementHandler类型是RoutingStatementHandler,RoutingStatementHandler使用了委派模式,根据statementType类型的不同委派给不同的StatementHandler去处理。statementHandler对应mapper.xml中的select|update|insert|delete中的statementType属性,默认为PREPARED。
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
另外,需要注意,configuration提供了拦截器进行扩展,因此生成的RoutingStatementHandler对象还需要交给拦截器链进行扩展,最后再返回。
5. StatementHandler#update(Statement statement)
该方法根据StatementHandler类型的不同通过不同的statement去执行sql,从而实现从mybatis到jdbc。
//CallableStatementHandler
@Override
public int update(Statement statement) throws SQLException {
CallableStatement cs = (CallableStatement) statement;
cs.execute();
int rows = cs.getUpdateCount();
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
keyGenerator.processAfter(executor, mappedStatement, cs, parameterObject);
resultSetHandler.handleOutputParameters(cs);
return rows;
}
//PreparedStatementHandler
@Override
public int update(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
int rows = ps.getUpdateCount();
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
keyGenerator.processAfter(executor, mappedStatement, ps, parameterObject);
return rows;
}
//SimpleStatementHandler
@Override
public int update(Statement statement) throws SQLException {
String sql = boundSql.getSql();
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
int rows;
if (keyGenerator instanceof Jdbc3KeyGenerator) {
statement.execute(sql, Statement.RETURN_GENERATED_KEYS);
rows = statement.getUpdateCount();
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else if (keyGenerator instanceof SelectKeyGenerator) {
statement.execute(sql);
rows = statement.getUpdateCount();
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else {
statement.execute(sql);
rows = statement.getUpdateCount();
}
return rows;
}
keyGenerator是mybatis的主键生成策略接口,以兼容不同数据库的不同主键生成策略。
6. select方法解析
上述内容全部以update为例进行解析,select方法的大致流程类似,不过为了支持mybatis的缓存机制增加了不少的缓存处理逻辑,缓存处理的源码后续专门分析。
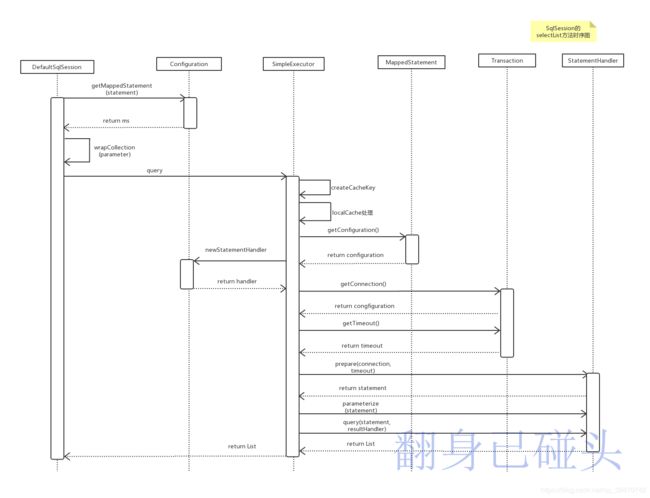
下面是DefaultSqlSession#selectList的时序图,可以看出与update方法基本一致。