Hive窗口函数
原文地址:https://acadgild.com/blog/windowing-functions-in-hive(2017-03-08)

窗口函数使你能够在一个数据集上创建一个窗口,并允许你在这个数据上使用聚合函数。Hive从0.11版本开始引入窗口函数。本篇博客会给出Hive上可以使用的窗口函数的使用样例。
Hive窗口函数包含以下函数
-
Lead
-
lead的行数是可以指定的,是可选项。如果lead的行数没有指定,默认值是一行。
-
如果当前行超出了窗口的结尾则返回null
-
-
Lag
-
lag的行数是可以指定的,是可选项。如果lead的行数没有指定,默认值是一行。
-
如果当前行超出了窗口的开头则返回null
-
-
FIRST_VALUE
-
LAST_VALUE
OVER语句
- 与OVER一起使用的标准聚合函数:
- COUNT
- SUM
- MIN
- MAX
- AVG
带PARTITION BY一个或多个列的OVER语句
- 带PARTITION BY和ORDER BY一个或多个列的OVER语句
分析函数
- RANK
- ROW_NUMBER
- DENSE_RANK
- CUME_DIST
- PERCENT_RANK
- NTILE
为了展示这些Hive窗口函数如何使用,我们会使用股票市场数据来演示。你可以从这里下载这些股票样本数据,加载到你的股票表中。
现在我们会创建一张表来加载股票市场数据,如下:
create table stocks (
date_ String
, Ticker String
, Open Double
, High Double
, Low Double
, Close Double
, Volume_for_the_day int
) row format delimited fields terminated by ',';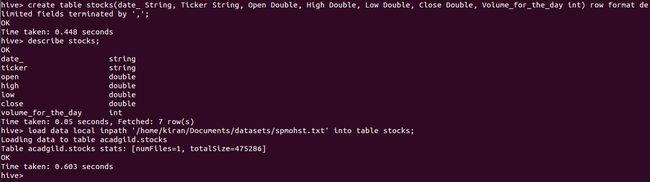
现在让我们深入了解下Hive窗口函数
Lag
此函数返回上一行中的值。你可以指定一个integer的偏移量来表示行的位置,如果不指定的话则使用默认偏移量1
下面是lag的一个例子
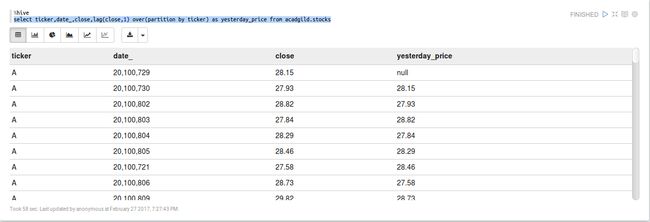
select ticker
,date_
,close
,lag(close,1) over(partition by ticker) as yesterday_price
from acadgild.stocks这里我们使用lag来显示特定ticker上一日的闭市价格close。lag加over函数一起使用,over函数中你可以使用partition或者order进行分类。
在下面的截屏中,你可以看到当日的闭市价格close,以及上一日的闭市价格yesterday_price
Lead
此函数返回下一行中的值。你可以指定一个integer的偏移量来表示行的位置,如果不指定的话则使用默认偏移量1
下面是lead的一个例子
现在我们使用lead函数,我们会找出下一日的闭市价格是高于还是低于当日的闭市价格,我们按照如下语句完成
select ticker
,date_
,close
,case (lead(close,1) over(partition by ticker)-close)>0
when true then "higher"
when false then "lesser"
end as Changes
from acadgild.stocks在下面的截图中,你可以看到结果

FIRST_VALUE
此函数返回本窗口中的第一行的值。按照如下的查询,你可以在所有行中看到ticker第一行的最高价格high。
select ticker
,first_value(high) over(partition by ticker) as first_high
from acadgild.stocks
LAST_VALUE
此函数与FIRST_VALUE相反,返回本窗口中最后一行的值。按照如下的查询,你可以在所有行看到ticker最后一行的最高价格high。
select ticker
,last_value(high) over(partition by ticker) as first_high
from acadgild.stocks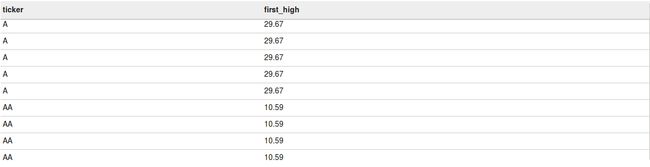
下面让我们来看下如何配合over使用聚合函数
Count
此函数返回over语句的表达式所表示的所有值的个数。从如下的查询,我们可以找出出现在每个ticker的行数。
select ticker
,count(ticker) over(partition by ticker) as cnt
from acadgild.stockscount在每个分区ticker计算一次,你可以在如下截屏看到相同的结果

Sum
此函数返回over语句的表达式所表示的所有值的和。从如下的查询,我们可以找出特定ticker所有闭市价格的和。
select ticker
,sum(close) over(partition by ticker) as total
from acadgild.stocks对于每个ticker,计算所有闭市价格的和,你可以在如下截屏看到相同的结果

找出累积总量
让我们假设,如果你想得到每个ticker下volume_for_the_day所有日期的累积总量,那你可以像下面这样查询
select ticker
,date_
,volume_for_the_day
,sum(volume_for_the_day) over(partition by ticker order by date_) as running_total
from acadgild.stocks
在上面的截屏中,你可以看到每天volume_for_the_day的值,以及过往日期的volume_for_the_day的总和
找出每行的值所占总和的比例
现在我们来看一个场景,你需要找出特定ticker的volume_for_the_day在总的交易量中的占比,我们可以按照如下来实现
select ticker
,date_
,volume_for_the_day
,(volume_for_the_day*100/(sum(volume_for_the_day) over(partition by ticker)))
from acadgild.stocks
在上面的截屏中,你可以看到每日交易量的贡献占比基于该ticker的总交易量。
Min
此函数返回over语句的表达式所表示的所有值的最小值。从如下的查询中,我们可以找出每个特定ticker的最小闭市价格。
select ticker
, min(close) over(partition by ticker) as minimum
from acadgild.stocks
Max
此函数返回over语句的表达式所表示的所有值的最大值。从如下的查询中,我们可以找出每个特定ticker的最大闭市价格。
select ticker
, max(close) over(partition by ticker) as maximum
from acadgild.stocks
AVG
此函数返回over语句的表达式所表示的所有值的均值。从如下的查询中,我们可以找出每个特定ticker的闭市价格均值。
select ticker
, avg(close) over(partition by ticker) as maximum
from acadgild.stocks
现在让我们来看一些分析函数。
Rank
rank函数返回每个over语句结果集的值的等级。如果两个值相同,那这两个值的等级相同,并且下一个值,也就是后续的等级会跳过。
下面的查询会把每个ticker按照闭市价格划分等级,就像下面的截屏所看到的一样。
select ticker
,close
,rank() over(partition by ticker order by close) as closing
from acadgild.stocks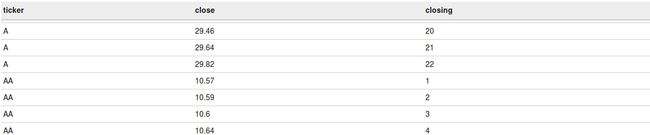
Row_number
row_number会返回over语句结果集所有行的连续行号。
从如下的查询,你可以得到ticker,close(闭市价格),基于每个ticker的行号。
select ticker
,close
,row_number() over(partition by ticker order by close) as num
from acadgild.stocks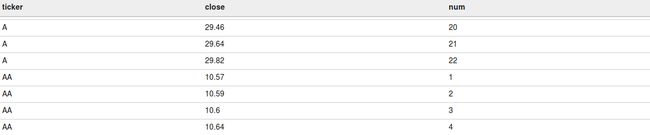
Dense_rank
此函数与rank()函数相同,但不同的是,如果有相同的值,那么后续行的等级不会跳过。每一个唯一的值都会得到连续等级中的一个等级。
下面的查询会把每个ticker按照闭市价格划分等级,就像下面的截屏所看到的一样。
select ticker
,close
,dense_rank() over(partition by ticker order by close) as closing
from acadgild.stocks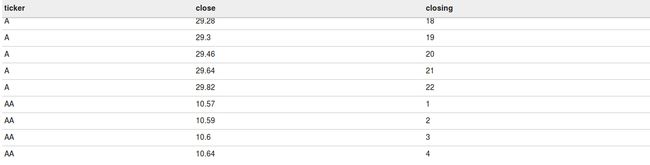
Cume_dist
此函数返回一个值的累积分布。结果区间从0到1。假设总的记录数是10,那么第一行的cume_dist就是1/10,第二行就是2/10,等等,直到10/10。
cume_dist会根据over语句结果集来计算。下面的查询会返回每个ticker下每条记录的累积比例。
select ticker
,cume_dist() over(partition by ticker order by close) as cummulative
from acadgild.stocks
Percent_rank
此函数返回每行在over语句结果集中的占比等级。percent_rank根据每行的等级来计算,公式为(rank-1)/(group内总行数 – 1)。如果over语句结果集只有一条记录,那percent_rank值为0。
下面的查询会计算每个partition下每行的percent_rank值,你可以从如下的截屏中看到一样的结果。
select ticker
,close
,percent_rank() over(partition by ticker order by close) as closing
from acadgild.stocks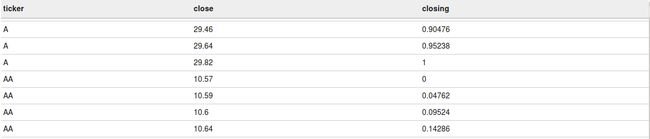
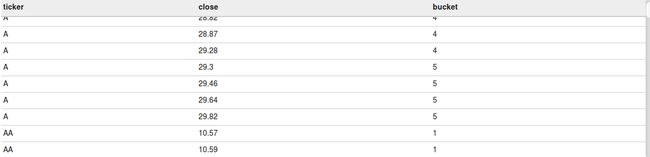
Ntile
此函数返回每个特定值分桶(bucket)的桶号。假设我们计算ntile(5),那么会基于over语句结果集创建5个桶,然后会把20%的记录放到第一个桶中,如此下去,直到第五个桶。
下面的查询为每个ticker创建了5个桶,每个ticker第一个20%的记录都在第一个桶中,如此继续分桶。
select ticker
,ntile(5) over(partition by ticker order by close ) as bucket
from acadgild.stocks在下面的截屏中,你可以看到每个ticker都会创建5个桶,最小的20%闭市价格的记录在第一个桶,下一个20%在第二个桶,如此下去,直到第五个桶。
这就是我们如何在Hive中使用窗口操作。
我们希望这篇博客能够帮助你了解窗口函数是什么,如何在Hive中实现他们。如需更多大数据及其他技术更新,请访问我们的网站www.acadgild.com。