MyBatis源码一基础层:解析器模块
1.概述
解析器模块是 MyBatis 基础支持层的功能, 如图1所示,基础支持层位于MyBatis 整体架构的最底层,支撑着 MyBatis 的核心处理层,是整个框架的基石。基础支持层中封装了多个较为通用的、独立的模块,不仅仅为 MyBatis 提供基础支撑 ,也可以在合适的场景中直接复用 ,如反射模块。
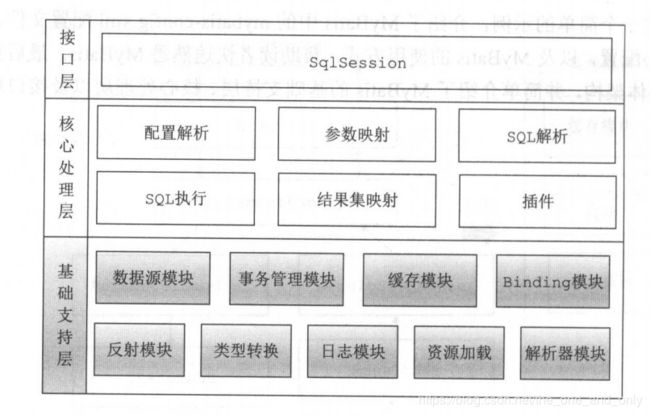
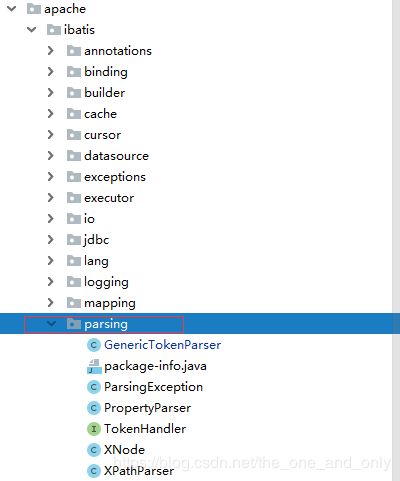
在MyBaits里,解析器模块主要是封装了对xml文件的解析和提取方法,核心类在XPathParser相关的方法实现,XPathParser是对Xpath进行的封装。解析器模块的 另一个功能是占位符解析的功能,该处主要在动态sql语句中用到;该模块的项目结构位于mybatis项目的parse包,如下图所示:
2.xml文件解析:
xml常见的文件解析方式有三种,分别是: DOM ( Document Object Model )解析方式和 SAX ( Simple API for XML )解析方式,以及从 JDK6.0 版本开始, JDK 开始支持的 StAX ( Streaming API for XML)解析方式;各种方式的不同,可网上自行学习。在MyBatis项目中,对于配置文件mybatis-config.xml和mapper文件的解析是基于dom方式和结合XPath解析的。dom方式不是本篇重点,本篇主要会简单介绍XPath。
2.1XPath:
XPath是一种xml查询语言,可以与dom解析一起配合使用,XPath对于xml就相当于sql对于数据库,不同的是,XPath是用路径表达式进行查询,XPath常见的路径表达式如下图所示:
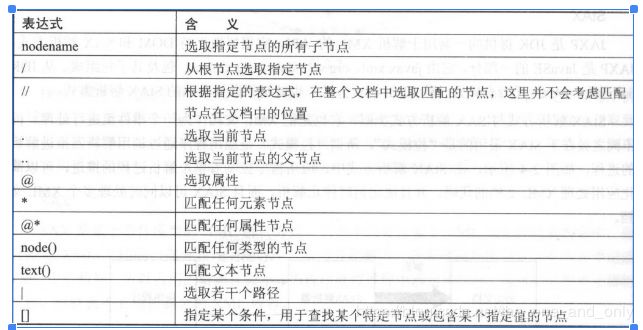
XPath相关语法可参考w3c:https://www.w3school.com.cn/xpath/xpath_nodes.asp。
在Java体系中,XPath是的类是javax.xml.xpath.XPath,使用它的模式比较固定和简单,基本是下面几个步骤
- 获取DocumentBuilderFactory
- 通过DocumentBuilderFactory获取DocumentBuilder
- 通过DocumentBuilder获取documnet对象
- 创建XPath对象。
public void testXpath() throws ParserConfigurationException, IOException, SAXException, XPathExpressionException {
//documentBuilderFactory
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setFeature(XMLConstants.FEATURE_SECURE_PROCESSING, true);
factory.setValidating(false);
factory.setNamespaceAware(false);
factory.setIgnoringComments(true);
factory.setIgnoringElementContentWhitespace(false);
factory.setCoalescing(false);
factory.setExpandEntityReferences(true);
//documentBuilder
DocumentBuilder documentBuilder = factory.newDocumentBuilder();
EntityResolver entityResolver = null;
documentBuilder.setEntityResolver(entityResolver);
documentBuilder.setErrorHandler(new ErrorHandler() {
@Override
public void warning(SAXParseException exception) throws SAXException {
log.error("SAXParseException", exception);
}
@Override
public void error(SAXParseException exception) throws SAXException {
log.error("SAXParseException", exception);
}
@Override
public void fatalError(SAXParseException exception) throws SAXException {
log.error("fatalError", exception);
}
});
//获取document对象
Document document = documentBuilder.parse(new ClassPathResource("inventory.xml").getFile());
//实例化xPath对象
XPathFactory xPathFactory = XPathFactory.newInstance();
XPath xpath = xPathFactory.newXPath();
//
Node inventoryNode = (Node) xpath.evaluate("/inventory", document, XPathConstants.NODE);
Assert.assertNotNull(inventoryNode);
}
3.XPathParser:
XPathParser是MyBatis对XPath进行封装提取,对于XPathParser的使用,如果熟悉XPath的话,应该不难理解,本文只对EntityResoler对象进行阐述和解释,如下图所示,为XPathParser类的成员变量:
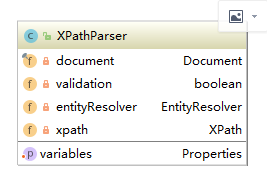
在上面XPath简单代码的展示里,有设置是否验证xml。当对xml文档进行检验时,会根据xml文档开始位置的加载对应的DTD和XSD文件进行校验,当网络比较慢时会导致验证过程缓慢。在实践中往往会提前设置 EntityResolver 接口对象加载本地的 DTD 文件;在MyBatis中,提供了EntityResolver的实现XMLMapperEntityResolver,具体使用,会在MyBatis初始化流程进行分析。
3.1 XPathParser构造函数
XPathParser构造函数重载有将近16个,但是每个构造函数模式基本相似,都是先调用common-Constructor(boolean validation, Properties variables, EntityResolver entityResolver) 这个方法,然后创建document对象;相应的 方法如下所示
private void commonConstructor(boolean validation, Properties variables, EntityResolver entityResolver) {
this.validation = validation;
this.entityResolver = entityResolver;
this.variables = variables;
XPathFactory factory = XPathFactory.newInstance();
this.xpath = factory.newXPath();
}
public XPathParser(Reader reader, boolean validation, Properties variables, EntityResolver entityResolver) {
commonConstructor(validation, variables, entityResolver);
this.document = createDocument(new InputSource(reader));
}
createDocument方法其实跟上面展示XPath的demo创建Document基本类似,相应代码读者也可自行去阅读,比较简单,就不再粘贴出来。
3.2 eval相关方法
XPathParser提供了一系列用于查询相关节点的方法,如下图所示,本质上都是利用XPath进行查询。另外,如果XPath查询表达式只使用一次 , 可以跳过编译步骤直接调用 XPath 对象的 evaluate()方法进行查询 。但是如果同一个 XPath 表达式要重复执行多次,则建议先进行编译,然后进行查询,这样性能会好一点。
对于XPathParser的eval相关的方法怎么用,在MyBatis项目的测试用例org.apache.ibatis.parsing.XPathParserTest都有明确的例子,如下图所示,为MyBatis提供的测试用例

3.GenericTokenParser
在MyBatis提供的一系列eval*方法中,我们可以发现,XPathParser.eva!String()会对占位符进行一层解析。如下面的代码所示
public String evalString(Object root, String expression) {
String result = (String) evaluate(expression, root, XPathConstants.STRING);
result = PropertyParser.parse(result, variables);
return result;
}
//org.apache.ibatis.parsing.PropertyParser#parse()
public static String parse(String string, Properties variables) {
VariableTokenHandler handler = new VariableTokenHandler(variables);
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
return parser.parse(string);
}
从上面代码可知,解析占位符的主要是parse方法,对于parse方法的主要实现逻辑如下,会查找openToken和closeToken里面字符串,然后交给具体的Handler对象处理。在Handler对象处理完毕的时候,会将Handler返回的结果代替对应的字符串;具体实现代码就不再粘贴出来了;读者可自行去阅读;需要注意的是,对于VariableTokenHandler的handleToken()方法。会有一层默认值的判断,如$ {usemame:root},其中“:”是占位符和 默认值的分隔符。如果查不到,会使用root作为默认值。
对于MyBatis源码第一章的分析就到这里了,博主也是花了三个星期才大致看完的,如果有什么错误之处,欢迎大佬留下评论探讨。