Mybatis高级用法
准备一个数据库
CREATE TABLE `blog` (
`bid` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`author_id` int(11) DEFAULT NULL,
PRIMARY KEY (`bid`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
CREATE TABLE `author` (
`author_id` int(16) NOT NULL AUTO_INCREMENT,
`author_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`author_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1002 DEFAULT CHARSET=utf8;
CREATE TABLE `comment` (
`comment_id` int(16) NOT NULL AUTO_INCREMENT,
`content` varchar(255) DEFAULT NULL,
`bid` int(16) DEFAULT NULL,
PRIMARY KEY (`comment_id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
INSERT INTO `blog` (`bid`, `name`, `author_id`) VALUES (1, 'RabbitMQ延时消息', 1001);
INSERT INTO `blog` (`bid`, `name`, `author_id`) VALUES (2, 'MyBatis源码分析', 1008);
INSERT INTO `author` (`author_id`, `author_name`) VALUES (1001, 'james');
INSERT INTO `comment` (`comment_id`, `content`, `bid`) VALUES (1, '写得真好,学习了', 1);
INSERT INTO `comment` (`comment_id`, `content`, `bid`) VALUES (2, '刚好碰到这个问题,谢谢', 1);
1.动态sql
- 标签根据条件动态拼接where后面的查询条件
<select id="selectBlogListIf" parameterType="blog" resultMap="BaseResultMap" >
select bid, name, author_id authorId from blog
<where>
<if test="bid != null">
AND bid = #{bid}
if>
<if test="name != null and name != ''">
AND name LIKE '%${name}%'
if>
<if test="authorId != null">
AND author_id = #{authorId}
if>
where>
select>
- 自动去除多余逗号,拼接括号
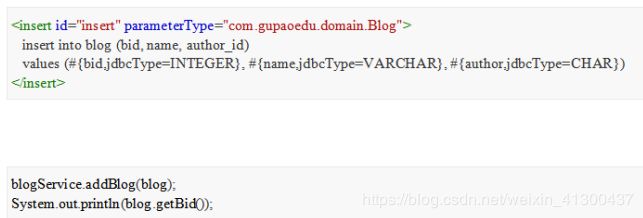
<insert id="insertBlog" parameterType="blog">
insert into blog
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="bid != null">
bid,
if>
<if test="name != null">
name,
if>
<if test="authorId != null">
author_id,
if>
trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="bid != null">
#{bid,jdbcType=INTEGER},
if>
<if test="name != null">
#{name,jdbcType=VARCHAR},
if>
<if test="authorId != null">
#{authorId,jdbcType=INTEGER},
if>
trim>
insert>
- 标签
<select id="selectBlogListChoose" parameterType="blog" resultMap="BaseResultMap" >
select bid, name, author_id authorId from blog
<where>
<choose>
<when test="bid !=null">
bid = #{bid, jdbcType=INTEGER}
when>
<when test="name != null and name != ''">
AND name LIKE CONCAT(CONCAT('%', #{name, jdbcType=VARCHAR}),'%')
when>
<when test="authorId != null ">
AND author_id = #{authorId, jdbcType=INTEGER}
when>
<otherwise>
otherwise>
choose>
where>
select>
- 标签
<update id="updateByPrimaryKey" parameterType="blog">
update blog
<set>
<if test="name != null">
name = #{name,jdbcType=VARCHAR},
if>
<if test="authorId != null">
author_id = #{authorId,jdbcType=CHAR},
if>
set>
where bid = #{bid,jdbcType=INTEGER}
update>
2.批量操作
<delete id="deleteByList" parameterType="java.util.List">
delete from blog where bid in
<foreach collection="list" item="item" open="(" separator="," close=")">
#{item.bid,jdbcType=INTEGER}
foreach>
delete>
<update id="updateBlogList">
update blog set
name =
<foreach collection="list" item="blogs" index="index" separator=" " open="case bid" close="end">
when #{blogs.bid} then #{blogs.name}
foreach>
,author_id =
<foreach collection="list" item="blogs" index="index" separator=" " open="case bid" close="end">
when #{blogs.bid} then #{blogs.authorId}
foreach>
where bid in
<foreach collection="list" item="item" open="(" separator="," close=")">
#{item.bid,jdbcType=INTEGER}
foreach>
update>
<insert id="insertBlogList" parameterType="java.util.List">
insert into blog (bid, name, author_id)
values
<foreach collection="list" item="blogs" index="index" separator=",">
( #{blogs.bid},#{blogs.name},#{blogs.authorId} )
foreach>
insert>
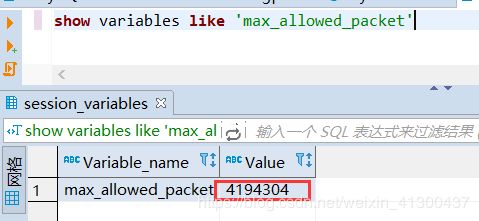
批量插入有个问题, 当拼接的sql语句特别长的时候就会报错。这是因为Mysql服务端对于接收的数据包有大小限制:
在数据库执行 show variables like ‘max_allowed_packet’ 这条语句可以看到默认大小是4M,如果数据量特别大,就需要修改这个参数或者手动控制批量插入的条数,比如,每1000条插入一次等。
除了这种方式,我们还可以在mybatis全局配置文件中将默认的Exexutor类型由SIMPLE改为BatchExecutor, 这样它创建的每一个执行器都将是批量的执行器:
<setting name="defalutExecutorType" value="BATCH"/>
也可以指定一次插入操作的执行器为批量执行器,在创建sqlsession时指定执行器类型为ExecutorType.BATCH即可:
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
其实批量执行器本质上是对PreparedStatement 的addBatch方法的封装,包括整合spring之后,jdbcTemplate的批量插入,也是对PreparedStatement 的封装
/**
* 原生JDBC的批量操作方式 ps.addBatch()
* @throws IOException
*/
@Test
public void testJdbcBatch() throws IOException {
Connection conn = null;
PreparedStatement ps = null;
try {
Long start = System.currentTimeMillis();
// 打开连接
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatistest?useUnicode=true&characterEncoding=utf-8&rewriteBatchedStatements=true", "root", "123456");
ps = conn.prepareStatement(
"INSERT into blog values (?, ?, ?)");
for (int i = 1000; i < 101000; i++) {
Blog blog = new Blog();
ps.setInt(1, i);
ps.setString(2, String.valueOf(i)+"");
ps.setInt(3, 1001);
ps.addBatch();
}
ps.executeBatch();
// conn.commit();
ps.close();
conn.close();
Long end = System.currentTimeMillis();
System.out.println("cost:"+(end -start ) +"ms");
} catch (SQLException se) {
se.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (ps != null) ps.close();
} catch (SQLException se2) {
}
try {
if (conn != null) conn.close();
} catch (SQLException se) {
se.printStackTrace();
}
}
}
3.关联查询、延迟加载以及N+1问题
实际应用中经常会遇到关联查询的场景,比如:
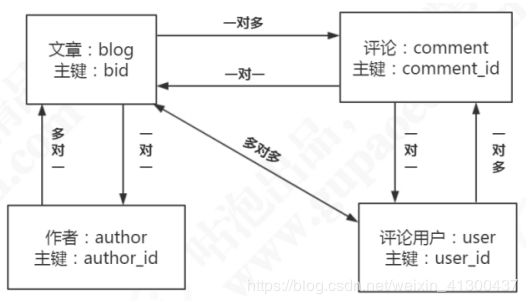
比如,我要查询一篇文章时,顺便把文章作者的信息也查询出来,这时可以有两种写法:
第一种是查询文章时,使用association 标签关联查询作者信息(嵌套的是结果),只执行一次查询就获取到了blog和author的信息,如下:
<select id="selectBlogWithAuthorResult" resultMap="BlogWithAuthorResultMap" >
select b.bid, b.name, b.author_id, a.author_id , a.author_name
from blog b
left join author a
on b.author_id=a.author_id
where b.bid = #{bid, jdbcType=INTEGER}
select>
<resultMap id="BlogWithAuthorResultMap" type="com.gupaoedu.domain.associate.BlogAndAuthor">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<association property="author" javaType="com.gupaoedu.domain.Author">
<id column="author_id" property="authorId"/>
<result column="author_name" property="authorName"/>
association>
resultMap>
第二种是,查询文章内容时,使用association 标签嵌套查询作者信息(嵌套的是查询)
这种查询会存在N+1问题,举例,比如有10条blogs, 执行了一次查询blog信息的sql,获取到了N条记录(比如10条blog),因为一条blog有一个作者,然后会再去查询N次author的信息,这就是所谓的N+1问题,这样会严重浪费数据库的性能。
<resultMap id="BlogWithAuthorQueryMap" type="com.gupaoedu.domain.associate.BlogAndAuthor">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<association property="author" javaType="com.gupaoedu.domain.Author"
column="author_id" select="selectAuthor"/>
resultMap>
<select id="selectAuthor" parameterType="int" resultType="com.gupaoedu.domain.Author">
select author_id authorId, author_name authorName
from author where author_id = #{authorId}
select>
N+1现象测试: 先将懒加载配置关闭(不配置或配置为false: )
private SqlSessionFactory sqlSessionFactory;
@Before
public void prepare() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
@Test
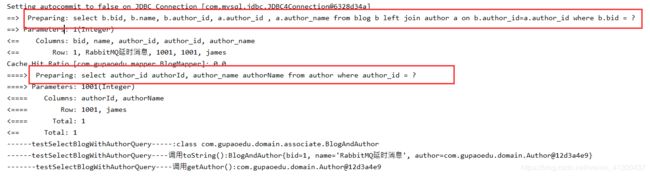
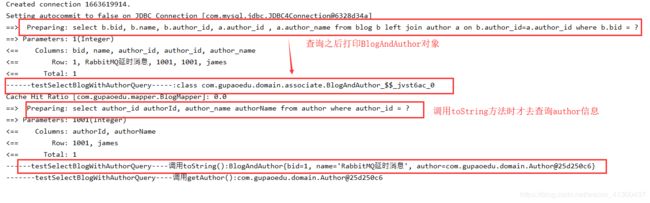
public void testSelectBlogWithAuthorQuery() throws IOException {
SqlSession session = sqlSessionFactory.openSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
BlogAndAuthor blog = mapper.selectBlogWithAuthorQuery(1);
System.out.println("------testSelectBlogWithAuthorQuery-----:"+blog.getClass());
// 如果开启了延迟加载(lazyLoadingEnabled=true),会在使用的时候才发出SQL
// equals,clone,hashCode,toString也会触发延迟加载
System.out.println("--" +
"----testSelectBlogWithAuthorQuery----调用toString():"+blog);
System.out.println("-------testSelectBlogWithAuthorQuery----调用getAuthor():"+blog.getAuthor().toString());
}
和明显数据库先去查了blog,然后又去查询了一次autor表
如何解决嵌套查询时N+1问题呢? 可以使用懒加载解决,在mybatis全局配置文件中启用懒加载再去测试:
<setting name="lazyLoadingEnabled" value="true"/>
代码中,把打印语句全部注释掉,不调用blog的任何方法:
//System.out.println("------testSelectBlogWithAuthorQuery-----:"+blog.getClass());
//System.out.println("------testSelectBlogWithAuthorQuery----调用toString():"+blog);
//System.out.println("-------testSelectBlogWithAuthorQuery----调用getAuthor():"+blog.getAuthor().toString());
可以看到只查询了blog信息

把打印语句放开再去测试: 除了调用blog.getAuthor() 的方法,调用equals,clone,hashCode,toString都会触发懒加载(blog.getName()不会触发)
上面有个问题,blog.getAuthor()只是一个获取属性的方法,并没有数据库连接的代码,那么为什么它能够触发对数据库的查询呢?
在上面的代码中,我们打印了blog的类型,发现它已经不是原本的Blog了,而是变成了一个代理对象。
4. Mapper映射接口的继承
假设一个表的表字段发生了改变,需要修改实体类和Mapper文件定义的字段和方法,如果是增量维护,
一个一个文件去修改,解决这个问题,可以通过mapper继承来实现:
假设已经存在了一个Mapper接口
package com.gupaoedu.mapper;
import com.gupaoedu.domain.BlogExample;
import com.gupaoedu.domain.associate.AuthorAndBlog;
import com.gupaoedu.domain.Blog;
import com.gupaoedu.domain.associate.BlogAndAuthor;
import com.gupaoedu.domain.associate.BlogAndComment;
import org.apache.ibatis.session.RowBounds;
import java.util.List;
public interface BlogMapper {
/**
* 根据主键查询文章
* @param bid
* @return
*/
public Blog selectBlogById(Integer bid);
/**
* 根据实体类查询文章
* @param blog
* @return
*/
public List<Blog> selectBlogByBean(Blog blog);
/**
* 文章列表翻页查询
* @param rowBounds
* @return
*/
public List<Blog> selectBlogList(RowBounds rowBounds);
/**
* 根据博客查询作者,一对一,嵌套结果
* @param bid
* @return
*/
public BlogAndAuthor selectBlogWithAuthorResult(Integer bid);
/**
* 根据博客查询作者,一对一,嵌套查询,存在N+1问题
* @param bid
* @return
*/
public BlogAndAuthor selectBlogWithAuthorQuery(Integer bid);
/**
* 查询文章带出文章所有评论(一对多)
* @param bid
* @return
*/
public BlogAndComment selectBlogWithCommentById(Integer bid);
/**
* 查询作者带出博客和评论(多对多)
* @return
*/
public List<AuthorAndBlog> selectAuthorWithBlog();
}
新建一个mapper接口继承它:
//扩展类继承了MBG生成的接口和Statement
public interface BlogMapperExt extends BlogMapper {
/**
* 根据名称查询文章
* @param name
* @return
*/
public Blog selectBlogByName(String name);
}
新建对应的Mapper映射文件BlogMapperExt.xml :
<mapper namespace="com.gupaoedu.mapper.BlogMapperExt">
<resultMap id="BaseResultMap" type="blog">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<result column="author_id" property="authorId" jdbcType="INTEGER"/>
resultMap>
<select id="selectBlogByName" resultMap="BaseResultMap" statementType="PREPARED">
select * from blog where name = #{name}
select>
mapper>
在mybatis中添加扫描,然后就可以调用了:
<mapper resource="BlogMapperExt.xml"/>
还有一种解决方式,就是使用通用Mapper, 封装一个支持泛型的通用接口,把实体类作为参数传入,这个接口里面封装所有的常用的增删改查的方法,然后自己定义的mapper接口继承该通用接,自动获得对实体类的操作方法,通用mapper中没有的方法,我们仍然可以自己去编写。这样的方案,MybatisPlus已经帮我们实现了,此处不详细展开
5.mybatis查询翻页原理
- 物理分页
在查询语句中使用limit , 传参时需要自己构造出查询的起始位置和页大小 - 逻辑分页
假分页,本质上是一次性查出所有数据,筛选出所需要的当前页的数据 - mybatis分页插件PageHelper

6.入库时返回自增id
mysql有些场景下插入数据会使用自增id, 并且要求插入之后获得最新的自增ID,而mybatis已经考虑到了这种场景,在insert成功后,mybatis会将插入的值自动绑定到插入的对象的Id属性中,我们用getId就可以取到最新的id