centos7 搭建hadoop集群 zookeeper Hbase集群
集群规划:
主机名 IP 安装的软件
master 192.168.1.201 jdk、hadoop、zookeeper
slave1 192.168.1.202 jdk、hadoop、zookeeper
slave2 192.168.1.203 jdk、hadoop、zookeeper
虚拟机安装技巧快速法: 先装master镜像,先操作后面“先在master上安装jdk(建议非openjdk)“这一节中的教程,安装ntp同步时间,接着按下面常用命令分别修改master主机名,ip地址和绑定hostname与ip,ip和主机名均按上面集群规划修改, 然后将master镜像克隆两个,分别为slave1、slave2,当然可以更多,接着按下面常用命令分别修改克隆的主机名,ip地址,再开启所有虚拟机并在master节点配置ssh免密登录到slave节点,接着按后面教程搭建hadoop集群 zookeeper Hbase集群。
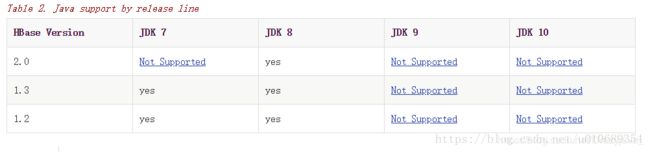
注意版本兼容问题
本博客:
jdk1.7
zookeeper3.4.14
hbase 1.5.0
hadoop 2.8.5
下面为版本兼容列表:

jdk与hbase兼容问题
安集群常用命令
root@master
即当前用户@主机名(hostname)
在master镜像中最好创建一个用户叫hadoop,解压什么的所有操作都用hadoop来操作
修改主机名
vim /etc/hostname
立即生效: hostname 主机名
修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-eth0
重启服务:
service network restart绑定hostname与ip
vim /etc/hosts

ntp同步时间
sudo yum install ntp.x86_64
systemctl start ntpd
ntpdate time1.aliyun.com
date
#重启命令
systemctl restart ntpd配置ssh免密登录
1.客户端生成公私钥
本地客户端生成公私钥:(一路回车默认即可)
ssh-keygen
上面这个命令会在用户目录.ssh文件夹下创建公私钥
cd ~/.ssh
ls
下创建两个密钥:
- id_rsa (私钥)
- id_rsa.pub (公钥)
2 免密登录集群其他服务器salve2 slave1

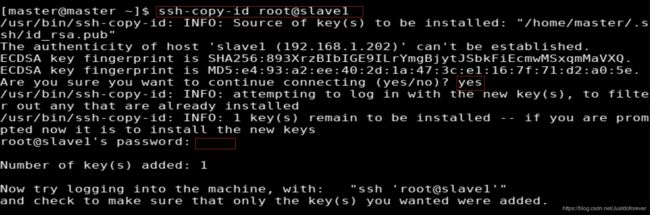
还有 ssh-copy-id master@master
测试成功

同理分别在slave1 slave2上执行同样的免密操作
先在master上安装jdk(建议非openjdk)
先下载jdk for linux,本文后缀为.zip其实是一样的,下载链接:https://download.csdn.net/download/Justdoforever/12527560
tar.gz后缀格式JDK安装方式
安装jdk-7u79-linux-x64.tar.gz。
在/usr目录下新建java文件夹,命令行:
[root@localhost Desktop]# mkdir /usr/java
进入JDK压缩包所在目录,将压缩包复制到java文件夹中。复制文件用cp xxx命令,复制文件夹用cp -r xxx,命令行:
[root@localhost Desktop]# cp jdk-7u79-linux-x64.gz /usr/java
然后返回到根目录,再进入java目录,命令行:
[root@localhost Desktop]# cd /
[root@localhost Desktop]# cd /usr/java
压缩包解压,命令行:
[root@localhost Desktop]# tar xvf jdk-7u79-linux-x64.gz
或者 [root@localhost Desktop]# unzip jdk-7u79-linux-x64.zip
删除压缩包,输入yes确认删除。命令行:
[root@localhost java]# rm jdk-7u79-linux-x64.gz
rm: remove regular file `jdk-7u79-linux-x64.gz'? yes
设置对所有用户有效方式:修改/etc/profile文件设置系统变量,设置jdk环境变量,该方式对所有用户有效。
使用VI编辑,输入命令,回车确认。命令行:
[root@localhost Desktop]# vi /etc/profile
打开之后在文件末尾添加下面配置。通过鼠标滑轮滚动到文件末尾,上下左右方向键控制光标输入位置。
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
配置好后,按Esc退出,按Shift加英文冒号shift + : 然后输入wq,按Enter回车键确认。取消编辑按Ctrl+z。
使profile配置生效。命令行:
[root@localhost Desktop]# source /etc/profile
安装步骤:
1.安装配置zooekeeper集群(在master上操作)3.4.14版本链接https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.4.14/ 用什么版本下面替换一下就好了
1.1解压
tar -zxvf zookeeper-3.4.6.tar.gz -C /usr/local
1.2修改配置
cd /usr/local/zookeeper-3.4.6/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
server.id=host:port1:port2
其中id为一个数字,表示zk进程的id,这个id也是dataDir目录下myid文件的内容。
host是该zk进程所在的IP地址,port1表示follower和leader交换消息所使用的端口,port2表示选举leader所使用的端口。
dataDir
其配置的含义跟单机模式下的含义类似,不同的是集群模式下还有一个myid文件。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。
修改:dataDir=/usr/local/zookeeper-3.4.6/tmp
在最后添加:
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
保存退出
然后创建一个tmp文件夹
mkdir /usr/local/zookeeper-3.4.6/tmp
再创建一个空文件
touch /usr/local/zookeeper-3.4.6/tmp/myid
最后向该文件写入ID
echo 1 > /usr/local/zookeeper-3.4.6/tmp/myid
1.3将配置好的zookeeper拷贝到其他节点(首先分别在slave1、slave2创建相应目录:mkdir /usr/local)
scp -r /usr/local/zookeeper-3.4.6/ slave1:/usr/local/
scp -r /usr/local/zookeeper-3.4.6/ slave2:/usr/local/
注意:修改slave1、slave2对应/usr/local/zookeeper-3.4.6/tmp/myid内容
slave1:
echo 2 > /usr/local/zookeeper-3.4.6/tmp/myid
slave2:
echo 3 > /usr/local/zookeeper-3.4.6/tmp/myid
2.安装配置hadoop集群(在master上操作)下载链接为zip,解压命令换为unzip,具体命令百度,可能要安装该命令:https://download.csdn.net/download/Justdoforever/12487962
2.1解压
tar -zxvf hadoop-2.4.0.tar.gz -C /usr/local/
2.2配置HDFS(hadoop2.0以上所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_55
export HADOOP_HOME=/usr/local/hadoop-2.4.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
#使变量生效
source /etc/profile
#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /usr/local/hadoop-2.4.0/etc/hadoop
2.2.1修改hadoo-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_55
2.2.2修改core-site.xml
hadoop中有3个核心组件:
分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上
分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运算
分布式资源调度平台:YARN —— 帮用户调度大量的mapreduce程序,并合理分配运算资源
2.2.3修改hdfs-site.xml
sshfence
shell(/bin/true)
2.2.4修改mapred-site.xml
Yarn 框架相对于老的 MapReduce 框架什么优势呢?我们可以看到:
1. 这个设计大大减小了 JobTracker(也就是现在的 ResourceManager)的资源消耗,并且让监测每一个 Job 子任务 (tasks) 状态的程序分布式化了,更安全、更优美。
2. 在新的 Yarn 中,ApplicationMaster 是一个可变更的部分,用户可以对不同的编程模型写自己的 AppMst,让更多类型的编程模型能够跑在 Hadoop 集群中,可以参考 hadoop Yarn 官方配置模板中的 mapred-site.xml 配置。
3. 对于资源的表示以内存为单位 ( 在目前版本的 Yarn 中,没有考虑 cpu 的占用 ),比之前以剩余 slot 数目更合理。
4. 老的框架中,JobTracker 一个很大的负担就是监控 job 下的 tasks 的运行状况,现在,这个部分就扔给 ApplicationMaster 做了,而 ResourceManager 中有一个模块叫做 ApplicationsMasters( 注意不是 ApplicationMaster),它是监测 ApplicationMaster 的运行状况,如果出问题,会将其在其他机器上重启。
5. Container 是 Yarn 为了将来作资源隔离而提出的一个框架。这一点应该借鉴了 Mesos 的工作,目前是一个框架,仅仅提供 java 虚拟机内存的隔离 ,hadoop 团队的设计思路应该后续能支持更多的资源调度和控制 , 既然资源表示成内存量,那就没有了之前的 map slot/reduce slot 分开造成集群资源闲置的尴尬情况。
2.2.5修改yarn-site.xml
2.2.6修改slaves(slaves是指定子节点的位置,因为要在itcast01上启动HDFS、在itcast03启动yarn,所以itcast01上的slaves文件指定的是datanode的位置,itcast03上的slaves文件指定的是nodemanager的位置)
slave1
slave2
2.4将配置好的hadoop拷贝到其他节点
scp -r /usr/local/hadoop-2.4.0/ slave1:/usr/local/
scp -r /usr/local/hadoop-2.4.0/ slave2:/usr/local/
拷贝完要配置环境,slave1 slave2
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_55
export HADOOP_HOME=/usr/local/hadoop-2.4.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
#使变量生效
source /etc/profile
###注意:严格按照下面的步骤
2.5启动zookeeper集群(分别在master、slave1、slave2上启动zk)
cd /usr/local/zookeeper-3.4.5/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status
2.6启动journalnode(分别在在master、slave1、slave2上执行)
cd /usr/local/hadoop-2.4.0
sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,master、slave1、slave2上多了JournalNode进程
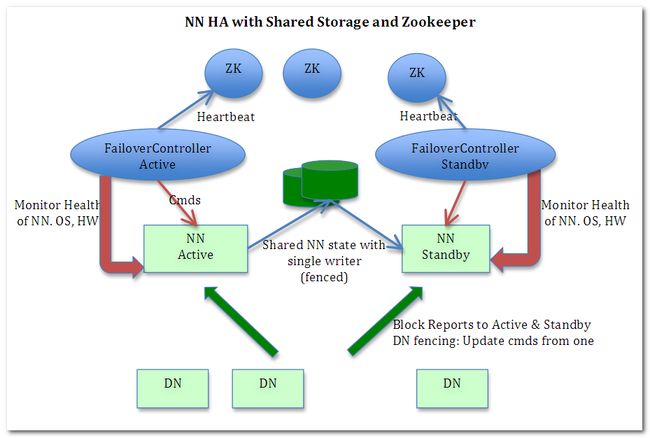
1〉上面在Active Namenode与StandBy Namenode之间的绿色区域就是JournalNode,当然数量不一定只有1个,作用相当于NFS共享文件系统.Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步.
2〉 NameNode之间共享数据(NFS 、Quorum Journal Node(用得多))
3〉两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
4〉 Hadoop中的NameNode好比是人的心脏,非常重要,绝对不可以停止工作
2.7格式化HDFS
#在master上执行命令: hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/usr/local/hadoop-2.4.0/tmp,然后将/usr/local/hadoop-2.4.0/tmp拷贝到slave1的/usr/local/hadoop-2.4.0/下。
scp -r tmp/ slave1:/usr/local/hadoop-2.4.0/
2.8格式化ZK(在master上执行即可)
hdfs zkfc -formatZK
2.9启动HDFS(在master上执行)
sbin/start-dfs.sh
2.10启动YARN(在master上操作)
sbin/start-yarn.sh
到此,hadoop-2.8.5配置完毕,可以统计浏览器访问:
http://192.168.1.201:50070
NameNode 'itcast01:9000' (active)
http://192.168.1.202:50070
NameNode 'itcast02:9000' (standby)

至此搞定hadoop~恭喜你也完成了。
最开始hbase用的1.1.5后面查资料,发现不兼容,后选1.5.0
wget http://archive.apache.org/dist/hbase/1.5.0/hbase-1.5.0-bin.tar.gz
一定记得同步三台机器时间
1.上传hbase安装包
2.解压
3.配置hbase集群,要修改3个文件(首先zk集群已经安装好了)
注意:要把hadoop的hdfs-site.xml和core-site.xml 放到hbase/conf下
3.1修改hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_80
//告诉hbase使用外部的zk
export HBASE_MANAGES_ZK=false
3.1修改hbase-site.xml
vim hbase-site.xml
hbase.rootdir
hdfs://192.168.1.201:9000/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
master:2181,slave1:2181,slave2:2181
vim regionservers
master
slave1
slave2
3.2拷贝hbase到其他节点
scp -r /usr/local/hbase-0.96.2-hadoop2/ slave1:/usr/local/
scp -r /usr/local/hbase-0.96.2-hadoop2/ slave2:/usr/local/4.将配置好的HBase拷贝到每一个节点并同步时间。
5.启动所有的hbase
分别启动zk
./zkServer.sh start
启动hbase集群
start-dfs.sh
启动hbase,在主节点上运行:
start-hbase.sh
6.通过浏览器访问hbase管理页面
192.168.1.201:16010
7.为保证集群的可靠性,要启动多个HMaster
hbase-daemon.sh start master
自此大功告成,花费了我5天时间, 太难了,以后装软件之间一定要考虑版本兼容性问题。共勉!!!