MapReduce 之 InputFormat数据输入
1.Job提交流程和切片源码详解
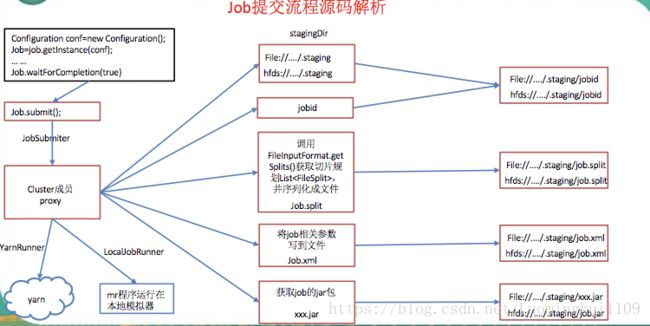
(1) job提交流程源码详解
waitForCompletion()
submit();
// 1
建立连接
connect();
// 1
)创建提交
job
的代理
new
Cluster(getConfiguration());
//
(
1
)判断是本地
yarn
还是远程
initialize(jobTrackAddr, conf);
// 2
提交
job
submitter.submitJobInternal(Job.
this
, cluster)
// 1
)创建给集群提交数据的
Stag
路径
Path jobStagingArea = JobSubmissionFiles.
getStagingDir
(cluster,
conf
);
// 2
)获取
jobid
,并创建
job
路径
JobID jobId = submitClient.getNewJobID();
// 3
)拷贝
jar
包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4
)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5
)向
Stag
路径写
xml
配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6
)提交
job,
返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
流程图:
(2) FileInputFormat
源码解析
①
找到你数据存储的目录。
② 开始遍历处理(规划切片)目录下的每一个文件
③ 遍历第一个文件
ss.txt
a
)获取文件大小
fs.sizeOf(ss.txt)
b
)计算切片大小
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
c
)默认情况下,切片大小
=blocksize
d
)开始切,形成第
1
个切片:
ss.txt—0:128M
第
2
个切片
ss.txt—128:256M
第
3
个切片
ss.txt—256M:300M
(
每次切片时,都要判断切完剩下的部分是否大于块的
1.1
倍,不大于
1.1
倍就划分一块切片
)
e
)将切片信息写到一个切片规划文件中
f
)整个切片的核心过程在
getSplit()
方法中完成
g
)数据切片只是在逻辑上对输入数据进行分片,并不会再磁盘上将其切分成分片进行存储。
InputSplit
只记录了分片的元数据信息,比如起始位置、长度以及所在的节点列表等
h
)注意:
block
是
HDFS
物理上存储的数据,切片是对数据逻辑上的划分
④ 提交切片规划文件到
yarn
上,
yarn
上的
MrAppMaster
就可以根据切片规划文件计算开启
maptask
个数。
2. FileInputFormat切片机制
(1) FileInputFormat中默认的切片机制:
① 简单地按照文件的内容长度进行切片
② 切片大小,默认等于block大小
③ 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
file1.txt 320M
file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10M
(2) FileInputFormat切片大小的参数配置
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize));
切片主要由这几个值来运算决定
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize= Long.MAXValue 默认值Long.MAXValue
因此,默认情况下,切片大小=blocksize。
maxsize(切片最大值):参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值。
minsize(切片最小值):参数调的比blockSize大,则可以让切片变得比blocksize还大。
(3) 获取切片信息API
// 根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
// 获取切片的文件名称
String name = inputSplit.getPath().getName();
4.InputFormat接口实现类
MapReduce任务的输入文件一般是存储在HDFS里面。输入的文件格式包括:基于行的日志文件、二进制格式文件等。这些文件一般会很大,达到数十GB,甚至更大。那么MapReduce是如何读取这些数据的呢?下面我们首先学习InputFormat接口。
InputFormat常见的接口实现类包括:
TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。
(1) TextInputFormat
TextInputFormat是默认的InputFormat。每条记录是一行输入。键是LongWritable类型,存储该行在整个文件中的字节偏移量。值是这行的内容,不包括任何行终止符(换行符和回车符)。
以下是一个示例,比如,一个分片包含了如下4条文本记录。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
每条记录表示为以下键/值对:
(0,Rich learning form)
(19,Intelligent learning engine)
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
很明显,键并不是行号。一般情况下,很难取得行号,因为文件按字节而不是按行切分为分片。
(2) KeyValueTextInputFormat
每一行均为一条记录,被分隔符分割为key,value。可以通过在驱动类中设置conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");来设定分隔符。默认分隔符是tab(\t)。
以下是一个示例,输入是一个包含4条记录的分片。其中——>表示一个(水平方向的)制表符。
line1 ——>Rich learning form
line2 ——>Intelligent learning engine
line3 ——>Learning more convenient
line4 ——>From the real demand for more close to the enterprise
每条记录表示为以下键/值对:
(line1,Rich learning form)
(line2,Intelligent learning engine)
(line3,Learning more convenient)
(line4,From the real demand for more close to the enterprise)
此时的键是每行排在制表符之前的Text序列。
(3) NLineInputFormat
如果使用NlineInputFormat,代表每个map进程处理的InputSplit不再按block块去划分,而是按NlineInputFormat指定的行数N来划分。即输入文件的总行数/N=切片数,如果不整除,切片数=商+1。
以下是一个示例,仍然以上面的4行输入为例。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
例如,如果N是2,则每个输入分片包含两行。开启2个maptask。
(0,Rich learning form)
(19,Intelligent learning engine)
另一个 mapper 则收到后两行:
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
这里的键和值与TextInputFormat生成的一样。
(4) CombineTextInputFormat切片机制
关于大量小文件的优化策略
① 默认情况下TextInputformat对任务的切片机制是按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个maptask,这样如果有大量小文件,就会产生大量的maptask,处理效率极其低下。
② 优化策略
a.最好的办法,在数据处理系统的最前端(预处理/采集),将小文件先合并成大文件,再上传到HDFS做后续分析。
b. 补救措施:如果已经是大量小文件在HDFS中了,可以使用另一种InputFormat来做切片(CombineTextInputFormat),它的切片逻辑跟TextFileInputFormat不同:它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个maptask。
c. 优先满足最小切片大小,不超过最大切片大小
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);// 2m
举例:0.5m+1m+0.3m+5m=2m + 4.8m=2m + 4m + 0.8m
③ 具体实现步骤
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class)
CombineTextInputFormat .setMaxInputSplitSize(job, 4194304);// 4m
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);// 2m
(5) 自定义InputFormat流程
① 自定义一个类继承FileInputFormat。
② 改写RecordReader,实现一次读取一个完整文件封装为KV。
③ 在输出时使用SequenceFileOutPutFormat输出合并文件。
5.自定义InputFormat案例实操
(1) 需求
无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案。将多个小文件合并成一个文件SequenceFile,SequenceFile里面存储着多个文件,存储的形式为文件路径+名称为key,文件内容为value。
(2)
输入数据
(3) 分析
小文件的优化无非以下几种方式:
① 在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS
② 在业务处理之前,在HDFS上使用mapreduce程序对小文件进行合并
③ 在mapreduce处理时,可采用CombineTextInputFormat提高效率
(4) 具体实现
本节采用自定义InputFormat的方式,处理输入小文件的问题。
① 自定义一个类继承FileInputFormat
② 改写RecordReader,实现一次读取一个完整文件封装为KV
③ 在输出时使用SequenceFileOutPutFormat输出合并文件
(5) 程序实现:
① 自定义InputFromat
public class
WholeFileInputFormat
extends
FileInputFormat
,
Text>{
@Override
protected boolean
isSplitable
(JobContext context
,
Path filename) {
//不让切片
return false;
}
@Override
public
RecordReader
,
Text>
createRecordReader
(InputSplit split
,
TaskAttemptContext context)
throws
IOException
,
InterruptedException {
WholeRecordReader recordReader =
new
WholeRecordReader()
;
recordReader.initialize(split
,
context)
;
return
recordReader
;
}
}
② 自定义RecordReader
public class
WholeRecordReader
extends
RecordReader
,
Text> {
private boolean
isProgressed
=
false;
private
Configuration
configuration
;
private
Path
path
;
private
FileSplit
fileSplit
;
//值
Text
value
=
new
Text()
;
@Override
public void
initialize
(InputSplit split
,
TaskAttemptContext context)
throws
IOException
,
InterruptedException {
//初始化配置信息
configuration
= context.getConfiguration()
;
//初始化切片信息(文件路径)
path
= ((FileSplit) split).getPath()
;
//初始化切片信息
fileSplit
= (FileSplit) split
;
}
@Override
public boolean
nextKeyValue
()
throws
IOException
,
InterruptedException {
//业务逻辑
if
(!
isProgressed
) {
//读数据
FileSystem fs = FileSystem.
get
(
configuration
)
;
//获取输入流
// FSDataInputStream fis = fs.open(new Path(path.getName()));
FSDataInputStream fis = fs.open(
path
)
;
//读数据
byte
[] buf =
new byte
[(
int
)
fileSplit
.getLength()]
;
IOUtils.
readFully
(fis
,
buf
,
0
,
buf.
length
)
;
//写入value
value
.set(buf)
;
isProgressed
=
true;
return
isProgressed
;
}
else
{
return false;
}
}
@Override
public
NullWritable
getCurrentKey
()
throws
IOException
,
InterruptedException {
//获取当前key
return
NullWritable.
get
()
;
}
@Override
public
Text
getCurrentValue
()
throws
IOException
,
InterruptedException {
//获取当前值
return
value
;
}
@Override
public float
getProgress
()
throws
IOException
,
InterruptedException {
//获取进程状态
return
0
;
}
@Override
public void
close
()
throws
IOException {
//关闭相应资源
}
}
③ SequenceFileMapper处理流程
public class
WholeFileMapper
extends
Mapper
,
Text
,
Text
,
Text> {
String
name
;
Text
k
=
new
Text()
;
@Override
protected void
setup
(Context context)
throws
IOException
,
InterruptedException {
//获取切片信息
FileSplit split = (FileSplit)context.getInputSplit()
;
name
= split.getPath().getName()
;
}
@Override
protected void
map
(NullWritable key
,
Text value
,
Context context)
throws
IOException
,
InterruptedException {
k
.set(
name
)
;
//写出
context.write(
k
,
value)
;
}
}
④ SequenceFileDriver处理流程
public class
WholeFileDriver {
public static void
main
(String[] args)
throws
IOException
,
ClassNotFoundException
,
InterruptedException {
//1.获取Job对象
Configuration configuration =
new
Configuration()
;
Job job = Job.
getInstance
(configuration)
;
//2.设置jar路径
job.setJarByClass(WholeFileDriver.
class
)
;
//3.设置Mapper类
job.setMapperClass(WholeFileMapper.
class
)
;
//4.设置Mapper输出的KV类型
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(Text.class);
//5.设置最终输出的KV类型
job.setOutputKeyClass(Text.
class
)
;
job.setOutputValueClass(Text.
class
)
;
//8.设置InputFormat
job.setInputFormatClass(WholeFileInputFormat.class);
job.setNumReduceTasks(0);
//6.设置文件输入输出路径
FileInputFormat.
setInputPaths
(job
, new
Path(args[
0
]))
;
FileOutputFormat.
setOutputPath
(job
, new
Path(args[
1
]))
;
//7.提交
boolean
result = job.waitForCompletion(
true
)
;
System.
exit
(result ?
0
:
1
)
;
}
}