mybatis源码解析2——Configuration
上一篇解析了SqlSession的源码,本篇继续解读有关流程,继续来看这个例子:
public int update(int id) {
SqlSession session = SQLSessionFactory.getSessoinFactory().openSession();
int i = session.update(namespace+"updateOne",id);
session.commit();
session.close();
return i;
}通过逆向推理,我们已经知道SqlSession实际上是一个包装器,它的大部分方法都是executor在执行,如上面代码中的close、commit,而对于update等查询方法,除了使用executor对应的update以外,还需要经过其他组件进行相关数据的获取,update代码如下:
@Override
public int update(String statement, Object parameter) {
try {
dirty = true;
MappedStatement ms = configuration.getMappedStatement(statement);//先得到它
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}MappedStatement是什么:
public final class MappedStatement {
private String resource;
private Configuration configuration;
private String id;
private Integer fetchSize;
private Integer timeout;
private StatementType statementType;
private ResultSetType resultSetType;
private SqlSource sqlSource;
private Cache cache;
private ParameterMap parameterMap;
private List resultMaps;
private boolean flushCacheRequired;
private boolean useCache;
private boolean resultOrdered;
private SqlCommandType sqlCommandType;
private KeyGenerator keyGenerator;
private String[] keyProperties;
private String[] keyColumns;
private boolean hasNestedResultMaps;
private String databaseId;
private Log statementLog;
private LanguageDriver lang;
private String[] resultSets; 在执行executor的update前,需要两个参数,一个是sql语句对应的statement和对应的参数parameter,我们知道,statement是来自mapper.xml文件中sql语句的id,从上述代码可以看出,通过configruation对象的getMappedStatement方法来取得对应的id的statement及其相关参数,并把它封装为MappedStatement对象传给executor。类似的还有select、remove等方法。要研究这个MappedStatement是如何产生,先从configuration入手,MappedStatament暂不深究。
在configuration对象中,封装了大量的初始化对象,包括配置文件中的配置项和mapper中配置项。在configuration对象创建的时候,首先会注册一批自身需要用到的类型:

注册的过程很简单,就是将这些类型统统放入一个map里面,在这之前,还要先注册java的基本类型和jdbc类型:
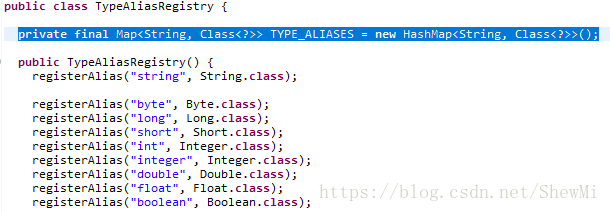
为什么要进行类型注册?看了这个方法就明白了:
public void registerAlias(String alias, Class value) {
if (alias == null) {
throw new TypeException("The parameter alias cannot be null");
}
// issue #748
String key = alias.toLowerCase(Locale.ENGLISH);//别名会全部转为小写,也就是不区分大小写
if (TYPE_ALIASES.containsKey(key) && TYPE_ALIASES.get(key) != null && !TYPE_ALIASES.get(key).equals(value)) {
throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + TYPE_ALIASES.get(key).getName() + "'.");
}
TYPE_ALIASES.put(key, value);
}为了防止用户使用的别名冲突,或者和自身使用的类型冲突,如果一个别名重复注册,就会抛出异常。必需在创建configuration的时候执行,因为后面的逻辑会依赖别名,配置文件中的typeAliases这一项必需置于首位,然后再到environment,其中一个原因就在于此,还有另一个原因,就是它读取xml是使用XPath导航的。
回过头来看刚才的mappedStatement在Configuration中是如何处理的:
protected final Map mappedStatements = new StrictMap("Mapped Statements collection");
protected final Map caches = new StrictMap("Caches collection");
protected final Map resultMaps = new StrictMap("Result Maps collection");
protected final Map parameterMaps = new StrictMap("Parameter Maps collection");
protected final Map keyGenerators = new StrictMap("Key Generators collection"); public void addMappedStatement(MappedStatement ms) {
mappedStatements.put(ms.getId(), ms);
}也是使用了map来缓存并映射statement,其中的key正是我们mapper.xml里面statement的id,而使用的StrictMap是一个继承了HashMap的静态内部类,它的一个主要作用就是处理id重映射:
public V put(String key, V value) {
if (containsKey(key)) {
throw new IllegalArgumentException(name + " already contains value for " + key);
}
if (key.contains(".")) {
final String shortKey = getShortName(key);
if (super.get(shortKey) == null) {
super.put(shortKey, value);
} else {
super.put(shortKey, (V) new Ambiguity(shortKey));//如果id重复映射,则存入标记字符串
}
}
return super.put(key, value);
}
public V get(Object key) {
V value = super.get(key);
if (value == null) {
throw new IllegalArgumentException(name + " does not contain value for " + key);
}
if (value instanceof Ambiguity) {//在取出的时候才抛出id重映射异常
throw new IllegalArgumentException(((Ambiguity) value).getSubject() + " is ambiguous in " + name
+ " (try using the full name including the namespace, or rename one of the entries)");
}
return value;
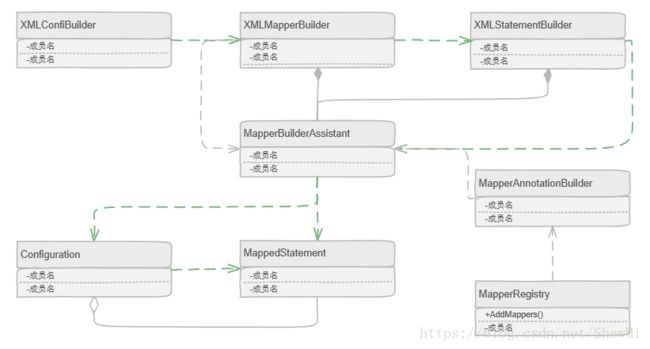
}那么,mappedStatement是怎么来的?在我们创建SqlSessionFactory的时候,会先得到一个XMLConfigBuilder,XMLConfigBuilder使用XPathParser读取配置文件并创建Configuration,XMLConfigBuilder再调用XMLMapperBuilder解析mapper配置文件,再调用XMLStatementBuilder(这些builder是跟配置文件的节点对应导航的),XMLStatementBuilder这个方法的作用可以理解为收集statement片段,最终将一些元信息和片段交给MapperBuilderAssistant去构建完整的statement:
public void parseStatementNode() {
String id = context.getStringAttribute("id");
String databaseId = context.getStringAttribute("databaseId");
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
return;
}
Integer fetchSize = context.getIntAttribute("fetchSize");
Integer timeout = context.getIntAttribute("timeout");
String parameterMap = context.getStringAttribute("parameterMap");
String parameterType = context.getStringAttribute("parameterType");
Class parameterTypeClass = resolveClass(parameterType);
String resultMap = context.getStringAttribute("resultMap");
String resultType = context.getStringAttribute("resultType");
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
......
......
// Include Fragments before parsing 在解析之前将所有片段包括进来
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
// Parse selectKey after includes and remove them.解析选择键
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// Parse the SQL (pre: and were parsed and removed)解析sql
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
......
......
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
} 在builderAssistant.addMappedStatement方法中,将完成构建的statement存入configruation的mappedStatements集合中,也就是SqlSession所获取的statement所在的集合:
public MappedStatement addMappedStatement(......) {
if (unresolvedCacheRef) {
throw new IncompleteElementException("Cache-ref not yet resolved");
}
id = applyCurrentNamespace(id, false);//检查命名空间是否正确并返回正确的命名空间下的statement的全限定名(namespace+.+id)
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
//实际的构建语句由statementbuilder执行
MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
.resource(resource)
.fetchSize(fetchSize)
.timeout(timeout)
.statementType(statementType)
.keyGenerator(keyGenerator)
.keyProperty(keyProperty)
.keyColumn(keyColumn)
.databaseId(databaseId)
.lang(lang)
.resultOrdered(resultOrdered)
.resultSets(resultSets)
.resultMaps(getStatementResultMaps(resultMap, resultType, id))
.resultSetType(resultSetType)
.flushCacheRequired(valueOrDefault(flushCache, !isSelect))
.useCache(valueOrDefault(useCache, isSelect))
.cache(currentCache);
ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id);
if (statementParameterMap != null) {
statementBuilder.parameterMap(statementParameterMap);//传入参数
}
MappedStatement statement = statementBuilder.build();
configuration.addMappedStatement(statement);//将构建好的statement存入集合
return statement;
}当sqlSession通过configuration的getMappedStatement方法取得,实际上就是直接通过我们写的的statement的id从map里面获取,而在获取statement的时候,所调用的configuration中这个方法怎么理解:
public MappedStatement getMappedStatement(String id, boolean validateIncompleteStatements) {
if (validateIncompleteStatements) {//是否校验未完成构建的statement
buildAllStatements();
}
return mappedStatements.get(id);
}从这个方法会多次被sqlSession调用的特点来看,如果给定的参数为true,那么每次都会检查有无未构建完成的statement,如果有则会进行构建,参数为false不会构建,只取出对应的statement,进一步细看:
/*
* Parses all the unprocessed statement nodes in the cache. It is recommended
* to call this method once all the mappers are added as it provides fail-fast
* statement validation.
*/
protected void buildAllStatements() {
if (!incompleteResultMaps.isEmpty()) {
synchronized (incompleteResultMaps) {
// This always throws a BuilderException.
incompleteResultMaps.iterator().next().resolve();
}
}
if (!incompleteCacheRefs.isEmpty()) {
synchronized (incompleteCacheRefs) {
// This always throws a BuilderException.
incompleteCacheRefs.iterator().next().resolveCacheRef();
}
}
if (!incompleteStatements.isEmpty()) {
synchronized (incompleteStatements) {
// This always throws a BuilderException.
incompleteStatements.iterator().next().parseStatementNode();
}
}
if (!incompleteMethods.isEmpty()) {
synchronized (incompleteMethods) {
// This always throws a BuilderException.
incompleteMethods.iterator().next().resolve();
}
}
}使用了同步锁来保证线程安全,从官方的注释证明了上述的观点,并且只是针对已缓存的statement,他建议我们调用一次build方法最好将所有xmlstatementbuilder进行构建一遍校验statement不通过时可以得到快速失败的效果。而这些incompleteStatement等未完成构建的对象和mappedStatement对象有什么关系呢(然而并没有任何关系)?
在xmlstatementbuilder方法中,如果构建时出现了IncompleteElementException(通常由于配置里sql属性写错),就会添加到集合,但是配置文件只加载一次,为何要保存这些得不到更正的对象呢?我认为就是为了让应用程序使用过程中可以多次触发异常,以便开发人员排查,一旦再次构建,就可以马上出现异常(这就是快速失败的效果吧-.-),也许是针对动态statement,可以过滤不能通过的动态statement片段而不会影响正常的片段:
private void buildStatementFromContext(List list, String requiredDatabaseId) {
for (XNode context : list) {
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
} configruation使用了链表来缓存这些对象,并且使用Collection类型签名类限制方法级别,使用链表意味着这些集合插入对象可能会比较频繁以取得更好的性能。实际上所有的对象都是添加到末尾,使用链表好处就是不用关心长度,如果使用可变数组则可能会频繁的扩容。这些集合中的并非MappedStatement对象,而是XMLStatementBuilder,只有在被调用的情况下(执行getMappedStatement方法)才会迭代执行parseStatementNode来构建statement,一种延迟方式。
protected final Collection incompleteStatements = new LinkedList();
protected final Collection incompleteCacheRefs = new LinkedList();
protected final Collection incompleteResultMaps = new LinkedList();
protected final Collection incompleteMethods = new LinkedList(); 对于Builder是如何构建sql和statement,这里不深究,我们已经知道一个statement是经过多个解析和拼接步骤完成的,尽管构建的过程分别经过几个类的处理,但是逻辑仍然耦合紧密,并且做了大量封装,没有任何的扩展元素,可以看出mybaits的开发者并不希望在初始化和构建statement的过程存在外界干预,对于希望根据应用改动sql语句的操作,在这个环节是不太可能实现的了。
另外,根据上述的流程,statement的构建是由SqlSession的调用Configuration来触发的,但是这并不是唯一的途径。MapperAnnotationBuilder用于解析注解配置,从构造方法可以推断是在configuration之后创建,用于解析注解中的statement和配置:
public MapperAnnotationBuilder(Configuration configuration, Class type) {
String resource = type.getName().replace('.', '/') + ".java (best guess)";
this.assistant = new MapperBuilderAssistant(configuration, resource);
this.configuration = configuration;
this.type = type;
sqlAnnotationTypes.add(Select.class);
sqlAnnotationTypes.add(Insert.class);
sqlAnnotationTypes.add(Update.class);
sqlAnnotationTypes.add(Delete.class);
sqlProviderAnnotationTypes.add(SelectProvider.class);
sqlProviderAnnotationTypes.add(InsertProvider.class);
sqlProviderAnnotationTypes.add(UpdateProvider.class);
sqlProviderAnnotationTypes.add(DeleteProvider.class);
}这个类解析并添加的注解statement是由我们常用的MapperRegistry的addMapper和getMapper方法触发。
最后,总结一下,configuration主要负责初始化所有mybatis工作所需的类型和对象,它通过map来管理别名和statement,statement经过XMLStatementBuilder的解析和拼接最终完成封装,XMLConfigBuilder会在一开始把配置文件项目statement解析出来存入configuration,MapperAnnotationBuilder用于手动添加mapper时构建statement。
值得注意的是,这里mybatis使用了懒加载模式,statement的构建是可以推迟到Sqlsession调用时触发的。
个人认为,解析statement这个模块mybatis的开发者写的比较乱,主要是工作流程被拆分太多,没有集中处理的方法也不少,如果没有开发者本地注释档做参考,是很难对其进行改动的。
本章的结构关系图如下: