Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
Ubuntu上搭建Hadoop环境(单击模式+伪分布模式)
Ubuntu上搭建Hadoop环境(单击模式+伪分布模式)
1.安装Ubuntu虚拟机
Ubuntu下载地址:Ubuntu官网
下面是VM安装ubuntu虚拟机
傻瓜式的安装即可




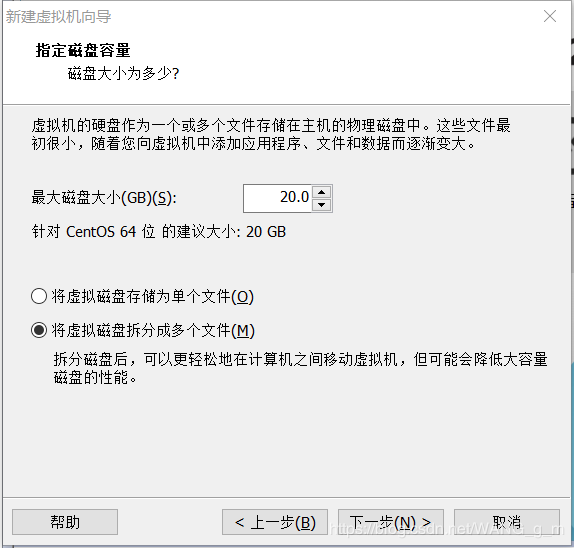
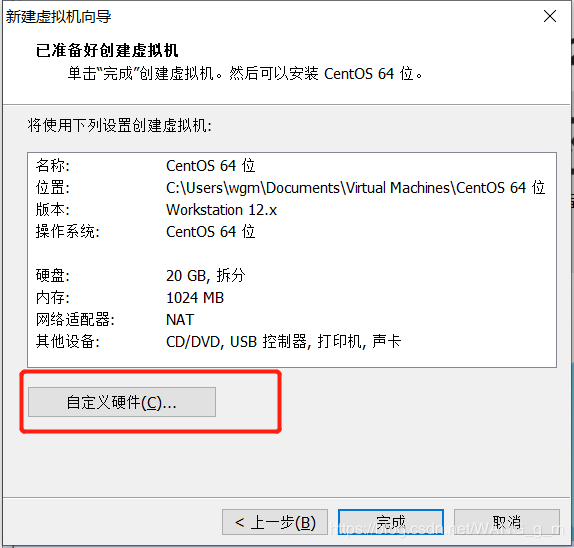 这里需要注意一下
这里需要注意一下

2.添加hadoop用户到系统用户
安装好Ubuntu之后,我们正式开始配置hadoop——添加一个名为hadoop到系统用户,专门用来做Hadoop测试
~$ sudo addgroup hadoop
~$ sudo adduser --ingroup hadoop hadoop
然后输入如下命令,使新建立的hadoop账户拥有最高的权限
~$ sudo gedit /etc/sudoers
在打开的文件中,在root下面加入下面一行。
hadoop ALL=(ALL:ALL) ALL
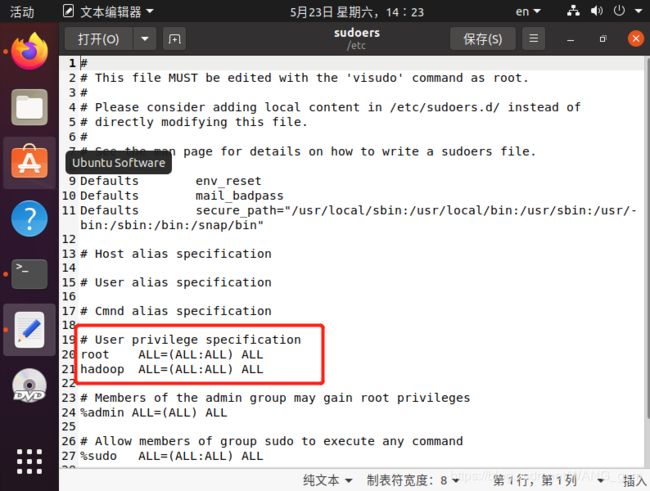 这里需要注意:如果手动敲入这行内容,hadoop后面跟的是/t,也就是键盘的Tab,如果这里输入不对的话会导致Ubuntu系统出现很大的问题。
这里需要注意:如果手动敲入这行内容,hadoop后面跟的是/t,也就是键盘的Tab,如果这里输入不对的话会导致Ubuntu系统出现很大的问题。
然后保存退出即可
3.安装ssh
接下来配置ssh服务,使系统可以远程登录。
先安装ssh
~$ sudo apt-get install openssh-server
ssh安装完成以后,先启动服务
~$ sudo /etc/init.d/ssh start
启动后,可以通过如下命令查看服务是否正确启动
~$ ps -e | grep ssh
 接下来我们要设置成免密码登录,生成私钥和公钥
接下来我们要设置成免密码登录,生成私钥和公钥
~$ ssh-keygen -t rsa -P ""
 因为我已有私钥,所以会提示是否覆盖当前私钥。第一次操作时会提示输入密码,按Enter直接过,这时会在~/home/{username}/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥,现在我们将公钥追加到authorized_keys中(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
因为我已有私钥,所以会提示是否覆盖当前私钥。第一次操作时会提示输入密码,按Enter直接过,这时会在~/home/{username}/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥,现在我们将公钥追加到authorized_keys中(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
~$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
在可以登入ssh确认以后登录时不用输入密码,如果后续jps有问题,即说明ssh无密码登录设置失败
~$ ssh localhost

退出
~$ exit
然后我们再次登录试一下是否设置无密码登录成功
~$ ssh localhost
结果和上面一样即可,这样我们以后登录ssh就不需要密码了
4.安装java环境
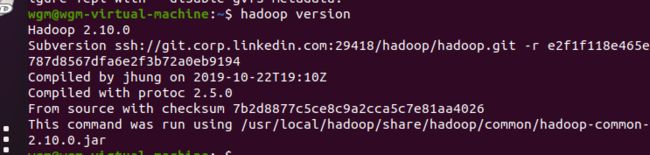
~$ sudo apt-get install openjdk-8-jdk
~$ java -version
这里openjdk-8-jdk是我们ubuntu自带的jdk,下载成功如下图(根据自己的jdk版本对照)

5.安装hadoop
hadoop官网安装hadoop
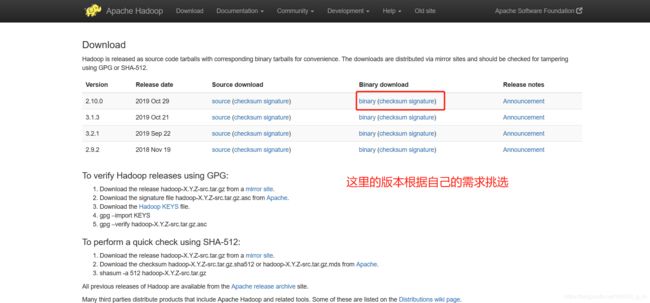
 然后解压并放到你希望的目录中,我的是放到/usr/local/hadoop
然后解压并放到你希望的目录中,我的是放到/usr/local/hadoop
~$ sudo tar xzf hadoop-1.0.2.tar.gz
~$ sudo mv hadoop-1.0.2 /usr/local/hadoop
接下来给前面建立的hadoop用户赋予相关的权限,否则hadoop用户无法配置这个目录下面的文件。
~$ sudo chown -R hadoop:hadoop /usr/local/hadoop
6.配置单击模式
接下来把这个配置到bashrc中,输入如下命令
~$ sudo gedit ~/.bashrc
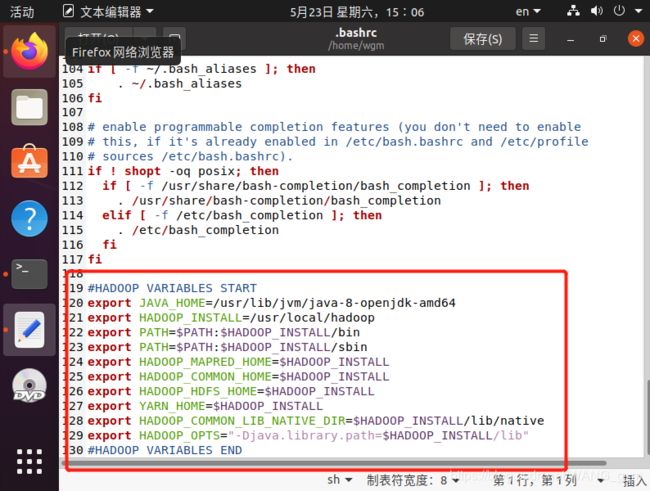
系统会打开Gedit,然后把如下内容附加到文件的末尾
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop
export PATH= P A T H : PATH: PATH:HADOOP_INSTALL/bin
export PATH= P A T H : PATH: PATH:HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME= H A D O O P I N S T A L L e x p o r t H A D O O P C O M M O N H O M E = HADOOP_INSTALL export HADOOP_COMMON_HOME= HADOOPINSTALLexportHADOOPCOMMONHOME=HADOOP_INSTALL
export HADOOP_HDFS_HOME= H A D O O P I N S T A L L e x p o r t Y A R N H O M E = HADOOP_INSTALL export YARN_HOME= HADOOPINSTALLexportYARNHOME=HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR= H A D O O P I N S T A L L / l i b / n a t i v e e x p o r t H A D O O P O P T S = " − D j a v a . l i b r a r y . p a t h = HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path= HADOOPINSTALL/lib/nativeexportHADOOPOPTS="−Djava.library.path=HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
 接下来通过如下命令使配置生效。接下来通过如下命令使配置生效。
接下来通过如下命令使配置生效。接下来通过如下命令使配置生效。
~$ source ~/.bashrc
然后设定hadoop-env.sh
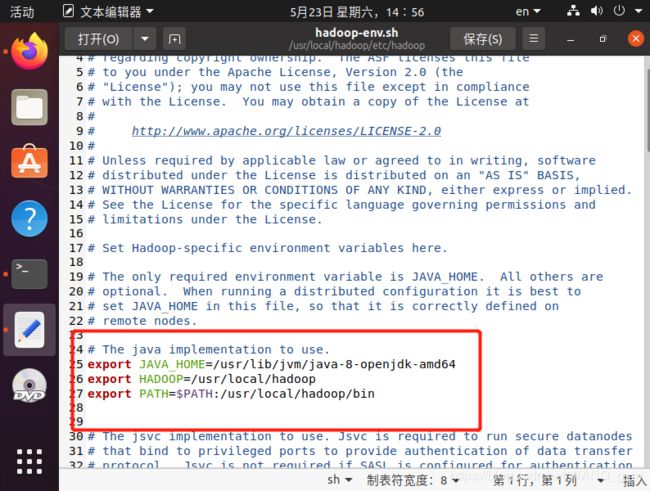
~$ sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 (视你机器的java安装路径而定)
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:/usr/local/hadoop/bin
 让环境变量配置生效source
让环境变量配置生效source
~$ source /usr/local/hadoop/conf/hadoop-env.sh
至此,hadoop的单机模式大功告成!!!
运行一下hadoop自带的例子WordCount来感受以下MapReduce过程
在hadoop目录下新建input文件夹
首先我们定位到hadoop目录
~$ cd /usr/local/hadoop
然后创建input目录
~$ mkdir input
如果不行用sudo提高权限
将README.txt文件夹复制到input文件夹下
~$ sudo cp README.txt input
最后运行一下命令
~$ sudo bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.10.0-sources.jar org.apache.hadoop.examples.WordCount input output
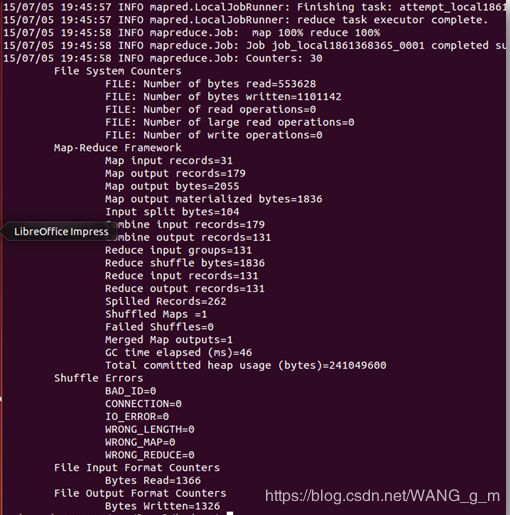 我们运行看一下结果
我们运行看一下结果
~$ cat output/*
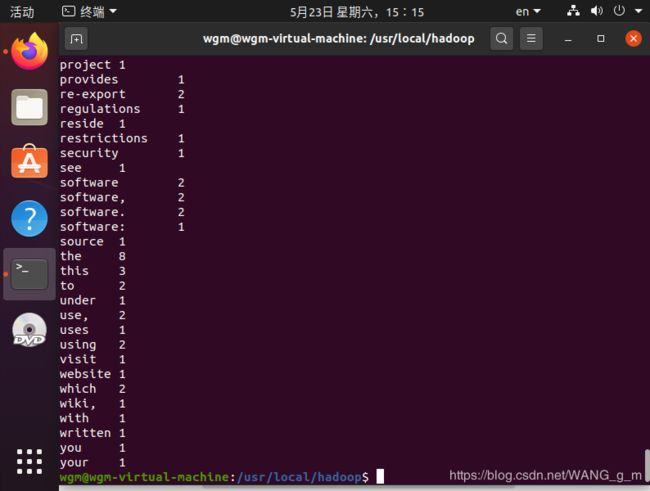
7.配置伪分布模式
首先在hadoop目录下新建几个文件夹
~$ sudo mkdir /usr/local/hadoop/tmp
~$ sudo mkdir /usr/local/hadoop/hdfs
~$ sudo mkdir /usr/local/hadoop/hdfs/name
~$ sudo mkdir /usr/local/hadoop/hdfs/data
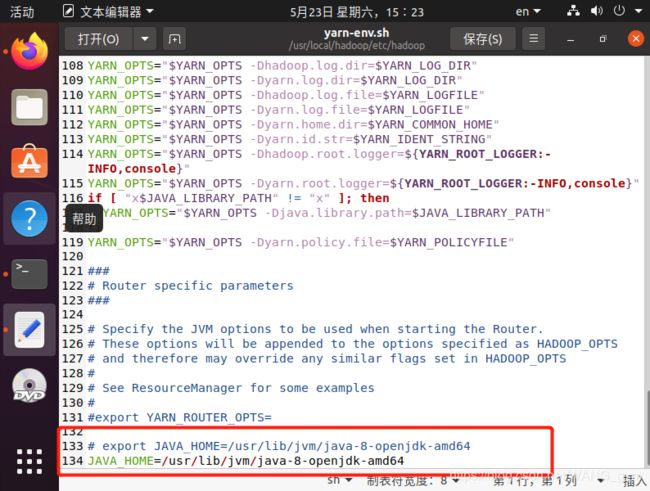
配置yarn-env.sh
~$ sudo gedit /usr/local/hadoop/etc/hadoop/yarn-env.sh
添加如下内容:
#export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
 配置core-site.xml
配置core-site.xml
~$ sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
插入如下内容
注意:将core-site.xml中原来的有的 < /configuration >一定要删除掉,不然后面格式化的时候会出错。即.xml文件中只有一对
fs.default.name
hdfs://localhost:9000
hadoop.tmp.dir
/usr/local/hadoop/tmp
Abase for other temporary directories.
启动HDFS为分布式模式 显示进程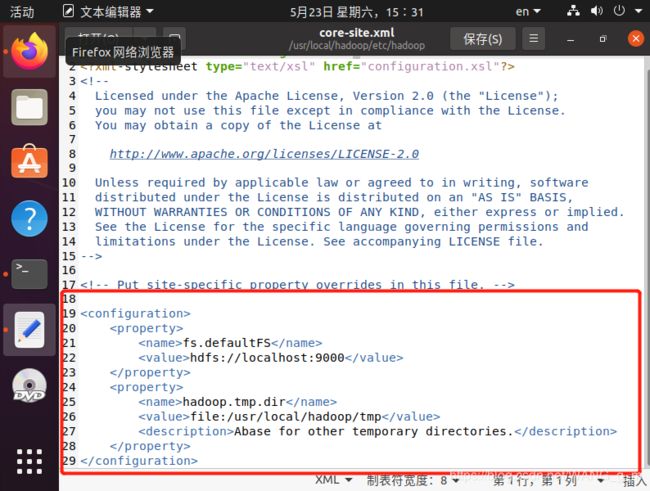 同样修改配置文件 hdfs-site.xml
同样修改配置文件 hdfs-site.xml
插入下列内容:(删除原有的 同理配置yarn-site.xml
同理配置yarn-site.xml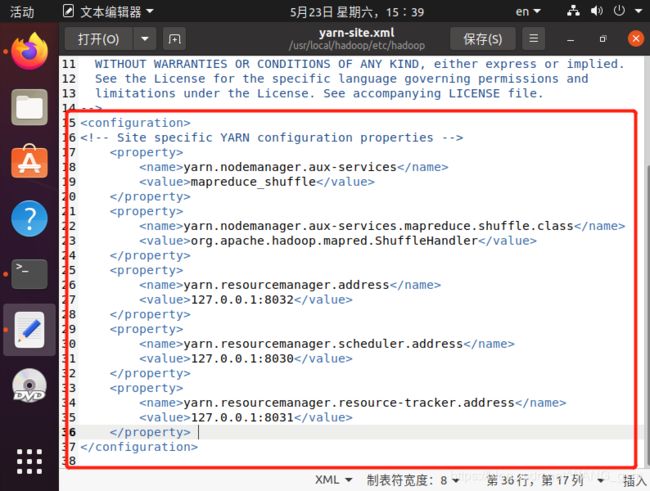 最后我们输入一下命令修改hadoop的权限
最后我们输入一下命令修改hadoop的权限 ~$ sudo chmod 777 -R /usr/local/hadoop
8.最后我们检验hadoop是否安装成功
每次开机都需要格式化namenode~$ hdfs namenode -format
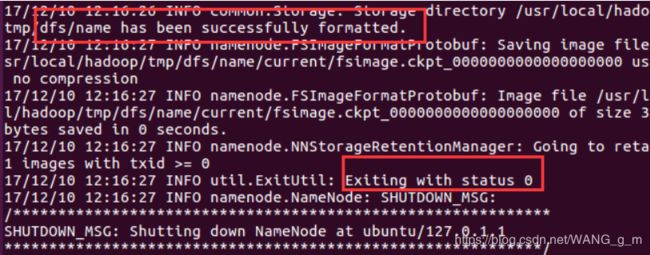 启动hdfs
启动hdfs ~$ start-all.sh
~$ jps
 有6个进程代表正确
有6个进程代表正确
在浏览器中输入http://localhost:50070/,出现如下页面
 输入 http://localhost:8088/, 出现如下页面
输入 http://localhost:8088/, 出现如下页面
