Stata:多元 Logit 模型详解 (mlogit)
作者:黄欣怡 (中山大学)
邮箱:[email protected]
「Source:MULTINOMIAL LOGISTIC REGRESSION | STATA DATA ANALYSIS EXAMPLES」
Stata连享会 计量专题 || 精品课程 || 简书推文 || 公众号合集

连享会计量方法专题……
1. 应用背景
在实证研究中,我们会遇到被解释变量为类别变量的情形。在部分情境下,被解释变量为非此即彼的二元选择变量 (如是否考取大学、是否结婚等),即我们熟知的0-1变量,此时应采用二元 Logit 模型进行估计;但在很多情形中,被解释变量涉及 3 种以上的类别变量。
例如:
- 人们的职业选择可能受到父母职业及其受教育水平的影响。我们可以探究一个个体的职业选择与父亲职业选择的相关关系,其中被解释变量职业选择包括了多种职业类别。
- 进入高中后学生可以自由选择综合课程、职业课程和学术课程。他们的选择可能受其写作成绩和社会经济地位的影响。
在这些情境下,我们需要采用多元 Logit 模型进行估计。
2. 多元 Logit 模型
多元 Logit 模型实质上可视为二元 Logit 模型的拓展,具体二元 Logit 模型的使用可参考阅读 Stata 连享会 推文 : Logit 模型简介。两者的差异在于,二元 Logit 模型的被解释变量只有 0 和 1 两个取值,而多元 Logit 模型涉及了被解释变量有多个取值的情形。
2.1 模型设定
多元 Logit 模型可视为对被解释变量中各类选择行为两两配对后构成的多个二元 Logit 模型实施联合估计 ( simultaneously estimation )。模型设定具体如下:
l n ( π i j π i b ) = l n ( P ( y i = j ∣ x ) P ( y i = b ∣ x ) ) = x i ′ β j ln\left(\frac{\pi_{ij}}{\pi_{ib}}\right) = ln\left(\frac{P(y_i=j\,|\,x)}{P(y_i=b\,|\,x)}\right) =x'_i\beta_j ln(πibπij)=ln(P(yi=b∣x)P(yi=j∣x))=xi′βj
其中, b b b为选定的基准组,设定 J J J为类别变量包含的种类总数,则 j = 1 , 2 , 3 … , J j=1,2,3\ldots ,J j=1,2,3…,J。当 j = b j=b j=b时,等式左侧为 l n 1 = 0 ln1=0 ln1=0,则 β b = 0 \beta_b=0 βb=0。即某种选择相对自己的 log-odds 始终为 0,致使该组别对应的任何解释变量系数也必然为0。
通过求解这 J J J个方程,可以得到每种选择的预测概率:
π i j = P ( y i = j ∣ x ) = e x p ( x i ′ β j ) ∑ m = 1 J e x p ( x i ′ β m ) \pi_{ij}=P(y_i=j\,|\,x) =\frac{exp(x'_i\beta_j)}{\sum_{m=1}^J{exp(x'_i\beta_m)}} πij=P(yi=j∣x)=∑m=1Jexp(xi′βm)exp(xi′βj)
2.2 模型系数解读
2.2.1 基于胜算比 (odds) 角度的解读
在因变量含有 J J J个组别并有 k k k个解释变量 (包含常数项) 的多元 Logit 模型中,我们共有$ (J-1)\times k$个参数,这使得模型的解读更为复杂。首先,Logit 模型估计的关键在于选定基准组 ( base group ),所有系数均是相对于基准组进行估计;其次,我们通常从概率的角度出发对 Logit 模型进行解读。与二元 Logit 模型相似,基于胜算比 (odds) 对模型参数进行解释能够使模型更加简明易懂。
我们假设选定的基准组 ( base group ) 为第 1 组,那么第 j j j个组别相对于基准组的胜算比 (odds) 可以表示为:
π i j π i 1 = P ( y i = j ∣ x ) P ( y i = 1 ∣ x ) = e x p ( x i ′ β j ) j = 2 , … , J \frac{\pi_{ij}}{\pi_{i1}}= \frac{P(y_i=j\,|\,x)}{P(y_i=1\,|\,x)} =exp(x'_i\beta_j) \qquad j=2,\ldots ,J πi1πij=P(yi=1∣x)P(yi=j∣x)=exp(xi′βj)j=2,…,J
那么第 l l l个解释变量的变化对该胜算比的影响 ( factor change ) 可表示为:
e x p ( x i ′ β j + Δ x i l β j l ) e x p ( x i ′ β j ) = e x p ( Δ x i l β j l ) \frac{exp(x'_i\beta_j+\Delta{x_{il}\beta_{jl}})}{exp(x'_i\beta_j)}= exp(\Delta{x_{il}\beta_{jl}}) exp(xi′βj)exp(xi′βj+Δxilβjl)=exp(Δxilβjl)
其中, β j l \beta_{jl} βjl为第 j j j组别系数向量 β j \beta_j βj中的第 l l l个元素。该表达式表明,保持其他解释变量不变, x i l x_{il} xil每增加一个单位,即 Δ x i l = 1 \Delta x_{il}=1 Δxil=1时,选择第 j j j组别相对于基准组的胜算比变化为 e x p ( β j l ) exp(\beta_{jl}) exp(βjl) ( factor change )。由此可见,当且仅当 β j l > 0 \beta_{jl} >0 βjl>0时,第 j j j组别相对于基准组的胜算比大于 1,并且 x i l x_{il} xil的增加能够提升选择第 j j j组别相对于基准组的胜算比。
我们可以进一步将等式一般化得到第 j j j组别相对于第 m m m组别的胜算比:
π i j π i m = e x p [ x i ′ ( β j − β m ) ] ∀ j ≠ m \frac{\pi_{ij}}{\pi_{im}}=exp[x'_i(\beta_j-\beta_m)] \qquad \forall j \not= m πimπij=exp[xi′(βj−βm)]∀j=m
第 l l l个解释变量 x i l x_{il} xil的变化 Δ x i l \Delta x_{il} Δxil会引起第第 j j j组别相对于第 m m m组别的胜算比发生 e x p [ Δ x i l ( β j l − β m l ) ] exp[\Delta x_{il}(\beta_{jl}-\beta_{ml})] exp[Δxil(βjl−βml)]的比率变化 ( factor change )。当且仅当 β j l > β m l \beta_{jl}>\beta_{ml} βjl>βml时, x i x_i xi的增加能够提高选择 j j j组别相对于选择 m m m组别的概率。
以上衡量的是第 j j j组别胜算比在 x i x_i xi发生变化后相对于原胜算比的比率变化 ( factor change ),若我们想要衡量第 j j j组别相对于基准组胜算比在 x i x_i xi发生变化前后的相对变化,则可以得到以下表达式:
e x p ( x i ′ β j + Δ x i l β j l ) − e x p ( x i ′ β j ) e x p ( x i ′ β j ) = e x p ( Δ x i l β j l ) − 1 \frac{exp(x'_i\beta_j+\Delta{x_{il}\beta_{jl}})-exp(x'_i\beta_j)}{exp(x'_i\beta_j)}= exp(\Delta{x_{il}\beta_{jl}})-1 exp(xi′βj)exp(xi′βj+Δxilβjl)−exp(xi′βj)=exp(Δxilβjl)−1
x i x_i xi增加一个单位,即 Δ x i l = 1 \Delta x_{il}=1 Δxil=1时,第 j j j组别相对于基准组胜算比的相对变化幅度为 e x p ( β j l ) − 1 exp(\beta_{jl})-1 exp(βjl)−1,当 β j l \beta_{jl} βjl很小时, e x p ( β j l ) − 1 ≈ β j l exp(\beta_{jl})-1\approx \beta_{jl} exp(βjl)−1≈βjl,此时系数 β j l \beta_{jl} βjl具有更为直观的含义。
2.2.2 基于概率的解读
以上主要从胜算比 (odds) 的角度对 Logit 模型进行解读。胜算比 (odds) 反映了不同组别发生概率的比值,但我们更为关注各组别发生概率本身的变化,而非其相对水平的变化。
当第 l l l个解释变量发生 Δ x i l \Delta x_{il} Δxil个单位的变化时,我们可以将各组别发生概率的变化表示为:
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ \begin{aligned…
我们不难看出, Δ x i l \Delta x_{il} Δxil引起的组别 j j j发生概率的变化方向不一定与其系数 β j l \beta_{jl} βjl保持一致,总体而言 Δ π i j \Delta \pi_{ij} Δπij的符号是模糊的。
需要注意的是,所有组别发生概率之和为 1,因此各组别发生概率的变化呈现出此消彼长的规律,而某一组别的概率变化也可以由其他 J − 1 J-1 J−1个组别决定,由此我们可以得到:
Δ π i 1 = − ∑ j = 2 J Δ π i j \Delta \pi_{i1}=-\sum_{j=2}^{J}\Delta\pi_{ij} Δπi1=−j=2∑JΔπij
对于连续型解释变量而言,我们可以直接通过求导得到该变量变化对某一组别发生概率产生的边际效应:
M P E i 1 l = ∂ π 1 j ∂ x i l = − π i 1 ∑ m = 2 J π i m β m l MPE_{i1l}=\frac{\partial \pi_{1j}}{\partial x_{il}}=-\pi_{i1} \sum_{m=2}^{J}\pi_{im}\beta_{ml} MPEi1l=∂xil∂π1j=−πi1m=2∑Jπimβml
M P E i j l = ∂ π i j ∂ x i l = π i j ( β j l − ∑ m = 2 J π i m β m l ) j = 2 , … , J MPE_{ijl}=\frac{\partial \pi_{ij}}{\partial x_{il}}=\pi_{ij} (\beta_{jl}-\sum_{m=2}^{J}\pi_{im}\beta_{ml}) \qquad j=2,\dots,J MPEijl=∂xil∂πij=πij(βjl−m=2∑Jπimβml)j=2,…,J
由以上两个表达式可以看出第 l l l个解释变量变化对第 j j j组别发生概率产生的边际效应不仅取决于 β j l \beta_{jl} βjl,同时还受到其他组别估计系数 β m l \beta_{ml} βml的影响,因此 M P E i j l MPE_{ijl} MPEijl的符号也是不确定的。但解释变量对各组别发生概率的边际效应存在以下规律:
∑ j = 1 J M P E i j l = 0 \sum_{j=1}^{J}MPE_{ijl}=0 j=1∑JMPEijl=0
在实证研究中,我们常用最大似然法对多元 Logit 模型进行估计。在模型解读中,我们通常采用平均边际效应 ( average marginal probability effects ) 来衡量解释变量对各组别发生概率产生的影响:
A M P E j l ^ = 1 n ∑ i = 1 n M P E i j l ^ j = 1 , … , J \widehat{AMPE_{jl}}=\frac{1}{n}\sum_{i=1}^{n}\widehat{MPE_{ijl}} \qquad j=1,\dots ,J AMPEjl =n1i=1∑nMPEijl j=1,…,J
一方面,我们通过计算平均预测概率及其标准差、或最大预测概率和最小预测概率对模型进行解读。另一方面,我们也可以通过绘制某一解释变量在不同取值下对应的预测概率的线形图 (其他解释变量取均值) 以描述该变量对发生概率的影响。
连享会计量方法专题…… || https://gitee.com/arlionn/Course
3. 应用实例
我们通过高中生进行课程选择的案例介绍多元 Logit 模型的应用。
3.1 数据结构描述
在本案例中,被解释变量prog是高中生样本个体选择参加的课程项目:「prog:1 综合项目 (general);2 学术项目 (academic); 3 职业项目 (vocation)」;解释变量包括被观测样本的社会经济地位 ses (类别变量:1 低等;2 中等;3 高等) 以及写作成绩 write (连续变量)。
我们分别通过tab命令和table命令对变量进行描述性统计,对解释变量与被解释变量之间的相关关系进行初步判断。卡方检验表明 prog 和 ses 两个变量存在相关关系;此外,选择参加学术课程项目的高中生平均写作成绩最高,而选择参加职业课程项目的高中生平均写作成绩最低。
use https://stats.idre.ucla.edu/stat/data/hsbdemo, clear
tab prog ses, chi2
type of | ses
program | low middle high | Total
-----------+---------------------------------+----------
general | 16 20 9 | 45
academic | 19 44 42 | 105
vocation | 12 31 7 | 50
-----------+---------------------------------+----------
Total | 47 95 58 | 200
Pearson chi2(4) = 16.6044 Pr = 0.002
table prog, con(mean write sd write)
------------------------------------
type of |
program | mean(write) sd(write)
----------+-------------------------
general | 51.33333 9.397776
academic | 56.25714 7.943343
vocation | 46.76 9.318754
------------------------------------
3.2 模型估计
我们采用mlogit命令估计多元回归模型。ses 变量前的i.标识表明该变量为类别变量,base选项帮助我们选定模型估计的基准组,此处我们将「学术课程项目」( ses=2 ) 作为基准组。
mlogit prog i.ses write, base(2)
Iteration 0: log likelihood = -204.09667
Iteration 1: log likelihood = -180.80105
Iteration 2: log likelihood = -179.98724
Iteration 3: log likelihood = -179.98173
Iteration 4: log likelihood = -179.98173
Multinomial logistic regression Number of obs = 200
LR chi2(6) = 48.23
Prob > chi2 = 0.0000
Log likelihood = -179.98173 Pseudo R2 = 0.1182
------------------------------------------------------------------------------
prog | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
general |
ses |
middle | -.533291 .4437321 -1.20 0.229 -1.40299 .336408
high | -1.162832 .5142195 -2.26 0.024 -2.170684 -.1549804
|
write | -.0579284 .0214109 -2.71 0.007 -.0998931 -.0159637
_cons | 2.852186 1.166439 2.45 0.014 .5660075 5.138365
-------------+----------------------------------------------------------------
academic | (base outcome)
-------------+----------------------------------------------------------------
vocation |
ses |
middle | .2913931 .4763737 0.61 0.541 -.6422822 1.225068
high | -.9826703 .5955669 -1.65 0.099 -2.14996 .1846195
|
write | -.1136026 .0222199 -5.11 0.000 -.1571528 -.0700524
_cons | 5.2182 1.163549 4.48 0.000 2.937686 7.498714
------------------------------------------------------------------------------
- 在输出结果中,
iteration log显示了多元 logit 模型的收敛速度,经过4次迭代后我们得到 MLE 估计量。输出结果中的对数似然值 (Log likelihood = -179.98173) 可用于嵌套模型的比较。 - 这里计算出的似然比统计量
LR chi2(6) = 48.23是评估模型拟合程度的指标,检验了除常数项外所有变量的联合显著性,Prob > chi2 = 0.0000表明与仅包含常数项的模型相比,该模型从整体而言具有更好的拟合优度。 - 模型估计的输出结果主要包括 general 和 vocation 两部分 ( academic 是基准组) 。实质上,多元 logit 模型可视为 prog 变量中的 3 种选择行为两两配对后构成的 2 个二元 logit 模型实施联合估计 ( simultaneously estimation ),它们分别对应以下两个方程:
l n ( P ( p r o g = g e n e r a l ) P ( p r o g = a c a d e m i c ) ) = b 10 + b 11 ( s e s = 2 ) + b 12 ( s e s = 3 ) + b 13 w r i t e ln\left(\frac{P(prog=general)}{P(prog=academic)}\right) = b_{10} + b_{11}(ses=2) + b_{12}(ses=3) + b_{13}write ln(P(prog=academic)P(prog=general))=b10+b11(ses=2)+b12(ses=3)+b13write
l n ( P ( p r o g = v o c a t i o n ) P ( p r o g = a c a d e m i c ) ) = b 20 + b 21 ( s e s = 2 ) + b 22 ( s e s = 3 ) + b 23 w r i t e ln\left(\frac{P(prog=vocation)}{P(prog=academic)}\right) = b_{20} + b_{21}(ses=2) + b_{22}(ses=3) + b_{23}write ln(P(prog=academic)P(prog=vocation))=b20+b21(ses=2)+b22(ses=3)+b23write
其中 b j k b_{jk} bjk是输出结果的估计系数,具体解读如下:
- 变量 write 每增加一个单位,个体选择参加综合课程相对于学术课程的胜算比对数 ( log odds ) 将减少 0.058。
- 变量 write 每增加一个单位,个体选择参加职业课程相对于学术课程的胜算比对数 ( log odds ) 将减少 0.1136。
- 与社会经济地位最低 ( ses=1 ) 的高中生个体相较,社会经济地位最高( ses=3 )的个体选择参加职业课程相对于学术课程的胜算比对数 ( log odds ) 将减少 1.163 。
使用 mlogit 模型只能获得各组类别相对于基准组 ( academic ) 的估计系数 ( log odds ),该估计系数的经济含义解释显然不够直观。在实践中,我们更常用到的指标是胜算比 ( odds ),即选择某一类课程的概率与选择基准组 academic 的概率的比值,这一指标也被称为相对风险 ( relative risk ),可以通过对估计系数取幂得到。相对风险系数的经济含义是解释变量变化一个单位所引起的某类选择相对于基准组选择胜算比的变化。若附加rrr选项,「Stata」的输出结果则会列示出所有系数估计值对应的胜算比,即e^b( odds ratio ) 。
mlogit, rrr
Multinomial logistic regression Number of obs = 200
LR chi2(6) = 48.23
Prob > chi2 = 0.0000
Log likelihood = -179.98173 Pseudo R2 = 0.1182
------------------------------------------------------------------------------
prog | RRR Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
general |
ses |
middle | .586671 .2603248 -1.20 0.229 .2458607 1.39991
high | .3125996 .1607448 -2.26 0.024 .1140996 .856432
|
write | .9437175 .0202059 -2.71 0.007 .9049342 .984163
_cons | 17.32562 20.20928 2.45 0.014 1.761221 170.4369
-------------+----------------------------------------------------------------
academic | (base outcome)
-------------+----------------------------------------------------------------
vocation |
ses |
middle | 1.338291 .6375264 0.61 0.541 .5260904 3.404399
high | .3743103 .2229268 -1.65 0.099 .1164888 1.202761
|
write | .8926126 .0198338 -5.11 0.000 .8545734 .9323449
_cons | 184.6016 214.793 4.48 0.000 18.87213 1805.719
------------------------------------------------------------------------------
连享会计量方法专题…… || https://gitee.com/arlionn/Course
3.3 假设检验
3.3.1 检验系数的显著性
由于多元 Logit 模型具有联立方程的特征,因此需要进行一些以组别为基础的检验。要检验某个变量是否显著,需要联合检验 J-1 ( J 表示组别个数 ) 个系数是否同时不为 0。在本案例中,若检验个体社会经济地位 ( ses ) 对课程类型选择 ( prog ) 是否产生显著影响,则需要分别检验 ses = 2 与 ses = 3 两个虚拟变量在 general 和 vocation 2 个组别中的估计系数是否显著异于 0 。
我们可以通过 LR 检验估计系数的显著性。由于 LR 检验需要估计限制性与非限制性两个模型,因此当模型较为复杂或样本数较大时,该检验会非常耗时,甚至无法执行,此时应进行 Wald 检验。以下采取lrtest命令检验 ses 是否对个体课程选择 prog 产生显著影响,结果同样表明变量 ses 对个体课程选择 prog 的影响是显著的。
qui mlogit prog i.ses write, base(2)
est store mFull
qui mlogit prog write, base(2)
est store m0
lrtest mFull m0
Likelihood-ratio test LR chi2(4) = 11.06
(Assumption: m0 nested in mFull) Prob > chi2 = 0.0259
我们也可以采用 test 命令执行 Wald 检验,在 Wald 检验下我们只需估计无限制模型即可。从以下检验结果可以看出变量 ses 对个体课程选择 prog 的影响是显著的。
test 2.ses 3.ses
( 1) [general]2.ses = 0
( 2) [academic]2o.ses = 0
( 3) [vocation]2.ses = 0
( 4) [general]3.ses = 0
( 5) [academic]3o.ses = 0
( 6) [vocation]3.ses = 0
Constraint 2 dropped
Constraint 5 dropped
chi2( 4) = 10.82
Prob > chi2 = 0.0287
3.3.2 组间无差异检验
在某些情况下,解释变量对两个甚至多个组别的影响具有相近的效果。此时,需要进行“无差异检验”。同样地,这一检验可以通过 Wald 检验和 LR 检验实现。
在本案例中,我们试图检验虚拟变量 ses = 3 对于 general 组别和 vocation 组别的影响差异。Wald检验的结果显示,ses = 3 对于 general 组别和 vocation 组别的影响是相近的。
test [general]3.ses = [vocation]3.ses
( 1) [general]3.ses - [vocation]3.ses = 0
chi2( 1) = 0.08
Prob > chi2 = 0.7811
3.4 预测概率值与概率值的图形显示
我们可以通过预测个体在特定条件下的概率以帮助我们更好地解读模型。我们通过执行margins命令获得样本内的预测概率。在本案例中,我们利用atmeans将除 ses 以外的其他变量设定为样本均值,分别比较不同社会经济地位 ses 对高中生选择不同课程 prog 的预测概率。我们需要重复三次使用margins命令以得到 prog 中不同组别 ( general, median, vocation ) 层级分别对应的预测概率。此处省略输出结果。
在呈现结果时,利用图表来呈现会更加方便明了,因此我们采用marginsplot命令绘制了 ses 对不同 prog 类别的预测概率。其中marginsplot命令绘制的散点图是基于前面执行的margins命令,如下图所示。在绘制的同时我们对每一张图表命名以便于后续的图表合并,最终我们采用graph combine命令将三张图表合并在一起,ycommon选项的添加能够使三张图表的 y 轴显示范围保持一致,从而使图表更加美观。
margins ses, atmeans predict(outcome(1))
marginsplot, name(general)
margins ses, atmeans predict(outcome(2))
marginsplot, name(academic)
margins ses, atmeans predict(outcome(3))
marginsplot, name(vocational)
graph combine general academic vocational, ycommon

下文我们进一步考察连续变量 write 在不同取值情况下对应的平均预测概率,平均预测概率为不同 ses 层级对应的预测概率的平均值。主要输出结果如下所示:
margins, at(write = (30(10) 70)) predict(outcome(1)) vsquish
Predictive margins Number of obs = 200
Model VCE : OIM
Expression : Pr(prog==general), predict(outcome(1))
1._at : write = 30
2._at : write = 40
3._at : write = 50
4._at : write = 60
5._at : write = 70
------------------------------------------------------------------------------
| Delta-method
| Margin Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
_at |
1 | .2130954 .0774327 2.75 0.006 .0613302 .3648606
2 | .2569932 .0529761 4.85 0.000 .1531619 .3608245
3 | .2543008 .0336297 7.56 0.000 .1883878 .3202138
4 | .2057855 .0371536 5.54 0.000 .1329658 .2786052
5 | .1423089 .0481683 2.95 0.003 .0479007 .2367172
------------------------------------------------------------------------------
margins, at(write = (30(10) 70)) predict(outcome(2)) vsquish
Predictive margins Number of obs = 200
Model VCE : OIM
Expression : Pr(prog==academic), predict(outcome(2))
1._at : write = 30
2._at : write = 40
3._at : write = 50
4._at : write = 60
5._at : write = 70
------------------------------------------------------------------------------
| Delta-method
| Margin Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
_at |
1 | .1348408 .0525979 2.56 0.010 .0317507 .2379308
2 | .2808143 .0553213 5.08 0.000 .1723867 .389242
3 | .4773283 .0397591 12.01 0.000 .399402 .5552547
4 | .6680752 .0434689 15.37 0.000 .5828776 .7532727
5 | .8075124 .0545504 14.80 0.000 .7005956 .9144291
------------------------------------------------------------------------------
margins, at(write = (30(10) 70)) predict(outcome(3)) vsquish
Predictive margins Number of obs = 200
Model VCE : OIM
Expression : Pr(prog==vocation), predict(outcome(3))
1._at : write = 30
2._at : write = 40
3._at : write = 50
4._at : write = 60
5._at : write = 70
------------------------------------------------------------------------------
| Delta-method
| Margin Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
_at |
1 | .6520638 .0944041 6.91 0.000 .4670353 .8370924
2 | .4621925 .0614388 7.52 0.000 .3417747 .5826102
3 | .2683708 .0342932 7.83 0.000 .2011575 .3355842
4 | .1261393 .03019 4.18 0.000 .0669679 .1853107
5 | .0501787 .0216863 2.31 0.021 .0076744 .092683
------------------------------------------------------------------------------
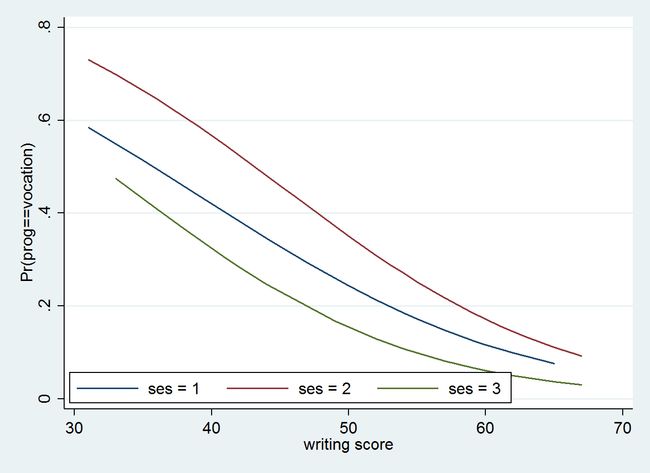
我们也可以通过图形的方式更为清晰明了地显示预测概率的结果。以下我们通过twoway命令绘制不同写作水平 write 对应的各 ses 层级下的平均预测概率,具体输出图表如下所示。
predict p1 p2 p3
sort write
twoway (line p1 write if ses ==1) (line p1 write if ses==2) (line p1 write if ses ==3), ///
legend(order(1 "ses = 1" 2 "ses = 2" 3 "ses = 3") ring(0) position(7) row(1))
twoway (line p2 write if ses ==1) (line p2 write if ses==2) (line p2 write if ses ==3), ///
legend(order(1 "ses = 1" 2 "ses = 2" 3 "ses = 3") ring(0) position(7) row(1))
twoway (line p3 write if ses ==1) (line p3 write if ses==2) (line p3 write if ses ==3), ///
legend(order(1 "ses = 1" 2 "ses = 2" 3 "ses = 3") ring(0) position(7) row(1))


连享会计量方法专题…… || https://gitee.com/arlionn/Course
3.5 拟合优度
对于 Logit 模型,我们采用 Pseudo-R2 评估线性模型的拟合优度,通常包括 McFadden’s R2、Maximum likelihood R2、Cragg & Uhler’s R2、Efron’s R2、AIC 和 BIC。mlogit命令的默认输出结果为 McFadden’s R2。McFadden’s R2 也称为似然比指数,其检验基本思想在于比较仅包含常数项的模型和包含所有解释变量的模型之间的对数似然值的相对大小。该值越大表明模型的拟合程度越高。我们也可以采用fitstat命令列示其他衡量模型拟合优度的统计量。
fitstat
Measures of Fit for mlogit of prog
Log-Lik Intercept Only: -204.097 Log-Lik Full Model: -179.982
D(185): 359.963 LR(6): 48.230
Prob > LR: 0.000
McFadden's R2: 0.118 McFadden's Adj R2: 0.045
Maximum Likelihood R2: 0.214 Cragg & Uhler's R2: 0.246
Count R2: 0.545 Adj Count R2: 0.042
AIC: 1.950 AIC*n: 389.963
BIC: -620.225 BIC': -16.440
3.6 其他思考
- 需要注意的是,多元 Logistic 模型采用最大似然法进行估计,并且具有联立方程的特征,因此与二元 Logistic 模型相较其对大样本的要求更高。
- 在某些情况下,虽然样本容量足够大,但却无法收敛或得到的估计结果与理论预期严重偏离。这往往是因为数据还没有很好的“净化”。比如,变量的构造可能存在问题、部分离群值没有得到很好的处理。此外,变量单位的选择也是一个主要的原因:最大的标准差与最小的标准差之间的比值越大,问题就会越严重。
连享会计量方法专题…… || https://gitee.com/arlionn/Course
参考文献
- UCLA Institute for Digital Research & Education : MULTINOMIAL LOGISTIC REGRESSION | STATA DATA ANALYSIS EXAMPLES
- 钟经樊,连玉君,计量分析与 STATA 应用第十五章 Logistic 模型,版本 2.0,2010.6
- Rainer Winkelmann, Stefan Boes. Analysis of Microdata, Springer-Verlag Berlin Heidelberg, 2006.
- Stata 连享会 推文 : Logit 模型简介
关于我们
- Stata连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。
- 欢迎赐稿: 欢迎赐稿至[email protected]。录用稿件达 三篇 以上,即可 免费 获得一期 Stata 现场培训资格。
- 往期精彩推文:
Stata绘图 | 时间序列+面板数据 | Stata资源 | 数据处理+程序 | 回归分析-交乘项-内生性
