2-2、spark的union和join操作演示
spark的union和join操作演示
union简介:
通常如果我们需要将两个select语句的结果作为一个整体显示出来,我们就需要用到union或者union all关键字。union(或称为联合)的作用是将多个结果合并在一起显示出来。
Union:将两个RDD进行合并,不去重;
Join连接:
SQL中大概有这么几种JOIN:
cross join 交叉连接(笛卡尔积)
inner join 内连接
left outer join 左外连接(左面有的,右面没有的,右面填NULL)
right outer join 右外连接
full outer join 全连接
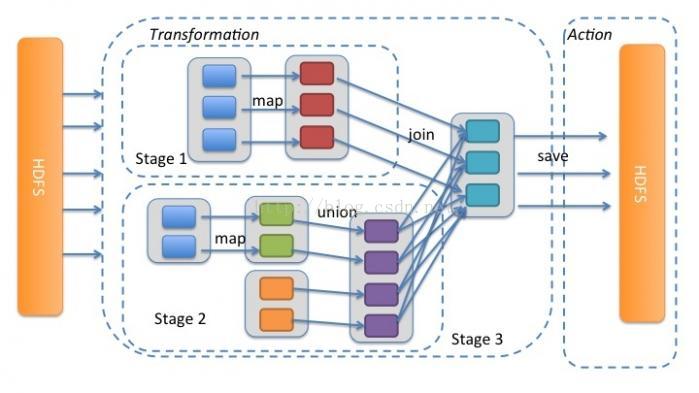
spark的union和join操作演示如下:
窄依赖:子RDD只依赖父RDD中的一个分区
宽依赖:子RDD可以依赖父RDD中的多个分区
union只能产生窄依赖
join既能产生窄依赖,也能产生宽依赖
创建rdd1:
scala> val rdd1=sc.parallelize(List(('a',2),('b',4),('c',6),('d',9)))rdd1:org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[6] at parallelizeat
创建rdd2:
scala> valrdd2=sc.parallelize(List(('c',6),('c',7),('d',8),('e',10)))rdd2:org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[7] at parallelizeat
执行union:
scala> val unionrdd=rdd1 union rdd2unionrdd: org.apache.spark.rdd.RDD[(Char,Int)] = UnionRDD[8] at union at
union结果:
scala> unionrdd.collect
res2: Array[(Char, Int)] = Array((a,2),(b,4), (c,6), (d,9), (c,6), (c,7), (d,8), (e,10))执行:join:
scala> val joinrdd=rdd1 join rdd2joinrdd: org.apache.spark.rdd.RDD[(Char,(Int, Int))] = MapPartitionsRDD[11] at join at
join结果:
scala>joinrdd.collect
res3: Array[(Char,(Int, Int))] = Array((d,(9,8)), (c,(6,6)), (c,(6,7))) 