Elasticsearch核心技术与实战学习笔记 37 | 集群分布式模型及选主与脑裂问题
一 序
本文属于极客时间Elasticsearch核心技术与实战学习笔记系列。
二 分布式特性
ES 的分布式架构带来的好处
- 储存的水平扩容,支持 PB 级数据
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
ES 的分布式架构
- 不同的集群通过不同的名字来区分,默认名字 “es”
- 通过配置文件的修改,或者在命令行中 - E cluster.name=’geektime ‘设定
2.1 节点
节点是一个 ES 的实例
- 其本质就是一个 JAVA 进程
- 一台机器可以运行多个 ES 进程,但是生产环境一般建议一台机器就运行一个 ES 实例
- 每一个节点都有名字,通过配置文件配置,或者启动时候 - E node.nam=geektime 指定
- 每一个节点在启动之后,都会分配一个 UID,保存在 data 目录下
2.2 Coordinating Node
处理请求的节点,叫 Coordinating Node
- 路由请求到正确的节点,例如创建索引的请求,需要路由到 Master 节点
所有节点默认都是 Coordinating Node
通过将其他类型设置成 False ,使其成为 Dedicated Coordinating Node
3 Demo 启动节点,Cerebro 介绍
bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data
bin/elasticsearch -E node.name=node2 -E cluster.name=geektime -E path.data=node2_data
bin/elasticsearch -E node.name=node3 -E cluster.name=geektime -E path.data=node3_data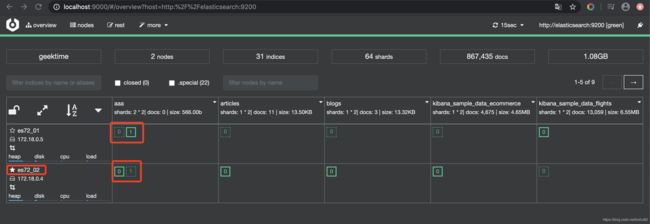
创建的索引:2个节点:02为master,索引aaa 2个分片,副本数1.
3.1 Data Node
可以保存数据的节点,叫做 Data Node
- 节点启动后,默认就是数据节点。可以设置 node.data:false 禁止
Data Node 的职责
- 保存分片数据。在数据扩展上起到了至关重要的作用(由 Master Node 决定把分片分发到数据节点上)
通过增加数据节点
- 可以解决数据水平扩展和解决数据单点的问题
3.2 Master Node
Master Node 的职责
- 处理创建,删除索引等请求 / 决定分片被分配到哪个节点 / 负责索引的创建与删除
- 维护并且更新 Cluster State
Master Node 的最佳实践
- Master 节点非常重要,在部署上需要考虑解决单点的问题
- 为一个集群设置多个 Master 节点 / 每个节点值承担 Master 的单一角色
3.3 Master Eligible Nodes & 选主流程
一个集群,支持配置多个 Master Eligble 节点。这些节点可以在必要时(如 Master 节点出现故障,网络故障时)参与选主流程,成为 Master 节点。
每个节点启动后,默认就是一个 Master eligible 节点。
- 可以设置 node.data:false
当集群内的第一个 Master eligible 节点时候,它会将自己选举成 Master 节点。
3.4 集群状态
集群状态信息(Cluster State),维护了一个集群中,必要的信息
- 所有的节点信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
在每个节点都保存了集群的状态信息
但是,只有 Master 节点才能修改集群的状态信息,并负责同步给其他节点
- 因为,任意节点都能修改信息会导致 Cluster State 信息不一致
3.5 Master Eligbile Nodes & 选主的过程
- 互相 ping 对方。Node Id 低的会被成为被选举的节点
- 其他节点会加入集群,但是不承担 Master 节点的角色。一旦发现被选中的主节点丢失,救护选举除新的 Master 节点

3.6 脑裂问题
Split-Brain ,分布式系统的经典网络问题,当出现网络问题,一个节点和其他节点无法连接
Node 2 和 Node 3 会被重新选举 Master
Node 1 自己还是作为 Master,组成一个集群,同时更新 Cluster State
导致 2 个 master,维护不同的 cluster state。当网络恢复是,无法选择正确恢复

这里老师一带而过,没有解释为什么选的node3,我有些疑惑,按照前面的说法选择节点小的应该选2,哪位大神看到可以给个解释。多谢。
3.7 如何避免脑裂问题
限定一个选举条件,这是 quorum(仲裁),只有在 Master eligble 节点数大于 quorum 时,才能进行选举
- Quorum = (master 节点总数 / 2) +1
- 当 3 个 master eligible 时,设置 discovery.zen.minimum_master_nodes 为 2 ,即可避免脑裂
从 7.0 开始,无需这个配置
- 移除 minimum_master_nodes 参数,让 ES 自己选择可以形成冲裁的节点
- 电信的主节点选举现在只需要很短的时间可以完成。集群的伸缩变得更加安全,更容易,并且可能造成丢失数据的系统配置选项更少了
- 节点更清楚的记录它们的状态,有助于诊断为什么它们不能加入集群或为什么无法选举除主节点
3.8 配置节点类型

学习了本节,就是扫盲了一些基本概念。还是迷惑。