ECCV 2020 | 智能自动零售可行吗?AI安全应引起广泛关注!

©PaperWeekly · 作者|王嘉凯
学校|北京航空航天大学博士生
研究方向|对抗样本
近年来,随着人工智能技术的发展,智能化应用在各行各业都有了广泛的应用。在与我们生活息息相关的零售领域,人工智能技术的到来极大地便利化了人们的零售购物方式,人们不在需要排队等待售货员人工扫码结账,只需要平铺所有商品,基于计算机视觉的智能零售系统便可以迅速扫描计算价格,这引起零售行业降本增效的新浪潮。
然而 AI 自动零售落地并不是一片坦途,近年来 AI 安全性问题向其发出了最严峻的挑战。
北京航空航天大学团队的最新研究成果表明,在自动零售领域核心的自动结算(Automatic Check-Out)环节,一块不大的类似商品商标的贴纸就能严重影响计算机视觉识别系统,导致其将昂贵的商品识别为非常便宜的物品。

如上图所示的带有商标或者 logo 的商品在生活中十分常见,而利用生成的类似形态的具有攻击性的对抗补丁(adversarial patch)可以让真实世界中的商品识别系统(淘宝“扫一扫”和京东“扫啊扫”)识别错误。
让我们想象一下这样的场景,当顾客在自动结算时,货物上出现了对抗补丁,原本可能只需要花 10 元钱的东西被错误识别为 100 元,顾客蒙受了损失,而对于商家而言,恶意的补丁可能导致原本应该收入 100 元的货物只收入 10 元,同样蒙受巨大损失。
因此对于自动结算环节,有能力使得识别模型失效的对抗补丁具有相当高的危险性,需要引起从业者的广泛关注!
该论文题为“Bias-based Universal Adversarial Patch Attack for Automatic Check-out”,提出了一种基于模型偏见(Bias)的通用对抗性补丁生成框架。
该框架充分利用了模型的感知偏见和语义偏见,具有较强的泛化能力,在数字世界进行了大量的实验,在真实世界具有极强的易实现性,并且能够成功攻击物理世界中部署的商品识别系统(淘宝和京东),目前论文已经被全球计算机视觉顶级会议 ECCV-2020 接收。

论文标题:Bias-based Universal Adversarial Patch Attack for Automatic Check-out
论文链接:http://arxiv.org/abs/2005.09257
代码链接:https://github.com/liuaishan/ModelBiasedAttack

基于模型偏见的对抗攻击
本文提出的对抗补丁生成框架具有较好的泛化能力,能够有效的攻击模型训练过程中“不可见”的物品种类,通过在真实世界系统中的测试和验证,验证了其有效性。
其主要框架如下图所示,通过利用模型固有的感知偏见从难样本中提取先验补丁块,并进行融合处理以获得更好的泛化攻击能力。在此基础上,生成包含丰富语义信息的类原型帮助训练对抗补丁,以获得对抗补丁生成效率上的提升。
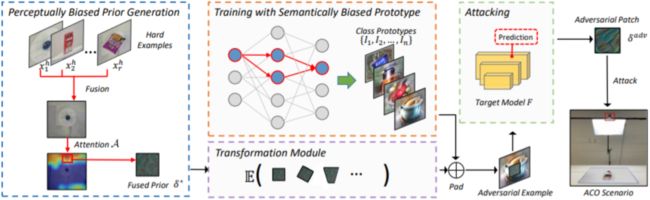
▲ 图2 基于偏见的通用对抗补丁生成框架

基于感知偏见的先验补丁生成
基于感知偏见的先验补丁首先基于多个难样本生成融合样本。难样本是指模型难以正确分类和识别的样本且在数据集中普遍存在,被模型错分的难样本显然离正确的分类区域更远,也即是更容易跨越模型的决策边界导致模型分类错误,利用难样本的特征进行攻击如同“站在巨人的肩膀上”。
而已有的研究证明了,神经网络模型的判断更多依赖于纹理信息(texture),这也被认为是一种模型在感知上的偏见,为了利用这一客观性质进行对抗攻击,进一步的,本论文通过引入风格损失提取这类感知偏见,以增强融合样本的泛化攻击能力:
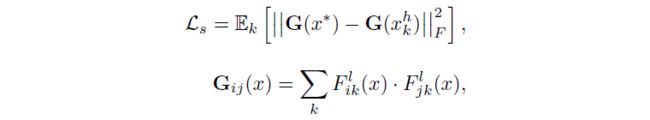
为了增强融合样本的不确定性,引入了类的不确定损失:
![]()
最终,在先验补丁生成环节,优化如下的融合损失:
![]()
融合后的样本具备更强的不确定性和泛化能力,基于此,作者通过使用一个注意力模块来提取最终先验补丁块:
![]()
其中融合样本中每个像素点的权重计算如下:
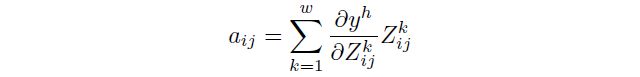

基于语义偏见的类原型训练
由于具有通用性的对抗性扰动的生成策略大多需要大量的训练数据,这极大的增加了各种意义上的训练开销,降低了对抗样本的可攻击性。为了减轻对大量训练数据的依赖,本文进一步引入了基于语义偏见的类原型。
类原型是一种包含数据集中某一类语义信息的典型表示,其代表了某一类别的深层特征,对模型而言,这种类原型会使得模型产生语义上的“偏见”,通过引入类原型,可以训练对抗补丁利用这种固有的语义上的偏见实现对模型的欺骗行为。
其中类原型的目标函数如下:
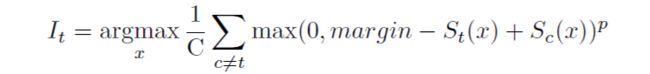
考虑到对抗补丁在现实中的环境适应,论文还引入了转换模块已获得更强的物理世界攻击性。由此,得到整个框架的训练流程:


实验结果:AI零售仍然有很长一段路要走
首先,论文的数字世界实验在目前为止最大的零售 ACO 任务数据集上进行了白盒攻击实验和黑盒攻击实验,验证了所提出的框架生成的对抗补丁的有效性。
4.1 数字世界攻击
如下图所示,在白盒攻击的条件下,论文基于 ResNet-152 为 backbone 模型进行实验,并在相同的 backbone 下与其他方法进行对比,结果显示,本论文提出的方法攻击后的准确率降为 5.42%,远远低于对比方法的准确率。

在黑盒攻击的条件下,论文在 ResNet-152 为 backbone 的条件下进行训练,攻击不同的模型(VGG-16、AlexNet、ResNet-101),同样达到了最好的水平(top-1 accuracy下)。
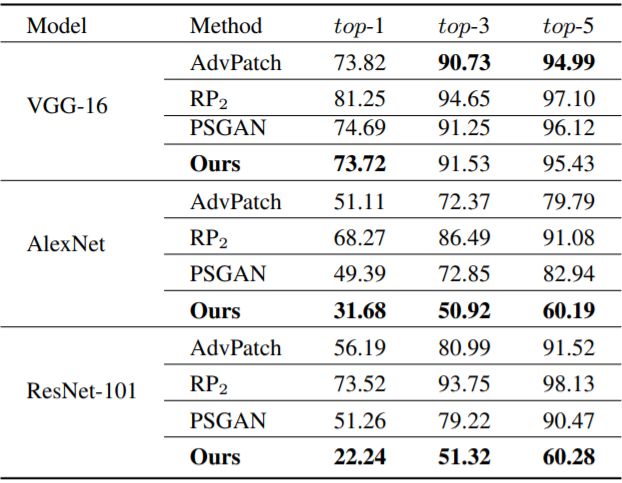
4.2 真实世界攻击
真实世界攻击基于两种在线购物平台(淘宝和京东)进行,在所有的 4 个种类 80 张真实世界货物的照片中,分别只有 56.25% 和 55% 被成功识别,而在不加对抗补丁的条件下,准确率分别为 100% 和 95%,如下图样例所示,牛奶被识别为铝箔,水杯被识别为装饰品:
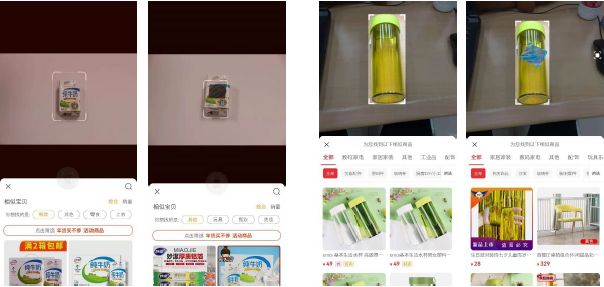

展望
计算机视觉技术的进步极大的推动了人工智能浪潮,视觉技术正在我们的生活中产生巨大的应用价值,也展现出了巨大的发展潜力,人脸识别、自动驾驶、行人检测、视频安防等领域的诸多成果无不昭示着技术给我们带来的便利。
AI 零售被认为是下一个人工智能应用落地的领域之一,计算机视觉应用于这一领域不仅能够提升结算效率,同时能够极大的节省成本。
然而面临着对抗样本的攻击,基于计算机视觉的自动零售系统暴露出了极大的安全隐患,面对这种风险,AI 自动零售还能更顺利的走下去吗?
我们应当以更加慎重的态度和更加挑剔的眼光审视人工智能系统,重视安全人工智能与可解释深度学习技术的发展,用积极的心态拥抱技术,用更周全的思维发展技术,让人工智能技术更好的造福人类。
作者及团队介绍
刘艾杉,北京航空航天大学计算机学院博士三年级在读,主要研究方向为对抗样本、深度学习鲁棒性、人工智能安全性,已在 ECCV、AAAI、IJCAI 等国际顶级人工智能与计算机视觉会议发表多篇论文,并担任多个国际会议及期刊审稿人(如:ACMMM,IJCAI,IEEE TIP等)。
王嘉凯,北京航空航天大学博士二年级在读,研究方向为对抗样本生成,深度学习鲁棒性与安全性,已有研究成果在 ECCV 发表。
刘祥龙,北京航空航天大学副教授,主要研究方向为大数据检索、大规模视觉分析、可信赖深度学习等,已在 CVPR、ICCV、AAAI 等国际顶级人工智能与计算机视觉会议和 IEEE TIP 等国际重要 SCI 期刊上发表论文 100 余篇,担任多个重要的国际会议或者期刊评审和领域主席,入选北京市科技新星计划和 CCF 青年人才发展计划等。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
