网上mongodb的数据同步工具较少,前一段时间用monstache实现了mongo到es的数据实时同步。
因为monstache是基于mongodb的oplog实现同步,而开启oplog前提是配置mongo的复制集;
开启复制集可参考:https://blog.csdn.net/jack_brandy/article/details/88887795;
接下来下载对应es,mongo版本的monstache https://rwynn.github.io/monstache-site/start/
在monstache目录下创建config.toml配置文件,内容如下:
# connection settings # connect to MongoDB using the following URL mongo-url = "mongodb://localhost:27017" # connect to the Elasticsearch REST API at the following node URLs elasticsearch-urls = ["http://localhost:9200"] # frequently required settings # if you don't want to listen for changes to all collections in MongoDB but only a few # e.g. only listen for inserts, updates, deletes, and drops from mydb.mycollection # this setting does not initiate a copy, it is a filter on the oplog change listener only namespace-regex = '^aaa\.bbb$' #aaa表示mongodb的数据库,bbb表示集合,表示要匹配的名字空间 # additionally, if you need to seed an index from a collection and not just listen for changes from the oplog # you can copy entire collections or views from MongoDB to Elasticsearch # direct-read-namespaces = ["mydb.mycollection", "db.collection", "test.test"] # if you want to use MongoDB change streams instead of legacy oplog tailing add the following # in this case you don't need regexes to filter collections. # change streams require MongoDB version 3.6+ # change streams can only be combined with resume, replay, or cluster-name options on MongoDB 4+ # if you have MongoDB 4+ you can listen for changes to an entire database or entire deployment # to listen to an entire db use only the database name. For a deployment use an empty string. # change-stream-namespaces = ["mydb.mycollection", "db.collection", "test.test"] # additional settings # compress requests to Elasticsearch # gzip = true # generate indexing statistics # stats = true # index statistics into Elasticsearch # index-stats = true # use the following PEM file for connections to MongoDB # mongo-pem-file = "/path/to/mongoCert.pem" # disable PEM validation # mongo-validate-pem-file = false # use the following user name for Elasticsearch basic auth # elasticsearch-user = "someuser" # use the following password for Elasticsearch basic auth # elasticsearch-password = "somepassword" # use 4 go routines concurrently pushing documents to Elasticsearch # elasticsearch-max-conns = 4 # use the following PEM file to connections to Elasticsearch # elasticsearch-pem-file = "/path/to/elasticCert.pem" # validate connections to Elasticsearch # elastic-validate-pem-file = true # propogate dropped collections in MongoDB as index deletes in Elasticsearch dropped-collections = true # propogate dropped databases in MongoDB as index deletes in Elasticsearch dropped-databases = true # do not start processing at the beginning of the MongoDB oplog # if you set the replay to true you may see version conflict messages # in the log if you had synced previously. This just means that you are replaying old docs which are already # in Elasticsearch with a newer version. Elasticsearch is preventing the old docs from overwriting new ones. # replay = false # resume processing from a timestamp saved in a previous run resume = true #从上次同步的时间开始同步 # do not validate that progress timestamps have been saved # resume-write-unsafe = false # override the name under which resume state is saved # resume-name = "default" # exclude documents whose namespace matches the following pattern # namespace-exclude-regex = '^mydb\.ignorecollection$' # turn on indexing of GridFS file content # index-files = true # turn on search result highlighting of GridFS content # file-highlighting = true # index GridFS files inserted into the following collections # file-namespaces = ["users.fs.files"] # print detailed information including request traces # verbose = true # enable clustering mode cluster-name = 'tzg' #es集群名 # do not exit after full-sync, rather continue tailing the oplog # exit-after-direct-reads = false
执行命令 ./monstache -f config.toml 成功的话会看到如下界面
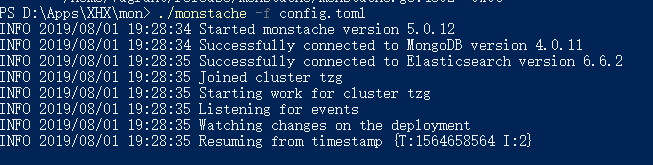
如果es提示queue size不足,则再es配置中添加如下内容:
thread_pool:
bulk:
queue_size: 200