Python 实战之淘宝手机销售分析(数据清洗、可视化、数据建模、文本分析)
文章目录
- 一、数据介绍
- 二、数据清洗
- 导入数据
- 缺失值处理+合并
- 清洗时间参数
- 清洗价格数据
- 清洗发货城市数据
- 价格分箱
- 手机参数信息提取
- 三、可视化分析
- 淘宝在售手机价格区间统计
- 商品现价&原价对比
- 手机类型分布词云图
- 绘制手机品牌词云图
- 不同品牌手机总销量比较
- 月销量气泡图
- 收藏量与价格分析
- 不同价格等级总销量饼图
- 总销售额构成分析
- TOP10 手机价格等级构成
- 各发货省不同价格等级销售情况
- 四、数据建模
- 五、文本分析
- SnowNLP 情感分析
- LDA 主题模型
一、数据介绍
链接: https://pan.baidu.com/s/1GVQ5rv3ElNDLOkaDzuD6Jw 密码:5h6g
本文数据爬取了淘宝全网手机销售数据,其中包括:
- cellphone.csv
该数据集包括淘宝网在售的手机商品信息,包括爬取信息、商品信息、评分收藏信息等;
| Index | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | 爬取时间(__time) | 1691 non-null | object |
| 1 | 爬取链接(__url) | 1691 non-null | object |
| 2 | 商品ID(product_id) | 1691 non-null | int64 |
| 3 | 商品名称(name) | 1691 non-null | object |
| 4 | 商品描述(description) | 1587 non-null | object |
| 5 | 商品参数(params) | 1691 non-null | object |
| 6 | 商品现价(current_price) | 1691 non-null | object |
| 7 | 商品原价(original_price) | 1691 non-null | object |
| 8 | 月销量(month_sales_count) | 1684 non-null | float64 |
| 9 | 库存(stock) | 1675 non-null | float64 |
| 10 | 发货地址(shipping_address) | 1691 non-null | object |
| 11 | 商品发布时间(product_publish_time) | 1691 non-null | int64 |
| 12 | 店铺ID(shop_id) | 1691 non-null | int64 |
| 13 | 店铺名称(shop_name) | 1691 non-null | object |
| 14 | 商品链接URL(url) | 1691 non-null | object |
| 15 | 评分(总分5.0分)(score) | 1680 non-null | float64 |
| 16 | 收藏数(stores_count) | 1691 non-null | int64 |
| 17 | 累计评价数(comments_count) | 1679 non-null | float64 |
| 18 | 商品评价印象标签(impresses) | 1691 non-null | object |
| 19 | Unnamed: 19 | 0 non-null | float64 |
- count_add_comments.csv
该数据集包含上述手机商品的评价信息,包含图片的评价条数、追评条数等;
| Index | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | 图片(picNum) | 1232 non-null | float64 |
| 1 | 追评(used) | 1176 non-null | float64 |
| 2 | ID(id) | 1691 non-null | int64 |
| 3 | Unnamed: 3 | 0 non-null | float64 |
- comments.csv
该数据集包含上数据手机商品的具体评价,包括评价时间、评价内容等;
| Index | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | 商品ID(id) | 376760 non-null | int64 |
| 1 | 评价时间(time) | 376760 non-null | object |
| 2 | 评价内容(content) | 376759 non-null | object |
| 3 | 爬取链接(spurl) | 376760 non-null | object |
| 4 | 爬取时间(sptime) | 376760 non-null | object |
| 5 | Unnamed: 5 | 0 non-null | float64 |
二、数据清洗
导入数据
- 发现商品描述、月销量、库存、评分、累计评价数存在缺失
import pandas as pd
import numpy as np
phone=pd.read_csv('cellphone.csv')
add_comments=pd.read_csv('count_add_comments.csv')
缺失值处理+合并
- 先对phone 进行处理
#删除空白列
phone=phone.drop(columns=['Unnamed: 19'])
#先获取列名,在此基础上进行更改
phone.columns
phone.columns=['爬取时间', '爬取链接', '商品ID', '商品名称',
'商品描述', '商品参数', '商品现价',
'商品原价', '月销量', '库存',
'发货地址', '商品发布时间',
'店铺ID', '店铺名称', '商品链接URL', '评分',
'收藏数' ,'累计评价数', '商品评价印象标签']
#商品描述、月销量、库存、评分、累计评价数存在缺失
#查看月销量为0的商品信息
phone[phone['月销量'].isnull()].info()
#对销量为零的数据进行 0 填充
phone['月销量']=phone['月销量'].fillna(0)
#处理库存(0 填充)、评分(删除空白数据)、累计评价数(0填充)
phone['库存']=phone['库存'].fillna(0)
phone['累计评价数']=phone['累计评价数'].fillna(0)
phone=phone.dropna(subset=['评分'])
#重新梳理 index
phone.index=np.arange(len(phone))
- 再对add_comments和 phone 进行数据合并
df=pd.merge(phone,add_comments,left_on='商品ID',right_on='ID(id)')
- 最后对合并后的df进行列名梳理,删去重复的商品 ID
df.columns=['爬取时间', '爬取链接', '商品ID', '商品名称',
'商品描述', '商品参数', '商品现价',
'商品原价', '月销量', '库存',
'发货地址', '商品发布时间',
'店铺ID', '店铺名称', '商品链接URL', '评分',
'收藏数' ,'累计评价数', '商品评价印象标签','图片', '追评', 'ID(id)', 'Unnamed: 3']
df=df.drop(columns=['Unnamed: 3'])
df=df.drop(columns=['ID(id)'])
清洗时间参数
-
time.localtime():能将 int 格式的时间数据转化
如:time.localtime(1548475512)
输出结果:time.struct_time(tm_year=2019, tm_mon=1, tm_mday=26, tm_hour=12, tm_min=5, tm_sec=12, tm_wday=5, tm_yday=26, tm_isdst=0) -
time.strftime(’%Y-%m-%d’,time.localtime(1548475512)):输出既定格式的时间信息;
输出结果:‘2019-01-26’
关于时间有关格式化信息
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00-59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
import time
df['商品发布时间']=df['商品发布时间'].apply(lambda op:time.strftime('%Y-%m-%d',time.localtime(op)))
清洗价格数据
目前得到的‘商品现价’、‘商品原价’两列均为价格区间的表示格式,我们无法获取完整的价格,在此取其均值;
def get_price(s):
price=s.split('-')
l=[float(i) for i in price]
return np.mean(l)
df['商品现价']=df['商品现价'].apply(get_price)
df['商品原价']=df['商品原价'].apply(get_price)
清洗发货城市数据
目前发货城市数据为省+城市名的表示方式,我们要将省份+城市数据提取出来;
#获得中国全部的省级单位名称,找到全部的省级单位
#将每一个地址的省份提取出来,剩下的就是城市
pro_list=['北京',
'天津',
'上海',
'重庆',
'河北',
'山西',
'辽宁',
'吉林',
'黑龙江',
'江苏',
'浙江',
'安徽',
'福建',
'江西',
'山东',
'河南',
'湖北',
'湖南',
'广东',
'海南',
'四川',
'贵州',
'云南',
'陕西',
'甘肃',
'青海',
'台湾',
'内蒙古',
'广西',
'西藏',
'宁夏',
'新疆',
'香港',
'澳门']
def get_city(address):
for i in pro_list:
if i in address:
city=address.replace(i,'')
if len(city)==0:
city=i
return city
def get_province(address):
for i in pro_list:
if i in address:
province=i
return province
df['发货城市']=df['发货地址'].apply(get_city)
df['发货省份']=df['发货地址'].apply(get_province)
价格分箱
import matplotlib.pyplot as plt
price_=df['商品现价'].value_counts().sort_index()
plt.plot(price_.index,price_)
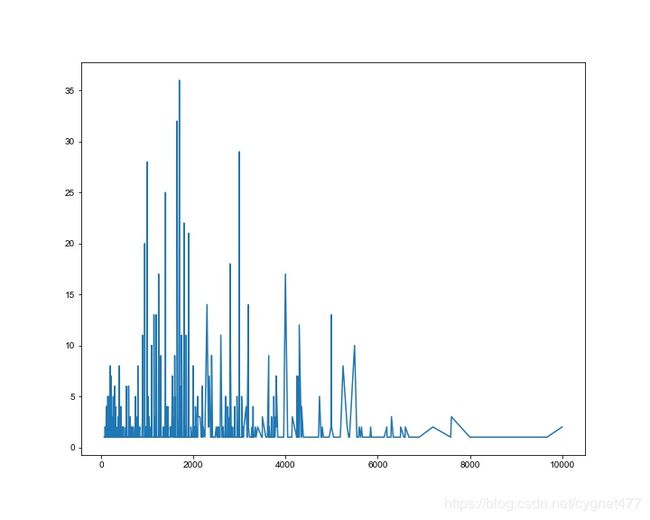 发现价格大致以 1000 元为一个等级,呈现分区分布;
发现价格大致以 1000 元为一个等级,呈现分区分布;
于是创建价格等级字段,以便后续进行分析;
def get_price_level(p):
level=p//1000
if level==0:
return '0~999'
if level==1:
return '1000~1999'
if level==2:
return '1999~2999'
if level==3:
return '2999~3999'
if level==4:
return '3999~4999'
if level>=5:
return '5000+'
else:
return '计算出错'
df['价格等级']=df['商品现价'].apply(get_price_level)
手机参数信息提取
手机参数信息以字典形式保存,创建一个函数,将每个键值对提取出来,以列的形式呈现;
target=['后置摄像头',
'摄像头类型',
'视频显示格式',
'分辨率',
'触摸屏类型',
'屏幕尺寸',
'网络类型',
'网络模式',
'键盘类型',
'款式',
'运行内存RAM',
'存储容量',
'品牌',
'华为型号',
'电池类型',
'核心数',
'机身颜色',
'手机类型',
'操作系统',
'CPU品牌',
'产品名称']
for t in target:
def get_pram(p):
for i in eval(p):
if i['label']==t:
return i['value']
df[t]=df['商品参数'].apply(get_pram)
至此,数据清洗过程大致完成,后续借助Matplotlib 和 Tableau 进行简要的可视化分析
三、可视化分析
淘宝在售手机价格区间统计
plt.rcParams['font.family']=['Arial Unicode MS']
plt.figure(figsize=(10,5),dpi=200)
#发现手机原价数据有异常,进行清洗
df=df.drop(df[df['商品原价']>10000].index)
x=df['价格等级']
y=df.groupby('价格等级').count().reset_index
plt.hist(x,bins=12,color='green',align='mid')
plt.title('淘宝在售手机价格区间统计')
plt.xlabel('价格区间')
plt.ylabel('淘宝在售手机数')
plt.savefig('淘宝在售手机价格区间统计')
plt.show()

商品现价&原价对比
#先筛选评分 >4.5的具有分析意义的手机商品
df1=df[df['评分']>4.5]
price1=df1.groupby('品牌')['商品原价'].mean().reset_index()
labels=price1['品牌']
price1=price1['商品原价'].astype(int)
price2=df1.groupby('品牌')['商品现价'].mean().reset_index()
price2=price2['商品现价'].astype(int)
x = np.arange(len(labels))
width = 0.4
fig, ax = plt.subplots(figsize=(40,20))
rects1 = ax.bar(x - width/2, price1, width, label='商品原价')
rects2 = ax.bar(x + width/2, price2, width, label='商品现价')
ax.set_ylabel('价格',fontsize=30)
ax.set_title('手机现价及原价对比',fontsize=50)
ax.set_xticks(x)
plt.xticks(rotation=90)
ax.set_xticklabels(labels)
ax.legend(fontsize=30)
#数据标签设置
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate('{}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom',fontsize=20)
autolabel(rects1)
autolabel(rects2)
plt.tick_params(labelsize=30)
labels = ax.get_xticklabels() + ax.get_yticklabels()
fig.tight_layout()
plt.savefig('手机销售现价&原价对比')
plt.show()

手机类型分布词云图
手机具体参数含有手机类型的参数,针对淘宝全网所有售卖手机的商品信息,提取包含手机类型的字段,对其类型进行清洗及统计,查看在售手机类型情况;
from wordcloud import WordCloud
from imageio import imread
plt.rcParams['font.family']=['Arial Unicode MS']
df=df[df['手机类型'].notnull()]
df['手机类型']=[i.replace('不祥','不详') for i in df['手机类型']]
df['手机类型']=[i.replace('不详4','不详') for i in df['手机类型']]
df['手机类型']=[i.replace('老年机','老人手机') for i in df['手机类型']]
df['手机类型']=[i.replace('老年手机','老人手机') for i in df['手机类型']]
df['手机类型']=[i.replace('功能机','功能手机') for i in df['手机类型']]
df['手机类型']=[i.replace('老人机','老人手机') for i in df['手机类型']]
df['手机类型']=[i.replace('4G+手机','4G手机') for i in df['手机类型']]
get_type=[i.split('\xa0') for i in df['手机类型'].tolist()]
phone_type=[]
for i in get_type:
phone_type+=i
word_count=pd.Series(phone_type).value_counts()
font='/Users/zhaosiqi/Library/Fonts/simhei.ttf'
wc = WordCloud(max_words=100,
scale=12,
max_font_size=200,
random_state=30,
background_color='white',
font_path=font)
wc2 = wc.fit_words(word_count)
plt.figure(figsize=(15,10))
plt.imshow(wc2)
plt.axis("off")
plt.show()
wc.to_file("手机类型词云图.png")
 由此发现市面上在售手机大多为智能手机,且其拍照功能炙手可热,也成为商家销售的卖点;
由此发现市面上在售手机大多为智能手机,且其拍照功能炙手可热,也成为商家销售的卖点;
而手机起步时代,对于手机的噱头,包括音乐手机、商务手机,女性手机等等,已不再成为卖点,市面上相关类型手机也逐渐下架;
绘制手机品牌词云图
word_count=pd.Series(df['品牌'].tolist()).value_counts()
font='/Users/zhaosiqi/Library/Fonts/simhei.ttf'
back_pic=imread('pic.jpg')
wc = WordCloud(max_words=100,
scale=12,
max_font_size=50,
random_state=30,
background_color='white',
mask=back_pic,
font_path=font)
wc2 = wc.fit_words(word_count)
plt.figure(figsize=(15,10))
plt.imshow(wc2)
plt.axis("off")
plt.show()
wc.to_file("手机品牌词云图.png")
 国内销售市场上,销售量总体维持着以下情况:
国内销售市场上,销售量总体维持着以下情况:
华为、荣耀为第一梯队;
三星、小米、OPPO、Vivo、Apple 等品牌为第二梯队;
魅族、美图、飞利浦等品牌为第三梯队;
从第一款 Iphone 发布在国际市场上就保持着良好成绩的 Apple 公司,由于近年产品迭代速度较慢,且价格较贵,在国内销售情况并不十分突出;
--------------------以下图表由 Tableau 绘制-----------------
不同品牌手机总销量比较
此次爬取数据中并未包含总销售量数据,但根据淘宝的系统设置,无论买家是否主动评价,交易成功后将会自动留下评价信息,故在这里可以视‘累计评价数’为总销售量进行分析;

月销量气泡图
 数据爬取时间为2019 年2月1日,则月销量代表爬取日期往前推 30 天,即 2019 年1 月全月的销售情况;
数据爬取时间为2019 年2月1日,则月销量代表爬取日期往前推 30 天,即 2019 年1 月全月的销售情况;
整体来看,荣耀、华为、小米、Vivo 占据了当月国内手机市场销售的半壁江山;
收藏量与价格分析

其中圆形图标大小代表该品牌手机的平均价格;
而条形图高低代表该品牌手机的收藏量;
不同价格等级总销量饼图

总销售额构成分析

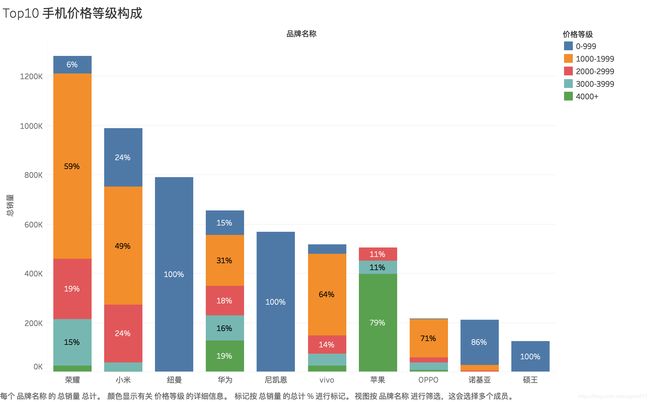
TOP10 手机价格等级构成
各发货省不同价格等级销售情况

四、数据建模
- 此处尝试以月销量为目标值,利用各种回归模型进行建模,但预测效果均不太好,后续有其他尝试再进行更新;
#对屏幕尺寸进行处理,转化为浮点型,纳入特征值中
df=df[df['屏幕尺寸'].notnull()]
df['屏幕尺寸']=[float(i.replace('英寸','')) for i in df['屏幕尺寸']]
#绘制热力图
f=df[['商品现价','商品原价','库存','评分','收藏数','累计评价数','追评','屏幕尺寸','累计评价数','图片','月销量']]
target=df['月销量']
df['商品折扣']=df['商品现价']/df['商品原价']
corr=f.corr()
import seaborn as sns
plt.figure(figsize=(12,9))
sns.heatmap(corr,annot=True)
plt.show()

根据热力图相关信息,库存、收藏数、累计评价数、追评数、图片数等都与月销量有较强的相关性,故舍弃其他特征,暂时将这几个数据列为特征值进行建模分析;
features=df[['库存','收藏数','累计评价数','累计评价数','屏幕尺寸','商品折扣']]
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.linear_model import LinearRegression,Ridge
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
def model_test(estimators,x_train,x_test,y_train,y_test):
for key,estimator in estimators.items():
estimator.fit(x_train,y_train)
y_predict=estimator.predict(x_test)
mse=mean_squared_error(y_test,y_predict)
print('----------------MSE of %s-------------'%(key),mse)
scores=estimator.score(x_test,y_test)
print('----------------Score of %s-------------'%(key),scores)
print('\n')
estimators={}
estimators['Linear']=LinearRegression()
estimators['ridge'] = Ridge()
estimators['forest'] = RandomForestRegressor()
estimators['gbdt'] = GradientBoostingRegressor()
estimators['light'] = LGBMRegressor()
estimators['xgb'] = XGBRegressor()
x_train,x_test,y_train,y_test=train_test_split(features,target,test_size=0.25)
std_x=StandardScaler()
std_y=StandardScaler()
x_train=std_x.fit_transform(x_train)
x_test=std_x.transform(x_test)
y_train=std_y.fit_transform(y_train.values.reshape(-1,1))
y_test=std_y.transform(y_test.values.reshape(-1,1))
model_test(estimators,x_train,x_test,y_train,y_test)
最后运行结果:
----------------MSE of Linear------------- 0.2444868135647999
----------------Score of Linear------------- 0.8342966651118264
----------------MSE of ridge------------- 0.2434147057213362
----------------Score of ridge------------- 0.8350232967138806
----------------MSE of forest------------- 0.581285474209155
----------------Score of forest------------- 0.6060280708228011
----------------MSE of gbdt------------- 0.7016777783281599
----------------Score of gbdt------------- 0.5244310063573885
----------------MSE of light------------- 0.745090845811169
----------------Score of light------------- 0.49500737424091323
----------------MSE of xgb------------- 0.7981978840571146
----------------Score of xgb------------- 0.4590135583983481
除线性回归及岭回归拟合效果较好外,其他模型没有比较好的得分,对特征进行多次增删调整后,也无太大变化;
五、文本分析
SnowNLP 情感分析
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库。
这里主要用到 SnowNLP库中的情绪判断,用与判断买家评论信息的情绪;
该 API 返回值为为正面情绪的概率,越接近1表示正面情绪,越接近0表示负面情绪,例如:
text1 = '这部电影真心棒,全程无尿点'
text2 = '这部电影简直烂到爆'
s1 = SnowNLP(text1)
s2 = SnowNLP(text2)
print(text1, s1.sentiments) # 这部电影真心棒,全程无尿点
0.9842572323704297
print(text2, s2.sentiments) # 这部电影简直烂到爆
0.0566960891729531
此外 SnowNLP 还具有分词、词性标注(动词、名词等分类)、断句、拼音、繁转简、关键词抽取等功能;
本文中买家的评论信息可以用作情感分析的数据集,但由于全网评价条目过多,我们创建一个规则:
正面情绪概率>0.6 称之为积极情绪;
正面情绪概率<0.4 称之为消极情绪;
正面情绪概率<0.6 & >0.4 称之为平和情绪;
下面创建了一个函数,对 30 万余条评价,按指定列字段进行分类情感分析:
from snownlp import SnowNLP
cmt=pd.read_csv('comments.csv')
cmt=cmt.dropna(subset=['评价内容(content)'])
cmt.index=np.arange(len(cmt))
#创建分类标签的情感分析函数
def Marks_emotion(column,content):
def emotion(content):
s=[np.round(SnowNLP(i).sentiments,2) for i in content]
positive=0
negative=0
smooth=0
for i in s:
if i >0.6:
positive+=1
elif i<0.4:
negative+=1
else:
smooth+=1
counts=positive+negative+smooth
print('积极情绪',str(int(positive/counts*100))+'%')
print('消极情绪',str(int(negative/counts*100))+'%')
print('平和情绪',str(int(smooth/counts*100))+'%')
for i in df[column].unique():
uid=df[df[column]==i]['商品ID']
def funci(ID):
for i in uid:
if ID==i:
return True
return False
whether_ture=cmt['商品ID(id)'].apply(funci)
comments=pd.Series(cmt[whether_ture][content])
print(i,'情感分析结果:')
emotion(comments)
Marks_emotion('品牌','评价内容(content)')
注:由于数据量过于庞大,上述代码需要至少1小时才能跑完,故如果只是用于测试,可以利用随机取数的方法,进行抽样分析,参考代码如下:
from snownlp import SnowNLP
cmt=pd.read_csv('comments.csv')
cmt=cmt.dropna(subset=['评价内容(content)'])
cmt.index=np.arange(len(cmt))
#创建分类标签的情感分析
def Marks_emotion(column,content):
def emotion(content):
s=[np.round(SnowNLP(i).sentiments,2) for i in content]
positive=0
negative=0
smooth=0
for i in s:
if i >0.6:
positive+=1
elif i<0.4:
negative+=1
else:
smooth+=1
counts=positive+negative+smooth
print('积极情绪',str(int(positive/counts*100))+'%')
print('消极情绪',str(int(negative/counts*100))+'%')
print('平和情绪',str(int(smooth/counts*100))+'%')
for i in df[column].unique():
uid=df[df[column]==i]['商品ID']
def funci(ID):
for i in uid:
if ID==i:
return True
return False
whether_ture=cmt['商品ID(id)'].apply(funci)
comments=pd.Series(cmt[whether_ture][content])
if len(comments)>1000:
index=np.random.randint(1,len(comments),1000)
comments=comments.iloc[index]
print(i,'品牌手机情感分析结果:')
emotion(comments)
Marks_emotion('品牌','评价内容(content)')
输出结果如下:
Huawei/华为 品牌手机情感分析结果:
积极情绪 75%
消极情绪 17%
平和情绪 6%
纽曼 品牌手机情感分析结果:
积极情绪 76%
消极情绪 14%
平和情绪 9%
Meizu/魅族 品牌手机情感分析结果:
积极情绪 68%
消极情绪 24%
平和情绪 6%
Samsung/三星 品牌手机情感分析结果:
积极情绪 65%
消极情绪 26%
平和情绪 8%
DOOV/朵唯 品牌手机情感分析结果:
积极情绪 88%
消极情绪 8%
平和情绪 3%
Philips/飞利浦 品牌手机情感分析结果:
积极情绪 78%
消极情绪 14%
平和情绪 7%
OPPO 品牌手机情感分析结果:
积极情绪 76%
消极情绪 17%
平和情绪 6%
honor/荣耀 品牌手机情感分析结果:
积极情绪 72%
消极情绪 21%
平和情绪 6%
Xiaomi/小米 品牌手机情感分析结果:
积极情绪 71%
消极情绪 21%
平和情绪 7%
Apple/苹果 品牌手机情感分析结果:
积极情绪 59%
消极情绪 31%
平和情绪 9%
Nokia/诺基亚 品牌手机情感分析结果:
积极情绪 68%
消极情绪 21%
平和情绪 9%
小辣椒 品牌手机情感分析结果:
积极情绪 78%
消极情绪 15%
平和情绪 6%
守护宝 品牌手机情感分析结果:
积极情绪 78%
消极情绪 14%
平和情绪 7%
Coolpad/酷派 品牌手机情感分析结果:
积极情绪 85%
消极情绪 12%
平和情绪 2%
BIRD/波导 品牌手机情感分析结果:
积极情绪 79%
消极情绪 13%
平和情绪 6%
K-Touch/天语 品牌手机情感分析结果:
积极情绪 81%
消极情绪 13%
平和情绪 4%
vivo 品牌手机情感分析结果:
积极情绪 81%
消极情绪 12%
平和情绪 5%
UniscopE/优思 品牌手机情感分析结果:
积极情绪 82%
消极情绪 10%
平和情绪 7%
Meitu/美图 品牌手机情感分析结果:
积极情绪 79%
消极情绪 15%
平和情绪 4%
360 品牌手机情感分析结果:
积极情绪 73%
消极情绪 20%
平和情绪 6%
nubia/努比亚 品牌手机情感分析结果:
积极情绪 74%
消极情绪 20%
平和情绪 5%
AGM(手机) 品牌手机情感分析结果:
积极情绪 73%
消极情绪 19%
平和情绪 6%
创星(手机) 品牌手机情感分析结果:
积极情绪 75%
消极情绪 19%
平和情绪 5%
ZTE/中兴 品牌手机情感分析结果:
积极情绪 74%
消极情绪 18%
平和情绪 6%
Konka/康佳 品牌手机情感分析结果:
积极情绪 88%
消极情绪 6%
平和情绪 5%
索爱 品牌手机情感分析结果:
积极情绪 85%
消极情绪 8%
平和情绪 6%
Haier/海尔 品牌手机情感分析结果:
积极情绪 78%
消极情绪 13%
平和情绪 8%
Changhong/长虹 品牌手机情感分析结果:
积极情绪 77%
消极情绪 15%
平和情绪 7%
SMARTISAN/锤子 品牌手机情感分析结果:
积极情绪 78%
消极情绪 14%
平和情绪 7%
YEPEN/誉品 品牌手机情感分析结果:
积极情绪 82%
消极情绪 12%
平和情绪 5%
OnePlus/一加 品牌手机情感分析结果:
积极情绪 70%
消极情绪 20%
平和情绪 9%
21KE 品牌手机情感分析结果:
积极情绪 72%
消极情绪 18%
平和情绪 8%
几米 品牌手机情感分析结果:
积极情绪 93%
消极情绪 3%
平和情绪 3%
LDA 主题模型
潜在狄利克雷模型(Latent Dirichlet Allocation)是贝叶斯学习的话题模型,是潜在语义分析的扩展,主要用于文本数据挖掘、图像处理等领域。
此处将模型封装为了一个函数,是为一个简单的引用。后续将进行 LDA 模型原理的详细讲解。
import jieba
import lda
from collections import Counter
string=open(r'stopwords.txt',encoding='utf-8').read()
filterwords=string.split('\n')
def word_cut(coms):
b=[]
for i in jieba.cut(coms):
if i not in filterwords:
b.append(i)
return b
def get_vector(sentence,vocab):
temp=[]
for word in vocab:
if word in sentence:
temp.append(1)
else:
temp.append(0)
return temp
def get_lda(params):
corpora_words=[]
for i in params:
ss=word_cut(i)
corpora_words.append(ss)
words=[]
for i in corpora_words:
words+=i
word_count=Counter(words)
vocab=[]
for word in word_count.keys():
if word_count[word]>1:
vocab.append(word)
X=[]
for se in corpora_words:
X.append(get_vector(se,vocab))
X=np.array(X)
lda_model=lda.LDA(n_topics=10,n_iter=1500,random_state=1)
lda_model.fit(X)
topic_word=lda_model.topic_word_
for i in range(5):
index=np.argsort(topic_word[i])[::-1]
print('主题',i,':',end='')
for j in np.array(vocab)[index][0:10]:
print(j,end=' ')
print()
get_lda(pd.Series(cmt['评价内容(content)'].iloc[:1000]))
输出结果:
主题 0 :东西 买 好评 评论 特别 天猫 淘宝 老板 评价 字
主题 1 :苏宁 快递 物流 好 手机 不错 买 满意 很快 快
主题 2 :不错 好 值得 手机 质量 购买 买 华为 支持 正品
主题 3 :买 老人 喜欢 好 不错 挺 声音 手机 妈妈 机
主题 4 :手机 送 不错 客服 收到 几天 好评 挺 一段时间 赞