Lucene技术---Solr实现全文检索技术
借用百度对solr和lucenen技术的了解.百度百科是这样解释的
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。对Lucene的解释为
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。我们可以在lucene 的官网下载到lucene

这里会谈到检索的概念
像我们常用的搜索引擎 百度,google(被天朝封了),360一系列的搜索工具.
定义:(2)全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
2.1 什么是Lucene?
Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。我们看看下载完成的Lucene开发的包结构
包名 功能
org.apache.lucene.analysis 语言分析器,主要用于的切词
Lucene提供的分析器实现类在:
lucene-analyzers-common-4.10.3.jar
org.apache.lucene.document 索引存储时的文档结构管理,类似于关系型数据库的表结构
org.apache.lucene.index 索引管理,包括索引建立、删除等
org.apache.lucene.queryParser 查询分析器,实现查询关键词间的运算,如与、或、非等, 生成查询表达式,
org.apache.lucene.search 检索管理,根据查询条件,检索得到结果
org.apache.lucene.store 数据存储管理,包括一些I/O操作
org.apache.lucene.util 公用类
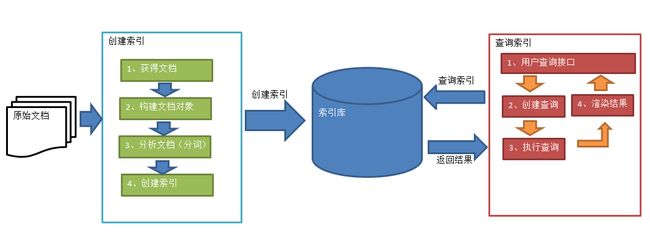
我们看到lucene的执行流程,从分析到索引.
首先对于lucene发开的目的是为了检索,而检索需要依赖与”次”,这里我们使用的是我们中国人开发支持中文分析的工具.简称IK分词器,也成为分析器,我喜欢成为分词器.(Ikanalyzer),分词的目的在于检索.
准备开发环境
Jdk:1.7.0_72
开发工具:eclipse indigo
Lucene包:
lucene-core-4.10.3.jar
lucene-analyzers-common-4.10.3.jar
lucene-queryparser-4.10.3.jar
其它:
commons-io-2.4.jar
junit-4.9.jar
在此基础上我们使用solr服务器,首先我们\也要搭建solr服务器.
系统使用centOS5.6,我们下载solr卡发工具包解压,

其中solr是一个web应用,我们在example/webapps下发现solr.war

我们把这个war包发布tomcat下,同时要依赖一些jar包,位置在

复制所有的jar包,到tomcat应用的jar包下

solr.war解压到tomcat的webapps目录下
解压命令是 unzip -r solr.war
解压后的目录
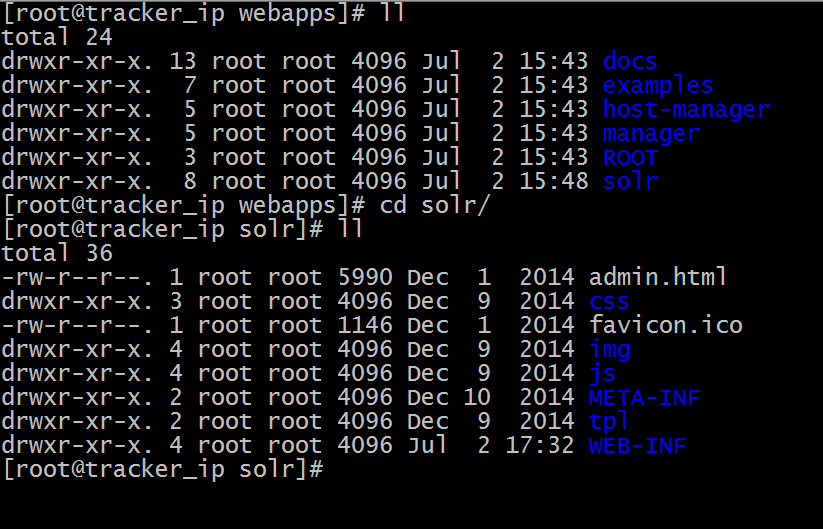
接下来我们首先启动tomcat
访问
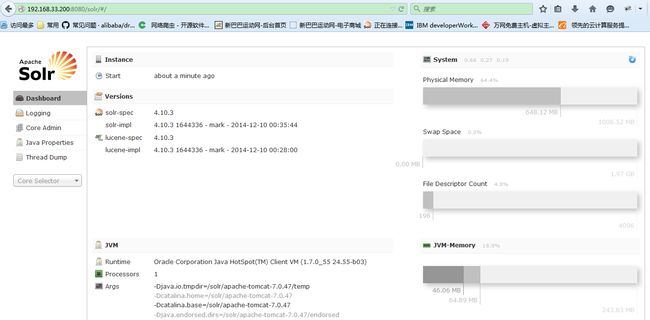
这次就算成功一半了,接下来开始设置solrhome
所谓的solrhome就是在solr的

里面conllction1就是一个solrhome
里面的文件夹的core.proerties是我们solrhome的名称,以后在solr中会选择这个.还有一个conf文件夹里面有个schema.xml
这个文件很重要,包含了已知的类型和自定义的类,以及我们是要使用的IK分词器的类型

<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene
.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.
IKAnalyzer"/>
fieldType>
<field name="name_ik" type="text_ik" indexed="true" stored="true" />
<field name="brandId" type="int" indexed="true" stored="true" />我们要看下他的定义
-->
"title" type="text_general" indexed="true" stored="true" multiValued="true"/>
"subject" type="text_general" indexed="true" stored="true"/>
"description" type="text_general" indexed="true" stored="true"/>
"comments" type="text_general" indexed="true" stored="true"/>
"author" type="text_general" indexed="true" stored="true"/>
"keywords" type="text_general" indexed="true" stored="true"/>
"category" type="text_general" indexed="true" stored="true"/>
"resourcename" type="text_general" indexed="true" stored="true"/>
"url" type="text_general" indexed="true" stored="true"/>
"content_type" type="string" indexed="true" stored="true" multiValued="true"/>
"last_modified" type="date" indexed="true" stored="true"/>
"links" type="string" indexed="true" stored="true" multiValued="true"/>
name不说了 type类型,也在本文件定义,可以找到
indexed:是否被索引
stored:是否存储
我们下面开始配置IK分词和solrhome
首先在web.xml配置solrhome
找到
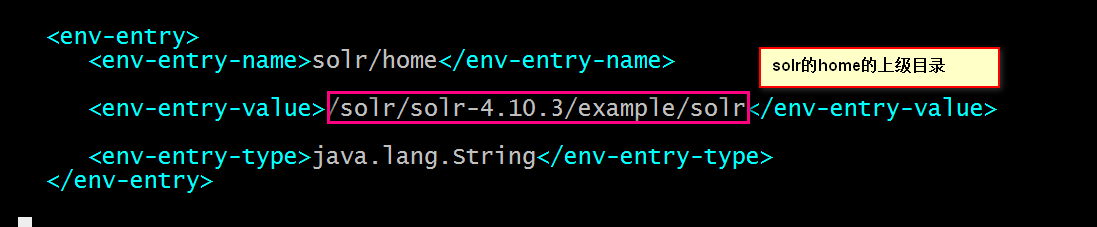
我们这里是打开注释的.
接下来在classes目录下复制Ik分词器的配置文件IKAnalyzer.cfg.xml
和IK分词器的jar包.IKAnalyzer2012FF_u1.jar
以及停词文件stopword.dic

我们看看ik分词器的配置文件
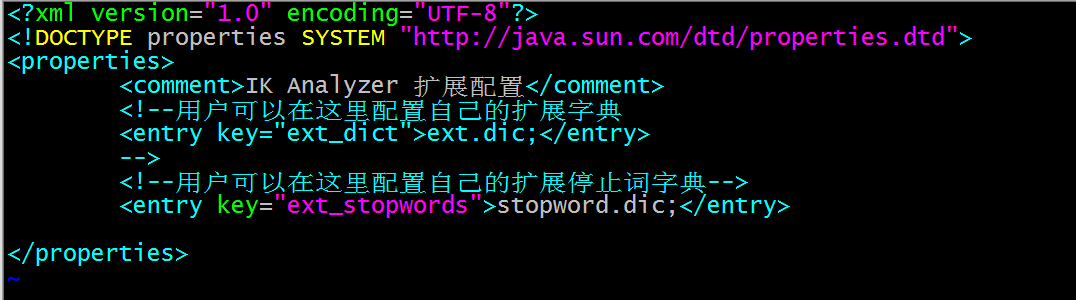
不多说了
我们都配置好 了.看看效果.启动服务器.
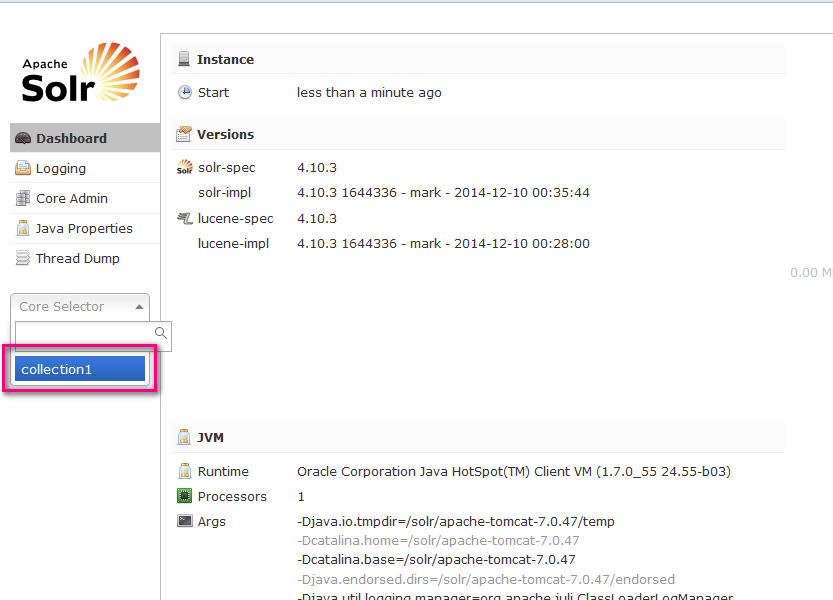
我们这样就搭建了一个简单的单机版solr服务器.
后续可以继续搭建solecloud.
这样我们在java借口中可以使用solr的客户端solrJ调用查询.