kubernetes中Service详解(图解)
目录
容器及Pod间通信
Kube-proxy
DNS服务发现机制
Kubernetes服务
第一部分:容器及Pod间通信
Kubernets网络模型设计的一个基础原则是:每个Pod都拥有一个独立的IP地址,而且假定所有的Pod都在一个可以之间联通的,扁平的网络空间里,所以不管是否运行在同一个Node中,都要求他们可以直接通过对方的IP进行访问。设计这个原则的原因是用户不需要额外考虑如何建立Pod之间的连接,也不需要将容器端口映射到主机端口等问题
按照上述的网络抽象原则,Kubernets对集群的网络有以下要求:
1)所有容器都可以在不用NAT的方式下同其他容器通信
2)所有节点都可以在不用NAT的方式下同其他容器通信
3)容器的地址和别人看到的地址是同一个地址
下面我们介绍kubernets中有哪些通信场景
一.同一Pod中的容器间通信
同一个Pod中的容器共享同一个网络命名空间,他们之间的访问可以通过localhost地址和容器端口来实现
二.同一Node中Pod间通信
同一Node中的Pod默认路由都是Docker0的地址,由于他们关联在同一个Docker0网桥上,地址网段相同,所以他们能直接通信
三.不同Node之间Pod间的通信
Docker0网桥与宿主机网卡是完全不同的IP网段,并且Node之间的通信只能通过宿主机的物理网卡进行,因此要想实现位于不同Node上的Pod容器之间的通信,就必须想办法通过主机的IP地址进行寻址和通信
另一方面,这些动态分配并且隐藏在Docker0之后的所谓“私有IP地址”也是可以找到的,Kubernetes会记录所有正在运行的Pod的IP分配信息,并且将这些信息保存在etcd中(作为Service的Endpoint),这些私有IP对Pod到Pod之间的通信是非常重要的
想要实现支持不同Node上的Pod之间的通信,要达到两个条件
1.在整个kubernetes集群中对Pod的IP进行规划,不能有冲突
2.找到一种方法,将Pod的IP和所在的Node关联起来,通过这个关联可以让Pod可以互相访问
应对条件一,Kubernetes的网络增强软件Flannel就能够管理网段的划分
应对条件二,Pod中的的数据在发出时需要一个机制,能够知道对方Pod的IP地址挂载具体哪个Pod上,也就是要先找到Node对应宿主机的IP地址,将数据发送到这个宿主机的网卡上,然后在宿主机上将相应的数据发送到具体的Docker0上,一旦数据到达宿主机Node,则该Node内部的Docker0便知道如何将数据发送到Pod上
关于上述三种通信的模型图解,请查看笔者的另一篇文章Dokcer网络模型
第二部分:kube-proxy
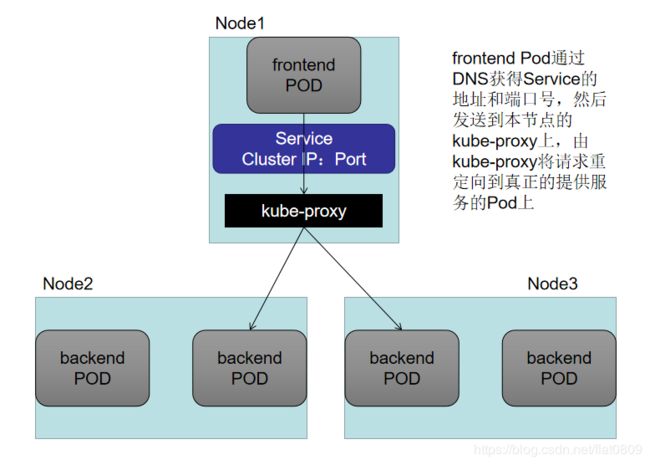
kube-proxy是一个简单的网络代理和负载均衡器,它的作用主要是负载Service的实现,实现从Pod到Service,以及从NodePort到Service的访问
一.kube-proxy实现方式
usersapce方式:通过kube-proxy实现LB的代理服务,是kube0proxy的最初版本,较为稳定,但是效率不高
iptables方式:采用iptables来实现LB,是当前kube-proxy的默认方式
kube-proxy监视Kubernetes主服务器对服务/端点对象的各种增,删,改等操作。对于每个服务,它配置iptables规则,捕获Service的ClusterIP和端口的流量,并将流量重定向到服务的后端之一。对于每个Endpoint对象,它选择后端Pod的iptables规则
默认情况下,后端的选择是随机的。可通过Service.spec.sessionAffinity设置为“ClientIP”来选择基于客户端IP的会话关联
第三部分:DNS服务发现机制
在Kubernetes系统中,当Pod需要访问其他Service时,可以通过两种方式来发现服务,即环境变量和DNS方式。前者有非常大的局限性,所以实际我们一般都选用第二种DNS方式来实现服务的注册和发现
kube-dns用来为Service分配子域名,以便集群中的Pod可通过域名获取Service的访问地址,通常kube-dns会为Service赋予一个名为“service_name.namespace_name.svc.cluster_domain”的记录,用来解析Service的Cluster_IP。Kubernetes v1.4版本之后,其主要由Kubedns,Dnsmasq,Exechealthz三个组件构成
Kubedns通过Kubernetes API监视Service资源变化并更新DNS记录,主要为Dnsmasq提供查询服务,服务端口是10053
Dnsmasq是一款小巧的DNS配置工具,其在kube-dns插件中的作用是:通过kube-dns容器获取DNS规则,在集群中提供DNS查询服务,提供DNS缓存,提高查询性能,降低kube-dns容器的压力
Exechealthz主要提供监控检查功能

到这里我们其实可以简单描述一下整个Kubernetes之间到底是如何各组件之间进行协作的了!
第四部分:Kubernetes服务
Service是Kubernets最核心的概念,通过创建Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求进行负载均衡分发到后端的各个容器应用上。
Service是一个虚拟的概念,真正实现Service功能的是kube-proxy,kube-proxy起到一个代理和负载均衡的作用
下面我们介绍一下Service的类型
Service的类型,即Service的访问方式
Service的类型默认是ClusterIP
ClusterIP,虚拟服务IP地址,该地址用于Kubernetes集群内部的Pod访问,在Node上kube-proxy通过设置的iptables规则进行转发
NodePort模式,使用宿主机的端口,使能够访问各Node的外部客户端通过Node的IP地址和端口号就能访问服务
LoadBalancer模式:使用外部负载均衡器完成到服务的负载分发,需要在spec.status.loadBalancer字段指定外部负载均衡器的地址,并同时定义nodePort和cluster IP,用于公有云环境
一.ClusterIP
ClusterIP服务是Kubernetes默认的服务类型。如果用户在集群内创建一个服务,
则在集群内部的其他应用程序可以对这个服务进行访问,但是不具备集群外部访问的能力
Service的ClusterIP地址是Kubernetes系统中虚拟的IP地址,由系统动态分配
二.NodePort
NodePort服务是外部访问服务的最基本方式,顾名思义,NodePort就是在所有节点或者虚拟机上开放特点的端口,该端口的流量将被转发到对应的服务

我们来分析一下上图要表达的意思,当集群外部的客户想要访问ServiceA时,它可以访问Host1-10.10.1.2的31600端口,也可以访问Host2-10.10.1.3的31600端口。这两个访问地址最终都会连接到ServiceA上,并且集群内部的Pod还是可以通过访问192.168.1.22这个集群地址来访问到ServiceA
可总结如下:
在具有集群内部IP的基础上,在集群的每个节点上的端口(每个节点上的相同端口)上公开服务。用户可以在任何< Node IP >:NodePort地址上访问
NodePort方式的缺点主要有:
1)每个服务占用一个端口
2)可以使用的范围端口为30000~32767
3)如果节点/虚拟机IP地址发生更改,需要进行相关处理
三. LoadBalancer
LoadBalancer服务是暴露服务至互联网最标准的方案,除了具有集群内部IP以及在NodePort上公开服务之外,还要求云提供商负载均衡将请求转发到每个Node节点的NodePort端口商

来自外部负载均衡器的流量将被定向到后端Pod,尽管其工作原理取决于云提供商。一些云提供商允许指定LoadBalancer IP。在这些情况下,将使用用户指定的LoadBalancerIP创建负载均衡器
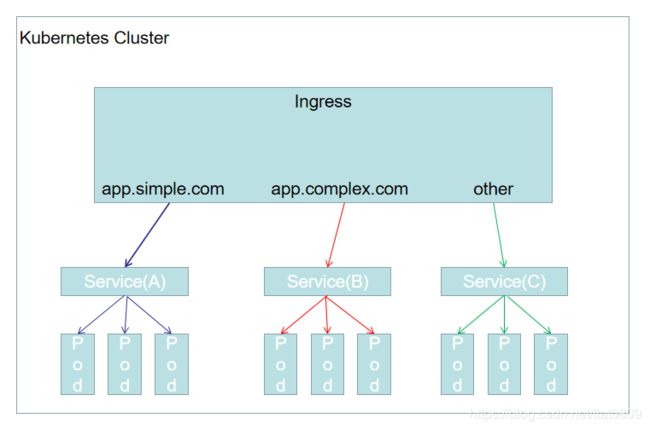
四.Ingress
Ingress并不是服务类型的一种,它位于多个服务的前端,充当一个智能路由表或者集群的入口点,GKE默认的Ingress控制器将启动一个HTTP(S)的负载均衡器,这将使用户可以基于访问路径和子域名将流量路由到后端服务
例如下图,我们可以将app.sample.com下的流量转发到服务A,将app.comlpex.com路径下的流量转发到服务B