spark lda对参数进行调试
online 方法setMaxIter
//对迭代次数进行循环
for(i<-Array(5,10,20,40,60,120,200,500)){
val lda=new LDA()
.setK(3)
.setTopicConcentration(3)
.setDocConcentration(3)
.setOptimizer("online")
.setCheckpointInterval(10)
.setMaxIter(i)
val model=lda.fit(dataset_lpa)
val ll = model.logLikelihood(dataset_lpa)
val lp = model.logPerplexity(dataset_lpa)
println(s"$i $ll")
println(s"$i $lp")
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
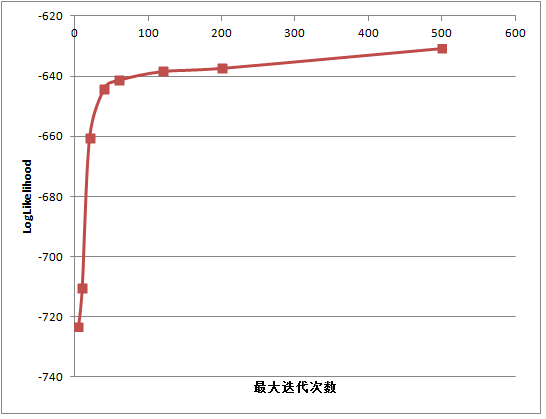
可以得到如下的结果:logPerplexity在减小,LogLikelihood在增加,最大迭代次数需要设置50次以上,才能收敛: 
Dirichlet分布的参数α、β
docConcentration(Dirichlet分布的参数α)
topicConcentration(Dirichlet分布的参数β)
首先要强调的是EM和Online两种算法,上述两个参数的设置是完全不同的。
EM方法:
(1)docConcentration: 只支持对称先验,K维向量的值都相同,必须>1.0。向量-1表示默认,k维向量值为(50/k)+1。
(2)topicConcentration: 只支持对称先验,值必须>1.0。向量-1表示默认。
docConcentration: Only symmetric priors are supported, so all values in the provided k-dimensional vector must be identical. All values must also be >1.0. Providing Vector(-1) results in default behavior (uniform k dimensional vector with value (50/k)+1
topicConcentration: Only symmetric priors supported. Values must be >1.0. Providing -1 results in defaulting to a value of 0.1+1.
由于这些参数都有明确的设置规则,因此也就不存在调优的问题了,计算出一个固定的值就可以了。但是我们还是实验下:
//EM 方法,分析setDocConcentration的影响,计算(50/k)+1=50/5+1=11
for(i<-Array(1.2,3,5,7,9,11,12,13,14,15,16,17,18,19,20)){
val lda=new LDA()
.setK(5)
.setTopicConcentration(1.1)
.setDocConcentration(i)
.setOptimizer("em")
.setMaxIter(30)
val model=lda.fit(dataset_lpa)
val lp = model.logPerplexity(dataset_lpa)
println(s"$i $lp")
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以看出果然DocConcentration>=11后,logPerplexity就不再下降了。 
在确定DocConcentration=11后,继续对topicConcentration分析,发现logPerplexity对topicConcentration不敏感。
1.1 2.602768469
1.2 2.551084142
1.5 2.523405179
2.0 2.524881353
5 2.575868552
Online Variational Bayes
(1)docConcentration: 可以通过传递一个k维等价于Dirichlet参数的向量作为非对称先验。值应该>=0。向量-1表示默认,k维向量值取(1.0/k)。
(2)topicConcentration: 只支持对称先验。值必须>=0。-1表示默认,取值为(1.0/k)。
docConcentration: Asymmetric priors can be used by passing in a vector with values equal to the Dirichlet parameter in each of the k dimensions. Values should be >=0>=0. Providing Vector(-1) results in default behavior (uniform k dimensional vector with value (1.0/k)(1.0/k))
topicConcentration: Only symmetric priors supported. Values must be >=0>=0. Providing -1 results in defaulting to a value of (1.0/k)(1.0/k).
运行LDA的小技巧
(1)确保迭代次数足够多。这个前面已经讲过了。前期的迭代返回一些无用的(极其相似的)话题,但是继续迭代多次后结果明显改善。我们注意到这对EM算法尤其有效。
(2)对于数据中特殊停用词的处理方法,通常的做法是运行一遍LDA,观察各个话题,挑出各个话题中的停用词,把他们滤除,再运行一遍LDA。
(3)确定话题的个数是一门艺术。有些算法可以自动选择话题个数,但是领域知识对得到好的结果至关重要。
(4)特征变换类的Pipeline API对于LDA的文字预处理工作极其有用;重点查看Tokenizer,StopwordsRemover和CountVectorizer接口.
对文本的预处理,还可以参考我的另外两篇文章《Spark2.0 特征提取、转换、选择之一:数据规范化…》《Spark2.0 特征提取、转换、选择之二:特征选择、文本处理…》。