Python+OpenCV+pytesseract 识别 银行卡号
首先给大家看下什么是OCR-A字体:

尽管现代OCR系统不需要专门的字体(如OCR-A),但仍被广泛应用于身份证,报表和信用卡。
下面给出具体的教程:
1. OCR通过模板匹配与OpenCV结合
在本节中,我们将使用Python + OpenCV实现我们的模板匹配算法,以自动识别信用卡数字。
为了实现这一点,我们需要应用一些图像处理操作,包括阈值,计算梯度幅度表示,形态运算和轮廓提取。
由于应用了许多图像处理操作来帮助我们检测和提取信用卡数字,因此当输入图像通过我们的图像处理流程时,我已经包含了大量的输入图像中间截图。
首先,打开新建一个文件,命名为:ocr_template_match.py,插入下列代码:

要安装/升级imutils,只需使用pip:
$ pip install --upgrade imutils
现在我们已经安装并导入了包,我们可以解析我们的命令行参数:

两个必需的命令行参数是:
- 图像:图像的路径为OCR'd。
- 参考:参考OCR-A图像的路径。 该图像包含OCR-A字体中的数字0-9,从而允许我们稍后在管道中执行模板匹配。
接下来我们来定义信用卡类型:

我们通过加载参考OCR-A图像开始我们的图像处理流水线:


图4显示了这些步骤的结果。
现在我们在OCR-A字体图像上找到轮廓:

现在,我们应该循环浏览轮廓,提取ROI并将其与相应的数字相关联:

在这一点上,我们完成了从参考图像中提取数字,并将它们与相应的数字名称相关联。
我们的下一个目标是在输入图像中隔离16位数的信用卡号。 我们需要找到并隔离数字,才能启动模板匹配来识别每个数字。 这些图像处理步骤是非常有趣和有见地的。

我们继续初始化几个构造核函数的结构:

现在让我们准备我们要去OCR的图像:

我们来看看我们的输入图像:

随后我们调整大小和灰度级操作:

现在我们的形象是灰色的,大小一致,我们来进行一个形态的操作:

顶帽操作可以在下面的结果图中看到黑暗背景下的亮区(即信用卡号)。

给定我们的tophat图像,我们来计算沿x方向的渐变:
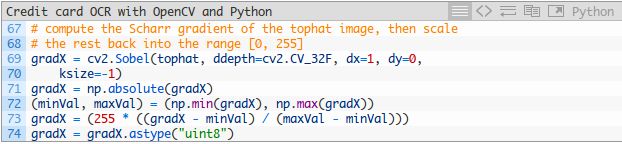
结果如下图所示:

让我们继续改进信用卡数位查找算法:
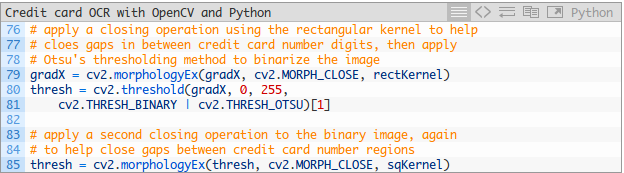
这些步骤的结果如下所示:

接下来,我们找到轮廓并初始化数字分组位置列表。

现在让我们循环浏览轮廓,同时根据每个轮廓的宽高比进行过滤,从而使我们从信用卡的其他不相关的区域修剪数字组的位置:

以下图片显示了我们发现的分组 - 为了演示的目的,我让OpenCV在每个组周围绘制一个边框:

接下来,我们将从左到右对分组进行排序,并初始化信用卡数位列表:

现在我们知道每个四位数字的位置,让我们循环四个排序的分组,并确定其中的数字。
这个循环很长,被分解成三个代码块 - 这是第一个块:
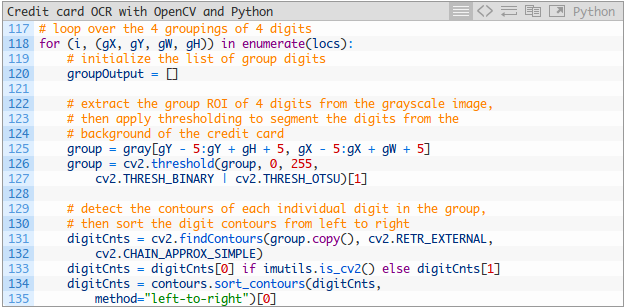
以下显示的是一组已被提取的组:

让我们用一个嵌套循环继续循环来做模板匹配和相似性分数提取:

最后,我们围绕每个组绘制一个矩形,并以红色文字查看图像上的信用卡号码:
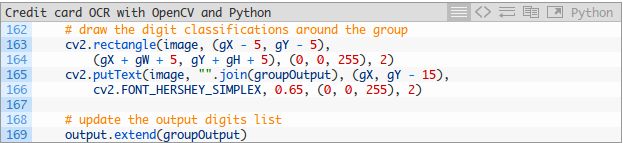
要了解脚本操作是如何的,我们将结果输出到终端,并在屏幕上显示我们的图像。

花一点时间来祝贺你 - 你做到了最后。 要重写(在高级别),这个脚本:
1)在字典中存储信用卡类型。
2)获取参考图像并提取数字。
3)在字典中存储数字模板。
4)本地化四个信用卡号码组,每个号码组分为四位数字(共十六位数字)。
5)提取要匹配的数字。
6)对每个数字执行模板匹配,将每个单独的ROI与每个数字模板0-9进行比较,同时存储每次尝试匹配的分数。
7)找到每个候选人数字的最高分数,并构建一个名为output的列表,其中包含信用卡号码。
8)将信用卡号和信用卡类型输出到我们的终端,并将输出图像显示在我们的屏幕上。
现在是时候看到脚本运行,并检查我们的结果。
2. 信用卡OCR系统展示结果
现在我们已经实现了我们的信用卡OCR系统,让我们来看一下。(源代码在下文的原文链接中,直接到“Downloads”模块下填入邮箱后获取)
我们显然不能使用真实的信用卡号码,所以我收集了一些使用Google的信用卡示例图。 这些信用卡显然是假的,仅供演示用途。
但是,您可以在此博客中应用相同的技术来识别实际的真实信用卡上的数字。
要查看我们的信用卡OCR系统的操作,打开一个终端并执行以下命令:
$ python ocr_template_match.py --reference ocr_a_reference.png \
我们的第一个结果图像,100%正确:


请注意,只需通过检查信用卡号码中的第一位数字即可将信用卡正确标记为万事达卡。
现在,你已经完成了OCR识别信用卡了,是不是很激动。
最后我们来总结一下:
在本教程中,我们学习了如何使用OpenCV和Python使用模板匹配来执行光学字符识别(OCR)。
具体来说,我们应用了我们的模板匹配OCR方法来识别信用卡的类型以及16个信用卡数字。
为了实现这一点,我们将图像处理流程分为四个步骤:
1)通过各种图像处理技术检测信用卡上的四组数字,包括形态运算,阈值和轮廓提取。
2)从四个分组中提取每个单个数字,导致需要分类的16位数字。
3)通过将模板匹配与OCR-A字体进行比较,以获得我们的数字分类,将模板匹配应用于每个数字。
4)检查信用卡号码的第一位,以确定发行公司。
在评估我们的信用卡OCR系统后,我们发现它是100%准确的,只要发卡信用卡公司使用OCR-A字体的数字。
要扩展此应用程序,您将需要在野外收集信用卡的真实图像,并可能通过标准特征提取或训练或卷积神经网络来训练机器学习模型,以进一步提高该系统的准确性。
附上原文链接:https://www.pyimagesearch.com/2017/07/17/credit-card-ocr-with-opencv-and-python/
原作者链接:https://www.cnblogs.com/wmr95/p/7643155.html