机器学习实战之KNN算法
前段时间在京东上购买了这本很多人都推荐的书---机器学习实战。刚刚看完第一章,感觉本书很适合 初学者,特别是对急于应用机器学习但又不想深究理论的小白(像我这样的)。不过在这里还是推荐一下李航老师的那本《统计学习方法》,该书注重理论推导及挖掘算法背后的数学本质,和《机器学习实战》配合起来学习,可以达到事半功倍的效果。有这两本书基本可以让我们这些小白开始起飞了。


看完《统计学习方法》的KNN算法推导,虽然知道了该算法的理论基础,但是对KNN算法还是没有一个宏观的把握,这样估计几天就会忘得一干二净。这几天抽空将《机器学习实战》中的KNN代码动手自己写了一遍,实践以后确实对它有了更深的理解,也知道了它的适用范围。本书是用python语言写的,确实是个正确的选择,感觉用起来很像matlab,特别方便。不过听实验室某位大神说搞大数据R语言用的也不少,现在真心感觉要学语言实在太多了。在大数据领域,两大王牌软件spark和hadoop分别是用scala和java写的,统计处理又推荐使用R,平时仿真又是python。对于我们这种一直用C/C++的,平时没写过什么软件应用,一下子要学这么多高级语言,实在有点招架不住啊!
废话不多说,谁让我铁了心要进军大数据的。兄弟们,拿起python来。开干。。。
KNN算法概况起来一句话:在样本数据中,距离测试样本点的一定范围内,寻找最多的一种样本类型,作为测试点的类型。距离可以是欧式距离,也可以非欧式距离,看具体的情况而定。至于范围大小的选取至关重要,目前貌似学术界也没什么办法可以算出哪个范围最好,所以工程上一般都是穷举测试。然后就是样本点和测试点的构建了,其实也就是特征提取,这部分是最最重要的,这直接决定了机器学习算法的准确性。如果特征不好,即使你的机器学习算法再好也没用。如果特征很棒,即使用的不是最优的机器学习算法效果也不错。这是实验室大牛说的。他说在各种大数据竞赛里,后面起决定性作用的是特征选择与提取,而不是算法(目前是这样的)。当然,非监督学习除外,因为它根本就不用特征提取。至于怎样选择特征最有效,这就要结合具体数据,具体问题而言了。本菜也不在这里YY了。
书中用了两个实例来测试KNN算法, 一个是约会对象判断,一个是数字识别。本人觉得还是数字识别比较有趣,因为可以自己动手测试一下,特别有成就感。废话不多说,上代码:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
"""
Created on Aug 29, 2015
@author: freestyle4568
this module is kNN method, classifying something.
"""
import numpy as np
import operator
def createdataset():
"""该函数用于产生kNN实验用列,返回样本数据集(numpy数组)和样本类型集(列表)
Keyword arguments:
None
"""
group = np.array([[1.0, 1.1],
[1.0, 1.0],
[0, 0],
[0, 0.1]
])
labels = ['A', 'A', 'B', 'B']
return group, labels
def classify(testData, dataSet, labels, k):
"""应用KNN方法对测试点进行分类,返回一个结果类型
Keyword argument:
testData: 待测试点,格式为数组
dataSet: 训练样本集合,格式为矩阵
labels: 训练样本类型集合,格式为数组
k: 近邻点数
"""
dataSetSize = dataSet.shape[0]
multitestData = np.tile(testData, (dataSetSize, 1))
diffMat = multitestData - dataSet
sqdiffMat = diffMat**2
sqdistance = sqdiffMat.sum(axis=1)
#print(sqdistance)
distance = sqdistance**0.5
sortedDistIndex = distance.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndex[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
#print(sortedClassCount)
return sortedClassCount[0][0]
if __name__ == '__main__':
import matplotlib.pyplot as plt
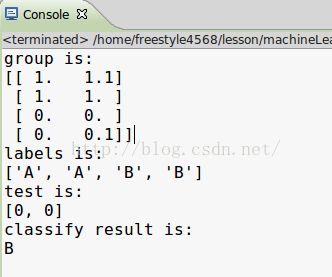
group, labels = createdataset()
print('group is:')
print(group)
print('labels is:')
print(labels)
plt.plot(group[:, 0], group[:, 1], 'o')
plt.xlim(-0.1, 1.2)
plt.ylim(-0.1, 1.2)
plt.show()
test = [0, 0]
print('test is:')
print(test)
print('classify result is:')
print(classify(test, group, labels, 3))
1.绘制出了测试点在特征空间中的坐标
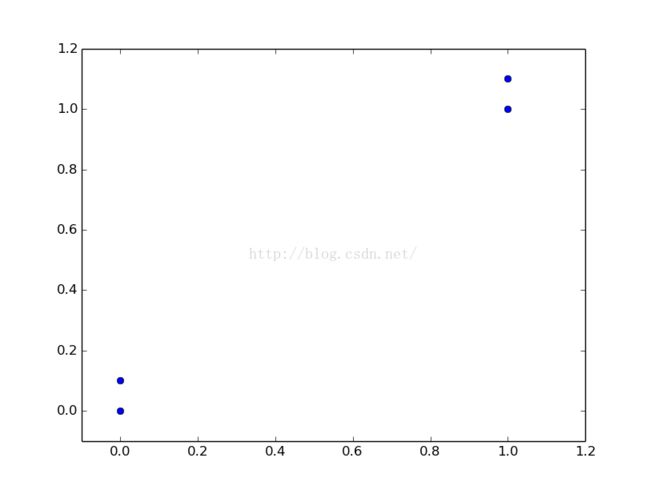
2.测试点为main函数中写的,(0,0),分类结果为B,KNN算法函数编写正确。
KNN算法构建好了,来进行第一个有趣的实验,约会对象分类实验。实验说明:本人特别喜欢约会,并且会给各个约会对象打分,分为三个档次:非常喜欢,一般喜欢,不喜欢。每个对象特征现成的,已经提取好了,如:鼻子多少分,嘴巴多少分,喜欢运动否,每天跑多少步等。再进行KNN的时候有个坑,就是各个特征范围不一样,有的大有的小,在计算欧式距离时小范围的特征当然不占优势,为了避免这种情况需要将特征进行归一化处理。然后再进行KNN分类,作者给出了测试用例和样本数据,所以可以借此来看看KNN算法的可靠性。
约会实例构建:(里面用到前面我们写的KNN算法,所以记得import kNN哦)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
Created on Aug 29, 2015
@author: freestyle4568
'''
import numpy as np
import kNN
def file2matrix(filename):
"""该函数将约会文件内容转换成数据处理格式,返回一个测试特征集(格式二维数组),和测试集类别集(格式列表)
Keyword argument:
filename -- 约会数据所在的路径,最好是绝对路径
"""
fr = open(filename)
arrayOnLines = fr.readlines()
numberOfLines = len(arrayOnLines)
returnMat = np.zeros((numberOfLines, 3))
classLabel = []
for i in range(numberOfLines):
line = arrayOnLines[i]
line = line.strip()
listFromLine = line.split('\t')
returnMat[i, :] = listFromLine[0:3]
classLabel.append(int(listFromLine[-1]))
return returnMat, classLabel
def autoNorm(dataSet):
"""该函数将数据集的所以特征归一化,返回归一化后的特征集(格式为数组),特征集最小值(格式为一维数组),特征集范围(格式为一维数组)
Keyword argument:
dataSet -- 特征数据集
"""
minVals = dataSet.min(axis=0)
maxVals = dataSet.max(axis=0)
ranges = maxVals - minVals
dataSize = dataSet.shape[0]
normDataSet = dataSet - np.tile(minVals, (dataSize, 1))
normDataSet = normDataSet / np.tile(ranges, (dataSize, 1))
return normDataSet, minVals, ranges
def dateClassTest(filename, k):
"""测试KNN算法对于约会数据的错误率
Keyword argument:
None
"""
ratio = 0.10
dataSet, labels = file2matrix(filename)
normDateSet, minVals, ranges = autoNorm(dataSet)
dataSize = dataSet.shape[0]
numTestVecs = int(dataSize*ratio)
errorcount = 0.0
print("m : %d" % dataSize)
for i in range(numTestVecs):
classifyResult = kNN.classify(normDateSet[i, :], normDateSet[numTestVecs:dataSize, :],\
labels[numTestVecs:dataSize], k)
if classifyResult != labels[i]:
errorcount += 1
print("the real answer is: %d, the classify answer is: %d" % (labels[i], classifyResult))
print("the total error ratio is %f" % (errorcount/float(numTestVecs)))
if __name__ == '__main__':
filename = '/home/freestyle4568/lesson/machineLearning/machinelearninginaction/Ch02/datingTestSet2.txt'
dateClassTest(filename, 3)
可以到在本例中KNN的错误率为5%。还是相当不错的。(不过书上测试的书2.4%,难道数据更新过了,还是我KNN写错了,应该不会吧)
这里选取K值为3。感兴趣的同学可以试试改改K值看看,通过改变范围大小,KNN的准确率怎么变化。
当K值取所以样本数量时,会发现KNN准确率会怎么样?当K取1时会怎么样?
留给各位思考啦!!!
再看下面一个更有趣的例子----数字识别。这个很好理解,就是给一个0-9的数字图片,然后通过KNN看分类结果是多少。
看具体代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
Created on Aug 31, 2015
@author: freestyle4568
'''
import numpy as np
import os
import kNN
def img2vector(filename):
"""函数将以文本格式出现的32*32的0-1图片,转变成一维特征数组,返回一维数组
Keyword argument:
filename -- 文本格式的图片文件
"""
imgvect = np.zeros((1, 1024))
fr = open(filename)
for i in range(32):
linestr = fr.readline()
for j in range(32):
imgvect[0, 32*i + j] = int(linestr[j])
return imgvect
def handwriteClassfiy(testfile, trainfile, k):
"""函数将trainfile中的文本图片转换成样本特征集和样本类型集,用testfile中的测试样本测试,无返回值
Keyword argument:
testfile -- 测试图片目录
trainfile -- 样本图片目录
"""
trainFileList = os.listdir(trainfile)
trainFileSize = len(trainFileList)
labels = []
trainDataSet = np.zeros((trainFileSize, 1024))
for i in range(trainFileSize):
filenameStr = trainFileList[i]
digitnameStr = filenameStr.split('.')[0]
digitLabels = digitnameStr.split('_')[0]
labels.append(digitLabels)
trainDataSet[i, :] = img2vector(trainfile + '/' + filenameStr)
testFileList = os.listdir(testfile)
testNumber = len(testFileList)
errorcount = 0.0
for testname in testFileList:
testdigit = img2vector(testfile + '/' + testname)
classifyresult = kNN.classify(testdigit, trainDataSet, labels, k)
testStr = testname.split('.')[0]
testDigitLabel = testStr.split('_')[0]
if classifyresult != testDigitLabel:
errorcount += 1.0
#print('this test real digit is:%s, and the result is: %s' % (testDigitLabel, classifyresult))
print('k = %d, errorRatio is: %f' % (k, errorcount/float(testNumber)))
return
if __name__ == '__main__':
filename = '/home/freestyle4568/lesson/machineLearning/machinelearninginaction/Ch02/digits/trainingDigits/0_0.txt'
traindir= '/home/freestyle4568/lesson/machineLearning/machinelearninginaction/Ch02/digits/trainingDigits'
testdir = '/home/freestyle4568/lesson/machineLearning/machinelearninginaction/Ch02/digits/testDigits'
handwriteClassfiy(testdir, traindir, 3)
正如代码中写的,我们先读入图片所在目录,然后将目录中的文本格式的二值图片文件转变为一维特征矩阵。然后代入我们的KNN算法,得出分类结果,还是一样的,让我们看看这次数字识别的效果。

运行了很长的时间,电脑风扇狂转有没有,最后结果准确率高达1.3%。
被KNN的准确率震惊到了。不过细细一想,也可能是由于作者准备的数字测试图片恰好比较规范,和测试样例比较接近,导致了这么高的准确率。抱着这种想法,我就打算自己在网上搜点手写数字图片下来,用python将图片二值化一下,大小转换成统一的32*32。然后按照作者的命名方式放在mydigit目录下面。
这些是我在百度图片里面下的手写图片:






为了节约时间,这里就不把所有图片贴出来了,感兴趣的同学可以自己下一些测试一下。
我先将下来的图片放在一个imgfile目录里面,然后将处理过的文本图片放在一个mydigit目录下面。
贴一个我处理过的图片4:
00000000000000000000000000000000
00000000000000000000000000000000
00000000000000000000000000000000
00000000000000001111000000000000
00000000000000001111000000000000
00000000000000011111000000000000
00000000000000111111100000000000
00000000000001111111100000000000
00000000000011111111100000000000
00000000000011110111000000000000
00000000000111100111000000000000
00000000011111000111000000000000
00000000011110000111000000000000
00000000111100000111000000000000
00000000111100000111000000000000
00000001111000001111000000000000
00000011111111100111110000000000
00000011111111111111111111111000
00000001111111111111111111111000
00000000000000011111001111110000
00000000000000001111000000000000
00000000000000001111000000000000
00000000000000001111000000000000
00000000000000001110000000000000
00000000000000001110000000000000
00000000000000001110000000000000
00000000000000011110000000000000
00000000000000011110000000000000
00000000000000001110000000000000
00000000000000001110000000000000
00000000000000000110000000000000
00000000000000000000000000000000
是不是很带感,再来一个8吧:
00000000000000000000000000000000
00000000000000000000000000000000
00000000000011111110000000000000
00000000000010000110000000000000
00000000001100000010000000000000
00000000001100000011000000000000
00000000001100000011000000000000
00000000001100000001000000000000
00000000000100000001000000000000
00000000001110000011000000000000
00000000000110000011000000000000
00000000000011000011000000000000
00000000000001111110000000000000
00000000000000011110000000000000
00000000000000111110000000000000
00000000000001110110000000000000
00000000000001110011000000000000
00000000000011000011000000000000
00000000000011000011100000000000
00000000000110000000100000000000
00000000000110000001101000000000
00000000000110000000111000000000
00000000000100000000110000000000
00000000001100000000111000000000
00000000001100000000011000000000
00000000001000000000010000000000
00000000001100000000110000000000
00000000000110000000010000000000
00000000000101000000100000000000
00000000000111000001100000000000
00000000000011111111000000000000
00000000000000000000000000000000
我的处理代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
Created on Sep 1, 2015
@author: freestyle4568
'''
import numpy as np
import os
import Image
def changeImgFile(imgDir):
"""该函数将图片格式的文件转换成32*32的文本格式图片,并删除原来的图片格式文件,无返回值
Keyword argument:
imgDir -- 保存图片的目录
"""
imgFileList = os.listdir(imgDir)
print imgFileList
imgNumber = len(imgFileList)
for i in range(imgNumber):
imgName = imgFileList[i]
print imgName
imgBig = Image.open(imgDir + '/' + imgName)
imgNormal = imgBig.resize((32, 32))
digitImg = imgNormal.convert('L')
digit_mat = digitImg.load()
fr = open(imgDir+'/../mydigit/'+str(i), 'w')
for i in range(32):
for j in range(32):
if digit_mat[j, i] != 255:
fr.write('1')
else:
fr.write('0')
fr.write('\n')
fr.close()
if __name__ == '__main__':
imgDir = '/home/freestyle4568/lesson/machineLearning/kNNinAction/imgfile'
changeImgFile(imgDir)
测试图片处理好了,下面直接调用我们之前的代码,只需要将目录路径改一下就可以了。
快来看看测试结果:
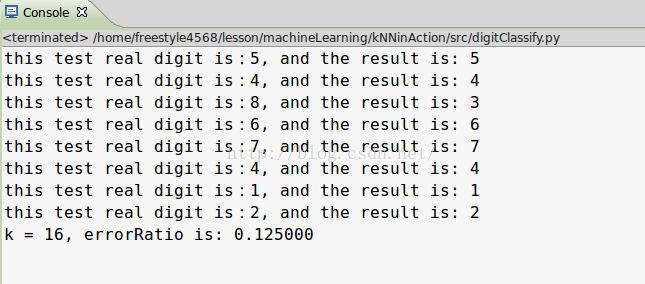
尖叫吧,欢呼吧,居然只有一个错了,可喜可贺,这里终于可以看到KNN的真正威力了。
可是为什么我这里K取16呢?
答对了,我是先扫描,再取错误率最小的k值的。想不想看看我的扫描结果(电脑可是嗡嗡直叫啊),可是我怎么一点也不心疼。。。。

好啦,今天的KNN实践就见到这里啦,具体的理论看有时间在补上。(这可是我在教研室偷偷码的)