ubuntu16.04+python+anaconda+tensorflow的深度学习1
目录
1、可视化Tensorflow
2、TensorFlow 基础知识
2.1 数据流图简介
2.1.1 数据流图基础
2.1.2 节点的依赖关系
2.2 在TensorFlow中定义数据流图
2.2.1 构建第一个Tensorflow 数据流图
writer = tf.summary.FileWriter('./my_graph', sess.graph)
2.2.2张量思维
2.2.3 张量的形状
2.2.4 TensorFlow的Operation
2.2.5 TensorFlow的Graph对象
2.2.6 TensorFlow Session
2.2.7 利用占位节点添加输入
2.2.8 Variable对象
2.3 通过名称作用域组织数据流图
2.4 练习:综合运用各种组件
拓展知识点1
2.4.1 构建数据流图
拓展知识1:API--tf.summary.scalar
拓展知识2 :函数tf.cast 类型转换 函数
拓展知识3 :TensorFlow中的数据
拓展知识4 tensorflow 1.0 的些许修改
拓展知识5 python函数中的位置参数、默认参数、关键字参数、可变参数区别
拓展知识6 Python PEP8 编码规范中文版
2.4.2 运行数据流图
拓展知识1: 用pycharm写python的时候,总会在def function()的那行出现如下错误
2.5 系统架构
2.6 设计理念
2.7、编程模型
2.7.1 边
拓展知识:详解Tensor与Flow
2.7.2 节点
拓展部分
2.7.3 其他概念
拓展知识1 python中的比较:==和is的区别
拓展知识2:tf.constant 函数
2.7.4 了解模型的运行机制
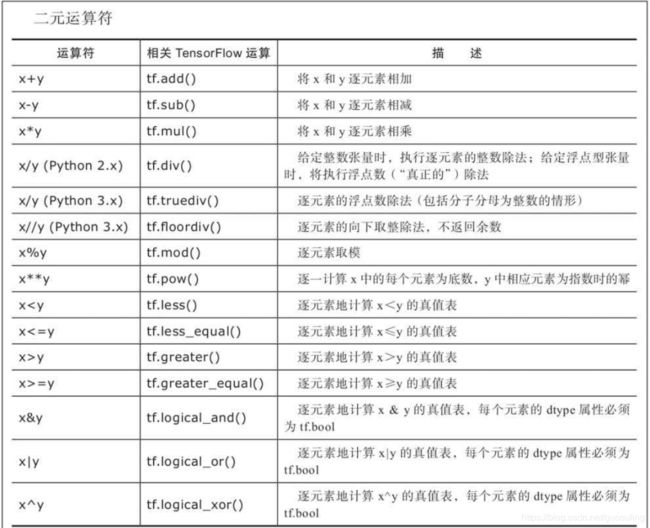
2.8 常用API
2.8.1 图、操作和张量
2.8.2 可视化
2.9 变量作用域
2.9.1 variable_scope 示例
2.9.2 name_scope 示例
1、可视化Tensorflow
TensorBoard 是 TensorFlow 自带的一个强大的可视化工具,也是一个 Web 应用程序套件。TensorBoard 目前支持 7 种可视化,即 SCALARS、IMAGES、AUDIO、GRAPHS、DISTRIBUTIONS、HISTOGRAMS 和 EMBEDDINGS。这 7 种可视化的主要功能如下
● SCALARS【scalars:标量】:展示训练过程中的准确率、损失值、权重/偏置的变化情况。
● IMAGES【images:图像】:展示训练过程中记录的图像。
● AUDIO【audio:音频】:展示训练过程中记录的音频。
● GRAPHS【graphs:图】:展示模型的数据流图,以及训练在各个设备上消耗的内存和时间。
● DISTRIBUTIONS【distributions:分布】:展示训练过程中记录的数据的分布图。
● HISTOGRAMS【histograms:直方图】:展示训练过程中记录的数据的柱状图。
● EMBEDDINGS【embeddings:嵌入】:展示词向量(如 Word2vec)后的投影分布。
TensorBoard 通过运行一个本地服务器,来监听 6006 端口。在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的图像。
2、TensorFlow 基础知识
2.1 数据流图简介
2.1.1 数据流图基础
借助TensorFlowAPI用代码描述的数据流图是每个TensorFlow程序的核心。毫不意外,数据流图这种特殊类型的有向图正是用于定义计算结构的。在TensorFlow中,数据流图本质上是一组链接在一起的函数,每个函数都会将其输出传递给0个、1个或更多位于这个级联链上的其他函数。按照这种方式,用户可利用一些很小的、为人们所充分理解的数学函数构造数据的复杂变换。下面来看一个比较简单的例子。
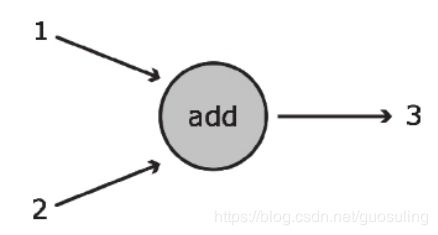
上图展示了可完成基本加法运算的数据流图。在该图中,加法运算是用圆圈表示的,它可接收两个输入(以指向该函数的箭头表示),并将1和2之和3输出(对应从该函数引出的箭头)。该函数的运算结果可传递给其他函数,也可直接返回给客户。
该数据流图可用如下简单公式表示:

上面的例子解释了在构建数据流图时,两个基础构件——节点和边是如何使用的。下面回顾节点和边的基本性质:
·节点(node) :在数据流图的语境中,节点通常以圆圈、椭圆和方框表示,代表了对数据所做的运算或某种操作。在上例中,“add”对应于一个孤立节点
边(edge) :对应于向Operation传入和从Operation传出的实际数值,通常以箭头表示。在“add”这个例子中,输入1和2均为指向运算节点的边,而输出3则为从运算节点引出的边。可从概念上将边视为不同Operation之间的连接,因为它们将信息从一个节点传输到另一个节点。
下面来看一个更有趣的例子。

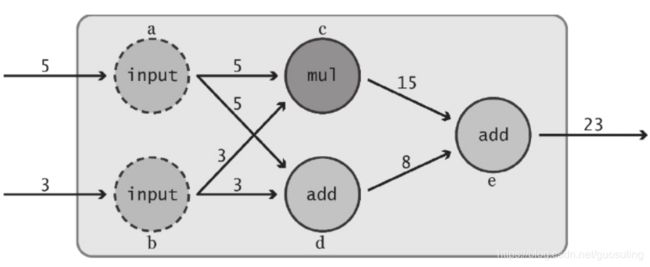
相比之前的例子,上图所示的数据流图略复杂。由于数据是从左侧流向右侧的(如箭头方向所示),因此可从最左端开始对这个数据流图进行分析
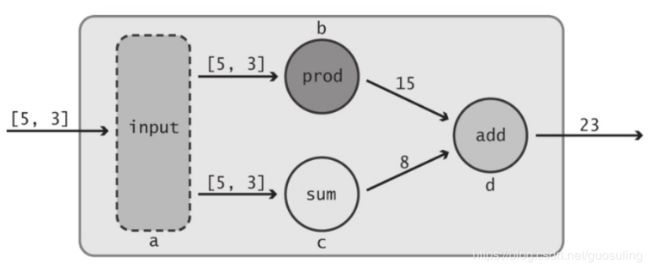
1)最开始时,可看到两个值5和3流入该数据流图。它们可能来自另一个数据流图,也可能读取自某个文件,或是由客户直接输入
2)这些初始值被分别传入两个明确的“input”节点(图中分别以a、b标识)。这些“input”节点的作用仅仅是传递它们的输入值——节点a接收到输入值5后,将同样的数值输出给节点c和节点d,节点b对其输入值3也完成同样的动作。
3)节点c代表乘法运算。它分别从节点a和b接收输入值5和3,并将运算结果15输出到节点e。与此同时,节点d对相同的两个输入执行加法运算,并将计算结果8传递给节点e
4)最后,该数据流图的终点——节点e是另一个“add”节点。它接收输入值15和8,将两者相加,然后输出该数据流图的最终结果23
下面说明为何上述图形表示看起来像是一组公式

当a=5、b=3时,若要求解e,只需依次代入上述公式

经过上述步骤,便完成了计算,这里有一些概念值得重点说明
·上述使用“input”节点的模式十分有用,因为这使得我们能够将单个输入值传递给大量后继节点。如果不这样做,客户(或传入这些初值的其他数据源)便不得不将输入值显式传递给数据流图中的多个节点。按照这种模式,客户只需保证一次性传入恰当的输入值,而如何对这些输入重复使用的细节便被隐藏起来。稍后,我们将对数据流图的抽象做更深入的探讨
突击小测验。哪一个节点将首先执行运算?是乘法节点c还是加法节点d?答案是:无从知晓。仅凭上述数据流图,无法推知c和d中的哪一个节点将率先执行。有的读者可能会按照从左到右、自上而下的顺序阅读该数据流图,从而做出节点c先运行的假设。但我们需要指出,在该数据流图中,将节点d绘制在c的上方也未尝不可。也可能有些读者认为这些节点会并发执行,但考虑到各种实现细节或硬件的限制,实际情况往往并非总是如此。实际上,最好的方式是将它们的执行视为相互独立。由于节点c并不依赖于来自节点d的任何信息,所以节点c在完成自身的运算时无需关心节点d的状态如何。反之亦然,节点d也不需要任何来自节点c的信息。
接下来,对上述数据流图稍做修改

主要的变化有两点:
1)来自节点b的“input”值3现在也传递给了节点e。
2)节点e中的函数“add”被替换为“sum”,表明它可完成两个以上的数的加法运算。
你已经注意到,上图在看起来被其他节点“隔离”的两个节点之间添加了一条边。一般而言,任何节点都可将其输出传递给数据流图中的任意后继节点,而无论这两者之间发生了多少计算。数据流图甚至可以拥有下图所示的结构,它仍然是完全合法的

通过这两个数据流图,想必你已能够初步感受到对数据流图的输入进行抽象所带来的好处。我们能够对数据流图中内部运算的精确细节进行操控,但客户只需了解将何种信息传递给那两个输入节点则可。我们甚至可以进一步抽象,将上述数据流图表示为如下的黑箱。

这样,我们便可将整个节点序列视为拥有一组输入和输出的离散构件。这种抽象方式使得对级联在一起的若干个运算组进行可视化更加容易,而无需关心每个部件的具体细节
2.1.2 节点的依赖关系
在数据流图中,节点之间的某些类型的连接是不被允许的,最常见的一种是将造成循环依赖(circular dependency)的连接。为理解“循环依赖”这个概念,需要先理解何为“依赖关系”。再次观察下面的数据流图。
循环依赖这个概念其实非常简单:对于任意节点A,如果其输出对于某个后继节点B的计算是必需的,则称节点A为节点B的依赖节点。如果某个节点A和节点B彼此不需要来自对方的任何信息,则称两者是独立的。为对此进行可视化,首先观察当乘法节点c出于某种原因无法完成计算时会出现何种情况
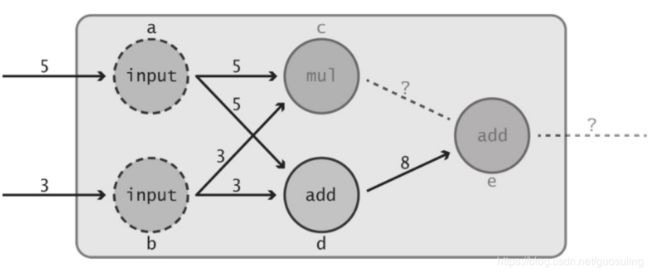
可以预见,由于节点e需要来自节点c的输出,因此其运算无法执行,只能无限等待节点c的数据的到来。容易看出,节点c和节点d均为节点e的依赖节点,因为它们均将信息直接传递到最后的加法函数。然而,稍加思索便可看出节点a和节点b也是节点e的依赖节点。如果输入节点中有一个未能将其输入传递给数据流图中的下一个函数,情形会怎样?
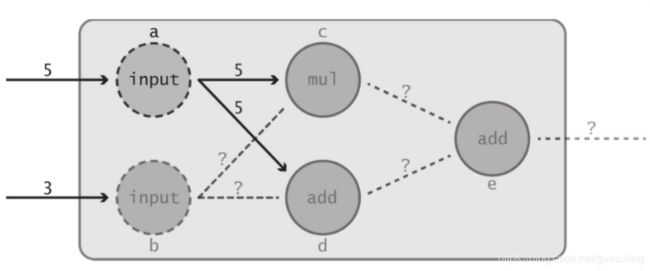
可以看出,若将输入中的某一个移除,会导致数据流图中的大部分运算中断,从而表明依赖关系具有传递性。即,若A依赖于B,而B依赖于C,则A依赖于C。在本例中,最终节点e依赖于节点c和节点d,而节点c和节点d均依赖于输入节点b。因此,最终节点e也依赖于输入节点b。同理可知节点e也依赖于输入节点a。此外,还可对节点e的不同依赖节点进行区分
1)称节点e直接依赖 于节点c和节点d。即为使节点e的运算得到执行,必须有直接来自节点c和节点d的数据
2)称节点e间接依赖 于节点a和节点b。这表示节点a和节点b的输出并未直接传递到节点e,而是传递到某个(或某些)中间节点,而这些中间节点可能是节点e的直接依赖节点,也可能是间接依赖节点。这意味着一个节点可以是被许多层的中间节点相隔的另一个节点的间接依赖节点(且这些中间节点中的每一个也是后者的依赖节点)。
最后来观察将数据流图的输出传递给其自身的某个位于前端的节点时会出现何种情况。

不幸的是,上面的数据流图看起来无法工作。我们试图将节点e的输出送回节点b,并希望该数据流图的计算能够循环进行。这里的问题在于节点e现在变为节点b的直接依赖节点;而与此同时,节点e仍然依赖于节点b(前文已说明过)。其结果是节点b和节点e都无法得到执行,因为它们都在等待对方计算的完成
也许你非常聪明,决定将传递给节点b或节点e的值设置为某个初始状态值。毕竟,这个数据流图是受我们控制的。不妨假设节点e的输出的初始状态值为1,使其先工作起来

上图给出了经过几轮循环各数据流图中各节点的状态。新引入的依赖关系制造了一个无穷反馈环,且该数据流图中的大部分边都趋向于无穷大。然而,出于多种原因,对于像TensorFlow这样的软件,这种类型的无限循环是非常不利的。
1)由于数据流图中存在无限循环,因此程序无法以优雅的方式终止
2)依赖节点的数量变为无穷大,因为每轮迭代都依赖于之前的所有轮次的迭代。不幸的是,在统计依赖关系时,每个节点都不会只被统计一次,每当其输出发生变化时,它便会被再次记为依赖节点。这就使得追踪依赖信息变得不可能,而出于多种原因(详见本节的最后一部分),这种需求是至关重要的
3)你经常会遇到这样的情况:被传递的值要么在正方向变得非常大(从而导致上溢),要么在负方向变得非常大(导致下溢),或者非常接近于0(使得每轮迭代在加法上失去意义)
基于上述考虑,在TensorFlow中,真正的循环依赖关系是无法表示的,这并非坏事。在实际使用中,完全可通过对数据流图进行有限次的复制,然后将它们并排放置,并将代表相邻迭代轮次的副本的输出与输入串接。该过程通常被称为数据流图的“展开”(unrolling)。
为了以图形化的方式展示数据流图的展开效果,下面给出一个将循环依赖展开5次后的数据流图

对这个数据流图进行分析,便会发现这个由各节点和边构成的序列等价于将之前的数据流图遍历5次。请注意原始输入值(以数据流图顶部和底部的跳跃箭头表示)是传递给数据流图的每个副本的,因为代表每轮迭代的数据流图的每个副本都需要它们。按照这种方式将数据流图展开,可在保持确定性计算的同时模拟有用的循环依赖
既然我们已理解了节点的依赖关系,接下来便可分析为什么追踪这种依赖关系十分有用。不妨假设在之前的例子中,我们只希望得到节点c(乘法节点)的输出。我们已经定义了完整的数据流图,其中包含独立于节点c和节点e(出现在节点c的后方)的节点d,那么是否必须执行整个数据流图的所有运算,即便并不需要节点d和节点e的输出?答案当然是否定的。观察该数据流图,不难发现,如果只需要节点c的输出,那么执行所有节点的运算便是浪费时间。但这里的问题在于:如何确保计算机只对必要的节点执行运算,而无需手工指定?答案是:利用节点之间的依赖关系!
这背后的概念相当简单,我们唯一需要确保的是为每个节点的直接(而非间接)依赖节点维护一个列表。可从一个空栈开始,它最终将保存所有我们希望运行的节点。从你希望获得其输出的节点开始。显然它必须得到执行,因此令其入栈。接下来查看该输出节点的依赖节点列表,这意味着为计算输出,那些节点必须运行,因此将它们全部入栈。然后,对所有那些节点进行检查,看它们的直接依赖节点有哪些,然后将它们全部入栈。继续这种追溯模式,直到数据流图中的所有依赖节点均已入栈。按照这种方式,便可保证我们获得运行该数据流图所需的全部节点,且只包含所有必需的节点。此外,利用上述栈结构,可对其中的节点进行排序,从而保证当遍历该栈时,其中的所有节点都会按照一定的次序得到运行。唯一需要注意的是需要追踪哪些节点已经完成了计算,并将它们的输出保存在内存中,以避免对同一节点反复计算。按照这种方式,便可确保计算量尽可能地精简,从而在规模较大的数据流图上节省以小时计的宝贵处理时间。
2.2 在TensorFlow中定义数据流图
你将接触到多样化的以及相当复杂的机器学习模型。然而,不同的模型在TensorFlow中的定义过程却遵循着相似的模式。当掌握了各种数学概念,并学会如何实现它们时,对TensorFlow核心工作模式的理解将有助于你脚踏实地开展工作。幸运的是,这个工作流非常容易记忆,它只包含两个步骤:
1)定义数据流图。
2)运行数据流图(在数据上)
这里有一个显而易见的道理,如果数据流图不存在,那么肯定无法运行它。头脑中有这种概念是很有必要的,因为当你编写代码时会发现TensorFlow功能是如此丰富。每次只需关注上述工作流的一部分,有助于更周密地组织自己的代码,并有助于明确接下来的工作方向
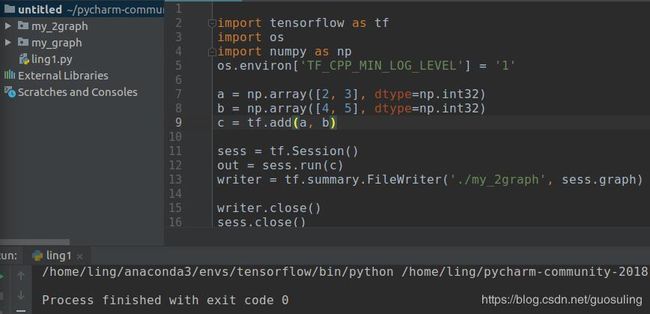
2.2.1 构建第一个Tensorflow 数据流图
通过上一节的介绍,我们已对如下数据流图颇为熟悉。

用于表示该数据流图的TensorFlow代码如下所示:
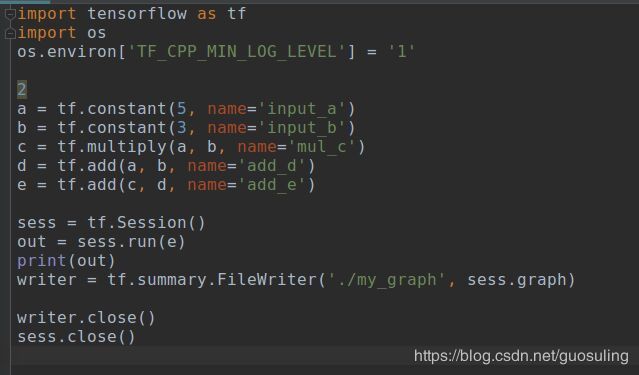
下面来逐行解析这段代码。首先,你会注意到下列导入语句:

毫不意外,这条语句的作用是导入TensorFlow库,并赋予它一个别名——tf。按照惯例,人们通常都是以这种形式导入TensorFlow的,因为在使用该库中的各种函数时,键入“tf”要比键入完整的“tensorflow”容易得多。
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]='1' # 这是默认的显示等级,显示所有信息,对于代码运行没有影响
接下来研究前两行变量赋值语句:

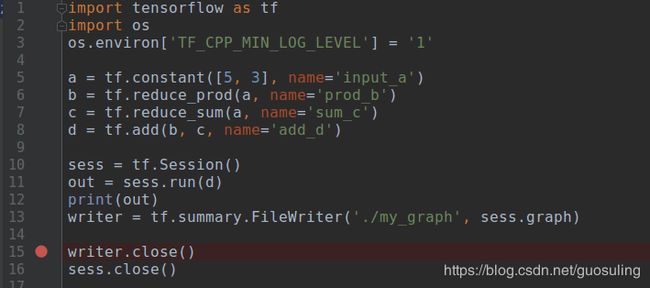
这里定义了“input”节点a和b。语句第一次引用了TensorFlowOperation:tf.constant()。在TensorFlow中,数据流图中的每个节点都被称为一个Operation(简记为Op,Operation:作业动作,constant:常量常项)。各Op可接收0个或多个Tensor对象作为输入,并输出0个或多个Tensor对象。要创建一个Op,可调用与其关联的Python构造方法,在本例中,tf.constant()创建了一个“常量”Op,它接收单个张量值,然后将同样的值输出给与其直接连接的节点。为方便起见,该函数自动将标量值5和3转换为Tensor对象。此外,我们还为这个构造方法传入了一个可选的字符串参数name,用于对所创建的节点进行标识。
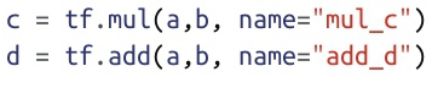
这两个语句定义了数据流图中的另外两个节点,而且它们都使用了之前定义的节点a和b。节点c使用了tf.mulOp,它接收两个输入,然后将它们的乘积输出。类似地,节点d使用了tf.add,该Op可将它的两个输入之和输出。对于这些Op,我们均传入了name参数(今后还将有大量此类用法)。请注意,无需专门对数据流图中的边进行定义,因为在Tensorflow中创建节点时已包含了相应的Op完成计算所需的全部输入,TensorFlow会自动绘制必要的连接

最后的这行代码定义了数据流图的终点e,它使用tf.add的方式与节点d是一致的。区别只在于它的输入来自节点c和节点d,这与数据流图中的描述完全一致
通过上述代码,便完成了第一个小规模数据流图的完整定义。如果在一个Python脚本或shell中执行上述代码,它虽然可以运行,但实际上却不会有任何实质性的结果输出。请注意,这只是整个流程的数据流图定义部分,要想体验一个数据流图的运行效果,还需在上述代码之后添加两行语句,以将数据流图终点的结果输出

如果在某个交互环境中运行这些代码,如Python shell或Jupyter/iPythonNotebook,则可看到正确的输出:

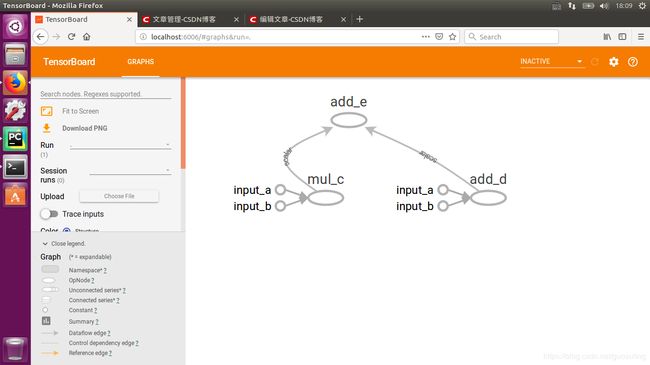
既然我们已经拥有了一个活动状态的Session对象,且数据流图已定义完毕,下面来对它进行可视化,以确认其结构与之前所绘制的数据流图完全一致。为此可使用TensorBoard,它是随TensorFlow一起安装的。为利用TensorBoard,需要在代码中添加下列语句
writer = tf.summary.FileWriter('./my_graph', sess.graph)
第一个参数是一个字符串输出目录,即数据流图的描述在磁盘中的存放路径。在本例中,所创建的文件将被存放在一个名为my_graph的文件夹中,而该文件夹位于运行Python代码的那个路径下。我们传递的第二个输入是Session对象的graph属性。作为在TensorFlow中定义的数据流图管理器,tf.Session对象拥有一个graph属性,该属性引用了它们所要追踪的数据流图。
回到终端,激活tensorflow环境后键入下列命令,确保当前工作路径与运行Python代码的路径一致(应该能看到列出的“my_graph”路径):
从控制台中,应该能够看到一些日志信息打印出来。。刚才所做的是启动一个使用来自“my_graph”目录下的数据的
TensorBoard服务器。默认情况下,TensorBoard服务器启动后会自动监听端口6006——要访问TensorBoard,可打开浏览器并在地址栏输入http://localhost:6006 ,然后将看到一个橙白主题的欢迎页面:[注意:上图中绿色圈圈表示,在浏览器中输入http://ling:6006也可以实现和http://localhost:6006相同的功能]
完成数据流图的构造之后,需要将Session对象和SummarWriter对象关闭,以释放资源并执行一些清理工作

从技术角度讲,当程序运行结束后(若使用的是交互式环境,当关闭或重启Python内核时),Session对象会自动关闭。尽管如此,笔者仍然建议显式关闭Session对象,以避免任何诡异的边界用例的出现。
2.2.2张量思维
在学习数据流图的基础知识时,使用简单的标量值是很好的选择。既然我们已经掌握了“数据流”,下面不妨熟悉一下张量的概念
如前所述,所谓张量,即n维矩阵的抽象。因此,1D张量等价于向量,2D张量等价于矩阵,对于更高维数的张量,可称“N维张量”或“N阶张量”。有了这一概念,便可对之前的示例数据流图进行修改,使其可使用张量,注意:prod是计算乘积
现在不再使用两个独立的输入节点,而是换成了一个可接收向量(或1阶张量)的节点。与之前的版本相比,这个新的流图有如下优点
1)客户只需将输入送给单个节点,简化了流图的使用。
2)那些直接依赖于输入的节点现在只需追踪一个依赖节点,而非两个
3)这个版本的流图可接收任意长度的向量,从而使其灵活性大大增强。我们还可对这个流图施加一条严格的约束,如要求输入的长度必须为2(或任何我们希望的长度)
按下列方式修改之前的代码,便可在TensorFlow中实现这种变动:
除了调整变量名称外,主要改动还有以下两处:
1)将原先分离的节点a和b替换为一个统一的输入节点(不止包含之前的节点a)。传入一组数值后,它们会由tf.constant函数转化为一个1阶张量。
2)之前只能接收标量值的乘法和加法Op,现在用tf.reduce_prod()和tf.reduce_sum()函数重新定义。当给定某个张量作为输入时,这些函数会接收其所有分量,然后分别将它们相乘或相加
在TensorFlow中,所有在节点之间传递的数据都为Tensor对象。我们已经看到,TensorFlowOp可接收标准Python数据类型,如整数或字符串,并将它们自动转化为张量。手工创建Tensor对象有多种方式(即无需从外部数据源读取),下面对其中一部分进行介绍。
1.Python原生类型
TensorFlow可接收Python数值、布尔值、字符串或由它们构成的列表。单个数值将被转化为0阶张量(或标量),数值列表将被转化为1阶张量(向量),由列表构成的列表将被转化为2阶张量(矩阵),以此类推。下面给出一些例子

TensorFlow数据类型
到目前为止,我们尚未见到布尔值或字符串,但可将张量视为一种以结构化格式保存任意数据的方式。显然,数学函数无法对字符串进行处理,而字符串解析函数也无法对数值型数据进行处理,但有必要了解TensorFlow所能处理的数据类型并不局限于数值型数据!下面给出TensorFlow中可用数据类型的完整清单

利用Python类型指定Tensor对象既容易又快捷,且对为一些想法提供原型非常有用。然而,很不幸,这种方式也会带来无法忽视的不利方面。TensorFlow有数量极为庞大的数据类型可供使用,但基本的Python类型缺乏对你希望使用的数据类型的种类进行明确声明的能力因此,TensorFlow不得不去推断你期望的是何种数据类型。
对于某些类型,如字符串,推断过程是非常简单的,但对于其他类型,则可能完全无法做出推断。例如,在Python中,所有整数都具有相同的类型,但TensorFlow却有8位、16位、32位和64位整数类型之分。当将数据传入TensorFlow时,虽有一些方法可将数据转化为恰当的类型,但某些数据类型仍然可能难以正确地声明,例如复数类型。因此,更常见的做法是借助NumPy数组手工定义Tensor对象。
2.NumPy数组
TensorFlow与专为操作N维数组而设计的科学计算软件包NumPy是紧密集成在一起的。如果之前没有使用过NumPy,笔者强烈推荐你从大量可用的入门材料和文档中选择一些进行学习,因为它已成为数据科学的通用语言。TensorFlow的数据类型是基于NumPy的数据类型的。实际上,语句np.int32==tf.int32的结果为True。任何NumPy数组都可传递给TensorFlowOp,而且其美妙之处在于可以用最小的代价轻易地指定所需的数据类型。
字符串数据类型
对于字符串数据类型,有一个“特别之处”需要注意。对于数值类型和布尔类型,TenosrFlow和NumPy dtype属性是完全一致的。然而,在NumPy中并无与tf.string精确对应的类型,这是由NumPy处理字符串的方式决定的。也就是说,TensorFlow可以从NumPy中完美地导入字符串数组,只是不要在NumPy中显式指定dtype属性
有一个好处是,在运行数据流图之前或之后,都可以利用NumPy库的功能,因为从Session.run方法所返回的张量均为NumPy数组。下面模仿之前的例子,给出一段用于演示创建NumPy数组的示例代码
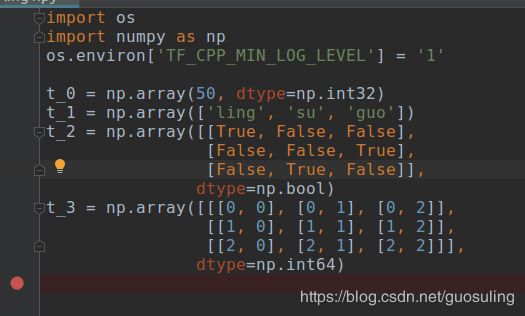
虽然TensorFlow是为理解NumPy原生数据类型而设计的,但反之不然。请不要尝试用tf.int32去初始化一个NumPy数组 [1]!
手工指定Tensor对象时,使用NumPy是推荐的方式
2.2.3 张量的形状
在整个TensorFlow库中,会经常看到一些引用了某个张量对象的“shape”属性的函数和Op。这里的“形状”是TensorFlow的专有术语,它同时刻画了张量的维(阶)数以及每一维的长度。张量的形状可以是包含有序整数集的列表(list)或元组(tuple):列表中元素的数量与维数一致,且每个元素描述了相应维度上的长度。例如,列表[2,3]描述了一个2阶张量的形状,其第1个维上的长度为2,第2个维上的长度为3。注意,无论元组(用一对小括号包裹),还是列表(用一对方括号包裹),都可用于定义张量的形状。
如果需要在数据流图的中间获取某个张量的形状,可以使用tf.shape Op。它的输入为希望获取其形状的Tensor对象,输出为一个int32类型的向量:

2.2.4 TensorFlow的Operation
上文曾经介绍过,TensorFlowOperation也称Op,是一些对(或利用)Tensor对象执行运算的节点,计算完毕后,它们会返回0个或多个张量,可在以后为数据流图中的其他Op所使用。为创建Op,需要在Python中调用其构造方法。调用时,需要传入计算所需的所有Tensor参数(称为输入)以及为正确创建Op的任何附加信息(称为属性)。Python构造方法将返回一个指向所创建Op的输出(0个或多个Tensor对象)的句柄。能够传递给其他Op或Session.run的输出如下


典例如下:

无输入、无输出的运算
是的,这意味着从技术角度讲,有些Op既无任何输入,也无任何输出。Op的功能并不只限于数据运算,它还可用于如状态初始化这样的任务。本章中,我们将回顾一些这样的非数学Op,但请记住,并非所有节点都需要与其他节点连接
除了输入和属性外,每个Op构造方法都可接收一个字符串参数——name,作为其输入。

在这个例子中,我们为加法Op赋予了名称“my_add_op”,这样便可在使用如Tensor-Board等工具时引用该Op
如果希望在一个数据流图中对不同Op复用相同的name参数,则无需为每个name参数手工添加前缀或后缀,只需利用name_scope以编程的方式将这些运算组织在一起便可。


2.2.5 TensorFlow的Graph对象
到目前为止,我们对数据流图的了解仅限于在TensorFlow中无处不在的某种抽象概念,而且对于开始编码时Op如何自动依附于某个数据流图并不清楚。既然已经接触了一些例子,下面来研究TensorFlow的Graph对象,学习如何创建更多的数据流图,以及如何让多个流图协同工作。
创建Graph对象的方法非常简单,它的构造方法不需要接收任何参数:


Graph对象初始化完成后,便可利用Graph.as_default()方法访问其上下文管理器,为其添加Op。结合with语句,可利用上下文管理器通知TensorFlow我们需要将一些Op添加到某个特定Graph对象中:

你可能会好奇,为什么在上面的例子中不需要指定我们希望将Op添加到哪个Graph对象?原因是这样的:为方便起见,当TensorFlow库被加载时,它会自动创 建一个Graph对象,并将其作为默认的数据流图。因此,在Graph.as_default()上下文管理器之外定义的任何Op、Tensor对象都会自动放置在默认的数据流图中:

在大多数TensorFlow程序中,只使用默认数据流图就足够了。然而,如果需要定义多个相互之间不存在依赖关系的模型,则创建多个Graph对象十分有用。当需要在单个文件中定义多个数据流图时,最佳实践是不使用默认数据流图,或为其立即分配句柄。这样可以保证各节点按照一致的方式添加到每个数据流图中。
1.正确的实践——创建新的数据流图,将默认数据流图忽略


此外,从其他TensorFlow脚本中加载之前定义的模型,并利用Graph.as_graph_def()和tf.import_graph_def()函数将其赋给Graph对象也是可行的。这样,用户便可在同一个Python文件中计算和使用若干独立的模型的输出
2.2.6 TensorFlow Session
之前的练习中,我们曾经介绍过,Session类负责数据流图的执行。构造方法tf.Session()接收3个可选参数
·target指定了所要使用的执行引擎。对于大多数应用,该参数取为默认的空字符串。在分布式设置中使用Session对象时,该参数用于连接不同的tf.train.Server实例
·graph参数指定了将要在Session对象中加载的Graph对象,其默认值为None,表示将使用当前默认数据流图。当使用多个数据流图时,最好的方式是显式传入你希望运行的Graph对象(而非在一个with语句块内创建Session对象)。
·config参数允许用户指定配置Session对象所需的选项,如限制CPU或GPU的使用数目,为数据流图设置优化参数及日志选项等
在典型的TensorFlow程序中,创建Session对象时无需改变任何默认构造参数

一旦创建完Session对象,便可利用其主要的方法run()来计算所期望的Tensor对象的输出
Session.run()方法接收一个参数fetches,以及其他三个可选参数:feed_dict、options和run_metadata。本书不打算对options和run_metadata进行介绍,因为它们尚处在实验阶段(因此以后很可能会有变动),且目前用途非常有限,但理解feed_dict非常重要,下文将对其进行讲解
1.fetches参数
fetches参数接收任意的数据流图元素(Op或Tensor对象),后者指定了用户希望执行的对象。如果请求对象为Tensor对象,则run()的输出将为一NumPy数组;如果请求对象为一个Op,则输出将为None
在上面的例子中,我们将fetches参数取为张量b(tf.mulOp的输出)。TensorFlow便会得到通知,Session对象应当找到为计算b的值所需的全部节点,顺序执行这些节点,然后将b的值输出。我们还可传入一个数据流图元素的列表:
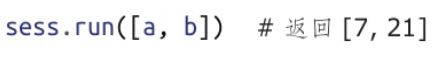
当fetches为一个列表时,run()的输出将为一个与所请求的元素对应的值的列表。在本例中,请求计算a和b的值,并保持这种次序。由于a和b均为张量,因此会接收到作为输出的它们的值
除了利用fetches获取Tensor对象输出外,还将看到这样的例子:有时也会赋予fetches一个指向某个Op的句柄,这是在运行中的一种有价值的用法。tf.initialize_all_variables()【在 2017年3月2号以后;用 tf.global_variables_initializer() 替代 tf.initialize_all_variables()】便是一个这样的例子,它会准备将要使用的所有TensorFlowVariable对象(本章稍后将介绍Variable对象)。我们仍然将该Op传给fetches参数,但Session.run()的结果将为None:

2.feed_dict参数
参数feed_dict用于覆盖数据流图中的Tensor对象值,它需要Python字典对象作为输入。字典中的“键”为指向应当被覆盖的Tensor对象的句柄,而字典的“值”可以是数字、字符串、列表或NumPy数组(之前介绍过)。这些“值”的类型必须与Tensor的“键”相同,或能够转换为相同的类型。下面通过一些代码来展示如何利用feed_dict重写之前的数据流图中a的值:

请注意,即便a的计算结果通常为7,我们传给feed_dict的字典也会将它替换为15。在相当多的场合中,feed_dict都极为有用。由于张量的值是预先提供的,数据流图不再需要对该张量的任何普通依赖节点进行计算。这意味着如果有一个规模较大的数据流图,并希望用一些虚构的值对某些部分进行测试,TensorFlow将不会在不必要的计算上浪费时间。对于指定输入值,feed_dict也十分有用,在稍后的占位符一节中我们将对此进行介绍。


也可利用Session类的as_default()方法将Session对象作为上下文管理器加以使用。类似于Graph对象被某些Op隐式使用的方式,可将一个Session对象设置为可被某些函数自动使用。这些函数中最常见的有Operation.run()和Tensor.eval(),调用这些函数相当于将它们直接传入Session.run()函数

关于InteractiveSession的进一步讨论
我们提到InteractiveSession是另外一种类型的TensorFlow会话,但我们不打算使用它。InteractiveSession对象所做的全部内容是在运行时将其作为默认会话,这在使用交互式Python shell的场合是非常方便的,因为可使用a.eval()或a.run(),而无须显式键入sess.run([a])。然而,如果需要同时使用多个会话,则事情会变得有些棘手。笔者发现,在运行数据流图时,如果能够保持一致的方式,将会使调试变得更容易,因此我们坚持使用常规的Session对象
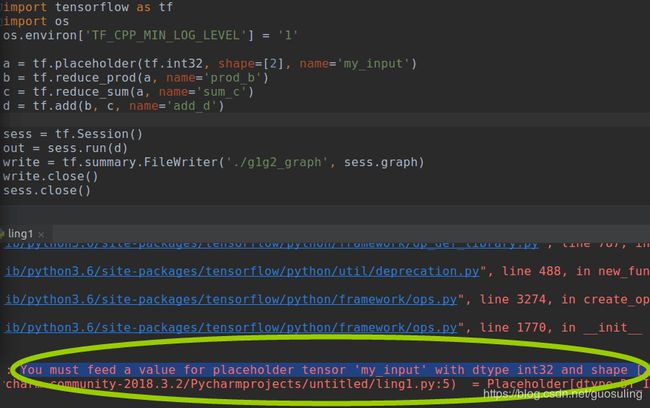
2.2.7 利用占位节点添加输入
之前定义的数据流图并未使用真正的“输入”,它总是使用相同的数值5和3。我们真正希望做的是从客户那里接收输入值,这样便可对数据流图中所描述的变换以各种不同类型的数值进行复用,借助“占位符”可达到这个目的。正如其名称所预示的那样,占位符的行为与Tensor对象一致,但在创建时无须为它们指定具体的数值。它们的作用是为运行时即将到来的某个Tensor对象预留位置,因此实际上变成了“输入”节点。利用tf.placeholder Op可创建占位符:

调用tf.placeholder()时,dtype参数是必须指定的,而shape参数可选:
·dtype指定了将传给该占位符的值的数据类型。该参数是必须指定的,因为需要确保不出现类型不匹配的错误。
· shape指定了所要传入的Tensor对象的形状。请参考前文中对Tensor形状的讨论。shape参数的默认值为None,表示可接收任意形状的Tensor对象。
与任何Op一样,也可在tf.placeholder中指定一个name标识符
为了给占位符传入一个实际的值,需要使用Session.run()中的feed_dict参数。我们将指向占位符输出的句柄作为字典(在上述代码中,对应变量a)的“键”,而将希望传入的Tensor对象作为字典的“值”。如果没有传入值就运行会报错如下【如果只是建模而不运行则没有问题】
为占位节点正确传入值的操作如下
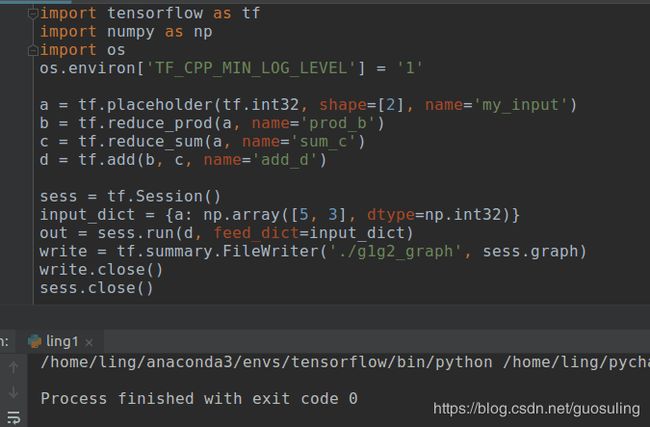
必须在feed_dict中为待计算的节点的每个依赖占位符包含一个键值对。在上面的代码中,需要计算d的输出,而它依赖于a的输出。如果还定义了一些d不依赖的其他占位符,则无需将它们包含在feed_dict中。
上述代码生成的流程图如下:

2.2.8 Variable对象
1.创建Variable对象
Tensor对象和Op对象都是不可变的(immutable),但机器学习任务的本质决定了需要一种机制保存随时间变化的值。借助TensorFlow中的Variable对象,便可达到这个目的。Variable对象包含了在对Session.run()多次调用中可持久化的可变张量值。Variable对象的创建可通过Variable类的构造方法tf.Variable()完成:

Variable对象可用于任何可能会使用Tensor对象的TensorFlow函数或Op中,其当前值将传给使用它的Op:

Variables对象的初值通常是全0、全1或用随机数填充的阶数较高的张量。为使创建具有这些常见类型初值的张量更加容易,TensorFlow提供了大量辅助Op,如tf.zeros()、tf.ones()、tf.random_normal()和tf.random_uniform(),每个Op都接收一个shape参数,以指定所创建的Tensor对象的形状:

除了tf.random_normal()外,经常还会看到人们使用tf.truncated_normal(),因为它不会创建任何偏离均值超过2倍标准差的值,从而可以防止有一个或两个元素与该张量中的其他元素显著不同的情况出现:

2.Variable对象的初始化
Variable对象与大多数其他TensorFlow对象在Graph中存在的方式都比较类似,但它们的状态实际上是由Session对象管理的。因此,为使用Variable对象,需要采取一些额外的步骤——必须在一个Session对象内对Variable对象进行初始化。这样会使Session对象开始追踪这个Variable对象的值的变化。Variable对象的初始化通常是通过将tf.initialize_all_variables()【在 2017年3月2号以后;用 tf.global_variables_initializer() 替代 tf.initialize_all_variables()】Op传给Session.run()完成的:

如果只需要对数据流图中定义的一个Variable对象子集初始化,可使用tf.initialize_variables()。该函数可接收一个要进行初始化的Variable对象列表:【注意:2017-3-2开始,`tf.variables_initializer` 替代了tf.initialize_variables()】

import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'
my_var1 = tf.Variable(tf.zeros([2, 2]), name='my_var1')
my_var2 = tf.Variable(tf.ones([6]), name='my_var2')
my_var3 = tf.Variable(tf.random_normal([3, 3, 3], mean=0.0, stddev=2.0), name='my_var3')
my_var4 = tf.Variable(tf.random_uniform([3, 3, 3], minval=0, maxval=10), name='my_var4')
my_var5 = tf.Variable(tf.truncated_normal([2, 2], mean=5.0, stddev=1.0), name='my_var5')
init = tf.global_variables_initializer()
3.Variable对象的修改
要修改Variable对象的值,可使用Variable.assign()方法。该方法的作用是为Variable对象赋予新值。请注意,Variable.assign()是一个Op,要使其生效必须在一个Session对象中运行。
对于Variable对象的简单自增和自减,TensorFlow提供了Variable.assign_add()方法和Variable.assign_sub()方法

由于不同Session对象会各自独立地维护Variable对象的值,因此每个Session对象都拥有自己的、在Graph对象中定义的Variable对象的当前值
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'
my_var = tf.Variable(0, name='my_var')
init = tf.global_variables_initializer()
sess1 = tf.Session()
sess2 = tf.Session()
sess1.run(init)
out1 = sess1.run(my_var.assign_add(5))
sess2.run(init)
out2 = sess2.run(my_var.assign_add(2))
执行结果如下:
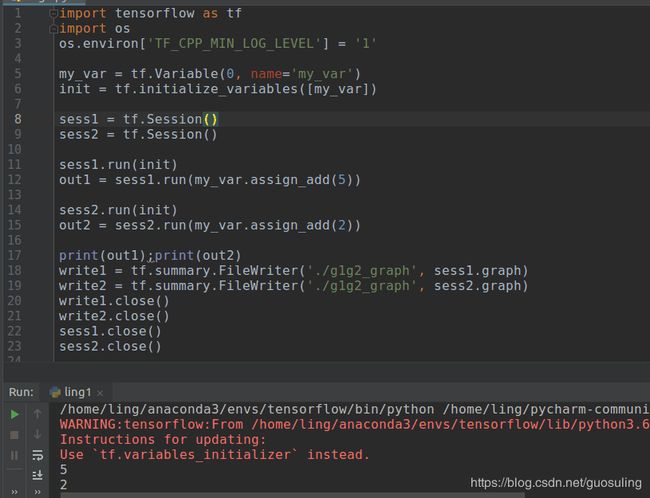
将上图中红色警告信息复制如下,可了解2017-3-2开始,`tf.variables_initializer` 替代了tf.initialize_variables()
WARNING:tensorflow:From /homeng/anaconda3/envs/tensorflowb/python3.6/site- packages/tensorflow/python/util/tf_should_use.py:189: initialize_variables (from tensorflow.python.ops.variables) is deprecated
and will be removed after 2017-03-02.
Instructions for updating:
Use `tf.variables_initializer` instead.
替换为正确函数后执行结果如下
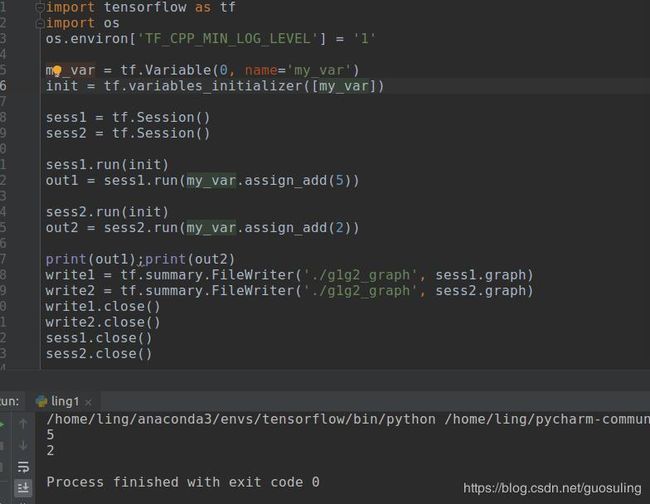
如果希望将所有Variable对象的值重置为初始值,则只需再次调用tf.initialize_all_variables()(如果只希望对部分Variable对象重新初始化,可调用tf.initialize_variables()):【2017-3-2开始,`tf.variables_initializer` 替代了tf.initialize_variables()】
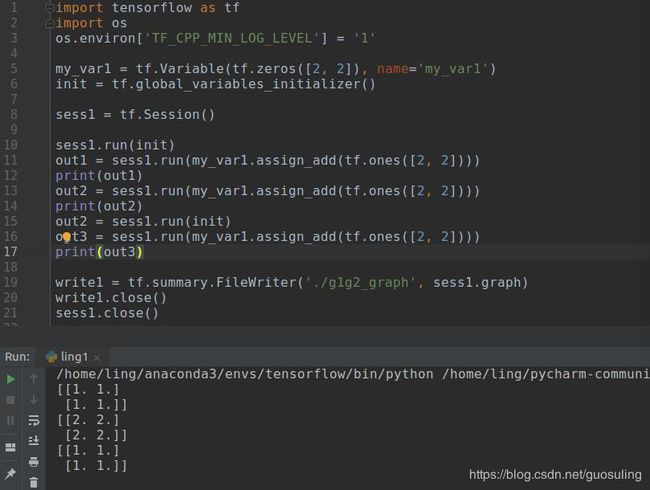
4.trainable参数
后面将介绍各种能够自动训练机器学习模型的Optimizer类,这意味着这些类将自动修改Variable对象的值,而无须显式做出请求。在大多数情况下,与我们的期望一致,但如果要求Graph对象中的一些Variable对象只可手工修改,而不允许使用Optimizer类时,可在创建这些Variable对象时将其trainable参数设为False:

对于迭代计数器或其他任何不涉及机器学习模型计算的Variable对象,通常都需要这样设置。
从技术角度讲,NumPy 也能够自动检测数据类型,但笔者强烈建议你养成显式声明Tensor 对象的数值属性的习惯, 因为当处理的流图规模较大时, 相信你一定不希望去逐一排查到底哪些对象导致了TypeMismatchError !当然,有一个例外,那就是当处理字符串时—创建字符串Tensor 对象时,请勿指定dtype 属性。
2.3 通过名称作用域组织数据流图
现在开始介绍构建任何TensorFlow数据流图所必需的核心构件。到目前为止,我们只接触了包含少量节点和阶数较小的张量的非常简单的数据流图,但现实世界中的模型往往会包含几十或上百个节点,以及数以百万计的参数。为使这种级别的复杂性可控,TensorFlow当前提供了一种帮助用户组织数据流图的机制——名称作用域(namescope)。
名称作用域非常易于使用,且在用TensorBoard对Graph对象可视化时极有价值。本质上,名称作用域允许将Op划分到一些较大的、有名称的语句块中。当以后用TensorBoard加载数据流图时,每个名称作用域都将对其自己的Op进行封装,从而获得更好的可视化效果。名称作用域的基本用法是将Op添加到withtf.name_scope(
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'
with tf.name_scope('scope_a'):
a = tf.add(1, 2, name='a_add')
b = tf.multiply(a, 3, name='b_mul')
with tf.name_scope('scope_b'):
c = tf.add(4, 5, name='c_add')
d = tf.multiply(c, 6, name='d_mul')
e = tf.add(b, d, name='output')
sess = tf.Session()
sess.run(e)
write = tf.summary.FileWriter('./g1g2_graph', sess.graph)
write.close()
sess.close()


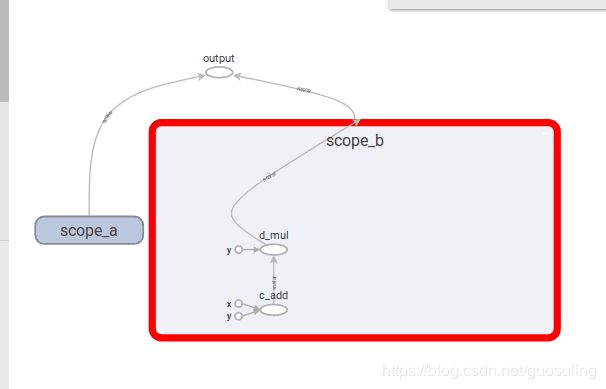
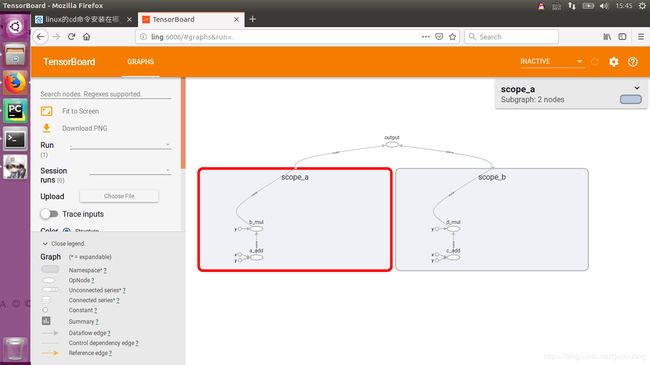
在每个作用域内,可看到已经添加到该数据流图中的各个Op,也可将名称作用域嵌入在其他名称作用域内:
典例1
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'
graph = tf.Graph()
with graph.as_default():
in1 = tf.placeholder(tf.float32, shape=[], name='input_a')
in2 = tf.placeholder(tf.float32, shape=[], name='inout_b')
const = tf.constant(3, dtype=tf.float32, name='static_value')
with tf.name_scope('all_scope'):
with tf.name_scope('a_scope'):
a_mul = tf.multiply(in1, const, name='a_mul')
a_out = tf.subtract(a_mul, in1, name='b_mul')
with tf.name_scope('b_scope'):
b_mul = tf.multiply(in2, const, name='b_mul')
b_out = tf.subtract(b_mul, in2, name='b_out')
with tf.name_scope('c_scope'):
c_div = tf.divide(a_out, b_out)
c_out = tf.add(c_div, const)
writer = tf.summary.FileWriter('./name_scope', graph=graph)
writer.close()
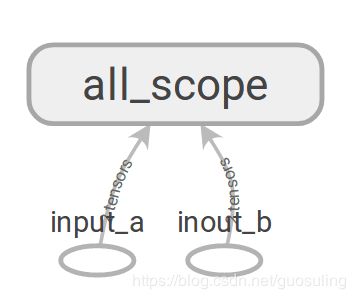
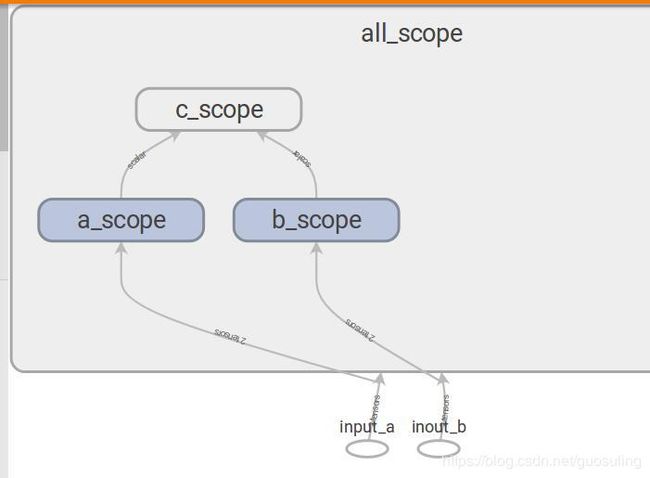



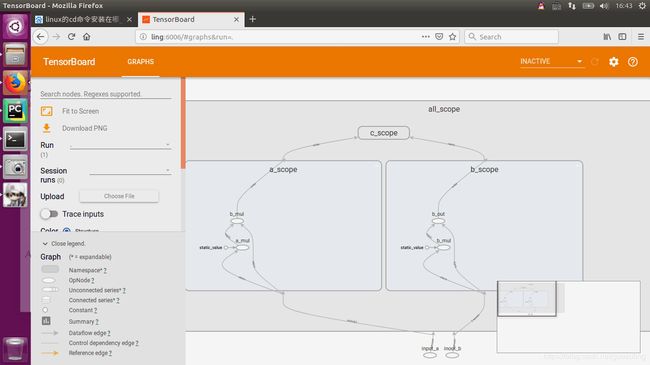
典例2
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'
graph = tf.Graph()
with graph.as_default():
in1 = tf.placeholder(tf.float32, shape=[], name='input_a')
in2 = tf.placeholder(tf.float32, shape=[], name='inout_b')
const = tf.constant(3, dtype=tf.float32, name='static_value')
with tf.name_scope('all_scope'):
with tf.name_scope('a_scope'):
a_mul = tf.multiply(in1, const, name='a_mul')
a_out = tf.subtract(a_mul, in1, name='b_mul')
with tf.name_scope('b_scope'):
b_mul = tf.multiply(in2, const, name='b_mul')
b_out = tf.subtract(b_mul, in2, name='b_out')
with tf.name_scope('c_scope'):
c_div = tf.divide(a_out, b_out)
c_out = tf.add(c_div, const)
writer = tf.summary.FileWriter('./name_scope', graph=graph)
writer.close()
这个模型拥有两个标量占位节点作为输入,一个TensorFlow常量,一个名为“Transformation”的中间块,以及一个使用tf.maximum()作为其Op的最终输出节点。可在TensorBoard内看到这种高层的表示:
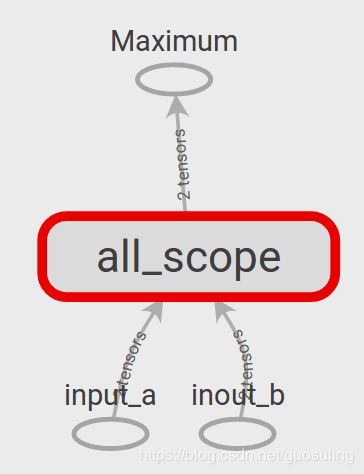
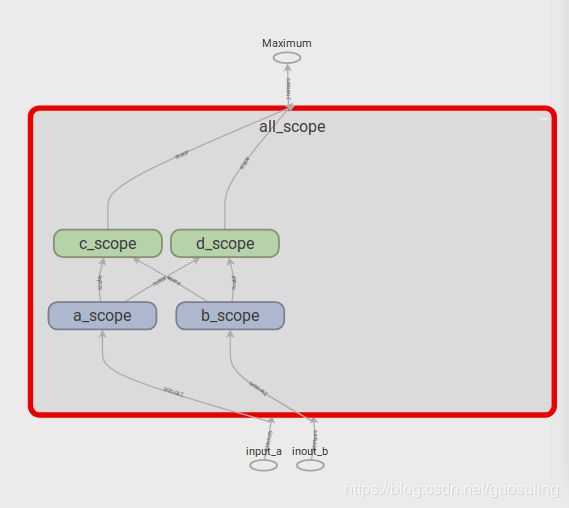



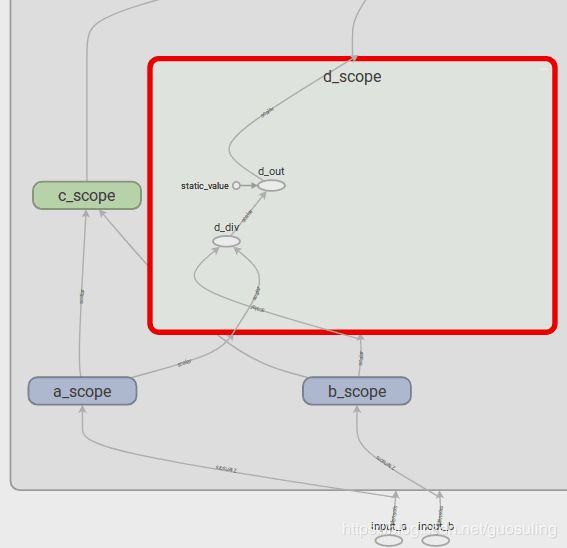
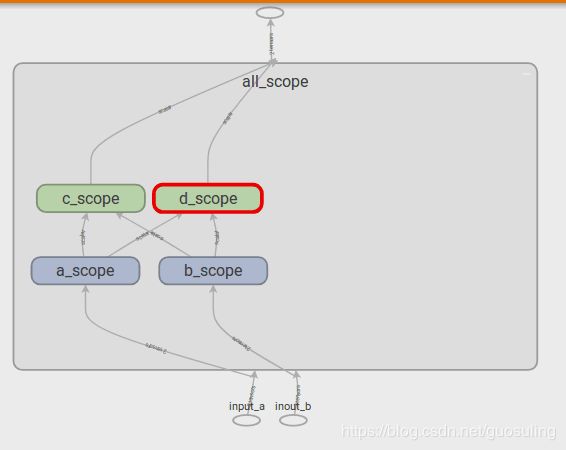
这同时还赋予了我们一个展示TensorBoard另外一个特性的机会。在上图中,可发现名称作用域“A”和“B”的颜色一致(蓝色),“C”和“D”的颜色也一致(绿色)。这是因为在相同的配置下,这些名称作用域拥有相同的Op设置,即“A”和“B”都有一个tf.mul()Op传给一个tf.sub()Op,而“C”和“D”都有一个tf.div()Op传给tf.add()Op。如果开始用一些函数创建重复的Op序列,将会非常方便
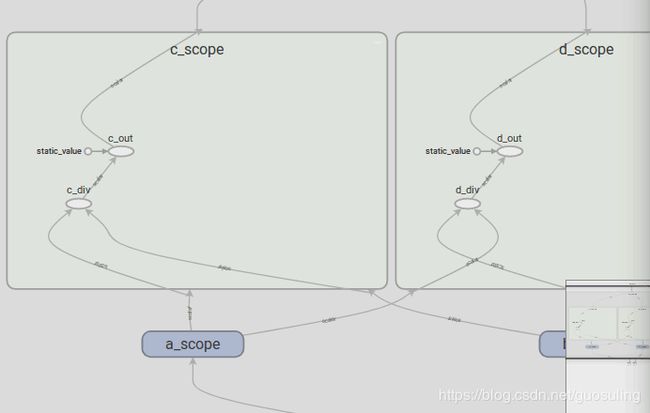
在下图中可以看到,当在TensorBoard中显示时,tf.constant对象的行为与其他Tensor对象或Op并不完全相同。即使我们没有在任何名称作用域内声明static_value,它仍然会被放置在这些名称作用域内,而且,static_value并非只出现一个图标,它会在被使用时创建一个小的视觉元素,其基本思想是常量可在任意时间使用,且在使用时无须遵循任何特定顺序。为防止在数据流图中出现从单点引出过多箭头的问题,只有当常量被使用时,它才会以一个很小的视觉元素的形式出现
2.4 练习:综合运用各种组件
下面通过一个综合运用了之前讨论过的所有组件——Tensor对象、Graph对象、Op、Variable对象、占位符、Session对象以及名称作用域的练习来结束本章。还会涉及一些TensorBoard汇总数据,以使数据流图在运行时能够跟踪其状态。练习结束后,读者将能够自如地搭建基本的TensorFlow数据流图并在TensorBoard中对其进行研究
本质上,本练习所要实现的数据流图与我们接触的第一个基本模型对应相同类型的变换。

但与之前的模型相比,本练习中的模型更加充分地利用了TensorFlow:
·输入将采用占位符,而非tf.constant节点。
·模型不再接收两个离散标量,而改为接收一个任意长度的向量。
·使用该数据流图时,将随时间计算所有输出的总和。
·将采用 名称作用域对数据流图进行合理划分。
·每次运行时,都将数据流图的输出、所有输出的累加以及所有输出的均值保存到磁盘,供TensorBoard使用。
现可直观感受一下本练习中的数据流图

在解读该模型时,有一些关键点需要注意:
·注意每条边的附近都标识了[None]或[]。它们代表了流经各条边的张量的形状,其中None代表张量为一个任意长度的向量,[]代表一个标量。
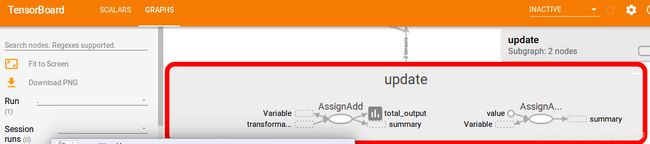
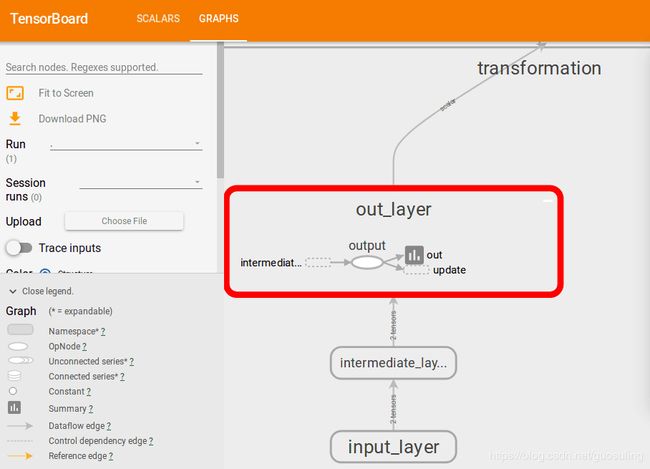
·节点d的输出流入“update”环节,后者包含了更新各Variable对象以及将数据传入TensorBoard汇总所需的Op。
· 用一个独立的名称作用域包含两个Variable对象。这两个Variable对象中一个用于存储输出的累加和,另一个用于记录数据流图的运行次数。由于这两个Variable对象是在主要的变换工作流之外发挥作用的,因此将其放在一个独立的空间中是完全合理的。
·TensorBoard汇总数据有一个专属的名称作用域,用于容纳tf.scalar_summaryOp。我们将它们放在“update”环节之后,以确保汇总数据在Variable对象更新完成后才被添加,否则运算将会失控
拓展知识点1
TensorFlow提供了可视化操作工具TensorBoard。他可以将训练过程中的各种数据展示出来,包括标量,图片,音频,计算图,数据分布,直方图和嵌入式向量。可以通过网页来观察模型的结构和训练过程中各个参数的变化。TensorBoard不会自动把代码代码出来,其实它是一个日志展示系统,需要在session中运算图时,将各种类型的数据汇总并输出到日志日志文件中。然后启动TensorBoard服务,读取这些日志文件,启动6006端口提供web服务,让用户可以在浏览器查看数据。
【https://blog.csdn.net/sinat_33761963/article/details/62433234 】 当使用Tensorflow训练大量深层的神经网络时,我们希望去跟踪神经网络的整个训练过程中的信息,比如迭代的过程中每一层参数是如何变化与分布的,比如每次循环参数更新后模型在测试集与训练集上的准确率是如何的,比如损失值的变化情况,等等。如果能在训练的过程中将一些信息加以记录并可视化得表现出来,是不是对我们探索模型有更深的帮助与理解呢?
Tensorflow官方推出了可视化工具Tensorboard,可以帮助我们实现以上功能,它可以将模型训练过程中的各种数据汇总起来存在自定义的路径与日志文件中,然后在指定的web端可视化地展现这些信息。
1、Tensorboard的数据形式: Tensorboard可以记录与展示以下数据形式:
(1)标量Scalars
(2)图片Images
(3)音频Audio
(4)计算图Graph
(5)数据分布Distribution
(6)直方图Histograms
(7)嵌入向量Embeddings
2 Tensorboard的可视化过程
(1)首先肯定是先建立一个graph,你想从这个graph中获取某些数据的信息
(2)确定要在graph中的哪些节点放置summary operations以记录信息
使用tf.summary.scalar记录标量
使用tf.summary.histogram记录数据的直方图
使用tf.summary.distribution记录数据的分布图
使用tf.summary.image记录图像数据
(3)operations并不会去真的执行计算,除非你告诉他们需要去run,或者它被其他的需要run的operation所依赖。而我们上一步创建的这些summary operations其实并不被其他节点依赖,因此,我们需要特地去运行所有的summary节点。但是呢,一份程序下来可能有超多这样的summary 节点,要手动一个一个去启动自然是及其繁琐的,因此我们可以使用tf.summary.merge_all去将所有summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之前设置的summary data。
(4)使用tf.summary.FileWriter将运行后输出的数据都保存到本地磁盘中
(5)运行整个程序,并在命令行输入运行tensorboard的指令,之后打开web端可查看可视化的结果
2.4.1 构建数据流图
我们要做的第一件事永远是导入TensorFlow库

下面显式创建一个Graph对象加以使用,而非使用默认的Graph对象,因此需要用Graph类的构造方法tf.Graph():
![]()
接着在构造模型时,将上述新Graph对象设为默认Graph对象
![]()
在我们的模型中有两个“全局”风格的Variable对象。第一个是“global_step”,用于追踪模型的运行次数。在TensorFlow中,这是一种常见的范式,在整个API中,这种范式会频繁出现。第二个Variable对象是“total_ouput”,其作用是追踪该模型的所有输出随时间的累加和。由于这些Variable对象本质上是全局的,因此在声明它们时需要与数据流图中的其他节点区分开来,并将它们放入自己的名称作用域

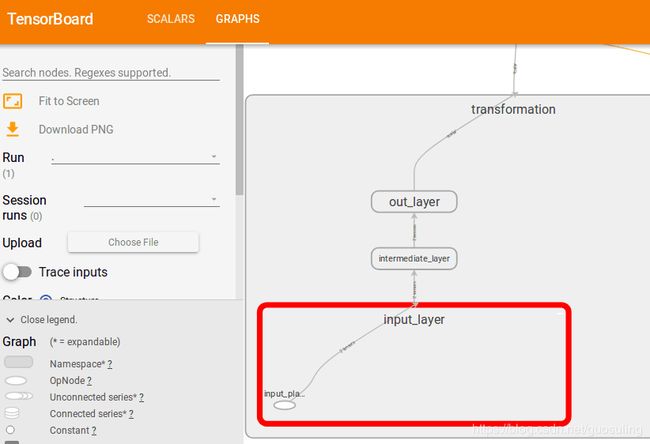
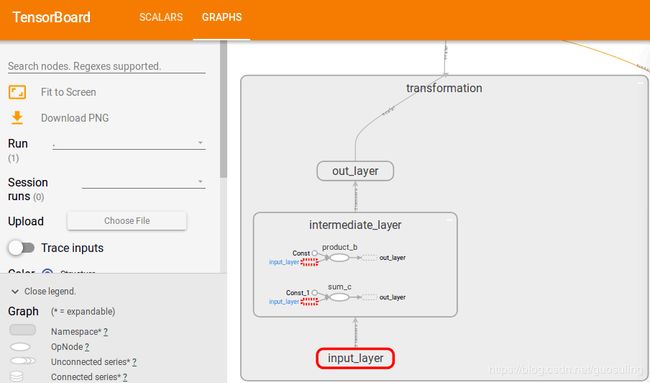
请注意,这里使用了trainable=False设置,这并不会对模型造成影响(因为并没有任何训练的步骤),但该设置明确指定了这些Variable对象只能通过手工设置。接下来,将创建模型的核心变换部分。我们会将整个变换封装到一个名称作用域“transformation”中,并进一步将它们划分为三个子名称作用域——“input”、“intermediate_layer”和“output

除少量关键之处不同外,上述代码与为之前的模型所编写的代码高度相似:
·输入节点为tf.placeholder Op,它可接收一个任意长度(因为shape=[None])的向量。
·对于乘法和加法运算,这里并未使用tf.mul()和tf.add(),而是分别使用了tf.reduce_prod()和tf.reduce_sum(),这样便可以对整个输入向量实施乘法和加法运算,而之前的Op只能接收两个标量作为输入。
经过上述变换计算,需要对前面定义的两个Variable对象进行更新。下面通过创建一个“update”名称作用域来容纳这些变化:

total_output和global_step的递增均通过Variable.assign_add()Op实现。output的值被累加到total_output中,因为希望随时间将所有的输出进行累加。对于global_step,只是将其简单地增1。这两个Variable对象更新完毕后,便可创建我们感兴趣的TensorBoard汇总数据,可将它们放入名为“summaries”的名称作用域中:

在该环节中,所做的第一件事是随时间计算输出的均值。幸运的是,可以获取当前全部输出的总和total_output(使用来自update_total的输出,以确保在计算avg之前更新便已完成)以及数据流图的总运行次数global_step(使用increment_step的输出,以确保数据流图有序运行)。一旦获得输出的均值,便可利用各个tf.scalar_summary对象将ouput、update_total和avg保存下来
为完成数据流图的构建,还需要创建Variable对象初始化Op和用于将所有汇总数据组织到一个Op的辅助节点。下面将它们放入名为“global_ops”的名称作用域:

读者可能会有一些疑惑,为什么将tf.merge_all_summaries()【此函数已经更名为:tf.summary.merge_all】Op放在这里,而非“summaries”名称作用域?虽然两者并无明显差异,但一般而言,将merge_all_summaries()与其他全局Op放在一起是最佳做法。我们的数据流图只为汇总数据设置了一个环节,但这并不妨碍去想象一个拥有Variable对象、Op和名称作用域等的不同汇总数据的数据流图。通过保持merge_all_summaries()的分离,可确保用户无需记忆放置它的特定“summary”代码块,从而比较容易找到该Op。
以上便是构建数据流图的全部内容,但要使这个数据流图能够运行,还需要完成一些设置
构建数据流图的完整代码段如下
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
graph = tf.Graph() # 显式创建图对象
# 主要节点
with graph.as_default(): # 为创建的图对象添加一系列节点
with tf.name_scope('Variable'): # 变量的名称作用区
globals_step = tf.Variable(0, dtype=tf.int32, trainable=False, name='global_step')
total_output = tf.Variable(0, dtype=tf.float32,trainable=False, name='total_output')
with tf.name_scope('global_ops'): # 全局节点的辅助节点
tf.global_variables_initializer()
tf.summary.merge_all()
with tf.name_scope('transformation'): # 整个转换部分的名称作用区
with tf.name_scope('input_layer'): # 输入层的名称作用区
a = tf.placeholder(tf.float32, shape=[None], name='input_placeholder_a')
with tf.name_scope('intermediate_layer'): # 中间层的名称作用区
b = tf.reduce_prod(a, name='product_b')
c = tf.reduce_sum(a, name='sum_c')
with tf.name_scope('out_layer'): # 输出层的名称作用区
out = tf.add(b, c, name='output')
with tf.name_scope('update'): # 更新节点的名称作用区
update_total = total_output.assign_add(out)
increment_step = globals_step.assign_add(1)
with tf.name_scope('summary'): # 感兴趣的tensorboard汇总数据的名称作用区
avg = tf.div(update_total, tf.cast(increment_step, tf.float32), name='average')
tf.summary.scalar('out', out)
tf.summary.scalar('total_output', update_total)
tf.summary.scalar('avg', avg)
拓展知识1:API--tf.summary.scalar
scalar(name,tensor,collections=None,family=None)
函数参数
name:生成节点的名字,也会作为TensorBoard中的系列的名字。
tensor:包含一个值的实数Tensor。
collection:图的集合键值的可选列表。新的求和op被添加到这个集合中。缺省为[GraphKeys.SUMMARIES]
family:可选项;设置时用作求和标签名称的前缀,这影响着TensorBoard所显示的标签名。
函数简介
返回值:一个字符串类型的标量张量,包含一个Summaryprotobuf
返回错误:ValueErrortensor有错误的类型或shape。
函数求出的Summary中有一个包含输入tensor的Tensor.proto
拓展知识2 :函数tf.cast 类型转换 函数
tf.cast(x, dtype, name=None)
参数 x:输入 dtype:转换目标类型 name:名称
返回: Tensor
拓展知识3 :TensorFlow中的数据
TensorFlow中,数据被封装在一个叫tensor的对象中,tf.constant()用来表示常量;tf.placeholder()用来向TensorFlow传递数据,例如神经网络中的features和labels,可以理解为一个可以用来操作却不能改变其值的变量;tf.Variable()用来表示可以用来改变其中存储数据值的变量,例如神经网络中的权重和偏置,可以使用tf.Variable()进行更新
拓展知识4 tensorflow 1.0 的些许修改
tf.mul、tf.sub 和 tf.neg 被弃用,现在使用的是 tf.multiply、tf.subtract 和 tf.negative.
移除了原来的 tf summary 运算符,比如 tf.scalar_summary 和 tf.histogram_summary. 取而代之的是 tf.summary.scalar 和 tf.summary.histogram .
tf.divide 现在是推荐的除法函数。tf.div 还将保留,但其语义将不会响应 Python 3 或 from future 机制. 【注意:divide(x,y)中只要有一个是float,其结果就是float,而div(x,y)中有一个是float,一个是int,结果为int】
拓展知识5 python函数中的位置参数、默认参数、关键字参数、可变参数区别
https://www.cnblogs.com/VseYoung/p/python_def.html
位置参数:调用函数时根据函数定义的参数位置来传递参数。
关键字参数:用于函数调用,通过“键-值”形式加以指定。可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求
有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序的
拓展知识6 Python PEP8 编码规范中文版
https://blog.csdn.net/ratsniper/article/details/78954852
行内注释是与代码语句同行的注释。行内注释和代码至少要有两个空格分隔。注释由#和一个空格开始。
块注释通常适用于跟随它们的某些(或全部)代码,并缩进到与代码相同的级别。块注释的每一行开头使用一个#和一个空格(除非块注释内部缩进文本)。 块注释内部的段落通过只有一个#的空行分隔
2.4.2 运行数据流图
打开一个Session对象,并加载已经创建好的Graph对象,也可打开一个tf.trian.SummaryWriter对象【此函数已经改为tf.summary.FileWriter】,便于以后利用它保存汇总数据。下面将./improved_graph作为保存汇总数据的目标文件夹
# 创建filewriter对象,用于保存模型和汇总数据
writer = tf.summary.FileWriter('./improved', graph)
# 创建session对象,并与已经创建的graph对象关联
sess = tf.Session(graph=graph) Session对象启动后,在做其他事之前,先对各Variable对象进行初始化:
# 初始化所有的variable对象
sess.run(init)
为运行该数据流图,需要创建一个辅助函数run_graph(),这样以后便无需反复输入相同的代码。我们希望将输入向量传给该函数,而后者将运行数据流图,并将汇总数据保存下来:
def run_graph(input_tensor):
feed_dict = {a: input_tensor}
_, step, summary = sess.run([out, increment_step, summary_merge], feed_dict=feed_dict)
writer.add_summary(summary, step) 下面对run_graph()函数逐行进行解析:
1)首先创建一个赋给Session.run()中feed_dict参数的字典,这对应于tf.placeholder节点,并用到了其句柄a。
2)然后,通知Session对象使用feed_dict运行数据流图,我们希望确保output、increment_step以及merged_summaries Op能够得到执行。为写入汇总数据,需要保存global_step和merged_summaries的值,因此将它们保存到Python变量step和summary中。这里用下划线“_”表示我们并不关心output值的存储。
3)最后,将汇总数据添加到SummaryWriter对象中。step参数非常重要,因为它使TensorBoard可随时间对数据进行图示(稍后将看到,它本质上创建了一个折线图的横轴)
注意:上述代码块和下述代码块作用相同,原因是summary_merge节点已经和out节点相关联,故若无需知道out输出值则可不写
def run_graph(input_tensor):
feed_dict = {a: input_tensor}
step, summary = sess.run([increment_step, summary_merge], feed_dict=feed_dict)
writer.add_summary(summary, step)
下面来实际使用这个函数,可变换向量的长度来多次调用run_graph()函数:
run_graph([2, 8])
run_graph([3, 1, 3, 3])
run_graph([8])
run_graph([1, 2, 3])
run_graph([11, 4])
run_graph([4, 1])
run_graph([7, 3, 1])
run_graph([6, 3])
run_graph([0, 2])
run_graph([4, 5, 6])上述调用可反复进行。数据填充完毕后,可用SummaryWriter.flush()函数将汇总数据写入磁盘
![]()
最后,既然SummaryWriter对象和Session对象已经使用完毕,我们将其关闭,以完成一些清理工作
整个流程图构建和运行代码如下
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
graph = tf.Graph() # 显式创建图对象
# 主要节点
with graph.as_default(): # 为创建的图对象添加一系列节点
with tf.name_scope('Variable'): # 变量的名称作用区
globals_step = tf.Variable(0, dtype=tf.int32, trainable=False, name='global_step')
total_output = tf.Variable(0.0, dtype=tf.float32, trainable=False, name='total_output')
with tf.name_scope('transformation'): # 整个转换部分的名称作用区
with tf.name_scope('input_layer'): # 输入层的名称作用区
a = tf.placeholder(tf.float32, shape=[None], name='input_placeholder_a')
with tf.name_scope('intermediate_layer'): # 中间层的名称作用区
b = tf.reduce_prod(a, name='product_b')
c = tf.reduce_sum(a, name='sum_c')
with tf.name_scope('out_layer'): # 输出层的名称作用区
out = tf.add(b, c, name='output')
with tf.name_scope('update'): # 更新节点的名称作用区
update_total = total_output.assign_add(out)
increment_step = globals_step.assign_add(1)
with tf.name_scope('summary'): # 感兴趣的tensorboard汇总数据的名称作用区
avg = tf.divide(update_total, tf.cast(increment_step, tf.float32), name='average')
tf.summary.scalar('out', out)
tf.summary.scalar('total_output', update_total)
tf.summary.scalar('avg', avg)
with tf.name_scope('global_ops'): # 全局节点的辅助节点
init = tf.global_variables_initializer()
summary_merge = tf.summary.merge_all()
sess = tf.Session(graph=graph) # 创建session对象,并与已经创建的graph对象关联
writer = tf.summary.FileWriter('./ling3', graph) # 创建filewriter对象,用于保存模型和汇总数据
sess.run(init) # 初始化所有的variable对象
def run_graph(input_tensor):
feed_dict = {a: input_tensor}
step, summary = sess.run([increment_step, summary_merge], feed_dict=feed_dict)
writer.add_summary(summary, step)//此函数是将数据保存在指定文件中
run_graph([2, 8])
run_graph([3, 1, 3, 3])
run_graph([8])
run_graph([1, 2, 3])
run_graph([11, 4])
run_graph([4, 1])
run_graph([7, 3, 1])
run_graph([6, 3])
run_graph([0, 2])
run_graph([4, 5, 6])
writer.flush()
writer.close()
sess.close()
与之前一样,该命令将在6006端口启动一个TensorBoard服务器,并托管存储在“ling3”中的数据。在浏览器中键入“localhost:6006”,观察所得到的结果。首先检查“Graph”标签页
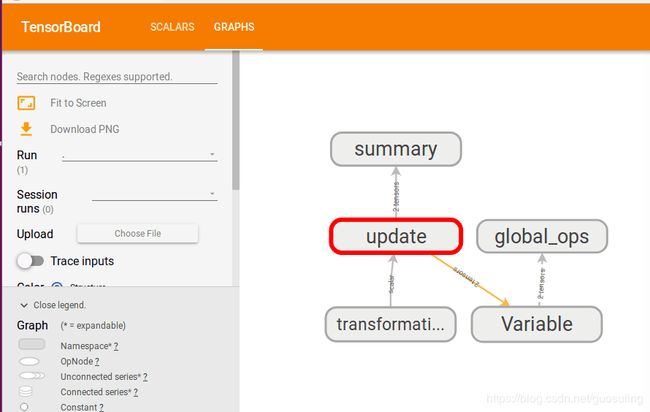



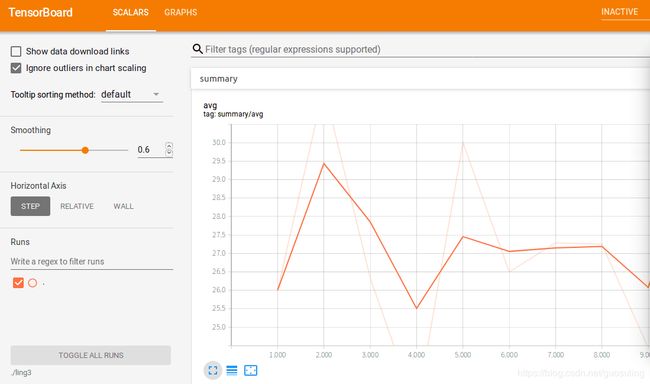
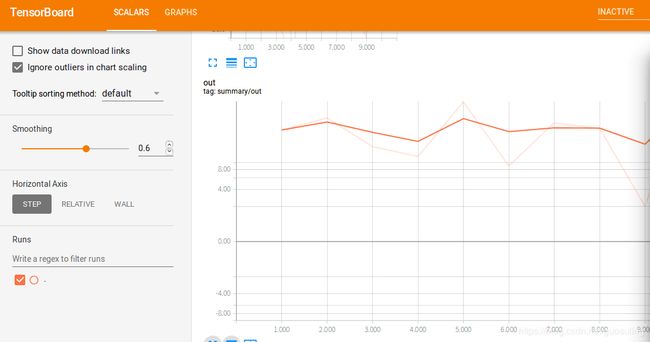
当打开“Events”页面后,可以看到3个依据我们赋予各scalar_summary对象的标签而命名的折叠的标签页。单击任意一个标签页,便可看到一个精美的折线图,展示了不同时间点上值的变化。单击该图表左下方的蓝色矩形,它们会像下图一样展开。

拓展知识1: 用pycharm写python的时候,总会在def function()的那行出现如下错误
PEP:8 expected 2 blank lines ,found 1
具体原因就是呢,pep8编程风格在声明函数的那一行的上方必须有两行的空行,否则便出现这个情况。
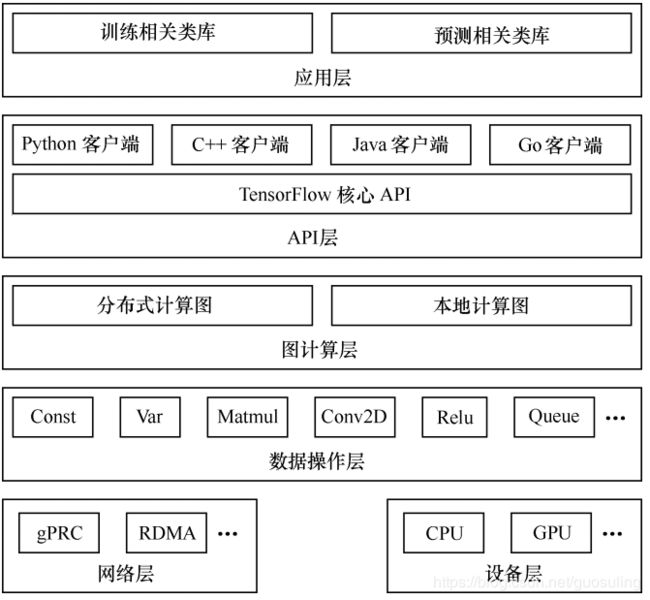
2.5 系统架构
自底向上分为设备层和网络层、数据操作层、图计算层、API 层、应用层,其中设备层和网络层、数据操作层、图计算层是 TensorFlow 的核心层。
最下层是网络通信层和设备管理层。网络通信层包括 gRPC(google Remote Procedure Call Protocol谷歌远程过程调用协议)和远程直接数据存取(Remote Direct Memory Access,RDMA),这都是在分布式计算时需要用到的。设备管理层包括 TensorFlow 分别在 CPU、GPU、FPGA 等设备上的实现,也就是对上层提供了一个统一的接口,使上层只需要处理卷积等逻辑,而不需要关心在硬件上的卷积的实现过程
其上是数据操作层,主要包括卷积函数、激活函数等操作,再往上是图计算层,也是我们要了解的核心,包含本地计算图和分布式计算图的实现,再往上是 API 层和应用层
2.6 设计理念
TensorFlow 的设计理念主要体现在以下两个方面
(1)将图的定义和图的运行完全分开。因此,TensorFlow 被认为是一个“符号主义”的库。
我们知道,编程模式通常分为命令式编程(imperative style programming)和符号式编程(symbolic style programming)。命令式编程就是编写我们理解的通常意义上的程序,很容易理解和调试,按照原有逻辑执行。符号式编程涉及很多的嵌入和优化,不容易理解和调试,但运行速度相对有所提升。现有的深度学习框架中,Torch 是典型的命令式的,Caffe、MXNet 采用了两种编程模式混合的方法,而 TensorFlow 完全采用符号式编程。
符号式计算一般是先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量之间的计算关系,最后需要对数据流图进行编译,但此时的数据流图还是一个空壳儿,里面没有任何实际数据,只有把需要运算的输入放进去后,才能在整个模型中形成数据流,从而形成输出值
例如: t = 8 + 9 print(t)
在传统的程序操作中,定义了 t 的运算,在运行时就执行了,并输出 17。而在 TensorFlow中,数据流图中的节点,实际上对应的是 TensorFlow API 中的一个操作,并没有真正去运行:定义了一个操作,但实际上并没有运行。
import tensorflow as tf
t = tf.add(8, 9)
print(t) # 输出 Tensor("Add_1:0", shape=(), dtype=int32)
(2)TensorFlow 中涉及的运算都要放在图中,而图的运行只发生在会话(session)中。
开启会话后,就可以用数据去填充节点,进行运算;关闭会话后,就不能进行计算了。因此,会话提供了操作运行和 Tensor 求值的环境。
2.7、编程模型
TensorFlow 是用数据流图做计算的,因此我们先创建一个数据流图(也称为网络结构图),如图 所示,看一下数据流图中的各个要素
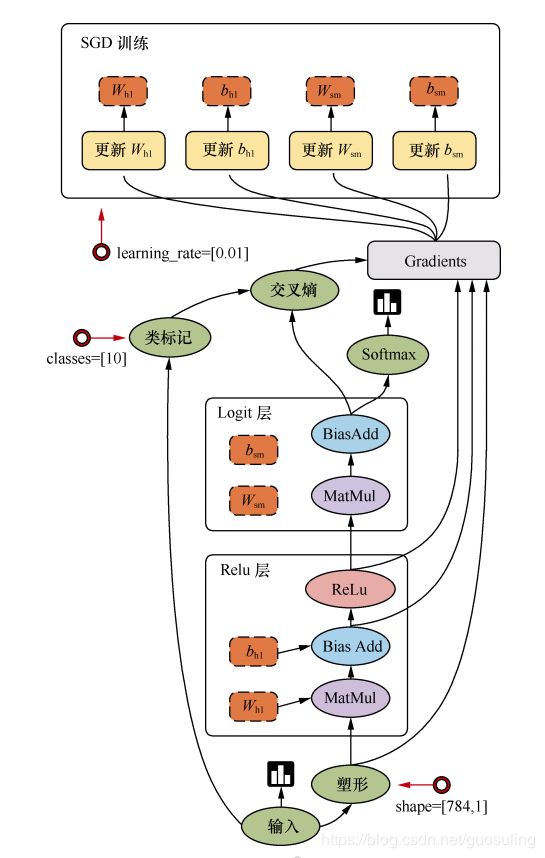
上图讲述了 TensorFlow 的运行原理。图中包含输入(input)、塑形(reshape)、Relu 层(Relu layer)、Logit 层(Logit layer)、Softmax、交叉熵(cross entropy)、梯度(gradient)、SGD 训练(SGD Trainer)等部分,是一个简单的回归模型。
它的计算过程是,首先从输入开始,经过塑形后,一层一层进行前向传播运算。Relu 层(隐藏层)里会有两个参数,即 Wh1和 bh1,在输出前使用 ReLu(Rectified Linear Units)激活函数做非线性处理。然后进入 Logit 层(输出层),学习两个参数 Wsm和 bsm。用 Softmax 来计算输出结果中各个类别的概率分布。用交叉熵来度量两个概率分布(源样本的概率分布和输出结果的概率分布)之间的相似性。然后开始计算梯度,这里是需要参数 Wh1、bh1、Wsm和 bsm,以及交叉熵后的结果。随后进入 SGD 训练,也就是反向传播的过程,从上往下计算每一层的参数,依次进行更新。也就是说,计算和更新的顺序为 bsm、Wsm、bh1和 Wh1
顾名思义,TensorFlow 是指“张量的流动”。TensorFlow 的数据流图是由节点(node)和边(edge)组成的有向无环图(directed acycline graph,DAG)。TensorFlow 由 Tensor 和 Flow 两部分组成,Tensor(张量)代表了数据流图中的边,而 Flow(流动)这个动作就代表了数据流图中节点所做的操作
使用 TensorFlow, 你必须明白 TensorFlow:
• 使用图 (graph) 来表示计算任务.
• 在被称之为 会话 (Session) 的上下文 (context) 中执行图.
• 使用 tensor 表示数据.
• 通过 变量 (Variable) 维护状态.
• 使用 feed 和 fetch 为任意操作输入和输出数据.
TensorFlow 是一个编程系统, 使用图来表示计算任务. 图中的节点被称之为 op (operation 的缩写). 一个 op获得 0 个或多个 Tensor , 执行计算, 产生 0 个或多个 Tensor . 每个 Tensor 是一个类型化的多维数组. 例如, 你可以将一小组图像集表示为一个四维浮点数数组, 这四个维度分别是 [batch, height, width, channels] .
一个 TensorFlow 图描述了计算的过程. 为了进行计算, 图必须在 会话 里被启动. 会话 将图的 op 分发到诸如 CPU 或 GPU 之类的 设备 上, 同时提供执行 op 的方法. 这些方法执行后, 将产生的 tensor 返回. 在 Python 语言中, 返回的 tensor 是 numpy ndarray 对象; 在 C 和 C++ 语言中, 返回的 tensor 是 tensorflow::Tensor 实例.
2.7.1 边
TensorFlow 的边有两种连接关系:数据依赖和控制依赖。其中,实线边表示数据依赖,代表数据,即张量。任意维度的数据统称为张量。在机器学习算法中,张量在数据流图中从前往后流动一遍就完成了一次前向传播(forword propagation),而残差【在数理统计中,残差是指实际观残值与训练的估计值之间的差】从后向前流动一遍就完成了一次反向传播(backword propagation)
还有一种特殊边,一般画为虚线边,称为控制依赖(control dependency),可以用于控制操作的运行,这被用来确保 happens-before 关系,这类边上没有数据流过,但源节点必须在目的节点开始执行前完成执行。例如之前的流程图中就有控制依赖,如下图所示

TensorFlow 支持的张量具有下表所示的数据属性
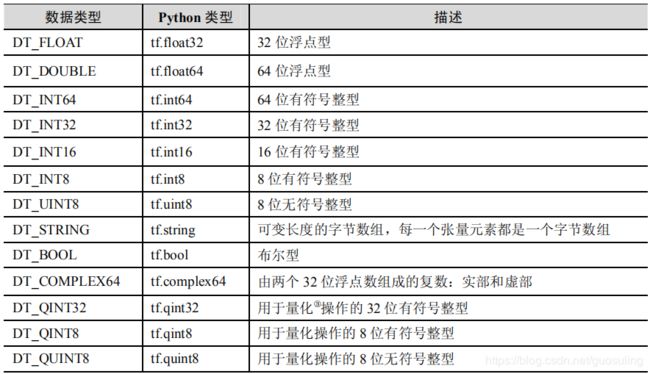
TensorFlow用张量这种数据结构来表示所有的数据.你可以把一个张量想象成一个n维的数组或列表.一个张量有一个静态类型和动态类型的维数.张量可以在图中的节点之间流通.
在TensorFlow系统中,张量的维数来被描述为阶.但是张量的阶和矩阵的阶并不是同一个概念.张量的阶(有时是关于如顺序或度数或者是n维)是张量维数的一个数量描述.比如,下面的张量(使用Python中list定义的)就是2阶. t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]你可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量.对于一个二阶张量你可以用语句 t[i, j] 来访问其中的任何元素.而对于三阶张量你可以用't[i, j, k]'来访问其中的任何元素.

TensorFlow文档中使用了三种记号来方便地描述张量的维度:阶,形状以及维数.下表展示了他们之间的关系:

拓展知识:详解Tensor与Flow
https://blog.csdn.net/roseki/article/details/70115369
2.7.2 节点
图中的节点又称为算子,它代表一个操作(operation,OP),一般用来表示施加的数学运算,也可以表示数据输入(feed in)的起点以及输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点
下表列举了一些 TensorFlow 实现的算子,算子支持上表中所示的张量的各种数据属性,并且需要在建立图的时候确定下来

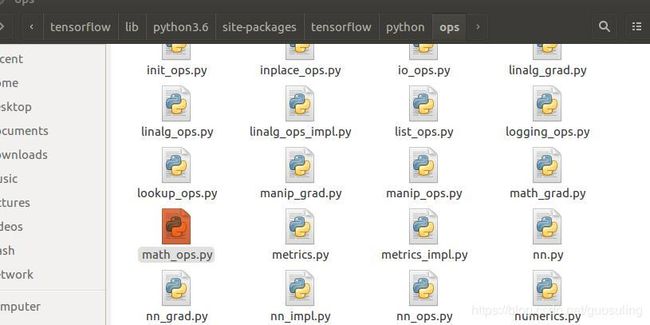
以数学运算为例,代码为上述目录下的 math_ops.py,里面定义了 add、subtract、multiply、scalar_mul、div、divide数学运算,每个函数里面调用了 gen_math_ops.py 中的方法,这个文件是在编译(安装时)TensorFlow 时生成的,位于 Python 库 site-packages/tensorflow/python/ops/gen_math_ops.py 中,随后又调用了 site-packages/tensorflow/core/kernels/下面的核函数实现。再例如,数据运算的代码位于 sitepackages/tensorflow/python/ops/array_ops.py 中,里面定义了concat、split、slice、size、rank 等运算,每个函数都调用了 gen_array_ops.py 中的方法,这个文件也是在编译 TensorFlow 时生成的,位于 Python 库 site-packages/tensorflow/python/ops/gen_array_ops.py中,随后又调用了ite-packages/tensorflow/core/kernels/下面的核函数实现
拓展部分
本人通过anaconda安装的独立环境tensorflow中,安装了tensorflow包,此包的位置在/home/anaconda3/envs/tensorflow/lib/python3.6/site-packages中,

2.7.3 其他概念
除了边和节点,TensorFlow 还涉及其他一些概念,如图、会话、设备、变量、内核等。下面就分别介绍一下
1.图
把操作任务描述成有向无环图。
以下代码示意了如何获取默认计算图以及如何查看一个运算所属的计算图
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
graph1 = tf.Graph() # 显式创建图对象
graph2 = tf.get_default_graph()
with graph1.as_default():
a = tf.constant([1, 2, 3], name='a_input')
with graph2.as_default():
b = tf.constant([1, 2, 4], name='b_input')
c = tf.constant([2], name='c')
print(a.graph is b.graph)
print(b.graph is c.graph)
print(c.graph is a.graph)

注意:不同计算图上的张量和运算都不会共享
TensorFlow 程序通常被组织成一个构建阶段, 和一个执行阶段. 在构建阶段, op 的执行步骤 被描述成一个图.在执行阶段, 使用会话执行执行图中的 op.例如, 通常在构建阶段创建一个图来表示和训练神经网络, 然后在执行阶段反复执行图中的训练 op.TensorFlow 支持 C, C++, Python 编程语言. 目前, TensorFlow 的 Python 库更加易用, 它提供了大量的辅助函数来简化构建图的工作, 这些函数尚未被 C 和 C++ 库支持.三种语言的会话库 (session libraries) 是一致的。
那么,如何构建一个图呢?构建图的第一步是创建各个节点。构建图的第一步, 是创建源 op (source op). 源 op 不需要任何输入, 例如 常量 (Constant) . 源 op 的输出被传递给其它 op 做运算。Python 库中, op 构造器的返回值代表被构造出的 op 的输出【即tensor数据】, 这些返回值可以传递给其它 op 构造器作为输入。TensorFlow Python 库有一个默认图 (default graph), op 构造器可以为其增加节点. 这个默认图对 许多程序来说已经足够用了.
如果要获取节点的具体输出tensor值,你必须在会话里启动这个图.构造阶段完成后, 才能启动图.
拓展知识1 python中的比较:==和is的区别
is 比较的是两个实例对象是不是完全相同,它们是不是同一个对象,占用的内存地址是否相同
== 比较的是两个对象的内容是否相等,即内存地址可以不一样,内容一样就可以了。
拓展知识2:tf.constant 函数
tf.constant(value,dtype=None,shape=None,name=’Const’)
创建一个常量tensor,按照给出value来赋值,可以用shape来指定其形状。value可以是一个数,也可以是一个 list。 如果是一个数,那么这个常量中所有值的按该数来赋值。 如果是list,那么len(value)一定要小于等于shape展开后的 长度。赋值时,先将value中的值逐个存入。不够的部分,则全部存入value的最后一个值。
参考 tensorflow笔记 :常用函数说明https://blog.csdn.net/u014595019/article/details/52805444
2.会话
启动图的第一步是创建一个 Session 对象。会话(session)提供在图中执行操作的一些方法。一般的模式是,建立会话,此时会生成一张空图,在会话中添加节点和边,形成一张图,然后执行。要创建一张图并运行操作的类,在 Python 的 API 中使用 tf.Session,在 C++ 的 API 中使用tensorflow::Session。
在调用 Session 对象的 run()方法来执行图时,传入一些 Tensor,这个过程叫填充(feed);返回的结果类型根据输入的类型而定,这个过程叫取回(fetch)
import tensorflow as tf
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点
# 加到默认图中.
# 构造器的返回值代表该常量 op 的返回值.
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.
# 返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)
# 启动默认图.
sess = tf.Session()
# 调用 sess 的 'run()' 方法来执行行矩阵乘法 op op, 传入 'product' 作为该方法的参数.
# 'product' 代表了矩阵乘法 op 的输出, 传入它是向方法表明, 我们希望取回矩阵乘法 op 的输出.
# 整个执行过程是自动化的, 会话负责传递 op 所需的全部输入. op 通常是并发执行的.
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.
# 返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(product)
print result
# ==> [[ 12.]]
# 任务完成, 关闭会话.
sess.close()
与会话相关的源代码位于/home/anaconda3/envs/tensorflow/lib/python3.6/site-packages/tensorflow/python/client/session.py

会话是图交互的一个桥梁,一个会话可以有多个图,会话可以修改图的结构,也可以往图中注入数据进行计算。因此,会话主要有两个 API 接口:Extend 和 Run。Extend 操作是在 Graph中添加节点和边,Run 操作是输入计算的节点和填充必要的数据后,进行运算,并输出运算结果
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
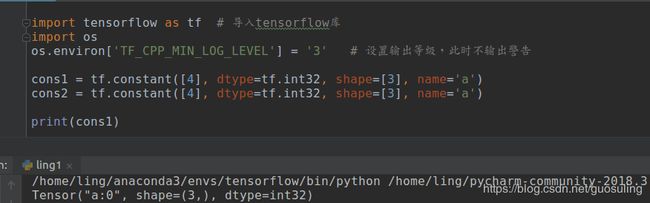
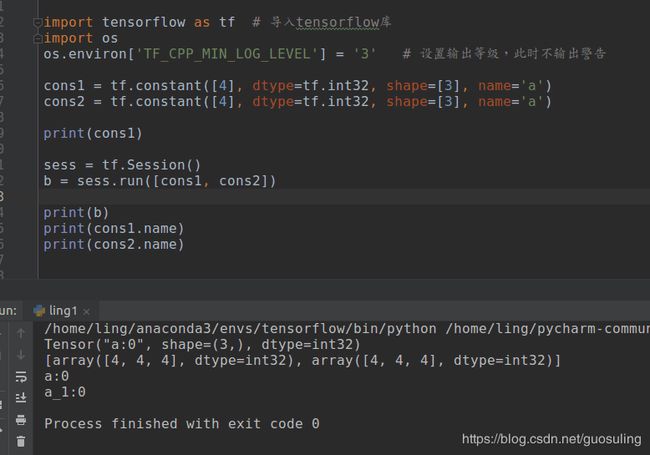
cons1 = tf.constant([4], dtype=tf.int32, shape=[3], name='a')
cons2 = tf.constant([4], dtype=tf.int32, shape=[3], name='a')
print(cons1)
sess = tf.Session()
b = sess.run([cons1, cons2])
print(b)
print(cons1.name)
print(cons2.name)
上述代码运行结果如下,从此图可以看出,面对相同节点名(代码中是a)tensorflow会为其赋予拓展的节点名(图中是a:0,a_1:0)
3、设备
设备(device)是指一块可以用来运算并且拥有自己的地址空间的硬件,如 GPU 和 CPU。TensorFlow 为了实现分布式执行操作,充分利用计算资源,可以明确指定操作在哪个设备上执行。
在实现上, TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU). 一般你不需要显式指定使用 CPU 还是 GPU, TensorFlow 能自动检测. 如果检测到 GPU, TensorFlow 会尽可能地利用找到的第一个 GPU 来执行操作.如果机器上有超过一个可用的 GPU, 除第一个外的其它 GPU 默认是不参与计算的. 为了让 TensorFlow 使用这些GPU, 你必须将 op 明确指派给它们执行. with...Device 语句用来指派特定的 CPU 或 GPU 执行操作:
具体如下:
with tf.Session() as sess:
# 指定在第二个 gpu 上运行
with tf.device("/gpu:1"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
设备用字符串进行标识. 目前支持的设备包括:
• "/cpu:0" : 机器的 CPU.
• "/gpu:0" : 机器的第一个 GPU, 如果有的话.
• "/gpu:1" : 机器的第二个 GPU, 以此类推.
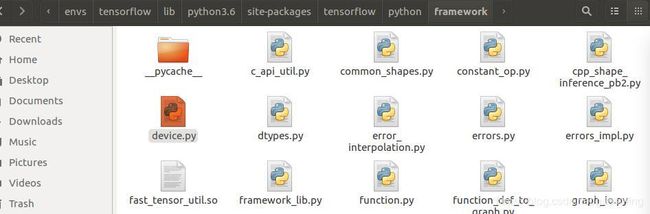
与设备相关的源代码位于:/home/anaconda3/envs/tensorflow/lib/python3.6/site-packages/tensorflow/python/framework/device.py
指定设备的方法还有,通过 tf.ConfigProto 来构建一个 config,在 config 中指定相关的 gpu,并且在session 中传入参数 config=“自己创建的 config”来指定 gpu 操作。
tf.ConfigProto()的参数如下: log_device_placement=True:是否打印设备分配日志;allow_soft_placement=True:如果指定的设备不存在,允许 TF 自动分配设备。

上文的 tf.ConfigProto()生成 config 之后,还可以设置其属性来分配 GPU 的运算资源。如下代码就是按需分配的意思
config = tf.ConfigProto(log_device_placement=True, allow_soft_placement=True)
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
使用 allow_growth option,刚一开始分配少量的 GPU 容量,然后按需慢慢的增加,由于不会释放内存,所以会导致碎片,同样上述代码也可以放在 config 创建的时指定,举例:

如下代码还可以给 GPU 分配固定大小的计算资源。
![]()
代表分配给 tensorflow 的 GPU 显存大小为:GPU 实际显存*0.7
4、变量
变量(variable)是一种特殊的数据,它在图中有固定的位置,不像普通张量那样可以流动。例如,创建一个变量张量,使用 tf.Variable()构造函数,这个构造函数需要一个初始值,初始值的形状和类型决定了这个变量的形状和类型
# 创建一个变量,初始化为标量 0
state = tf.Variable(0, name="counter")TensorFlow 还提供了填充机制,可以在构建图时使用 tf.placeholder()临时替代任意操作的张量,在调用 Session 对象的 run()方法去执行图时,使用填充数据作为调用的参数,调用结束后,填充数据就消失。代码示例如下:
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1, input2)
with tf.Session() as sess:
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
# 输出 [array([ 14.], dtype=float32)]与变量相关的源代码位于/home/anaconda3/envs/tensorflow/lib/python3.6/site-packages/tensorflow/python/ops/variables.py中

5、内核
我们知道操作(operation)是对抽象操作(如 matmul 或者 add)的一个统称,而内核(kernel)则是能够运行在特定设备(如 CPU、GPU)上的一种对操作的实现。因此,同一个操作可能会对应多个内核
当自定义一个操作时,需要把新操作和内核通过注册的方式添加到系统中。
6、交互式使用
为了便于使用诸如 IPython 之类的 Python 交互环境, 可以使用 InteractiveSession 代替 Session 类, 使用Tensor.eval() 和 Operation.run() 方法代替 Session.run() .
Tensorflow:interactivesession和session的区别。 https://blog.csdn.net/lvsehaiyang1993/article/details/80728675
TensorFlow中run与eval的区别 https://blog.csdn.net/pestzhang/article/details/80267025
tf.InteractiveSession()是一种交替式的会话方式,它让自己成为了默认的会话,也就是说用户在单一会话的情境下,不需要指明用哪个会话也不需要更改会话运行的情况下,就可以运行起来,这就是默认的好处。 tf.InteractiveSession()默认自己就是用户要操作的会话(session),而tf.Session()没有这个默认,因此用eval()启动计算时需要指明使用那个会话(session)。这样的话就是run和eval()函数可以不指明session啦简单来说InteractiveSession()等价于:
sess=tf.Session()
with sess.as_default():即,下面两段代码等价
sess=tf.InteractiveSession()
print (testc.eval())
sess=tf.Session()
print (c.eval(session=sess))如果你有一个Tensor t,在使用t.eval()时,等价于:tf.get_default_session().run(t). 这其中最主要的区别就在于你可以使用sess.run()在同一步获取多个tensor中的值,
2.7.4 了解模型的运行机制
TensorFlow 的运行机制属于“定义”与“运行”相分离。从操作层面可以抽象成两种:模型构建和模型运行
下图表示了 session 与图的工作关系
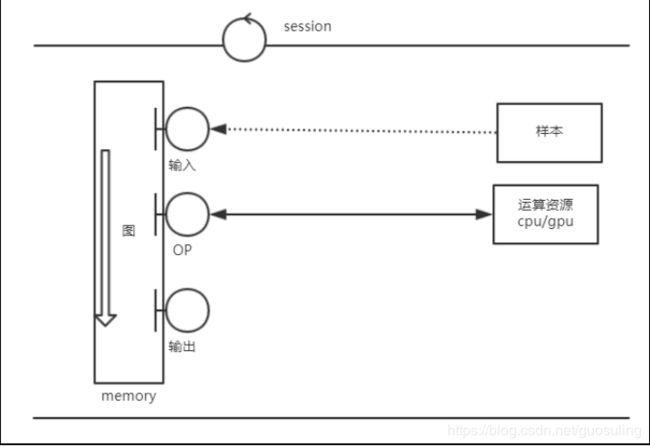
在实际环境中,这种运行情况会有三种应用场景,训练场景、测试场景与使用场景。在训练场景下图的运行方式与其他两种不同,具体介绍如下:
(1)训练场景:主要是实现模型从无到有的过程,通过对样本的学习训练,调整学习参数,成最终的模型。其过程是将给定的样本和标签作为输入节点,通过大量的循环迭代,将图正向运算得到输出值,再进行反向运算更新模型中的学习参数。最终使模型产生的正向结果最大化的接近样本标签。这样就得到了一个可以拟合样本规律的模型。
(2)测试场景和使用场景:测试场景是利用图的正向运算得到结果比较与真实值的产别;使用场景也是利用图的正向运算得到结果,并直接使用。所以二者的运算过程是一样的。对于该场景下的模型与正常编程用到的函数特别相似。大家知道,在函数中,可以分为:实参、形参、函数体与返回值。同样在模型中,实参就是输入的样本,形参就是占位符,运算过程就相当于函数体,得到的结果相当于返回值
2.8 常用API
2.8.1 图、操作和张量
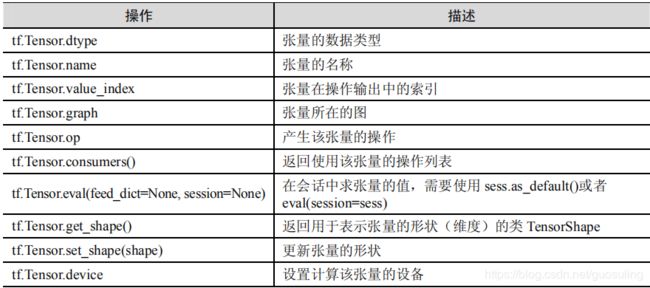
TensorFlow 的计算表现为数据流图,所以 tf.Graph 类中包含一系列表示计算的操作对象(tf.Operation),以及在操作之间流动的数据—张量对象(tf.Tensor).与图相关的 API 均位于tf.Graph 类中,如下表所示

tf.Operation 类代表图中的一个节点,用于计算张量数据。该类型由节点构造器(如 tf.matmul()或者 Graph.create_op())产生。例如,c = tf.matmul(a, b)创建一个 Operation 类,其类型为 MatMul的操作类。与操作相关的 API 均位于 tf.Operation 类中,参见下表


tf.Tensor 类是操作输出的符号句柄,它不包含操作输出的值,而是提供了一种在 tf.Session中计算这些值的方法。这样就可以在操作之间构建一个数据流连接,使 TensorFlow 能够执行一个表示大量多步计算的图形。与张量相关的 API 均位于 tf.Tensor 类中,参见下表
2.8.2 可视化
可视化时,需要在程序中给必要的节点添加摘要(summary),摘要会收集该节点的数据,并标记上第几步、时间戳等标识,写入事件文件(event file)中。tf.summary.FileWriter 类用于在目录中创建事件文件,并且向文件中添加摘要和事件,用来在 TensorBoard 中展示
下表 给出了可视化常用的 API 操作


2.9 变量作用域
在 TensorFlow 中有两个作用域(scope),一个是 name_scope,另一个是 variable_scope。它们究竟有什么区别呢?简而言之,name_scope主要是给variable_name加前缀,也可以给op_name加前缀;variable_scope 是给 variable_name 加前缀。
2.9.1 variable_scope 示例
variable_scope 变量作用域机制在 TensorFlow 中主要由两部分组成,variable_scope 主要用在循环神经网络(RNN)的操作中,其中需要大量的共享变量。
2.9.2 name_scope 示例
TensorFlow 中常常会有数以千计的节点,在可视化的过程中很难一下子展示出来,因此用 name_scope 为变量划分范围,在可视化中,这表示在计算图中的一个层级。name_scope会影响 op_name,不会影响用 get_variable()创建的变量,而会影响通过 Variable()创建的变量。
tensorflow中tf.Variable() 方法和 tf.get_variable()方法的区别https://blog.csdn.net/timothytt/article/details/79789274
除了用法稍有不同外,二者本质区别在于,当出现name冲突时处理不同
var1 = tf.Variable(initial_value=0.0, name="var")
var2 = tf.Variable(initial_value=0.1, name="var")
print(var1.name)
print(var2.name)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(var1.eval())
print(var2.eval())
执行结果如下:
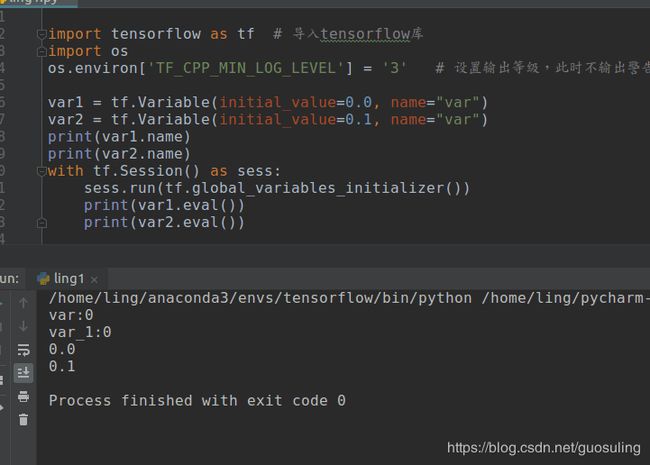
可以看到,虽然我们把两个变量名字都取作‘var’,但是第二个被自动重命名为‘var_1’。 结论:使用 tf.Variable() 方法时不用担心名字冲突,框架会自动处理。
tf.get_variable()方法,根据在tensorflow命名空间内是否开启自动变量复用
1. 不开启变量复用

注意:默认的变量作用域不开启自动变量复用
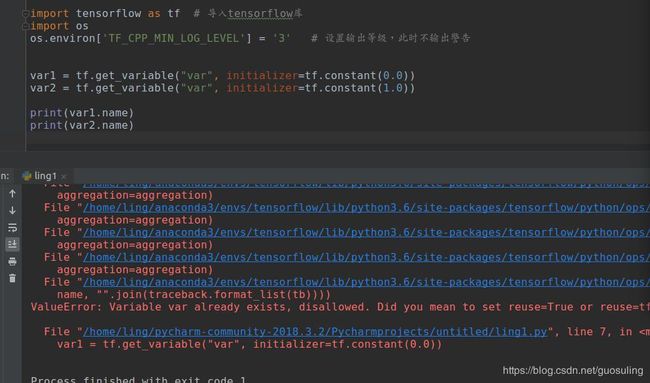
2. 开启变量复用【reuse:复用】
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
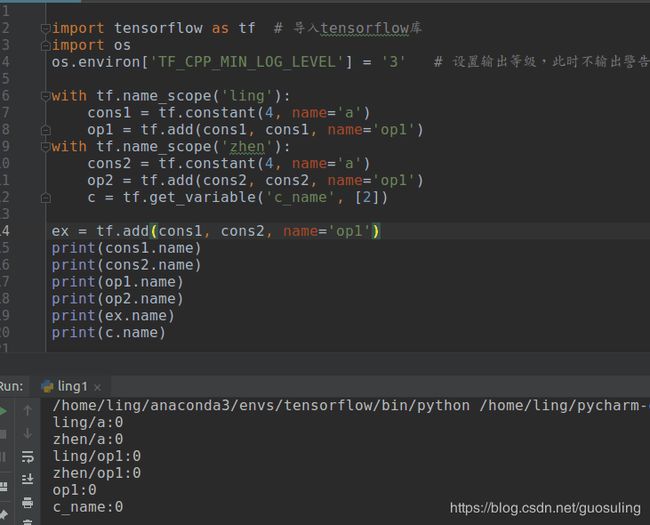
with tf.variable_scope('ling', reuse=tf.AUTO_REUSE):
var1 = tf.get_variable("var", initializer=tf.constant(0.0))
var2 = tf.get_variable("var", initializer=tf.constant(1.0))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(var1.name);print(var1.eval())
print(var2.name);print(var2.eval())运行结果如下:
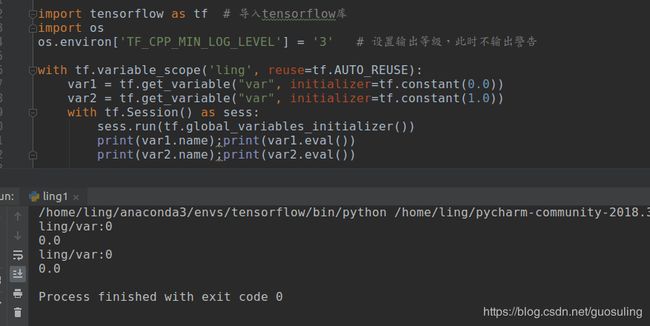
结论:开启复用后,tf.get_variable() 生成的变量,会被复用,但值是第一次赋值的那个值。