本文从CSDN上转移过来:
http://blog.csdn.net/mounty_fsc/article/details/51092906
本部分剖析Caffe中Net::Forward()函数,即前向计算过程。从LeNet网络角度出发,且调式网络为测试网络(区别为训练网络),具体网络层信息见(Caffe,LeNet)初始化测试网络(四)
1 入口信息
通过如下的调用堆栈信息可以定位到函数ForwardFromTo(其他函数中无重要信息)
caffe::Net::ForwardFromTo() at net.cpp:574
caffe::Net::ForwardPrefilled() at net.cpp:596
caffe::Net::Forward() at net.cpp:610
对于ForwardFromTo有,对每层网络前向计算(start=0,end=11共12层网络)。
template
Dtype Net::ForwardFromTo(int start, int end) {
for (int i = start; i <= end; ++i) {
Dtype layer_loss = layers_[i]->Forward(bottom_vecs_[i], top_vecs_[i]);
loss += layer_loss;
}
return loss;
}
在ForwardFromTo中,对网络的每层调用Forward函数,Forward中根据配置情况选择调用Forward_gpu还是Forward_cpu。
以下主要从Forward_gpu中绍介
2 第一层DataLayer
DataLayer未实现Forward_cpu或Forward_gpu,其父类BasePrefetchingDataLayer实现了。
内容为从BasePrefetchingDataLayer的数据缓存队列BlockingQueue取出一个Batch的数据放入DataLayer的Top Blob中,其中Top[0]存放数据,Top[1]存放标签。
3 第二层SplitLayer
SplitLayer有两个Top Blob label_mnist_1_split_0和label_mnist_1_split_1,在其Forward_g(c)pu中,从它的Bottom Blob,也就是DataLayer的第二个Top Blob,label中把数据复制到label_mnist_1_split_0和label_mnist_1_split_1中。
代码如下,将bottom[0]复制成多个top blob
void SplitLayer::Forward_gpu(const vector*>& bottom,
const vector*>& top) {
for (int i = 0; i < top.size(); ++i) {
top[i]->ShareData(*bottom[0]);
}
}
4 第三层ConvolutionLayer
Caffe中的卷原理见(Caffe)卷积的实现
以GPU为例,展开代码如下:
template
void ConvolutionLayer::Forward_gpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* weight = this->blobs_[0]->gpu_data();
//对第一个Bottom Blob,对于Lenet此处只有一个Bottom Blob
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->gpu_data();
//对于一个Batch中的第一个样本的Featrue Maps,对于Lenet此处num_为64(train)或者100(test)
for (int n = 0; n < this->num_; ++n) {
//bottom_data中的数据与weight作卷积,结果放入top_data中
this->forward_gpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
//*****展开forward_gpu_gemm开始*****
template
void BaseConvolutionLayer::forward_gpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
//1x1卷积不处理
if (!is_1x1_) {
if (!skip_im2col) {
//把图像展开成列,进而可以表示一个矩阵(即这个矩阵最后还是写成了一个列向量col_buffer)
conv_im2col_gpu(input, col_buffer_.mutable_gpu_data());
}
col_buff = col_buffer_.gpu_data();
}
//调用gemm,对weights与col_buff作卷积,结果放入output
caffe_gpu_gemm(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}
//*****展开forward_gpu_gemm结束*****
//计算偏置
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->gpu_data();
this->forward_gpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}
5 第四层PoolingLayer
Caffe中实现了Max Pooling和Average Pooling两种方法,cuda代码在理解算法上会更易读些:
template
__global__ void MaxPoolForward(...) {
//CUDA_KERNEL_LOOP为caffe中的相关宏,index为线程索引,caffe中grid,block(512)都一维的
//在其它《(Caffe)编程小技巧》中介绍了
//nthreads为线程的总数,为该pooling层top blob的输出神经元总数,也就是说一个线程对应输出的一个结点
CUDA_KERNEL_LOOP(index, nthreads) {
// 该线程对应的top blob(N,C,H,W)中的N,即样本个数
const int n = index / pooled_width / pooled_height / channels;
// 该线程对应的top blob(N,C,H,W)中的C,即第C个Channel(number of feature maps)
const int c = (index / pooled_width / pooled_height) % channels;
// 该线程对应的top blob(N,C,H,W)中的H,输出Feature Map的中的高的坐标
const int ph = (index / pooled_width) % pooled_height;
// 该线程对应的top blob(N,C,H,W)中的W,输出Feature Map的中的宽的坐标
const int pw = index % pooled_width;
// hstart,wstart,hend,wend分别为bottom blob(上一层feature map)中的点的坐标范围
// 由这些点计算出该线程对应的点(top blob中的点)
int hstart = ph * stride_h - pad_h;
int wstart = pw * stride_w - pad_w;
const int hend = min(hstart + kernel_h, height);
const int wend = min(wstart + kernel_w, width);
hstart = max(hstart, 0);
wstart = max(wstart, 0);
Dtype maxval = -FLT_MAX;
int maxidx = -1;
// bottom_slice为上一层(bottom blob)中相关的那**一个**feature map的切片视图
const Dtype* const bottom_slice =
bottom_data + (n * channels + c) * height * width;
for (int h = hstart; h < hend; ++h) {
for (int w = wstart; w < wend; ++w) {
if (bottom_slice[h * width + w] > maxval) {
maxidx = h * width + w;
maxval = bottom_slice[maxidx];
}
}
}
// index正好是top blob中对应点的索引,这也是为什么线程都是用了一维的维度
// 数据在Blob.data中最后都是一维的形式保存的
top_data[index] = maxval;
if (mask) {
mask[index] = maxidx;
} else {
top_mask[index] = maxidx;
}
}
}
6 第七层InnerProductLayer
在InnerProductLayer的Forward_gpu实际止调用了以下的核心代码来求两个矩阵的积。其中bottom_data为$M \times K$的矩阵,weight为 $N \times K$ 的矩阵,top_data为$M \times N$ 的矩阵,M_为样本个数,K为bottom中第个样本的维度,N为top中每个样本的维度,准确说明见(Caffe,LeNet)初始化训练网络(三) 第7部分。
caffe_gpu_gemm(CblasNoTrans, CblasTrans, M_, N_, K_, (Dtype)1.,
bottom_data, weight, (Dtype)0., top_data);
caffe_gpu_gemm中的实际上调用了cublas的矩阵计算。
void caffe_gpu_gemm(const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K,
const float alpha, const float* A, const float* B, const float beta,
float* C) {
// Note that cublas follows fortran order.
int lda = (TransA == CblasNoTrans) ? K : M;
int ldb = (TransB == CblasNoTrans) ? N : K;
// lenet中cuTransA是不转置的
cublasOperation_t cuTransA =
(TransA == CblasNoTrans) ? CUBLAS_OP_N : CUBLAS_OP_T;
// lenet中cuTransB是需要转置的
cublasOperation_t cuTransB =
(TransB == CblasNoTrans) ? CUBLAS_OP_N : CUBLAS_OP_T;
CUBLAS_CHECK(cublasSgemm(Caffe::cublas_handle(), cuTransB, cuTransA,
N, M, K, &alpha, B, ldb, A, lda, &beta, C, N));
}
这里针对caffe的例子对调用cublas做说明:
Caffe中Blob矩阵逻辑表达与物理存储的关系见 (Caffe)基本类Blob,Layer,Net(一) 1.4部分描述
-
Caffe行优先存储,Cuda列优先存储,矩阵表达的关系:主机端的矩阵$B$,其与设备端的$B^T$在物理存储上是等价的
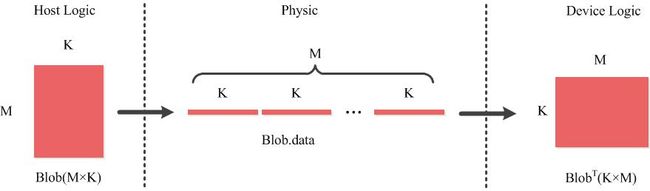 这里写图片描述
这里写图片描述
-
InnerProductLayer中的例子
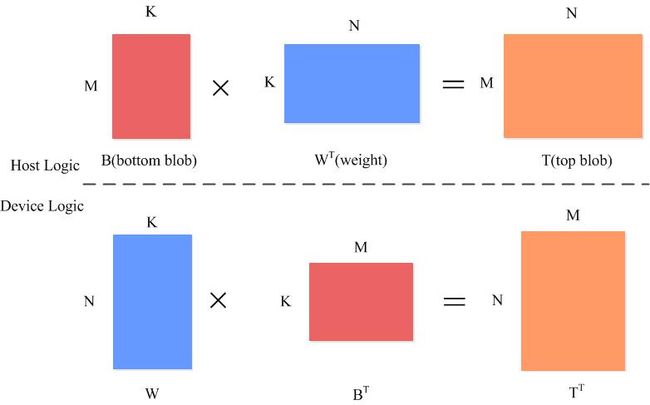 这里写图片描述
这里写图片描述
- 要计算主机端的$T$,实际上是要计算设备端的$TT$,所以用公式$TT=W \times B^T$(设备端表示)
- 而主机端的$B$,$W$与设备端的$BT$,$WT$物理上是相同的存储,所以在调用cublasSgemm的时候(此时在主机端),需要对$W$设置转置
- cublasSgemm的计算公式为$$C=alpha \times A \times B+beta \times C$$
7 第八层ReLUForward
ReLu层很简单,就是实现了公式$$out = max(0,in)$$
核心代码如下,其中negative_slope一般取0,即为以上公式。
out[index] = in[index] > 0 ? in[index] : in[index] * negative_slope;
8 第十一层AccuracyLayer
void AccuracyLayer::Forward_cpu(const vector*>& bottom,
const vector*>& top) {
Dtype accuracy = 0;
// 一个Batch中包含的样本数量,lenet中outer_num_=100
for (int i = 0; i < outer_num_; ++i) {
//一个样本对应的类别数量,lenet中一个样本一个标签,所以inner_num_=1
for (int j = 0; j < inner_num_; ++j) {
//该样本的label
const int label_value = static_cast(bottom_label[i * inner_num_ + j]);
// top_k为取前k个最高评分(的预测标签)
// Top-k accuracy
std::vector > bottom_data_vector;
// num_labels为分类类别个数,lenet中为10
// 接下来两步把测试评分与类别ID挂勾,并对评分排序
for (int k = 0; k < num_labels; ++k) {
bottom_data_vector.push_back(std::make_pair(
bottom_data[i * dim + k * inner_num_ + j], k));
}
std::partial_sort(
bottom_data_vector.begin(), bottom_data_vector.begin() + top_k_,
bottom_data_vector.end(), std::greater >());
// 看top_5个预测的标签与实际标签是不是相同
// check if true label is in top k predictions
for (int k = 0; k < top_k_; k++) {
if (bottom_data_vector[k].second == label_value) {
++accuracy;
if (top.size() > 1) ++top[1]->mutable_cpu_data()[label_value];
break;
}
}
// 最后的正确率写入只有一个单位的top blob中
top[0]->mutable_cpu_data()[0] = accuracy / count;
}
}
}
说明:
- outer_num_与inner_num_和为样本总数量
- lenet中outer_num_为一个Batch中包含的样本数量
- lenet中inner_num_为1
- 详细见介绍AccuracyLayer的博文
- top_k为取前k个最高评分(的预测标签)
9 第十二层SoftmaxWithLossLayer
关于SoftmaxWithLossLayer与SoftmaxLayer的关系参见(Caffe,LeNet)初始化训练网络(三)10.3节
9.1 SoftmaxLayer
在其Forward_gpu函数中把10010的bottom blob,计算得到10010的top blob,可以理解为100个样本,每个样本特征数量为10,计算这100个样本分别在10个类别上的概率。计算公式如下:
$$f(z_k)=\frac{e{z_k-m}}{\sum_in{e^{z_i-m}}}$$
$$m=max(z_i)$$
对应的说明图,针对一个样本而言,y为样本的标签:
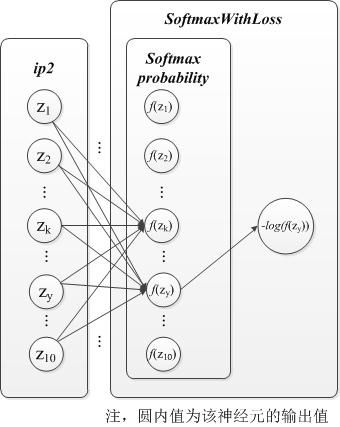
代码如下:
void SoftmaxLayer::Forward_gpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* bottom_data = bottom[0]->gpu_data();
// top shape: 100*10
Dtype* top_data = top[0]->mutable_gpu_data();
// scale shape: 100*1
Dtype* scale_data = scale_.mutable_gpu_data();
int count = bottom[0]->count();
int channels = top[0]->shape(softmax_axis_);
// 从bottom 复制到 top,以下操作都在top上进行
caffe_copy(count, bottom_data, top_data);
// 求最大值m=max(z_i)(存放在scale_data)
kernel_channel_max<<>>(outer_num_, channels, inner_num_, top_data,
scale_data);
// 求减法,z_k-m(存放在top_data)
kernel_channel_subtract<<>>(count, outer_num_, channels, inner_num_,
scale_data, top_data);
// 求指数e^{z_k-m}(存放在top_data)
kernel_exp<<>>(
count, top_data, top_data);
// 求和\sum_i^n{e^{z_i-m}}(存放在scale_data)
kernel_channel_sum<<>>(outer_num_, channels, inner_num_, top_data,
scale_data);
// 求除法,得到结果\frac{e^{z_k-m}}{\sum_i^n{e^{z_i-m}}}(存放在top_data)
kernel_channel_div<<>>(count, outer_num_, channels, inner_num_,
scale_data, top_data);
}
9.2 SoftmaxWithLossLayer
对于样本(x,y),z为x经过网络处理后在ip2层的输出,也就是SoftmaxWithLossLayer的输入,同时也是Softmax的输入。注意n为n个样本,y为样本对应的类别(标签),y=0,1,...,N,损失如下公式计算:
$$loss=\sum^n-\log{f(z_y)}$$
Forward_gpu函数代码:
void SoftmaxWithLossLayer::Forward_gpu(
const vector*>& bottom, const vector*>& top) {
// 计算出prob_(100*10维),即每个样本属于某个类别的概率
softmax_layer_->Forward(softmax_bottom_vec_, softmax_top_vec_);
const Dtype* prob_data = prob_.gpu_data();
const Dtype* label = bottom[1]->gpu_data();
const int dim = prob_.count() / outer_num_;
const int nthreads = outer_num_ * inner_num_;
// 求loss,见公式
// prob_data为100*10,label为100*10,
// 计算后得loss_data为100*1
SoftmaxLossForwardGPU<<>>(nthreads, prob_data, label, loss_data,
outer_num_, dim, inner_num_, has_ignore_label_, ignore_label_, counts);
Dtype loss;
// 求和,loss_data为(1)所以最后输出为1维
caffe_gpu_asum(nthreads, loss_data, &loss);
// 归一化,除以样本总数。最后存放在top blob中,top blob只有一个单位内在,用来存放loss
top[0]->mutable_cpu_data()[0] = loss / get_normalizer(normalization_, valid_count);
}
SoftmaxLossForwardGPU代码:
// 为了提高可读性,代码有改动
__global__ void SoftmaxLossForwardGPU(const int nthreads,
const Dtype* prob_data, const Dtype* label, Dtype* loss,
const int num, const int dim, const int spatial_dim,
const bool has_ignore_label_, const int ignore_label_,
Dtype* counts) {
CUDA_KERNEL_LOOP(index, nthreads) {
const int n = index;
//label_value为真实标签
const int label_value = static_cast(label[n]);
loss[index] = -log(max(prob_data[n * dim + label_value], Dtype(FLT_MIN)));
counts[index] = 1;
}
}