逻辑综合重点解析(Design Compiler篇)
前言
本文摘录自微信公众号 “数字芯片实验室”
欢迎关注

1、逻辑综合(Logic Synthesis)分为哪三个步骤?

逻辑综合的行为是将数字电路的寄存器传输级描述(RTL,Register Transfer Level)“综合”成门级网表(Gate-Level Netlist)。Design Compiler将RTL和根据设计需求编写的约束文件作为输入综合出门级网表,在性能、面积和功耗之间进行trade-offs。后端Place&Route工具(ICC、Innovus)将门级网表作为输入生成GDSII文件用于芯片制造。
逻辑综合 = 翻译 + 优化+ 映射。其中,read_verilog将RTL翻译成GTECH,compile进行综合,也就是优化和映射成工艺相关的门级网表。
2、当你拿到一个ddc格式的文件,你是否能够知道这是一个已经综合过的设计?
False
综合前和综合后的设计都能够保存为.ddc格式。一般保存在unmapped和mapped 文件夹下。
3、使用Design Compiler进行逻辑综合出现下述log,请问gtech.db和standard.sldb包含哪些信息?

gtech.db和standard.db是synopsys提供的默认库,分别包含了GTECH逻辑单元和基本的DesignWare IP模块。在使用read命令时,这些库都被自动地加载。
4、Design Compiler综合过程中,target_library是如何被使用的?
target_library使用在"compile"过程中,用来生成工艺相关的门级网表。Design Compiler尽量选择面积最小的逻辑门去满足设计功能和时序的要求。
如果不通过“set target_library *”指定目标工艺库,默认值是your_library.db,同时工具会报出warning
5、Design Compiler 综合过程中 “link”命令完成了什么功能?
link是Design Compiler ”resolve”设计中例化模块的过程。Design Compiler通过变量“link_library”指定例化模块库的位置,和target_library一样,默认为your_library.db。建议显式地使用link命令,否则工具可能带着“unresolved references”进行综合,产生没有意义的结果,同时浪费时间。
6、link_library = “ * $target_library”中的 "*"指的是什么 ?
DC memory 。Design Compiler 首先会在DC memory中寻找匹配的例化模块。
7、Design Compiler 逻辑综合中 search_path变量的作用是什么?
DC在search_path指定的目录底下寻找设计代码和库文件。建议在search_path中使用相对路径,增强脚本环境的可移植性
8、Design Compiler 逻辑综合流程中,下述脚本的意义是?

避免某些设计者只使用run 脚本综合设计,不仔细查看log和reoport。基于错误的link或者check_design结果run完整个综合流程会浪费大量不必要的时间。
9、将综合前的设计保存为.ddc的格式文件有什么好处?
read命令将rtl(unmapped)翻译成GTECH格式。对于一个较大的设计,rtl to ddc需要花费很长的时间。当我们需要对设计重新进行compile时,只要读取保存的unmapped的设计(.ddc)就能节省很多时间。如果rtl已经被更新,还是要重新读入rtl.
10、请问在Design Compiler综合过程中,下述命令的作用是什么?
Design Compiler 完成了ASIC设计流程中的rtl to netlist过程,后续需要有第三方工具完成netlist to GDSII的实现。而第三方工具对于netlist有字符语法上的限制,所以需要使用change_names 命令,才能让第三方工具正确识别netlist。
11、下面哪个是关于target_library和link_library变量正确的表述?
a)所有在设计中例化的宏模块都应该在target_library中设置
b) 在compile期间,DC从link_library中选择最小的逻辑门去满足时序要求
c) link_library用于resolve例化模块,target_library用于在compile
d) link_library自动加载.ddc文件
C
a) 应该是 link_library
b) 应该是 target_library
d) 应该是 link
12、在设计中,port和pin有什么异同?
相同点:port和pin都是一个input/output;
不同点:port是当前设计的input/output;
pin是当前设计中例化模块的input/output。
如果当前设计被另外的设计例化,则port会变成pin
13、在Design Compiler中如何正确地使用set_max_area约束命令?
如果是面积约束过于严格,或者直接设为0,Design Compiler将执行面积优化,直到无法优化为止。面积优化可能会增加run time,但是不会影响时序优化。 时序约束优先级总是高于面积约束。 如果run time是一个需要在乎的问题,请将面积约束设为实际设计要求的值。 如果不关心run time,可以将其设置0。
14、Design Compiler是如何划分时序路径进行时序分析的?

Design Compiler将设计划分为一个个timing path,每一条路径都有一个startpoint(input port、触发器的clock pin)和一个endpoint(output ports、触发器的data pin)
Design Compiler会计算每一条路径的延时,然后比较arrive time和require time来判断这条路径是否满足时序要求。
15、Design Compiler如何在逻辑综合的时候考虑到时钟树的影响?
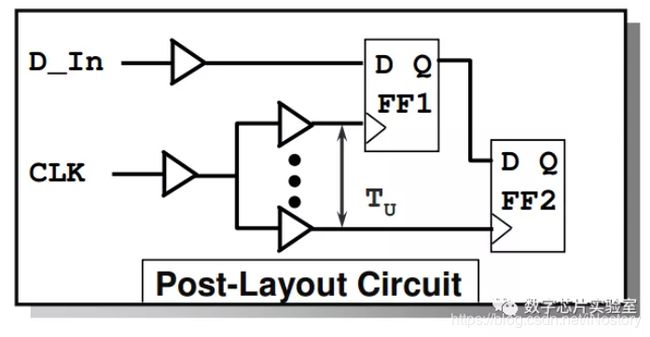
Design Compiler可以使用 set_clock_uncertainty命令来建模时钟的skew + jitter + margin。如果不设置的话,默认值为0
16、Design Compiler如何在逻辑综合阶段考虑时钟延迟的影响?
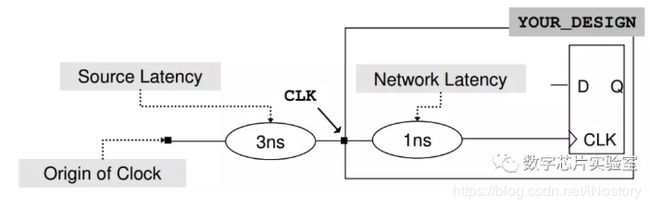
时钟的network latency是指时钟输入端口到触发器的时钟端延迟;
时钟的source latency是指实际的时钟源到时钟输入端口延迟。
在pre_layout阶段,使用set_clock_latency (-source)来建模;
在post_layout阶段,使用set_propagated_clock来建模。
17、什么是virtual clock,有什么用处 ?
未连接到任何port或pin的时钟
用作输入或输出延迟的参考点
18、为什么模块级设计推荐寄存器输出?
方便后级模块时序约束和时序预算
19、input path、output path和reg-to-reg path分别被什么sdc语句约束?
input path :set_input_delay
output path :set_output_delay
reg-to-reg : create_clock
20、Design Compiler综合中,set_max_capacitance命令的用处是什么?
max_capacitance属于“逻辑DRC”,它限制了端口的扇出电容。默认情况下,逻辑DRC的优先级高于时序和面积约束。max_capacitance是由工艺厂的库决定的。
21、如何通过tcl脚本找出lib库最大的max_capacitance ?

22、Design Compiler 在综合时如何估计pre_layout的cell和net延时?

Design Compiler使用非线性延迟模型生成查找表, 用于计算cell延迟。

基于扇出和工艺厂提供的线负载模型(set_wire_load_model)计算net延迟。
23、Design Compiler 的Topographical Mode相比Wire Load Models有什么优势?
线负载模型(WLM)是基于工艺厂的数据统计,而不是特定于自己的设计。在深亚微米(UDSM)设计中,互连寄生参数对路径延迟有很大的影响 ,WLM是不够准确的。
Topographical Mode使用placement算法来估计线延时,提供和实际物理布局更好的时序相关性。
Topographical Mode 除了逻辑库之外,还需要物理库(Milkyway)
24、使用Design Compiler,在compile或optimize之后应该执行的分析操作是什么?
report_constraint –all_violators,如果这个报告表明没有违规行为,不需要进一步的时序和逻辑DRC分析。 如果有违规,可以使用report_timing执行更详细的分析。
25、Milkyway库包含了哪些信息,Design Compiler中如何指定Milkyway库?
物理Milkyway库(例如std,ip和pad)包含cell的物理布局描述,用于执行placement。 technology file定义了该工艺金属层,物理设计规则,电阻,电容单位等。TLU-plus文件定义深亚微米RC寄生模型。 这些文件由工艺厂商提供。
在Design Compiler中,由下列命令定义:

26、Floorplan是通过什么指标来设置芯片的大小和形状的?
Aspect Ratio(height/width),默认比值为1
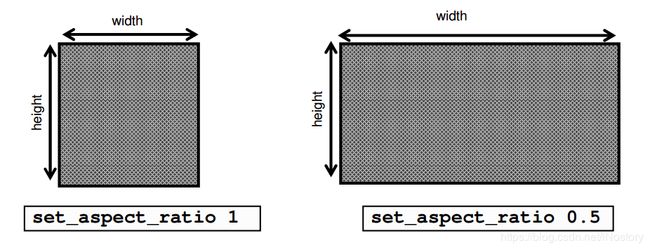
Utilization(利用率)决定了cell的密集程度,提高利用率将减少core大小,默认利用率为0.6

27、DC Topographical mode如何读入设计的实际物理布局信息?
1、 source PhysConstr.tcl
2、 extract_physical_constraints
28、为什么用于综合的verilog不建议使用for循环?
DC无法优化for循环的逻辑,只是单纯进行展开和复制,这可能降低电路的面积和性能
29、Milkyway库中的“Layout” vs. “Abstract” 视图有什么不同?
Milkyway库中包含相应的Abstract视图和 Layout视图, Abstract视图用于Place & Route减少工具处理的数据量。

Abstract视图不包含底层器件细节,仅包含以下内容:
- cell的轮廓(placement工具将每个cell放置在core中的site上。 Placement工具只需要知道的是cell的大小和形状(轮廓)。)
- 引脚位置和层(引脚通常是金属连接的区域。routing工具使用这些引脚位置来布线
- Metal blockages(cell中某些不能布线的金属层区域,因为这些区域已经被该cell使用。上面的示例布局太简单,不需要Metal blockages。 Metal blockages更常见于IP宏模块
30、针对上图,分别使用report_timing、report_timing -max_paths 2、report_timing -nworst 2 -max_paths 2会输出哪些slack ?

report_timing: 由于4条路径都属于同一path group,因此report_timing只会报出一条路径,即时序最差的路径(Slack =-0.3)
report_timing -max_paths 2在每个endpoint都会报出一个最差的slack ,即(Slack = -0.3、Slack = -0.15)
report_timing -max_paths 2 -nworst 2在每个endpoint允许报出两个最差的slack,即(Slack = -0.3、Slack = -0.25)
31、分析上述时序报告,该进行什么样的优化操作?

请注意,相对于12.5ns的时钟周期,input delay为8.4 ns - 几乎为70%!
实际上,该值要小得多,可以考虑将input delay减少到更合理的数字。
32、如何生成上图所示的时钟,假设触发器的setup为0.03ns,Tmax最大允许延时为多大?

create_clock –period 1.6 –waveform {0 0.4 0.6 1.4 } –name My_CLK [get_ports Clk]
Tmax = 0.6 - 0.4 – 0.03 = 0.17ns
33、怎样理解上述原理图和约束?

指定外部逻辑(JANE’s_DESIGN)使用的时间,然后Design Compiler计算内部逻辑(MY_DESIGN)允许的时间。
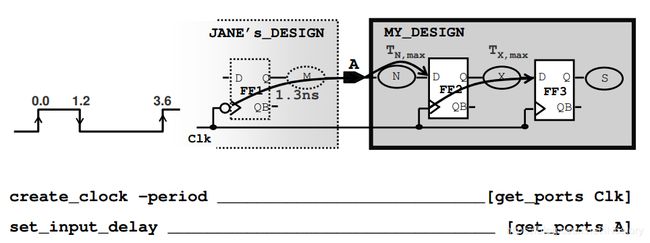
如何约束上述设计?如果FF2和FF3的setup要求为0.2 ns:
最大延迟TNmax =
最大延迟TXmax =
create_clock –period 3.6 –waveform {0.0 1.2} [get_ports Clk]
set_input_delay –max 1.3 –clock Clk –clock_fall [get_ports A]
Tn, max = 3.6 – 1.2 – 1.3 - 0.2 = 0.9ns
Tx, max = 3.6 – 0.2 = 3.4ns
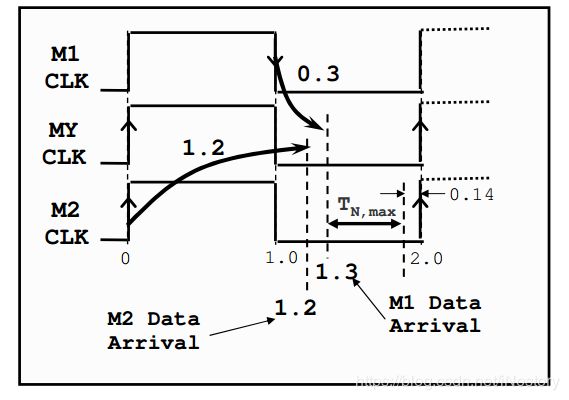
34、如何约束上图多输入路径?假设触发器setup要求为0.14ns,两条路径中哪一条更加严格?
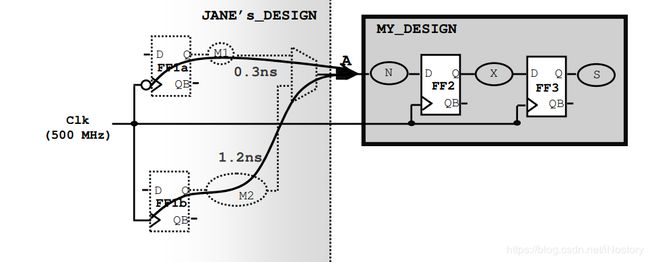
create_clock -period 2 [get_ports Clk]
set_input_delay -max 0.3 –clock Clk –clock_fall [get_ports A]
set_input_delay -max 1.2 –clock Clk –add_delay [get_ports A]
M1:TNmax = 2 – 1 – 0.3 – 0.14 = 0.56ns
M2:TNmax = 2 – 1.2 – 0.14 = 0.66 ns
35、如何约束上图多输出路径?假设触发器setup要求为0.1ns,两条路径中哪一条更加严格?
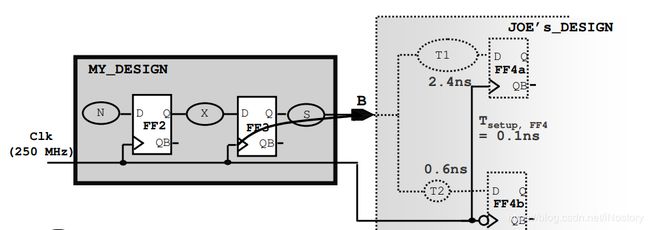

create_clock -period 4 [get_ports Clk]
set_output_delay –max 2.5 –clock Clk [get_ports B]
set_output_delay –max 0.7 –clock Clk - clock_fall –add_delay [get_ports B]
T1:TSmax = 4 – 2.5 = 1.5ns
T2:TSmax = 2 – 0.7 = 1.3 ns
36、用什么命令来设置设计驱动和负载约束?
set_driving_cell 、set_load
37、如何约束上述包含异步时钟的设计?

如果设计中的所有时钟都是异步的,可以使用以下脚本:

38、上述设计,时钟周期为10 ns。 加法器需要近6个时钟周期。经过六个时钟周期使能触发器。如何不施加多周期约束,会发生什么?

Design Compiler默认所有路径都是单周期路径。不施加多周期约束,工具会尽量让64bit加法器满足10ns约束!
39、Design Compiler综合过程中,上述命令的用处是?

单时钟设计,因此所有路径都在同一path group中。在I/O上的非常糟糕的约束可能影响设计最后的综合效果。 我们可以自定义path group,使得每个path group的WNS path都能够得到优化,不至于其中一个WNS的path阻碍另一个path group的优化。


report_timing也会分别报告每个path group的时序
40、group path中的 –weight选项有什么实际用处?
Design Compiler以降低cost function为优化方向,–weight用于给特定path group设置优先级或权重
例如:path group 1:
slack =-2ns,weight=5,则cost function = 10
path group 2:
slack =-3ns,weight=1,则cost function = 3.Design Compiler优化的方向是降低两个path group的cost function之和
41、group path中的 –critical选项有什么实际用处?

–critical选项用于优化 critical range范围内的路径,critical range不应超过时钟周期的10%。优化次关键路径可能有助于关键路径。
默认情况下,所有路径的critical range均为零。
42、下列关于DesignWare库的描述正确的是?
a、compile_ultra之前需要额外设置库变量
b、推断综合各种各样的算术和关系运算符
c、推断综合各种各样的标准IP,例如 FIFO,移位寄存器,分频器
d、以上都是
B. compile_ultra自动设置库变量; 非算术/关系IP不能由DC推断,它们必须在RTL代码中实例化
43、下列关于optimize_registers的描述正确的是?
a、拆分/合并寄存器 - 不优化组合逻辑
b、可以增加pipeline中的寄存器级数
c、可能会增加违规,以减少寄存器数量
d、可能生成更快和更小的流水线设计
D. optimize_registers:不改变寄存器级数; 可能会增加
寄存器数量; 将利用正slack以减少寄存器数量; 将执行增量编译,以进一步优化组合逻辑
44、通过增加Design Compiler delay优化的的优先级将不会修复任何逻辑DRC违规 - True or False?
False Design Compiler将修复逻辑DRC违规,只要不增加负slack
45、在单时钟设计中,默认情况下,Design Compiler不会自动创建任何path group - True or False?
False: Design Compiler为时钟创建至少一个path group。 如果有任何不受约束的路径,
这些路径会被分组为名为default的path group
46、默认情况下,path group内的优化会停止在关键路径的优化上 - True or False?
True 当关键路径无法进一步优化时,、默认情况下,次关键路径不会
优化。 Design Compiler进入下一个path group的优化。
47、为什么建议优化次关键路径?
通过优化次关键路径,可能能够改善相关的关键路径,最终会减少违规路径,更容易通过Place&Route物理设计工具来修复
48、默认情况下被忽略优化的次关键路径如何能够得到优化
a)将它们放在自己的path group中
b)将critical range应用于create_clock
c)将weight应用于其path group
d)以上所有
A. critical range适用于path group,而不是时钟约束;
应用weight没有指示Design Compiler来优化否则被忽略的路径 - 它只是对已经考虑优化的路径施加更多的优化权重
49、通过将-weight选项应用于path group,它可能会恶化另一条路径上WNS - 对错吗?True or False?
True,如果Design Compiler可以降低整体的cost function的话
50、Topographical mode相比WLM模式,通常提供更好的速度/面积结果 - True or False?
False。 Topographical mode导致与实际布局更好的时序相关性,不一定是更好的速度和/或面积结果。
51、在Topographical mode中包括物理约束
a)获得更好的速度/面积优化
b)生成一个ready for clock tree synthesis的设计
c)是可选的,但建议用,以提高与实际物理布局更好的时序相关性
d)以上所有
C.虽然Topographical mode确实执行了placement引擎,但这仅适用于
时序计算的目的。只有能够保存网表,用于Place&Route物理设计工具。
52、综合后,已经完成映射的网表为什么不能够包含assign语句,assign语句可能是由什么引起的?
布局工具可能无法处理Verilog网表中assign语句
网表中assign语句可能是由多端口网络和三态网络导致
53、Design Compiler怎么fix多端口网络导致的网表中含有的assign语句问题?

确保最终网表不包含assign语句,在综合时,分隔多端口网络:


54、Design Compiler怎么fix三态网络导致的网表中含有的assign语句问题?
Design Compiler使用assign语句描述三态网络,我们需要将三态网络声明转换为wire声明

欢迎关注微信公众号 “数字芯片实验室”