linux查看日志的几种方法
作为开发项目出了bug想要最快速定位到问题所在,查看日志是最好不过的了~(当然,也要习惯在业务关键点设置日志).
最常用查看日志方法:
·实时日志:tail -f XXX.log
·搜索关键字附近日志:cat -n filename | grep "关键字"
下面详细看下⬇⬇⬇:
1.查看日志常用命令(查看文件命令)
tail:
-n 是显示行号;相当于nl命令;例子如下:
tail -100f test.log 实时监控100行日志
tail -n 10 test.log 查询日志尾部最后10行的日志;
tail -n +10 test.log 查询10行之后的所有日志;
head:
跟tail是相反的,tail是看后多少行日志,而head是查看日志文件的头多少行,例子如下:
head -n 10 test.log 查询日志文件中的头10行日志;
head -n -10 test.log 查询日志文件除了最后10行的其他所有日志;
cat:
tac是倒序查看,是cat单词反写;例子如下:
cat -n test.log |grep "debug" 查询关键字的日志(常用!~)
vim:
1、进入vim编辑模式:vim filename
2、输入“/关键字”,按enter键查找
3、查找下一个,按“n”即可
退出:按ESC键后,接着再输入:号时,vi会在屏幕的最下方等待我们输入命令
wq! 保存退出
q! 不保存退出
列出几种常见的应用场景⬇⬇⬇:
查看日志应用场景一:按行号查看:过滤出关键字附近的日志
(1) cat -n test.log |grep "debug" 得到关键日志的行号
(2) cat -n test.log |tail -n +92|head -n 20 选择关键字所在的中间一行. 然后查看这个关键字前10行和后10行的日志:
tail -n +92表示查询92行之后的日志
head -n 20 则表示在前面的查询结果里再查前20条记录
查看日志应用场景二:根据日期查询日志
(1) sed -n '/2014-12-17 16:17:20/,/2014-12-17 16:17:36/p' test.log
特别说明:
上面的两个日期必须是日志中打印出来的日志,否则无效
先 grep '2014-12-17 16:17:20' test.log 来确定日志中是否有该时间点
查看日志应用场景三:日志内容特别多,打印在屏幕上不方便查看,分页/保存文件查看
(1)使用more和less命令,
如: cat -n test.log |grep "debug" |more 这样就分页打印了,通过点击空格键翻页
(2)使用 >xxx.txt 将其保存到文件中,到时可以拉下这个文件分析
如:cat -n test.log |grep "debug" >debug.txt
2.linux查看进程占用cpu、内存
top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器
内容解释:
- PID:进程的ID
- USER:进程所有者
- PR:进程的优先级别,越小越优先被执行
- NInice:值
- VIRT:进程占用的虚拟内存
- RES:进程占用的物理内存
- SHR:进程使用的共享内存
- S:进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数
- %CPU:进程占用CPU的使用率
- %MEM:进程使用的物理内存和总内存的百分比
- TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。
- COMMAND:进程启动命令名称
常用的命令:
- P:按%CPU使用率排行
- T:按TIME+排行
- M:按%MEM排行

内存
1) 消耗内存前10排序的进程
ps aux | sort -k4nr |head -n 10
2) 查看内存占用 排序
top
然后按
M
3) 查看swap
free -h
或者
cat /proc/swaps
3) 查看某个程序的内存占用
获取程序pid
lsof -i:3306
或者
ps -aux | grep mysqld
假如我获取的mysql的pid为3779
那么获取内存使用情况
top -p 3779
CPU
消耗CPU前10排序的进程
ps命令查看CPU状态
ps aux | sort -k3nr |head -n 10
查看CPU占用 排序
top
然后按
P
IO
每隔1s查询一次 共查询10次
iostat这个命令主要用来查看io使用情况,也可以来查看cpu,个人感觉不常用。
iostat 1 10
路由信息
查看主机路由信息
netstat -rn
free命令
free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。在Linux系统监控的工具中,free命令是最经常使用的命令之一。
free [-k] # 以 kb 为单位显示内存使用状况
free -g # 以 G 为单位显示内存使用状况
free -m # 以 M 为单位显示内存使用状况
free -t # 以总和的形式显示内存的使用信息
free -s 1 # 每一秒显示内存使用情况
磁盘和内存的区别与联系:
(磁盘--也叫硬盘--或是U盘--或是移动硬盘)
1、硬盘与内存都是存储器,一个是内部,一个是外部。
2、硬盘与内存的区别是很大的,这里只谈最主要的三点:
1)内存是计算机的工作场所,硬盘用来存放暂时不用的信息;
2)内存是半导体材料制作,硬盘是磁性材料制作;
3)内存中的信息会随掉电而丢失,硬盘中的信息可以长久保存。
3、内存与硬盘的联系也非常密切:
硬盘上的信息永远是暂时不用的,要用请装入内存!
CPU与硬盘不发生直接的数据交换,CPU只是通过控制信号指挥硬盘工作,硬盘上的信息只有在装入内存后才能被处理。
4、计算机的启动过程就是一个从硬盘上把最常用信息装入内存的过程。
5、硬盘则决定你的电脑可以装下多少东西,内存则决定你的电脑开机后一次最多可以运行多少程序(如手机运行内存)。
3.使用ps命令监控系统进程
ps命令(Process Status)用于显示当前进程的状态。
ps命令有两种不同风格的语法规则:
- BSD形式,BSD形式的语法的选项前没有破折号,如:ps aux
- UNIX/LINUX形式,Linux形式的语法的选项前有破折号,如:ps -ef
在Linux系统上混合这两种语法是可以的。比如 "ps ax -f"。这里主要讨论UNIX形式语法。
注意:"ps aux"不等同于"ps -aux"。比如"-u"用于显示用户的进程,但是"u"意味着显示具体信息。
使用 ps --help 查询参数帮助说明:
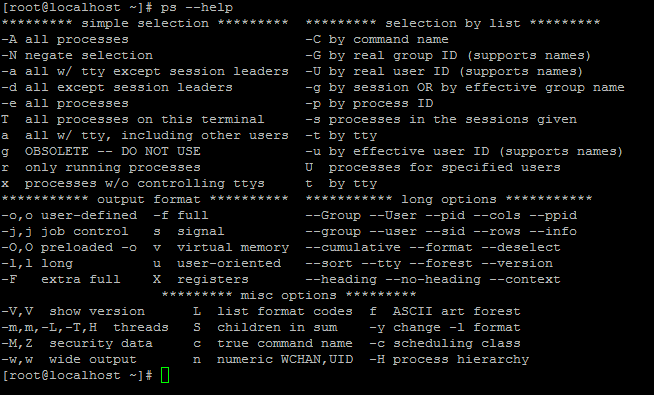
a:显示终端中包括其它用户的所有进程。
x:显示无控制终端的进程。
r:显示当前终端的进程。
c:显示进程的真实名称。
e:显示环境变量。
f: 显示程序间的关系。
T:显示当前终端的所有程序
u: 指定用户的所有进程例:查看系统中的每个进程。
命令:ps -A
例:列出目前所有的正在内存当中的程序。
命令:ps aux
例:显示所有进程信息,连同命令行。
命令:ps -ef
例:ps 与grep 常用组合用法,查找特定进程。
命令:ps -ef |grep ssh
例:显示指定用户进程。
命令:ps -u root
例:按内存占用情况对进程排序
命令:ps auxw --sort=rss
例:在进行系统维护时,如果CPU负载突然增加,而又不知道是哪一个进程造成的
命令:ps auxw --sort=%cpu
使用pstree命令监控系统进程
该命令显示当前运行的所有进程及其相关的子进程,以树的格式输出。
例:显示当前所有进程的进程号和进程ID。
命令:pstree -p
例:显示所有进程的所有详细信息,遇到相同的进程名可以压缩显示。
命令:pstree -a
使用top命令监控系统进程
top命令可以动态管理监控linux进程,非常类似于Windows任务管理器。top命令是一个功能十分强大的监控系统的工具,对于系统管理员而言尤其重要。但是,它的缺点是会消耗一定的系统资源。
例:设置top命令10秒刷新一次。
命令:top -d 10
例:显示程序及其完整相关信息
命令:top -c
例:设定监控信息的更新次数。如设定系统任务信息更新5次后结束top命令,在命令行提示符下输入:
命令:top -n 5
进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的。可通过键盘指令来改变排序字段,比如想监控哪个进程占用MEM最多,我一般的使用方法如下:
1. 敲击键盘b(打开/关闭加亮效果),top的视图变化如下:
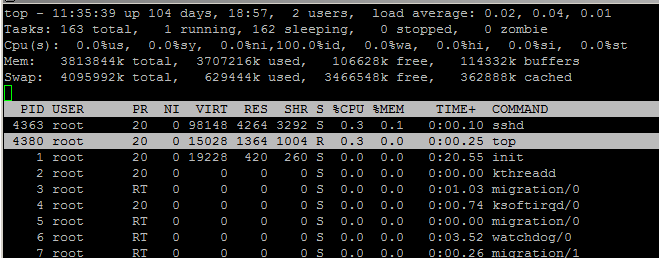
进程id为4380的top进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击y键关闭或打开运行态进程的加亮效果。
2. 敲击键盘x(打开/关闭排序列的加亮效果),top的视图变化如下:

可以看到,top默认的排序列是%CPU。
3. 通过shift + >或shift + <可以向右或左改变排序列,下图是按一次shift + >的效果图:

视图现在已经按照%MEM来排序了。
使用lsof命令监控系统进程
lsof(list open files)是一个列出当前系统打开文件的工具。
在Linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。
如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。因为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此通过lsof工具能够查看这个列表对系统监测以及排错将是很有帮助的。
例:查看谁正在使用某个文件,也就是说查找某个文件相关的进程。
命令:lsof /bin/bash
例:列出某个用户打开的文件信息。
命令:lsof -u username
例:列出某个程序进程所打开的文件信息。
命令:lsof -c mysql
说明:-c 选项将会列出所有以mysql这个进程开头的程序的文件,其实也可以写成 lsof | grep mysql
例:列出多个进程多个打开的文件信息。
命令:lsof -c mysql -c apache
例:列出除了某个用户外的被打开的文件信息
命令:lsof -u ^root
说明:^这个符号在用户名之前,将会把是root用户打开的进程不让显示。
例:列出多个进程号对应的文件信息。
命令:lsof -p 1,2,3
例:列出除了某个进程号,其他进程号所打开的文件信息。
命令:lsof -p ^1
例:列出所有的网络连接。
命令:lsof -i
例:列出所有tcp 网络连接信息。
命令:lsof -i tcp
例:列出所有udp网络连接信息。
命令:lsof -i udp
例:列出谁在使用某个端口。
命令:lsof -i :3306
结束进程
kill命令
例:查询信号

说明:
只有第9种信号(SIGKILL)才可以无条件终止进程,其他信号进程都有权利忽略。 下面是常用的信号:

HUP 1 终端断线 INT 2 中断(同 Ctrl + C) QUIT 3 退出(同 Ctrl + \) TERM 15 终止 KILL 9 强制终止 CONT 18 继续(与STOP相反, fg/bg命令) STOP 19 暂停(同 Ctrl + Z)
例:到指定信号的数值。

例:先用ps查找进程,然后用kill杀掉
命令:kill 3268
例:强制终止进程
命令:kill –9 3268
说明:这种方法应该尽量少用。
例:杀死指定用户所有进程
命令:
kill -9 $(ps -ef | grep peidalinux)
kill -u peidalinux
kill结束进程有些进程是无法杀死的。关键进程是无法结束的。比如bash的进程。
init进程是无法被终止,或者说是不允。init是Linux系统操作中不可缺少的程序之一。所谓的init进程,它是一个由内核启动的用户级进程。内核自行启动(已经被载入内存,开始运行,并已初始化 所有的设备驱动程序和数据结构等)之后,就通过启动一个用户级程序init的方式,完成引导进程。所以,init始终是第一个进程(其进程编号始终为 1)。 其它所有进程都是init进程的子孙。init进程是不可杀的!
killall命令
该命令用于结束指定名字的进程及其所有子进程。
例:结束svn服务器的进程
![]()
若需要强制结束进程,与kill命令相似,可以使用 -9 ,例:killall -9 cpusd
nice命令
调整程序运行的优先级。
nice [-n 数字] command
例:启动vi程序,同时提升其优先级。

查看网络端口占用情况(重要)
1 查看端口使用情况
netstat -tunlp | grep 端口
显示情况

占用端口的进程PID是18365
2 查看进程状况
ps -ef | grep 18365
显示情况

前面显示的是关联进程,后面显示的是程序地址
Linux写sql去查询
服务端命令SQL
在数据库系统中,SQL语句不区分大小写(建议用大写)
SQL语句可单行或多行书写,以“;”结尾
关键词不能跨多行或简写
用空格和缩进来提高语句的可读性
子句通常位于独立行,便于编辑,提高可读性
注释:
SQL标准:
/*注释内容*/ 多行注释
-- 注释内容 单行注释,注意有空格
MySQL注释:
#
SQL优化
查询时,能不要*就不用*,尽量写全字段名
大部分情况连接效率远大于子查询
多表连接时,尽量小表驱动大表,即小表 join 大表
在千万级分页时使用limit
对于经常使用的查询,可以开启缓存
多使用explain和profile分析查询语句
查看慢查询日志,找出执行时间长的sql语句优化
sql查询:单表查询和多表查询
两张表合并:横向合并、纵向合并
纵向合并:两张表挑出相同的字段进行合并(注意顺序)
范例
SQL查询范例
1、给表的字段名添加别名 select stuid as 学生编号,name 姓名,gender 性别 from students;
2、查询年龄大于40的 select * from students where age >40;
3、查找年龄大于20小于40的 select * from students where age < 40 and age > 20; select * from students where age between 20 and 40;(这种是包含)
4、查询以姓名以X开头的 select * from students where name like 'x%';
5、查找字段中为空值得信息 select * from students where classid is null;
6、查找字段值不为空得信息 select * from students where classid is not null;
7、查找报1,2,6班得学生信息 select * from students where classid in (1,2,6);
8、查找年龄,并去掉重复得年龄 select distinct age from students;
9、查询年龄,去掉重复并排序 select distinct age from students order by age;(默认正序) select distinct age from students order by age desc;(倒叙)
10、统计students表总共有多少行 select count(*) from students;
11、统计age年龄的总和 select sum(age) from students;
12、统计年龄最大的 select max(age) from students;
13、统计男女平均年龄 select gender,avg(age) from students group by gender;
14、分别统计每班的女生男生平均成绩(gender性别classid班级age成绩) select gender,classid,avg(age) from students group by gender, classid;
15、基于上条再统计女生的最大年龄 select gender,max(age) from students group by gender having gender='f'; 备注:分完组后再条件用having不能用where
16、按照课程统计没课考试最好的成绩 select courseid,max(score) as 最好成绩 from scores group by courseid;
17、取排序的前3名 select age from students order by age desc limit 3;
18、基于排序跳过2个显示3个 select age from students order by age desc limit 2,3;
多表
| 01 02 03 04 05 |
|
子查询:
| 01 02 |
|
交叉链接
| 01 02 |
|
内连接
| 01 02 03 |
|
左外链接
| 01 02 03 |
|
有这样一个表emp
公司人员信息,即对应的领导--(leaderid领导编号)
| id | name | leaderid |
| 1 | xiaoming | null |
| 2 | wanger | 1 |
| 3 | zhangsan | 2 |
| 4 | lisi | 3 |
现在有这样一个需求,查询每个人员对应的领导是谁
把emp表当作两张表来处理,自链接
|
|
|