为什么ArrayBlockingQueue不使用LinkedBlockingQueue类似的双锁实现?
为什么ArrayBlockingQueue不使用LinkedBlockingQueue类似的双锁实现?在讨论这个问题之前,我们先来回顾下BlockingQueue的这两个实现类。我比较认同“程序等于数据结构加算法”的这一说法,对于面向对象设计的Java语言而言,类的字段对应数据结构,方法对应算法,所以从关键属性和方法就可以看出一个Java类的设计思路。先放上类图,只列出关键属性和方法。
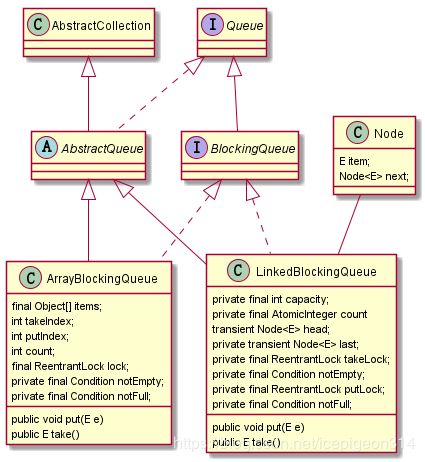
1.ArrayBlockingQueue,底层用数组存储数据,属于有界队列,初始化时必须指定队列大小,count记录当前队列元素个数,takeIndex和putIndex分别记录出队和入队的数组下标边界,都在[0,items.length-1]范围内循环使用,同时满足0<=count<=items.length。在提供的阻塞方法put/take中,共用一个Lock实例,分别在绑定的不同的Condition实例处阻塞,如put在队列满时调用notFull.await(),take在队列空时调用notEmpty.await(),源码比较容易看懂,下面贴出put和enqueue方法的源码。
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
} private void enqueue(E x) {
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}2.LinkedBlockingQueue,底层用单向链表存储数据,可以用作有界队列或者无界队列,默认无参构造函数的容量为Integer.MAX_VALUE。上面类图中的各个属性也比较好懂,不再叙述。从类图中可以看到,LinkedBlockingQueue使用了takeLock和putLock两把锁,分别用于阻塞队列的读写线程,也就是说,读线程和写线程可以同时运行,在多线程高并发场景,应该可以有更高的吞吐量,性能比单锁更高。
那么问题来了,既然LinkedBlockingQueue兄弟用双锁实现,而且性能更好,为什么ArrayBlockingQueue不使用双锁实现呢?心中产生了这个问题之后,我首先想到的是去网上搜搜别人的见解,最终我没有得到完全令人信服的答案,但至少我知道不仅仅我一个人心中有这样的疑问。相关讨论的链接:
a.The reason why they didn't used it, is mainly because of the complexity in implementation especially iterators and trade off between complexity and performance gain was not that lucrative.
https://stackoverflow.com/questions/11015571/arrayblockingqueue-uses-a-single-lock-for-insertion-and-removal-but-linkedblocki
http://jsr166-concurrency.10961.n7.nabble.com/ArrayBlockingQueue-concurrent-put-and-take-tc1306.html
b.It may be that Doug Lea didn't feel that Java needed to support 2 different BlockingQueues that differed only in their allocation scheme.
https://stackoverflow.com/questions/50739951/what-is-the-reason-to-implement-arrayblockingqueue-with-one-lock-on-tail-and-hea
我个人还是偏向于第二种答案的,从根源上说,写代码的作者决定了设计思路。
针对这个问题,我也做了自己的一些分析,主要分为两步:
1、ABQ是否可以用双锁实现?
为了简化模型,我把ABQ的继承父类和实现接口全部干掉,只保留核心方法put/take,然后将count修改为原子类的变量,将单锁改造成双锁。

简化之后,改造还是非常简单的,事实证明双锁实现Array存储的BlockingQueue是没有问题的。
2、ABQ完全改造成双锁实现是否存在实现困难?改造后性能会有明显提升吗?
a.双锁改造,我的做法是将ArrayBlockingQueue完全复制过来,然后先按步骤1的做法设计双锁,然后将所有受影响的地方做相应的代码改动,同时在加锁的所有地方分析是否要上双锁还是只需上某一把锁。实际coding下来,应该是没有困难的,当然我是在已经实现的ArrayBlockingQueue代码基础上去做部分修改。
b.改造后分别用MyABQ、ArrayBlockingQueue、LinkedBlockingQueue做多线程读写测试,测试环境4核CPU、8G内存、64位window7系统,写线程80个,读线程10个,保证读写的总数据量差额在队列长度内,每种类型测试10次,测试结果如下:
类型\平均用时(ms)
| MyABQ | 715.4 |
| ArrayBlockingQueue | 19471.3 |
| LinkedBlockingQueue | 188.3 |
事实证明,双锁改造后的ABQ性能有明显提升。下面贴出我的测试代码:
public static long testBQ(String queueType) {
final CountDownLatch latch = new CountDownLatch(1);
int threadNum = 80;
int size = threadNum/8 + 2;
int totalThreadNum = threadNum + threadNum / 8;
final BlockingQueue myQueue;
if ("MyABQ".equals(queueType)) {
myQueue = new MyABQ(size);
} else if("ArrayBlockingQueue".equals(queueType)) {
myQueue = new ArrayBlockingQueue(size);
} else {
myQueue = new LinkedBlockingQueue();
}
final AtomicInteger i = new AtomicInteger(0);
final int innerLoop = 10000;
final CountDownLatch latch2 = new CountDownLatch(totalThreadNum);
long timeBefore = System.currentTimeMillis();
for (int j = 0; j < threadNum; j++) {
Thread t1 = new Thread(() -> {
try {
latch.await();
for (int k = 0; k < innerLoop; k++) {
myQueue.put("" + (i.getAndIncrement()));
}
latch2.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
}
for (int j = 0; j < threadNum/8; j++) {
Thread t2 = new Thread(() -> {
try {
latch.await();
for (int k = 0; k < 8*innerLoop-1; k++) {
myQueue.take();
// System.out.print(myQueue.take() + " ");
}
latch2.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t2.start();
}
latch.countDown();
try {
latch2.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("");
long ret = System.currentTimeMillis() - timeBefore;
// System.out.println("\nusing time(ms): " + ret);
return ret;
}