tidyverse —— tidyr包

野菜团子,R语言中文社区专栏作者
博客:https://ask.hellobi.com/blog/esperanca
tidyr包,tidyverse工具箱中的改锥和锤子,哪儿不顺眼修哪里,犀利得好比找茬儿的老板,专注把数据在长和宽的形态中互转,功能类似reshape2包,本篇顺带也回顾一下reshape2包。
1. reshape2包
1.1 melt函数
以airquality数据为例,先把变量名全改成小写,方便之后的处理
names(airquality) <- tolower(names(airquality))
melt函数用于宽数据转长数据,语法如下
melt(data, id.vars, measure.vars, variable.name = "variable", ..., na.rm = FALSE, value.name = "value", factorsAsStrings = TRUE)
第二个参数id用于指明需要保存的变量,第三个参数measure用于指明哪些变量,其名字都作为新生成的变量variable的因子,其取值作为新生成的变量value的取值。第三个参数不填的话,则默认除第二个参数指明的变量外,其余变量都作为第三个参数。举个例子
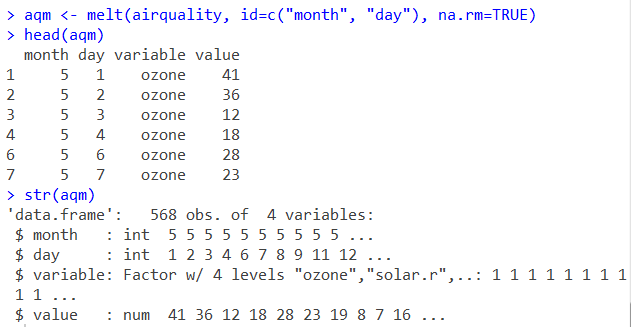
aqm <- melt(airquality, id=c("month", "day"), na.rm=TRUE)
head(aqm)
1.2 cast函数
类似Excel的透视表,有acast和dcast,前者返回向量或数组,后者返回数据框。用法如下
acast(aqm, variable ~ month, mean, subset = .(variable == "ozone"))

第三个参数为函数,指明要求的值,subset指明范围。不填函数的话,day、month和variable三个变量分别标示了得到的数组a的三个维度
a <- acast(aqm, day ~ month ~ variable)
str(a)

2. tidyr包
2.1 gather函数
gather函数的功能和melt函数对应,但是语法要友好得多,非常有范儿,Hadley出品,必属精品。举个例子

table4a原本的1999和2000两个变量被转换成了新变量year的因子,原来的值被储存在新变量cases中。
2.2 spread函数
spread函数作用和gather相反,举例如下,经过gather和spread两个函数的操作,得到的结果和原来的数据一毛一样
table4a
table4a %>%
gather(`1999`, `2000`, key = "year", value = "cases") %>%
spread(key = 'year', value = 'cases')

2.3 separate函数
恰如其名,把一列拆成多列,sep参数可以匹配正则表达式,也可以是数字,表示在该数字长度处进行拆分变量,举例如下
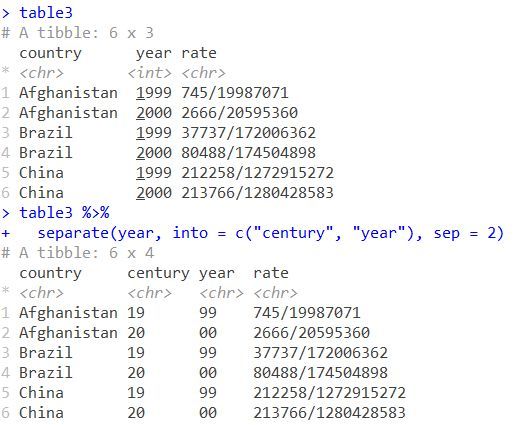
table3
table3 %>%
separate(year, into = c("century", "year"), sep = 2)
into参数表示新生成的变量的名字,默认删除被拆分的变量,如果想要不删除的话,就设置remove参数为FALSE
table3 %>%
separate(rate, into = c("cases", "population"), convert = TRUE, remove = F)

2.4 unite函数
unite函数就很简单了,separate函数的反向操作,多列合作一列。如下,经过separate和unite函数的双重作用,table3还是原来的模样

话说,距离上一篇笔记已经很久了
但是我还没有放弃这个专栏
就像我还没有放弃这么蠢的自己
在这里给自己和大家打打气
坚持下去
你就会发现
以后的困难还多着呢OT2
往期回顾:
tidyverse —— dplyr包
tidyverse —— readr包
tidyverse —— readxl包
大家都在看
2017年R语言发展报告(国内)
精心整理 | R语言中文社区历史文章合集(作者篇)
精心整理 | R语言中文社区历史文章整理(类型篇)

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法