Hive学习(上)
文章目录
- 1Hive概念
- 1.1 Hive架构
- 1.2 Hive与数据库的比较
- 1.2.1 查询语言
- 1.2.2 数据存储位置
- 1.2.3 数据更新
- 1.2.4 索引
- 1.2.5 执行
- 1.2.6 可扩展性
- 2.Hive数据类型
- 2.1 基本数据类型
- 2.2 集合数据类型
- 2.3 类型转化
- 3.DDL数据定义
- 3.1 创建数据库
- 3.2 查询数据库
- 3.2.1 显示数据库
- 3.2.2 查看数据库详情
- 3.3 修改数据库
- 3.4 删除数据库
- 3.4.1删除空数据库
- 3.5 创建表
- 3.5.1 管理表
- 3.5.2 外部表
- 3.5.3 管理表与外部表的相互转换
- 3.6 分区表
- 3.6.1 分区表的基本操作
- 3.6.2分区表注意事项
- 3.7修改表
- 3.7.1 重命名表
- 3.7.2 增加/修改/替换列信息
- 3.8 删除表
- 4 DML数据操作
- 4.1 数据导入
- 4.1.1 向Hive表中装载数据(Load)
- 4.1.2 通过查询语句向表中插入数据(Insert)
- 4.1.3 查询语句中创建表并加载数据(As select)
- 4.1.4 创建表时通过Location指定加载数据路径
- 4.1.5 Import数据到指定的Hive表中
- 4.2 数据导出
- 4.2.1 Insert导出
- 4.2.2 Hadoop 命令导出到本地
- 4.2.3 Hive shell 命令导出
- 4.2.4 Export 导出到HDFS上
- 4.2.5 Sqoop导出
- 4.3 清除表中的数据(Truncate)
1Hive概念
1.1 Hive架构
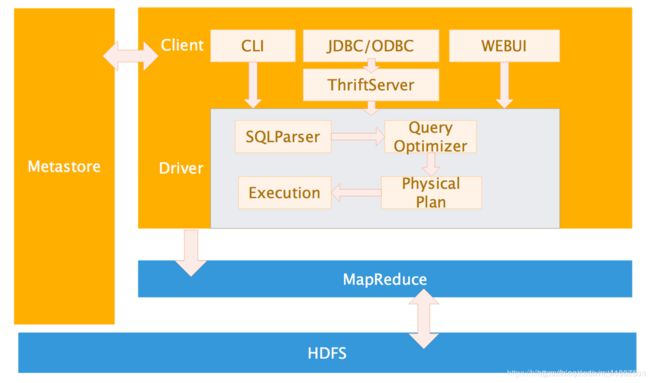
- 1.用户接口:Client(与Hive交互)
CLI(Hive shell)、JDBC/ODBC(基于 JDBC 操作提供的客户端)、WEBUI(浏览器访问Hive,例如:Cloudera提供的开源Hue项目、Qubole提供的Hive即服务方式、Karmasphere发布的商业化产品等)
-
2.跨语言服务:Thrift Server
提供JDBC/ODBC接入的能力,用于进行可扩展且跨语言服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive接口
-
3.元数据:MetaStore
所有的Hive客户端需要一个metastoreservice(元数据服务),Hive使用这个服务来存储表模式信息和其他元数据信息。
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否为外部表)、表所在的目录。
默认存储在自带的derby数据库中,缺点是不适合多用户操作,并且数据存储目录不固定。
推荐使用MySQL存储Metastore,Hive和Mysql之间通过MetaStore服务交互
可以在Mysql中查看DBS
-
4.驱动器:Driver
-
解析器(SQL Parser):将HiveQL语句转换为抽象语法树(AST)
-
编译器(Physical Plan):将AST编译生成逻辑执行计划
-
优化器(Query Optimizer):对逻辑执行计划进行优化
-
执行器(Execution):将逻辑执行计划转换成可以运行的物理计划,例如MapReduce等。
完成HQL的查询语句的词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,由MapReduce调用执行。
-
-
5.Hadoop&MapReduce
使用HDFS进行存储,利用MapReduce进行计算。
-
6.Hive数据组织
-
Hive的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区都对应HDFS上的一个目录,表数据对应HDFS对应目录下的文件。表数据对应HDFS对应目录下的文件。
-
Hive中所有的数据都存储在HDFS中,没有专门的数据存储格式,因为Hive是读模式(Schema On Read),可支持TextFile,SequenceFile,RCFile或者自定义格式等。
-
Hive中包含以下数据模型:
database:在HDFS中表现为${/user/hive/warehouse}目录下一个文件夹

table:在HDFS中表现为所属database目录下一个文件夹

external table:与table类似,但是其数据存放位置可以指定任意HDFS目录路径
partition:在HDFS中表现为table目录下的子目录
-
**bucket**:在HDFS中表现为同一个表目录或者分区目录下根据某个字段值进行hash散列之后的多个文件
**view**:与传统数据库类似,只读,基于基本表创建。
-
Hive中的表分为内部表、外部表、分区表和Bucket表
内部表与外部表的区别:
删除内部表,则会删除表元数据和数据
删除外部表,则只会删除元数据,不会删除数据
内部表和外部表的使用选择
当只需要处理hive中的数据时,则倾向于选择内部表;
当需要处理存储在HSFS上hive目录之外的数据时,则需要选择外部表,从而通过Hive转换数据并存入内部表中
分区表与分桶表的区别:
Hive数据表可以根据某些字段进行分区操作,细化数据管理,让部分查询更快。
表和分区可以进一步划分为Buckets,分桶表的原理和MapReduce编程中的HashPartitioner原理类似。
分区和分桶都是细化数据管理,分区表是手动添加分区。由于Hive是只读模式,所以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行Hash散列形成的多个文件,所以数据的准确性也提高很多。
1.2 Hive与数据库的比较
Hive采用了类似SQL的查询语言HQL,因此很容易将Hive理解为数据库。但是Hive除了和数据库拥有类似的查询语言,其他并没有相似之处。
1.2.1 查询语言
HQL类似于SQL,可以很方便的利用SQL进行开发
1.2.2 数据存储位置
Hive 是建立在Hadoop之上的,Hive中的数据都是存储在HDFS中的,而数据库可以将数据存储在块设备或者本地文件系统中。
1.2.3 数据更新
Hive是针对数据仓库应用设计的,而数据仓库是读多写少的,因此Hive中不建议对数据进行改写,所有数据都是在加载时确定好的
1.2.4 索引
Hive没有索引,所以访问延迟比较高,使得Hive不适合在线数据查询
针对大数据量的访问,由于引入了MapReduce,使得Hive可以并行访问数据,因此即使没有索引,Hive仍然具有优势。
1.2.5 执行
Hive中查询都是通过Hadoop提供的MapReduce来实现的,而数据库通常有自己的执行引擎
1.2.6 可扩展性
由于Hive是建立在Hadoop之上的,Hive的可扩展性和Hadoop的可扩展性是一致的。而数据库由于ACID语义严格限制,扩展行非常有限。
2.Hive数据类型
2.1 基本数据类型
| Hive 数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
| TINYINT | byte | 1byte 有符号整数 | 20 |
| SMALINT | short | 2 byte 有符号整数 | 20 |
| INT | int | 4 byte 有符号整数 | 20 |
| BIGINT | long | 8 byte 有符号整数 | 20 |
| BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | string | 字符系列 | ‘now is the time’ |
| TIMESTAMP | 时间类型 | ||
| BINARY | 字节数组 |
2.2 集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 某个列的数据类型是STRUCT{first STRING,last STRING};访问第一个元素可以通过字段.first来引用 | struct(‘John’,‘Doe’) |
| MAP | 键值对元组集合:‘first’->‘john’和’last’->‘Doe’;可以通过字段名[‘last’]获取最后一个元素 | map(first’,‘John’,‘last’,‘Doe’) |
| ARRAY | 数组值为[‘John’,‘Doe’],第二个元素可以通过数组名[1]进行引用 | Array(‘John’,‘Doe’) |
Hive三种复杂数据类型ARRAY、MAP和STRUCT。ARRAY、MAP与Java中的Array和Map类似;
STRUCT与C语言中的Struct类似,封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
-
实例操作
1.例如某表有如下一行,利用JSON格式表示其数据结构
{
"name":"songsong"
"friends":["bingbing","lili"] //列表 Array
"children":{ //键值 Map
"xiao song":18,
"xiaoxiao song":19
}
"address":{ //结构 struct
"street":"hui long guan"
"city":"beijing"
}
}
2.基于上述数据结构,在Hive里创建对应的表,并导入数据
创建本地测试文件
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
Hive 上创建测试表
CREATE TABLE test(
name string,
friends ARRAY<string>,
children map<string,int>,
address STRUCT<street:string,city:string>
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
将文本数据导入到测试表
hive> load data local inpath '/opt/datas/test.txt' into table test
访问三种集合列里的数据,以下分别是ARRAY,MAP,STRUCT等数据结构的访问方式
SELECT friends[1], children['xiao song'], address.city from test where name="songsong";
2.3 类型转化
Hive 不会进行类型自动转化,除非使用CAST操作
-
隐式类型转换规则如下
任何整数类型都可以隐式地转换为一个范围更广的类型,TINYINT可以转换INT,INT转换为BIGINT。
所有整数类型、FLOAT和STRING类型可以隐士地转换成DOUBLE
TINYINT、SMALLINT、INT都可以转换为FLOAT
BOOLEAN类型不可以转换为任何其他的类型
-
可以使用CAST操作显示进行数据类型转换
CAST(‘1’ AS INT)将把字符串’1’转换成整数1;强制类型转换失败,执行CAST(‘X’ AS INT),表达式返回空值NULL。
3.DDL数据定义
3.1 创建数据库
创建一个数据库
create database if not exists db_hive;
3.2 查询数据库
3.2.1 显示数据库
show databases;
3.2.2 查看数据库详情
desc database db_hive;

3.3 修改数据库
alter database db_hive set dbproperties('createtime'='20170830')

3.4 删除数据库
3.4.1删除空数据库
drop database if exists db_hive;
## 如果数据库不为空,可以采用cascade命令,强制删除
drop database db_hive cascade;
3.5 创建表
-
建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment],...)] [COMMENT table_comment] [PARTITIONED BY (col_name daya_type [COMMENT col_comment],...)] [CLUSTERED BY (col_name,col_name,...) [SORTED BY (col_name [ASC|DESC],...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [SORTED AS file_format] [LOCATION hdfs_path] -
字段解释
CREATE TABLE 创建一个指定名字的表 EXTERNAL 使用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION);Hive在创建内部表中,会将数据移动到数据仓库指定的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。 /* 删除外部表的时候,不会删除实际的数据 删除内部表的时候,元数据和数据会被一起删除 */COMMENT:为表和列添加注释 PARTTITIONED BY:创建分区表 CLUSTERED BY:创建分桶表 SORTED BY:不常用/*序列化和反序列化*/ /*这个后面可以详细了解,现在不清楚具体用途*/ ROW FORMAT() 用户在建表时可以自定义SerDe或者使用自带的SerDe。 SerDe是 serialize/Deserilize简称,目的是用于序列化和反序列化STORED AS 指定存储文件类型 常用的存储文件类型:SEQUENCEFILE(二进制序列文件) TEXTFILE(文本) RCFILE(列式存储格式文件) LOCATION:指定表在HDFS上的存储位置 LIKE 允许用户复制现有表结构,但不复制数据
3.5.1 管理表
- 默认创建的表都是管理表,有时候也被称为内部表。Hive会控制着数据的生命周期。管理表不适合与其他工具共享数据。
3.5.2 外部表
-
实例操作
/* 创建部门和员工外部表,并向表中导入数据 */ CREATE EXTERNAL table if not exists default.dept( deptno int, dname string, loc int ) row format delimited fields terminated by '\t'; CREATE EXTERNAL table if not exists default.emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) row format delimited fields terminated by '\t';## 向外部表导入数据 hive> load data local inpath '/opt/datas/files/dept.txt' into table default.dept; hive> load data local inpath '/opt/datas/files/emp.txt' into table default.emp;
查看表数据
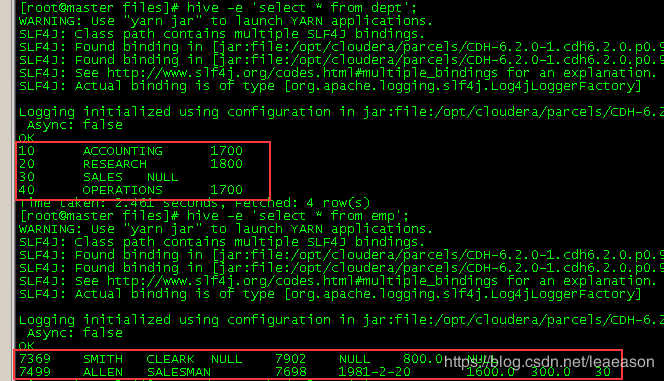
3.5.3 管理表与外部表的相互转换
## 查询表的类型
hive> desc formatted student2;
## 修改内部表student2为外部表
hive> alter table student2 set tblproperties('EXTERNAL'='TRUE');
## 修改内部表student2为外部表
hive> alter table student2 set tblproperties('EXTERNAL'='FALSE');
3.6 分区表
分区表实际上就是对应一个HDFS文件系统上的独立文件夹,该文件夹下包含了该分区下所有的数据文件。
Hive中的分区就是目录,将一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要指定的分区,从而提高查询效率。
3.6.1 分区表的基本操作
-
引入分区表(根据日期对日志进行管理)
/user/hive/warehouse/log_partition/20200619/20200619.log /user/hive/warehouse/log_partition/20200620/20200620.log /user/hive/warehouse/log_partition/20200621/20200621.log -
创建分区表语法
hive> create table if not exists dept_partition(
deptno int,
dname string,
loc string
)
partitioned by (month string)
row format delimited fields terminated by '\t';
- 加载数据到分区表中
hive> load data local inpath '/opt/datas/files/dept.txt' into table default.dept partition partition(month='202006')
hive> load data local inpath '/opt/datas/files/dept.txt' into table default.dept partition partition(month='202007')
hive> load data local inpath '/opt/datas/files/dept.txt' into table default.dept partition partition(month='202008')
分区表截图


-
查询分区表中的数据
## 单分区查询 hive> select * from dept_partition where month='202006'; ## 多分区联合查询 hive> select * from dept_partition where month='202006' union select * from dept_partition where month='202007' union select * from dept_partition where month='202008'

-
增加分区
创建单个分区
```sql
hive> alter table dept_partition add partition(month=‘202005’);
```
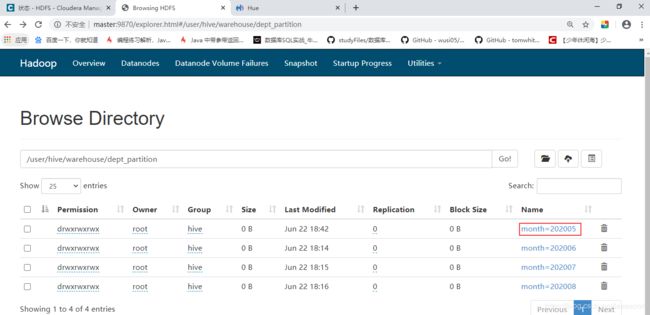
创建多个分区
hive> alter table dept_partition add partition(month='202003) partition(month='202004');

-
删除分区
hive> alter table dept_partition add partition(month='202003');
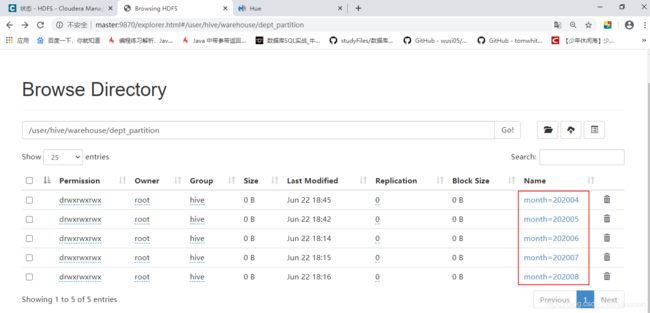
-
查看分区表中有多少分区
hive> show partitions dept_partition;
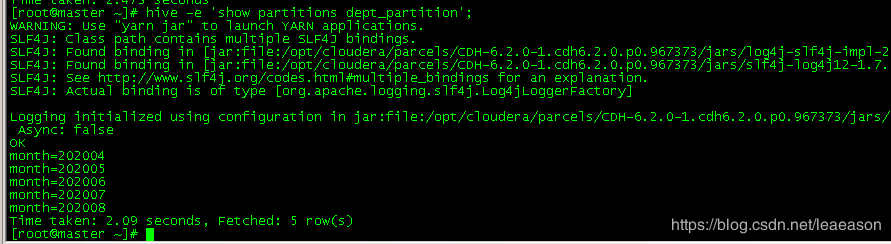
-
查看分区表结构
hive> desc formatted dept_partition;
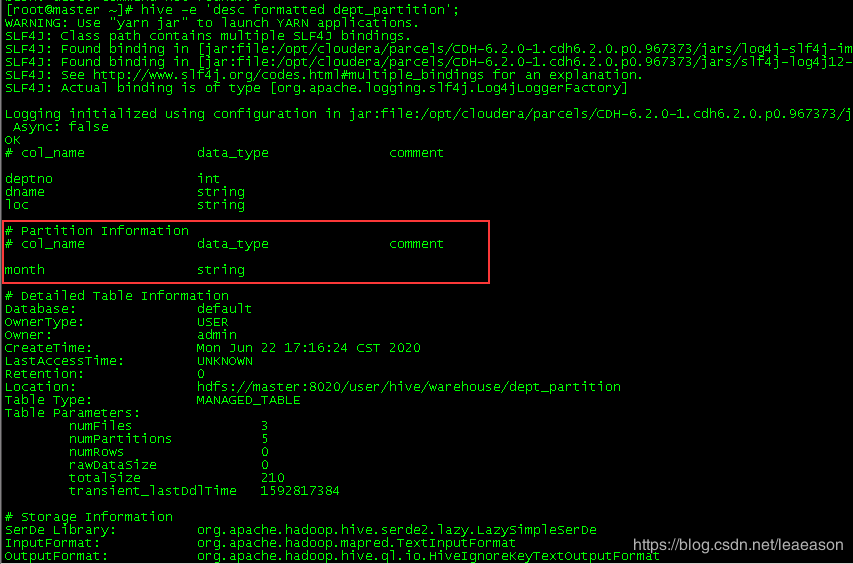
3.6.2分区表注意事项
-
创建二级分区表
hive> CREATE TABLE IF NOT EXISTS dept_partition2( deptno int, dname STRING, loc string ) PARTITIONED BY (month string,day STRING) row format delimited fields terminated by '\t';- 正常加载数据
加载数据到二级分区
hive> load data local path `/opt/datas/files/dept.txt` into table default.departition2 partition(month='202006',day='13');

查询分区数据
hive> select * from dept_partition2 where month='202006' and day='13';
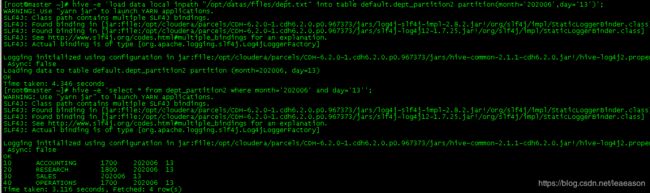
-
将数据直接上传到分区目录,让分区表和数据产生关联的三种方式
1.上传数据后修复
hive> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=202006/day=12; hive> dfs -put /opt/datas/files/dept.txt /user/hive/warehouse/dept_partition2/month=202006/day=12;

查询数据
hive> select * from dept_partition2 where month='202006' and day='12';
但是查询不到数据。
执行修复命令
hive> msck repair table dept_partition2;
再次查询数据
hive> select * from dept_partition2 where month='202006' and day='12';
2.上传数据后添加分区
上传数据
hive> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=202006/day=11
hive> dfs -put /opt/datas/files/dept.txt /user/hive/warehouse/dept_partition2/month=202006/day=11;
添加分区
hive> alter table dept_partition2 add partition(month='202006',day='11');
查询数据
hive> select * from dept_partition2 where month='202006' and day='11'
3.创建文件夹后load数据到分区(***)
3.7修改表
3.7.1 重命名表
hive> alter table dept_partition2 rename to dept_partition3;
3.7.2 增加/修改/替换列信息
查询表结构
hive> desc default.dept_partition;

添加列
hive> alter table dept_partition add columns(deptdesc string);
查询现在的表结构
hive> desc default.dept_partition;
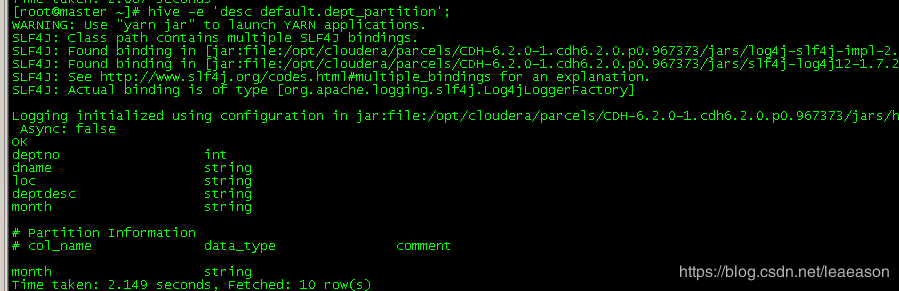
更新列
hive> alter table dept_partition change column deptdesc desc int;

替换列
hive> alter table dept_partition replace columns(deptno string,dname string,loc string);

3.8 删除表
hive> drop table dept_partition
4 DML数据操作
4.1 数据导入
4.1.1 向Hive表中装载数据(Load)
hive> load data [local] inpath '/opt/datas/files/student.txt' overwrite | into table student [partition (partcol1=val...)];
## load data:表示加载数据
## local:表示从本地加载数据到hive表,否则从HDFS加载数据到Hive
## inpath:表示加载数据的路径
## overwrite:覆盖表中已有数据,否则表示追加
## into table:表示加载到哪张表
## student:表示具体的表
## partition:表是上传到指定分区
4.1.2 通过查询语句向表中插入数据(Insert)
创建一张分区表
hive> create table student (id int,name string) partitioned by (month string)
row format delimited fields terminated by '\t';
基本插入数据
hive> insert into table student partition(month='202009') values(1,'wangwu');
基本模式插入(根据单张表查询结果)
hive> insert overwrite table student partition(month='202008')
select id,name from student where month='202009';
多插入模式(根据多张表查询结果)
hive> from student
insert overwrite table student partition(month='202007')
select id,name where month='202009'
insert overwrite table student partition(month='202006')
select id,name where month='202009'
4.1.3 查询语句中创建表并加载数据(As select)
hive> create table if not exists student3 as select id,name from student;
4.1.4 创建表时通过Location指定加载数据路径
创建表,指定在HDFS上的位置
hive> create table if not exist student5(
id int,name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student5';
上传数据到HDFS上
hive> dfs -put /opt/module/datas/student.txt /user/hive/warehouse/student5;
查询数据
hive> select * from student5;
4.1.5 Import数据到指定的Hive表中
hive> import table student2 partition(month='201709') from '/user/hive/warehouse/export/student'
4.2 数据导出
4.2.1 Insert导出
将查询的结果导出到本地
hive> insert overwrite local directory '/opt/module/datas/export/student' select * from student;
将查询结果导出到HDFS
hive> insert overwrite directory '/user/atguigu/student2'
ROW RORMATE DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
4.2.2 Hadoop 命令导出到本地
hive> dfs -get /user/hive/warehouse/student/month=202009/000000_0 /opt/module/datas/export/student3.txt;
4.2.3 Hive shell 命令导出
hive -e 'select * from default.student;' > /opt/module/datas/export/student4.txt
4.2.4 Export 导出到HDFS上
hive> export table default.student to '/user/hive/warehouse/export/student';
4.2.5 Sqoop导出
4.3 清除表中的数据(Truncate)
hive> truncate table student;