Flink部署过程(standalone模式,备忘)
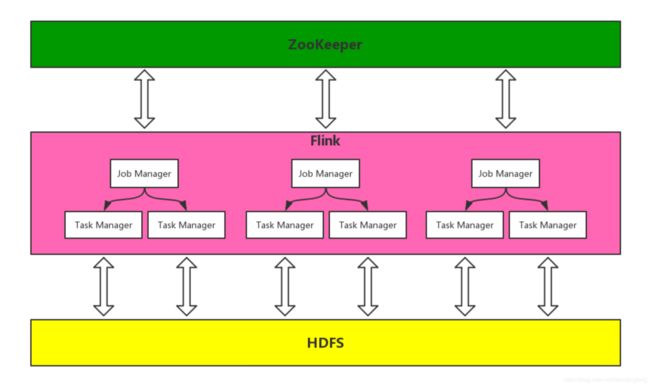
集群架构
环境
-
机器环境
- java8
- SSH
- 各模块版本
- Flink: 1.8.x
- Hadoop:2.8.x
- Zookeeper:3.4.x
部署流程
Misc
- 操作账号:user(教程中配置示例使用的是”root”)
- 操作顺序
- SSH免密登陆
- ZooKeeper部署/Hadoop部署(两者无先后顺序)
- Flink部署
- 安装包
- flink 1.8 包采用 flink-1.8.1-bin-scala_2.11.tgz
下载地址:https://adu-microcar.cdn.bcebos.com/flink-1.8.1-bin-scala_2.11.tgz - flink 1.8 需指定对应的hadoop关联依赖包:
下载地址:https://adu-microcar.cdn.bcebos.com/flink-shaded-hadoop-2-uber-2.8.3-7.0.jar - hadoop 安装包
下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
- flink 1.8 包采用 flink-1.8.1-bin-scala_2.11.tgz
JDK环境检查
机器上应该已经装好JDK,如果没装,需协调相关人员进行安装。
检查方法
# 通过这两个命令中的任何一个都可以找到java的安装位置
$ which java
$ env|grep JAVA_HOMEJAVA_HOME会在后续配置中用到
SSH免密登陆
1、生成公钥、私钥
$ ssh-keygen -t rsa
$ chmod 700 ~/.ssh
(同时修改.ssh的父目录为755)2、在各个节点上执行步骤1,并记录公钥内容
3、创建authorized_keys文件,将所有节点的公钥写到该文件
$ touch authorized_keys4、将authorized_keys文件分发至各节点~/.ssh目录下
## 分发至example01.baidu.com节点
$ scp authorized_keys [email protected]:~/.ssh
## 在example01.baidu.com上
$ chmod 600 authorized_keys5、验证(无论免密是否已经由别人安装,此步务必执行)
测试各个机器之间的免密是不是好的,这一步虽然麻烦,但是非常有必要,能避免后续踩坑。
经常遇到免密配置之后,第一次连接依然需要确认的情况。
尤其注意,本机到本机的免密也需要验证一下。
$ ssh user@node2
$ exit
$ ssh user@node3
$ exitZooKeeper
Flink Job Manager存在单点问题,使用ZooKeeper实现Job Manager HA。
3节点的ZooKeeper集群完全可以满足生产环境的要求,在机器允许的情况下,建议部署5个节点以获取更高的可靠 性。5节点集群可以随时下线其中一个节点进行维护而不影响生产环境。
此步骤暂未验证,Zookeeper复用了已有服务。
1、DownLoad Zookeeper
2、配置conf/zoo.cfg文件,示例如下
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/flink-example/zookeeper-3.4.14/data
clientPort=2181
server.1=example01.baidu.com:2888:3888
server.2=example02.baidu.com:2888:3888
server.3=example03.baidu.com:2888:3888
server.4=example04.baidu.com:2888:3888
server.5=example05.baidu.com:2888:38883、在{dataDir}目录下创建myid文件,该文件内容只有一行,一个数字,为该节点对应的server.{id}中的 id。
example01.baidu.com节点myid文件示例如下:
14、在各节点上重复步骤1~3
5、启动服务
java -cp zookeeper-3.4.14.jar:lib/slf4j-api-1.7.25.jar:lib/slf4j-log4j12-1.7.25.jar:lib/log4j-1.2.17.ja r:conf org.apache.zookeeper.server.quorum.QuorumPeerMain conf/zoo.cfg6、验证(非必须)
$ bin/zkCli.sh -server 127.0.0.1:2181
Hadoop
使用HDFS作为Flink的State Backends。
1、Download Hadoop
2、配置etc/hadoop/core-site.xml
fs.defaultFS
hdfs://node2:8020
hadoop.tmp.dir
/root/software/hadoop-2.8.5/hadoop_tmp
io.file.buffer.size
4096
3、配置etc/hadoop/hdfs-site.xml
dfs.replication
3
dfs.namenode.name.dir
file:/root/software/hadoop-2.8.5/hdfs/namenode
dfs.datanode.data.dir
file:/root/software/hadoop-2.8.5/hdfs/datanode
dfs.namenode.checkpoint.dir
file:/root/software/hadoop-2.8.5/hdfs/namesecondary
dfs.http.address
node2:50070
dfs.secondary.http.address
node2:50090
dfs.webhdfs.enabled
true
dfs.permissions
false
4、配置etc/hadoop/mapred-site.xml
$ cp mapred-site.xml.template mapred-site.xml
增加如下内容
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
node2:10020
mapreduce.jobhistory.webapp.address
node2:19888
5、配置etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
node2
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.local-dirs
/root/software/hadoop-2.8.5/hadoop_tmp/yarn/local
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/root/software/hadoop-2.8.5/hadoop_tmp/logs
yarn.log.server.url
http://node2:19888/jobhistory/logs/
URL for job history server
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.resource.memory-mb
2048
yarn.scheduler.minimum-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
4096
mapreduce.map.memory.mb
2048
mapreduce.reduce.memory.mb
2048
yarn.nodemanager.resource.cpu-vcores
1
6、配置etc/hadoop/slaves。将所有worker节点都写进文件,如果只配置一个节点,就是只在这个节点上有datenode和nodeManager
node2
node37、配置etc/hadoop/hadoop-env.sh
# 搜索到JAVA_HOME,修改成线上安装的jdk路径
export JAVA_HOME=/root/software/jdk1.8.0_1318、配置etc/hadoop/yarn-env.sh
# 搜索到JAVA_HOME,修改成线上安装的jdk路径
export JAVA_HOME=/root/software/jdk1.8.0_1319、配置etc/hadooop/mapred-env.sh
# 搜索到JAVA_HOME,修改成线上安装的jdk路径
export JAVA_HOME=/root/software/jdk1.8.0_13110、然后通过scp命令将文件发送到其他所有机器
# 多机器地址保持一致
$ scp -r hadoop-2.8.5 root@node3:/root/software/11、格式化namanode(只在第一次启动集群之前操作)
$ bin/hdfs namenode -format操作完成后会发现生成了/root/software/hadoop-2.8.5/hdfs/namenode目录,下面有初始化的namenode信息。如果需要将集群数据重置,可以将下面的数据全部删除(datanode数据也删除,每个机器上都清除数据),重新格式化namenode。
12、启动dfs
$ sbin/start-dfs.sh停止dfs(不必要)
$ sbin/stop-dfs.shTest
$ bin/hdfs dfs -mkdir /aa
$ bin/hdfs dfs -ls /访问NameNode UI: http://node2:50070
13、启动yarn
$ sbin/start-yarn.sh访问Yarn UI:http://node2:8088
停止yarn
$ sbin/stop-yarn.sh14、全部启动
$ sbin/start-all.sh全部停止
$ sbin/stop-all.sh15、配置环境变量(方便使用),在/etc/profile文件中增加如下配置:
export HADOOP_HOME=root/software/hadoop-2.8.5
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
Flink
使用Standalone + HA的方式部署Flink集群。
(配置文件各机器上相同,可配置一份后分发)
1. Download Flink,解压缩。
将flink-shaded-hadoop-2-uber-2.8.3-7.0.jar包放到lib目录下。
2. 配置conf/flink-conf.yaml文件。原文件中大部分配置都被注释了,每个配置项上面都有注释说明。可以直接用下面的配置内容覆盖文件内容,并对相关内容进行修改
# jobmanager的地址,在HA模式下这个参数会被接管,配置不生效。只有在standalone模式下才会生效,如果用域名不生效,可以改成ip地址。
jobmanager.rpc.address: localhost
# jobmanager和taskmanager通信的端口
jobmanager.rpc.port: 6123
# jobmanager的堆大小
jobmanager.heap.size: 4096m
# taskmanager的堆大小
taskmanager.heap.size: 2048m
# 每个taskmanager启动的slot个数
taskmanager.numberOfTaskSlots: 3
# taskmanager启动后是否直接预分配内存,批处理模式下使用这个参数可避免动态内存扩展,但是流式计算模式下不要设置为true
taskmanager.memory.preallocate: false
# 默认并行度
parallelism.default: 1
# web页面的端口,还有个rest.port,默认也是8081,不知道是不是改了名称了,不过这么设置没有问题。不设置默认也是8081
web.port: 8081
# web页面上提交的jar包存放位置
web.upload.dir: /root/software/flink-1.8.1/data/temp
# 存放flinkjobmanager和taskmanager的进程id
env.pid.dir: /root/software/flink-1.8.1/tmp/pid
# 完成的任务保存在hdfs目录下
jobmanager.archive.fs.dir: hdfs://node2-ip/flink/completed-jobs/
historyserver.archive.fs.dir: hdfs://node2-ip/flink/history/completed-jobs/
# flink的状态数据存储
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://node2-ip/flink/checkpoints
# checkpoint在hdfs中的存储位
state.checkpoints.dir: hdfs://node2-ip/flink/checkpoint
taskmanager.tmp.dirs: /root/software/flink-1.8.1/taskmanagertmp
# 启用HA
high-availability: zookeeper
high-availability.storageDir: hdfs://node2-ip/flink/ha
high-availability.zookeeper.quorum: zk-ip:2181
high-availability.zookeeper.path.root: /flink
# The cluster-id ZooKeeper node, under which all required coordination data for a cluster is placed.
# important: customize per cluster
high-availability.cluster-id: /flink_cluster_one3. 配置conf/masters文件。配置所有的jobmanager(非HA模式下,只需要配置一个jobmanager)
node2:8081
node3:80814. 配置conf/slaves文件。
此文件直接置空,直接进行下一步。如果想理解为什么,可以看一下本步的内容。
此文件用于配置所有的taskmanager所在机器,每配置一台机器,就会在该机器上启动一个taskmanager;同一台机器可以重复配置,配置多次就会启动多个taskmanager。文件为空,则不会启动taskmanager。
node2
node3这个配置最好直接置空,不要使用。因为每次使用 bin/start-cluster.sh 的时候就会读取本配置文件,重新生成一遍taskmanager,多次执行之后会使taskmanager的个数倍增。
那么taskmanager怎么启动?很简单,继续往下看。
5. 启动集群
$ bin/start-cluster.sh此命令的效果:
根据conf/masters的配置启动jobmanager;根据conf/slaves启动taskmanager。
6. 关闭集群(非必须)
$ bin/stop-cluster.sh7. 访问web页面
http:node2:8081
可以看到已经启动的taskmanager和slot个数。如果conf/slaves已经置空,此时的界面如下
使用http://node3:8081也可以访问,是同一个集群。
8. 启动taskmanager
# 连接到要启动taskmanager的机器上
$ ssh user@node2
$ cd /root/software/flink-1.8.1
$ bin/taskmanager.sh start
# 启动10个taskmanager
$ for i in {1..3}; do /root/software/flink-1.8.1/bin/taskmanager.sh start; done
# 查看启动结果
$ ps aux|grep TaskManager|grep -v grep |wc -l这时候看web页面上,taskmanager个数和slot个数都已经发生了变化。slot个数为taskmanager个数的3倍,这是我们在conf/flink-conf.yaml中用 taskmanager.numberOfTaskSlots: 3 配置的。
9. Test
跑个demo
$ ./bin/flink run ./examples/batch/WordCount.jar
增/删资源
增/删 job manager
1. 增加 job manager 在现有flink节点上直接启动job manager即可
$ bin/jobmanager.sh start2. 移除 job manager
在job manager所在节点上停止job manager即可
$ bin/jobmanager.sh stop
# 上面的方法有可能会失效,那就进入bin目录再执行。暂不知原因。
$ cd bin
$ ./jobmanager.sh stop
增/删 task manager
1. 增加 task manager
在现有flink节点上直接启动task manager即可
$ bin/taskmanager.sh start2. 移除 task manager
在现有flink节点上直接停止task manager即可
$ bin/taskmanager.sh stop
增加节点
1. 新节点与所有zookeeper节点配置SSH免密登陆
2. 启动task manager
$ bin/taskmanager.sh start3. 将新节点添加到conf/masters文件和conf/slavers文件中
移除节点
1. 关闭 job manager
$ bin/jobmanager.sh stop2. 关闭 task manager
$ bin/taskmanager.sh stop3. 从conf/masters文件和conf/slavers文件中移除节点
保活脚本
1、保活脚本software-check-restart.sh
#!/bin/bash
export JAVA_HOME=/root/software/jdk1.8.0_131
export JRE_HOME=$JAVA_HOME/jre
declare -A namedict
namedict=(['redis']="REDIS_PROCESS_ERROR" \
['/root/software/zookeeper']="ZOOKEEPER_PROCESS_ERROR" \
['/root/software/hadoop-2.8.5']="MYSQL_PROCESS_ERROR" \
['StandaloneSessionClusterEntrypoint']="JOBMANAGER_PROCESS_ERROR" \
['TaskManagerRunner']="TASKMANAGER_PROCESS_ERROR")
disk_error_code="DISK_OVER_THRESHOLD_ERROR"
mem_error_code="MEM_OVER_THRESHOLD_ERROR"
cpu_error_code="CPU_OVER_THRESHOLD_ERROR"
local_host=`hostname --fqdn`
local_ip=`ifconfig -a | grep inet | grep -v 127.0.0.1 | grep -v inet6 | awk '{print $2}' | tr -d "addr:"`
check() {
process=$1
echo "`date` : check process $process $2"
cnt=`ps -ef | grep $process | grep -v grep | wc -l`
return $cnt
}
double_check() {
check $1
ret=$?
# echo $ret
if [ "$ret" -eq "0" ]
then
sleep 1
check $1
ret=$?
# echo $ret
fi
return $ret
}
check_and_restart() {
double_check $1
ret=$?
required_num=$2
if [ "$ret" -lt "$required_num" ]
then
echo "need start $1, use cmd: $3"
gap_num=`echo $required_num $ret | awk '{print $1-$2}'`
echo "need to start $1 for $gap_num times"
for i in `seq 1 $gap_num`;
do
eval $3
done
log_error_code=${namedict[$1]}
echo "$log_error_code"
else
echo "$1 exist"
fi
}
check_and_restart StandaloneSessionClusterEntrypoint 1 "/root/software/flink-1.8.1/bin/start-cluster.sh"
check_and_restart TaskManagerRunner 35 "/root/software/flink-1.8.1/bin/taskmanager.sh start"
# check_and_restart namenode.NameNode 1 "/root/software/hadoop-2.8.5/sbin/start-all.sh"
将文件放在/root/software/tools目录下(没有目录先创建目录)
# check_and_restart是一个function
# 第一个参数是要保活的进程关键字
# 第二个参数是该进程要保证有几个在运行,根据需要修改个数
# 第三个参数是:如果进程个数不够,应该执行什么命令进行启动。
check_and_restart StandaloneSessionClusterEntrypoint 1 "/root/software/flink-1.8.1/bin/start-cluster.sh"
check_and_restart TaskManagerRunner 35 "/root/software/flink-1.8.1/bin/taskmanager.sh start"
# check_and_restart namenode.NameNode 1 "/root/software/hadoop-2.8.5/sbin/start-all.sh"将保活脚本分发到Flink集群的所有机器上
$ scp -r /root/software/tools user@node3:/root/software/脚本发送出去之后,将主节点上的namenode.NameNode 监测打开注释。因为只有主节点上有NameNode,其他节点没有。
# 一般所有节点上都会启动jobmanager,所以这一行可以每个节点都有;如果不是,只能在/root/software/flink-1.8.1/conf/masters文件中配置了的所有机器上执行这一行
check_and_restart StandaloneSessionClusterEntrypoint 1 "/root/software/flink-1.8.1/bin/start-cluster.sh"
# Flink集群的所有节点都需要执行这一行,但是35这个数字需要根据机器情况进行调整,尽量不要超过CPU个数
check_and_restart TaskManagerRunner 35 "/root/software/flink-1.8.1/bin/taskmanager.sh start"
# 只在hadoop配置的主节点打开这一行的注释。
check_and_restart namenode.NameNode 1 "/root/software/hadoop-2.8.5/sbin/start-all.sh"2、配置crontab
* * * * * root bash /root/software/tools/software-check-restart.sh >> /root/software/tools/software-check-restart.log 2>&1