IJON: Exploring Deep State Spaces via Fuzzing
摘要–虽然目前的模糊测试(fuzzing)方法是非常有效的,但仍有许多情况下,如复杂状态机的全自动方法失败。在这种情况下,最先进的模糊化方法为人类提供了非常有限的交互和帮助模糊者的能力。更具体地说,目前的大多数方法仅限于添加字典或新的种子输入来指导模糊器。在处理复杂程序时,这些机制无法发现代码库的新部分。
在这篇文章中,我们提出了IJON,一个人类分析师可以用来引导模糊者的注释机制。与上述两种技术相比,这种方法允许基于表示程序内部状态的数据对程序的行为进行更系统的探索。因此,只要使用一个小的(通常是一行)注释,用户就可以帮助fuzzer解决以前无法解决的难题。我们扩展了各种基于AFL的模糊器,使之能够用指导提示注释目标应用程序的源代码。我们的评估表明,这种简单的注释能够解决我们所知的问题——目前没有其他的基于模糊器或符号执行的工具能够克服这些问题。例如,使用我们的扩展,fuzzer能够玩和解决超级马里奥兄弟(Super Mario Bros)之类的游戏,或者解决更复杂的模式,比如散列图查找。为了进一步展示我们注释的功能,我们使用AFL和IJON来发现新的安全问题和以前需要一个自定义的和全面的语法才能发现的问题。最后,我们证明,使用IJON和AFL,可以解决迄今为止抵制了所有全自动和人工引导的尝试的CGC数据集的许多挑战。
I. INTRODUCTION
近年来,模糊测试(fuzz testing,简称fuzzing)发现了大量的软件缺陷,这一研究领域受到了学术界[7]、[14]、[43]、[45]、[53]、[60]和实践[1]、[33]、[61]的广泛关注。因此,人们将更多的注意力放在进一步改进模糊化方法上,通常是为了实现更大的代码覆盖率并深入到给定的软件应用程序中。然而,仍然存在大量的开放挑战:即使使用象符号或混合执行这样的聪明的程序分析技术,一些约束也无法轻易克服。此外,在某些情况下,无论是模糊测试还是基于符号执行的方法,状态爆炸都会对当前的技术造成太大的阻碍。这是因为在一般情况下,根本问题(查找错误)是不可确定的。因此,我们不能期望任何单一的算法在所有被测试的目标应用程序中都能很好地执行。
基于这一观点,尽管最近在改进完全自治模糊器方面取得了重大进展,但无论使用哪种算法(例如,如果使用密码学),某些约束都将无法解决。在实践中,当前的方法很难探索复杂的状态机,其中大多数进展只能在程序状态数据的更改中观察到。由于状态数据的每次更新都是由特定的代码触发的,因此基于覆盖率的fuzzer能够独立地探索每个更新。但是,如果之前观察到了所有单独的更新,则没有任何反馈可以奖励探索不同更新组合导致的新状态。在需要特定的更新序列来发现bug的情况下,这会阻止fuzzer取得进展。类似地,基于混合执行的方法也会失败,因为更新的确切顺序(以及因此选择的精确代码路径)对于发现错误至关重要。由于混合执行将路径固定到观察到的执行路径,因此解算器不可能获得触发目标条件的输入。最后,如果状态空间太大,即使完全符号化的执行(可以自由探索不同的路径)也会失败。
我们注意到有一种趋势是使用更复杂的解决方案,它只支持最小的环境/指令集,基于符号执行来克服模糊化中的困难挑战[43]、[45]、[53]、[60]。另一方面,正如不同来源所观察到的[10]、[60]、[62],这种方法有时对复杂的应用程序的伸缩性很差。因此,与LIBFUZZER和AFL等模糊器相比,它们在工业上几乎没有用处。仅谷歌的OSS fuzz项目就使用LIBFUZZER等工具,就能够在像Chrome浏览器这样复杂的目标中发现超过27000个bug[23]。通常,看起来,建立和处理一个象征性环境的额外努力是不值得的。
在这篇文章中,我们将探讨人类如何驾驭模糊器来克服当前模糊测试的挑战。套用一句广为人知但却难以捉摸的名言:“计算机速度惊人,精确而愚蠢;人类速度惊人,不精确而聪明;它们的力量之大超乎想象。”。人类往往更善于制定高层次的战略计划,而计算机则确保战术的实施,人类不会忽视任何重要方面。这种方法通常被称为循环中的人,是软件验证中常用的概念[8]、[15]、[34]、[39]、[41]、[52]以及其他各个领域,如机器学习[17]、[59]、控制网络物理系统[47]、[49]和优化[24]、[51]。
我们的方法也是基于这样的观察,即行业中的许多模糊测试实践者在他们的模糊过程中已经使用了一个闭环反馈环[35]:首先,他们运行模糊器一段时间,然后分析得到的代码覆盖率。在这个手动分析之后,他们调整和调整模糊化过程以增加覆盖范围。提高模糊性能的常用策略包括从目标应用程序中移除具有挑战性的方面(例如校验和),更改变异策略,或者显式地添加输入样本,以解决模糊器无法自动生成的某些约束。这种方法有两个主要原因:一方面,在模糊化活动中,所有“容易”的bug(即那些可以完全自动找到的bug)都会很快找到。另一方面,根据定义,更有趣的bug是那些在现成配置中使用当前工具找不到的bug,因此需要一些手动调整。我们相信,通过帮助和指导模糊化过程,人类与模糊器的交互可以极大地提高分析应用程序的能力,并克服与复杂应用程序的模糊化相关的许多当前障碍。
具体来说,我们关注的是一类特殊的挑战:我们观察到当前的fuzzer无法正确地探索超出代码覆盖范围的程序状态空间。例如,导致相同代码覆盖率但状态值不同的程序执行不能由当前的模糊器进行适当的探索。一般来说,探索状态的问题是有挑战性的,因为很难自动推断哪些值是有趣的,哪些不是。然而,对项目目标有高度了解的人,往往知道哪些价值观是相关的,哪些价值观不是相关的。例如,人类可能知道探索不同的玩家位置与解决游戏相关,而游戏世界中所有敌人的位置则不是。
我们表明,人类分析人员可以对状态空间中应该更彻底地探索的部分进行注释,从而修改fuzzer可以使用的反馈函数。所需的注释通常很小,通常只需要一行或两行额外的代码。为了证明所提方法的可行性,我们扩展了各种基于AFL的模糊器,能够用提示来注释目标应用程序的源代码,以指导模糊器。我们的分机名为IJON,以斯坦尼斯拉夫·勒姆书中著名的太空探险家IJON Tichy命名[31]。在四个案例研究中,我们表明注释可以帮助克服重要的障碍,并探索更有趣的行为。例如,使用简单的注释,我们能够播放Super Mario Bros(如图1所示),并从CGC challenge数据集中解决硬实例。
总之,我们在本文中做出了以下贡献:
我们系统地分析了当前模糊器中实现的反馈方法,研究了它们如何表示状态空间,并研究了它们在实际应用中失败的情况。
我们为当前反馈模糊器设计了一组扩展,允许人类分析师引导模糊器通过应用程序的状态空间,并在当前方法失败时解决硬约束。
我们在几个案例研究中演示了如何使用这些注释来探索目标应用程序的深层行为。更具体地说,我们展示了一个可信平台模块(TPM)、复杂格式解析器、游戏超级马里奥兄弟、迷宫和哈希图实现的软件仿真器的状态空间是如何被模糊器有效地探索的。此外,我们证明,我们的方法使我们能够解决CGC数据集中的一些最困难的挑战,并在实际软件中发现新的漏洞。
IJON的实现和说明我们的评估结果的完整数据集(包括本文中的案例研究的播放视频)可在https://github.com/RUB-SysSec/IJON上获得。
II. TECHNICAL BACKGROUND
我们的工作建立在AFL家族上,比如ANGORA[14]、AFLFAST[11]、QSYM[60]或LAFINTEL[1]。为了解释我们方法的技术细节,我们需要介绍AFL自身内部工作的一些方面。AFL家族的Fuzzers通常试图从程序的状态空间中找到一个能够触发各种不同状态的语料库。这里,状态表示存储器和寄存器的一种配置,以及操作系统提供的状态(例如,文件描述符和类似的原语)。状态空间是一个程序可能处于的所有状态的集合。因为即使对于非常小的程序,状态空间也大于宇宙中原子的数量,所以模糊器必须优化测试用例所达到的状态多样性。这类模糊器通常使用代码覆盖率来决定输入是否达到与语料库中存在的输入完全不同的状态。我们使用AFL用来跟踪这个覆盖范围的位图。因此,我们从解释AFL使用的覆盖反馈的设计开始。随后,我们讨论了在使用模糊器优化状态覆盖率时这种设计的一些后果。
A. AFL Coverage Feedback
AFL的各个分支使用插桩来获取测试覆盖率信息。通常,AFL风格的模糊器跟踪控制流图(CFG)中的各个边在每个测试输入期间执行的频率。常用的反馈机制有两类:基于源代码的AFL fork通常使用一个自定义编译器pass,该过程用一段自定义代码注释所有边。仅二进制版本的AFL使用不同的机制,如动态二进制检测(DBI)或硬件加速跟踪(通常是Intel LBR或Intel PT)来获取覆盖率信息。不管是哪种方式,插入目标应用程序的探测都会计算CFG中每个边的出现次数,并将它们存储在密集编码的表示中。
结果信息存储在共享映射中,该映射在每次测试运行期间累积所有边计数。fuzzer还维护一个全局位图,其中包含在整个fuzzing活动中遇到的所有边缘覆盖。全局位图用于快速检查测试输入是否触发了新的覆盖。AFL将测试输入视为有趣的并将其存储,如果它在任何边上包含以前未看到的迭代次数。由于边总是连接两个基本块,因此边被编码为由两个标识符组成的元组,一个用于源基本块id,另一个用于目标块idt。在基于源代码的版本中,在编译时为每个基本块分配一个静态随机值,用作id或idt。对于纯二进制实现,通常使用应用于跳转指令/目标指令地址的廉价哈希函数来分别导出id和idt值。然后使用这个元组(ids,idt)来索引共享映射中的一个字节。通常,下标的计算方法为(ids*2)⊕idt。乘法被用来有效地区分自循环。
在每次新的测试运行之前,将清除共享映射。在测试运行期间,每次遇到边时,共享映射中的相应字节都会递增。这意味着大于255的边计数将溢出,并可能注册为0到255之间的任意数字。执行完成后,对边计数进行了扣减,使得非零边计数的共享映射中的每个字节都包含2的幂。为此,边缘计数被离散到以下范围1, 2, 3, 4 . . . 7, 8 . . . 15, 16 . . . 31, 32 . . . 127, 128 . . . 255。边计数的每个范围被指定为2的一个特定幂。为了提高不常见边上的精度,3也映射到2的唯一幂,而范围32到64被省略。然后我们可以将共享映射与全局位图进行比较,全局位图包含以前运行中观察到的所有位。如果设置了任何新位,则会存储测试输入,因为它已导致覆盖率增加,并且会更新全局位图以包含新的覆盖。
B. Extending Feedback Beyond Coverage
模糊器有时会陷入搜索空间的某一部分,在那里没有合理的、可能的变异提供任何新的反馈。在本文中,我们开发了新的方法来提供更平滑的反馈景观。因此,我们现在回顾了为避免陷入停滞状态而提出的将反馈机制扩展到代码覆盖范围之外的各种方法。值得注意的是,LAF-INTEL[1]是通过将大型比较指令拆分成多个较小的指令来解决幻数字节类型约束(例如if(input==0xdeadbeef))的早期方法。后来,在STEELIX[32]工具中使用动态二进制插桩实现了同样的想法。将多字节比较指令拆分为多个单字节指令允许fuzzer在每次操作数的单字节匹配时找到新的覆盖范围。ANGORA[14]为每个函数分配一个随机标识符。它使用这些标识符将扩展覆盖元组的第三个字段,该字段包含当前执行上下文的哈希值。为了计算这个散列,它使用一个异或操作组合了所有已调用但尚未返回的函数(即活动函数)的标识符。这样,如果在不同的调用上下文中会发现“相同”覆盖率。例如,此方法有助于解决对strcmp函数的多个调用。然而,这种方法的缺点(即认为所有的调用上下文都是唯一的)是,在某些情况下,这会产生大量实际上不感兴趣的输入。因此,ANGORA需要比AFL更大的位图。
III. DESIGN
一般来说,模糊器试图尽可能有效地从状态空间的“有趣”区域进行采样。然而,很难找到一个准确客观的指标来衡量任何给定输入的状态空间有多“有趣”。AFL及其衍生物的总体成功证明,跟踪边覆盖率是识别新的感兴趣区域的有效指标。边缘覆盖可能是实际中信噪比最好的特性-毕竟,在大多数(即未混淆的[25]、[30])程序中,每个新边缘都表示一种特殊情况。然而,有些代码结构中,如果不探索状态空间中的中间点,这种方法不太可能达到新的覆盖范围。在下面,我们分析代码结构,在其中用户可以提供额外的反馈,这将有助于通过概念性地描述中间步骤,提供额外的反馈。最后,我们介绍了一组新颖的原语,它实际上允许分析师添加自定义注释,这些注释正好提供了克服这些困难所需的反馈。
A. State Exploration
为了识别当前技术难以模糊测试的有问题的代码结构,我们使用最新的模糊器进行了几个离线实验,并手动检查获得的覆盖率。在某些情况下,我们使用种子文件来寻找可以用好种子覆盖的代码,但并非没有,这表明存在困难。在下面,我们总结了我们在这些实验中遇到的最重要的问题:
已知的相关状态值:有时,代码覆盖率不会添加任何反馈来帮助fuzzer前进。如果只有一小部分状态是有趣的,并且人类分析师能够识别这些值,我们就可以直接使用它们来指导模糊器。
已知状态变化:有时,程序太复杂,或者不清楚哪些变量包含有趣的状态,哪些变量不包含。在这种情况下,由于我们不知道足够小的一组相关状态值,我们不能直接使用它们来指导模糊器。相反,人类分析员可能能够识别代码中可能会使状态发生变异的位置。分析人员可以使用这种状态变化的历史作为更复杂状态的抽象,并指导模糊器。例如,许多程序单独处理消息或输入块。处理不同类型的输入块很可能以不同的方式改变状态。
缺少中间状态:与前两种情况不同,可能既没有包含状态的变量,也没有改变我们关心的状态的代码。在这种情况下,分析员可以创建人工中间状态来指导模糊器。
基于模糊测试中重要问题的系统化,我们提供了实例,并对每种建议的方法进行了更详细的描述。
1) 已知的相关状态值:如前所述,有时代码覆盖率几乎不产生有关程序状态的信息,因为所有感兴趣的状态都存储在数据中。例如,覆盖率对无分支AES实现的行为几乎一无所知。如果分析员了解存储有趣状态的变量,他可以直接将状态暴露给fuzzer,然后fuzzer可以探索导致不同内部状态的输入。
while(true) {
ox=x; oy=y;
switch (input[i]) {
case 'w': y--; break;
case 's': y++; break;
case 'a': x--; break;
case 'd': x++; break;
}
if (maze[y][x] == '#'){ Bug(); }
//If target is blocked, do not advance
if (maze[y][x] != ' ') { x = ox; y = oy; }
}
Listing 1: A harder version of the maze game.
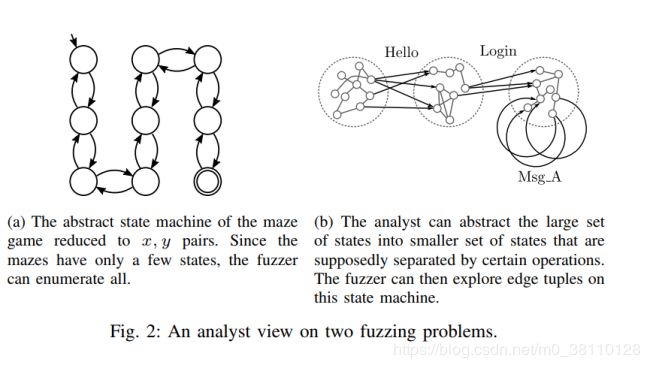
考虑 Listing 1.中的代码。它实现了一个小游戏,在这个游戏中,玩家必须通过在四个可能的方向中的一个移动来导航迷宫。它基于著名的迷宫演示,这是符号执行社区常用来演示符号执行器如何探索迷宫的状态空间。在这个修改后的版本中,可以向后走并保持在同一个位置。这会在程序中创建大量不同的路径。同时,实际上只有四个分支可以被覆盖,因此仅靠覆盖并不能很好地指示有趣的行为。在这个更难的版本中,甚至KLEE [12]也没能解决迷宫问题。在这里,必须理解x和y坐标是需要探索的相关状态。在有死角的迷宫中,甚至不可能通过单独增加x或y来找到解决方案。必须考虑x和y的组合才能发现解决方案。由于迷宫相当小(最多只能到达几百个不同的x,y对),分析员可以指示fuzzer将任何新的x,y对视为新的覆盖(图2.a)。
类似的场景中,用户知道状态的精确方面,这是有趣的探索也发生在更大的状态空间。演示类似场景的一个例子是游戏Super Mario Bros(图3)。同样,我们主要关心的是玩家的坐标。然而,玩家坐标的空间要比迷宫游戏大得多(按106的顺序排列)。因此,分析员需要能够提供一个模糊器可以实现的目标(即增加x坐标),而不是简单地探索所有不同的状态。这样,模糊器可以丢弃劣质的中间结果。
2) 已知状态更改:在某些场景中,用户可能不知道相关状态的哪些部分值得探究,或者状态可能分布在整个应用程序中,难以识别。或者,状态可能是已知的,但是不能识别足够小的子集来直接指导fuzzer。但是,可以确定代码中预期会更改状态的部分。这种情况通常发生在使用高度结构化数据(如消息序列或文件格式的块列表)的应用程序中。在这种情况下,用户可以创建包含消息或块类型日志的变量,而不是直接公开状态本身。这个变量可以作为实际状态变化的代理,并且可以暴露给反馈函数(图2.b)。因此,fuzzer现在可以尝试探索这些状态变化的不同组合。在这样的场景中,状态更改日志充当了一个抽象层,可以抽象出不易暴露给fuzzer的真实状态。我们在第III-D节的示例4中进一步阐述了这一点。
msg = parse_msg();
switch(msg.type) {
case Hello: eval_hello(msg); break;
case Login: eval_login(msg); break;
case Msg_A: eval_msg_a(msg); break;
}
Listing 2: A common problem in protocol fuzzing.
考虑 Listing 2中所示的调度程序代码,它基于许多常见的协议实现。fuzzer将成功地发现不同的消息。然而,AFL难以生成有趣的消息序列,因为没有为链接消息生成新的覆盖。这里的根本问题是模糊器无法区分程序状态机中的不同状态。通过使用成功处理的消息类型的日志,fuzzer能够更有效地探索由消息组合产生的不同状态。
3) 缺少中间状态:一个简单的问题示例,其中程序中的覆盖率和值都不提供相关的反馈,这就是幻数字节检查。开箱即用的AFLstyle模糊器无法解决这些问题。请注意,各种方法试图使用其他方法来解决此问题[1]、[7]、[14]、[53]、[60]。然而,同样的问题在更复杂的情况下仍然存在:如果输入和最终比较之间的关系变得更复杂,那么即使是诸如混合执行之类的技术也将失败。另一方面,人类分析师通常可以对程序的行为进行推理,并经常提供进度指标。通过将这个指示器编码为附加的人工中间状态,分析员能够引导模糊器。请注意,对于类似于简单魔法字节的情况,这正是LAF-INTEL所做的。
考虑清单3中的代码,它基于在著名的objdump二进制文件中找到的一个硬案例。程序包含一个执行哈希表查找的函数和一个if条件,其中查找结果用于搜索给定字符串。更具体地说,首先对键进行散列,然后检查相应的桶。如果桶是空的,则不会进行进一步的处理。如果桶包含一些值,则会分别对它们进行比较。这对基于混合执行的工具和模糊器都提出了重大挑战:解决此约束需要找到路径(即计算哈希所需的循环迭代次数)和哈希值的非常特定的组合,它们都共享相同的覆盖范围。即使找到了确切的路径,我们现在仍然依赖哈希和实际字符串匹配。fuzzer必须解决比较问题,同时保持输入的哈希值始终等于目标字符串的哈希值。混合执行很难找到解决这个约束的确切路径。
//shortened version of a hashmap lookup from binutils
entry* bfd_get_section_by_name(table *tbl, char *str) {
entry *lp;
uint32_t hash = bfd_hash_hash(str);
uint32_t i = hash % tbl->size;
//Every hash bucket contains a linked list of strings
for (lp = tbl->table[i]; lp != NULL; lp = lp->next) {
if (lp->hash == hash && strcmp( lp->string, str) == 0)
return lp;
}
return NULL;
}
// used somewhere else
section = bfd_get_section_by_name (abfd, ".bootloader");
if (section != NULL){ ... }
Listing 3: A hash map lookup that is hard to solve (from binutils libbfd, available at bfd/section.c).
我们发现,在整个binutils代码库中,对于各种字符串,类似的情况出现了500多次。在大多数情况下,哈希表由来自输入的值填充,并查找一个固定的字符串。人们可以认识到,这有效地实现了一对多的字符串比较。利用这种洞察力,她可以引导fuzzer找到一个解决方案,将这个复杂的约束转化为一系列简单的字符串比较,这些比较可以通过类似lafi - intel的反馈来解决。
B. Feedback Mechanisms
由于没有当前的fuzzer允许人类分析师直接向fuzzer提供反馈,我们设计了一组注释,允许分析师影响fuzzer的反馈功能。我们的目标是,分析师可以使用这些注释为模糊化过程提供高级指导。在一个交互式模糊会话中,分析员不时检查代码覆盖率,以确定模糊器似乎难以覆盖的分支。然后分析员可以找出模糊器无法取得进展的原因。一般来说,这对人类来说是一件容易的事情。找到路障后,分析人员可以启动第二个模糊会话,该会话使用自定义注释重点解决此路障。注释本身是目标应用程序的一个小补丁,通常由一行(有时是两行)代码组成,这些代码提供额外的反馈信息。当fuzzer解决了道路阻塞时,长时间运行的fuzzing会话从临时会话中选择产生新覆盖的输入并继续fuzzing,从而克服了困难情况。
为了简化这样的工作流,我们设计了四个通用原语,可用于注释源代码:
1) 我们允许分析员选择与解决当前问题相关的代码区域。
2) 我们允许直接访问AFL位图来存储附加值。位图项可以直接设置,也可以递增,因此可以向反馈函数公开状态值。
3) 我们使分析员能够影响覆盖率计算。这允许相同的边缘覆盖率导致不同的位图覆盖率。这允许在不同的状态下创建更细粒度的反馈。
4) 我们引入了一个原语,允许用户添加爬山优化[48]。这样,如果可能状态的空间太大而无法穷尽地探索,则用户可以提供一个要努力实现的目标。
在下面,我们将更详细地解释这些注释,并说明它们是如何工作的,以及如何使用它们来实现第III-A节中描述的附加反馈机制。
C. IJON-Enable
IJON-ENABLE(和IJON-DISABLE)注释可用于启用和禁用覆盖率反馈。这样,我们可以有效地排除代码库中的某些部分,或者引导fuzzer仅在满足某些条件时才探索代码。
IJON_DISABLE();
//...
if(x<0)
IJON_ENABLE();
Listing 4: Using the IJON-ENABLE annotation. The green highlight indicates an added annotation.
例1。考虑Listing 4中的注释(绿色突出显示)。在本例中,IJON-ENABLE将临时模糊会话限制为到达注释行且x为负值的输入。此注释允许模糊器集中精力解决难题,而不会浪费时间探索输入队列中的许多其他路径。
D. IJON-INC and IJON-SET
IJON-INC和IJON-SET注释可用于增加或设置位图中的特定项。这有效地允许将状态中的新值视为等于新代码覆盖率。分析员可以使用这个注释选择性地将状态的各个方面公开给fuzzer。因此,fuzzer可以探索这个变量的许多不同值。实际上,这个注释添加了一个超出代码覆盖范围的反馈机制。fuzzer现在还可以通过其测试用例获得新的数据覆盖率。此注释可用于在我们前面描述的所有三个场景中提供反馈。
IJON_INC(x);
Listing 5: Using the IJON-INC annotation to expose the value x to the feedback function.
例2。考虑Listing 5所示的注释。每次x改变时,位图中的一个新条目都会递增。例如,如果x等于5,我们根据当前文件名、当前行号和值5的散列计算位图中的索引。位图中相应的项随后递增。这使得fuzzer能够一点一点地学习显示大量行为的各种输入。
类似地,对于IJON-INC注释,我们还提供IJON-SET注释。此注释不是递增项,而是直接设置位图值的最低有效位。这使得可以控制位图中的特定条目来引导模糊器;此原语用于前面介绍的所有三种注释方法
while(true) {
ox=x; oy=y;
IJON_SET(hash_int(x,y));
switch (input[i]) {
case 'w': y--; break;
//....
Listing 6: Annotated version of the maze.
例3。我们在第III-A1节介绍的迷宫游戏中添加了一个单行注释(见清单6)。它使用x和y坐标的组合作为反馈。因此,游戏中任何新访问的位置都被视为新的覆盖范围。我们使用IJON-SET而不是IJON-INC,因为我们不关心给定位置被访问的频率。相反,我们只对访问了一个新位置的事实感兴趣。
如果状态不容易观察,我们可以使用状态更改日志(如前所述),其中我们注释了已知会影响我们关心的状态的操作,并使用状态更改日志作为反馈的索引。
例4。作为另一个例子,请考虑Listing 7。在每个成功解析和处理的消息之后,我们将表示消息类型的命令索引追加到状态更改日志中。然后我们设置一个位,由状态更改日志的散列寻址。因此,每当我们看到由多达四条成功处理的消息组成的新组合时,fuzzer就会将输入视为有趣的,从而在应用程序的状态空间中提供更好的覆盖。
//abbreviated libtpms parsing code in ExecCommand.c
msg = parse(msg);
err = handle(msg);
if(err != 0){goto Cleanup;}
state_log=(state_log<<8)+command.index;
IJON_SET(state_log);
Listing 7: Annotated version of libtpms.
例4。作为另一个例子,请考虑清单7。在每个成功解析和处理的消息之后,我们将表示消息类型的命令索引追加到状态更改日志中。然后我们设置一个bit,由状态更改日志的哈希值寻址。因此,每当我们看到最多四个成功处理的消息的新组合时,fuzzer就会认为输入很有趣,从而在应用程序的状态空间中提供了更好的覆盖率。
E. IJON-STATE
如果消息不容易连接(例如,因为有一个消息计数器),则状态更改日志可能不足以探索不同的状态。为了产生更精细的反馈,我们可以探索状态和代码覆盖率的笛卡尔积。为了实现这一点,我们提供了第三个原语,它能够改变边缘覆盖率本身的计算。与ANGORA相似,我们使用名为“虚拟状态”的第三个组件扩展了边缘元组。 在计算任何边缘的位图索引时,也会考虑此虚拟状态分量。 此注释称为IJON-STATE。 只要虚拟状态发生变化,任何边缘都会触发新的覆盖范围。 必须谨慎使用此原语:如果虚拟状态的数量增加太多,则模糊器会被大量输入淹没,这实际上会减慢模糊处理的进度。
IJON_STATE(has_hello + has_login);
msg = parse_msg();
//...
Listing 8: Annotated version of the protocol fuzzing example (using IJONSTATE).
例5。考虑Listing 8中提供的示例。如前所述,如果没有注释,fuzzer可能很难探索各种消息的组合。通过显式地将协议状态添加到fuzzer的虚拟状态,我们可以根据协议状态创建代码的多个虚拟副本。
因此,fuzzer能够在协议状态机的各种状态下充分挖掘所有可能的消息。有效地,相同的边缘覆盖现在可以导致不同的位图覆盖,因此模糊器可以有效地探索被测程序的状态空间。注意,为了防止状态爆炸,只有三个可能的状态值。因此,一旦成功认证,fuzzer就可以完全重新探索整个代码库。
IJON-MAX
到目前为止,我们主要处理的是提供反馈,这些反馈可以用来增加存储的输入的多样性。但是,在某些情况下,我们希望针对特定目标进行优化,或者状态空间太大,无法完全覆盖。在这种情况下,我们可能不关心不同的值集,也不想放弃所有中间值。为了在这种情况下允许有效的模糊化,我们提供了一个称为IJON-MAX的最大化原语,它有效地将模糊化器转化为一个通用的基于爬山的黑盒优化器。为了使多个值最大化,提供了多个(默认为512个)插槽来存储这些值。与覆盖位图一样,每个值都是独立最大化的。使用此原语,还可以通过最大化-x轻松地为x构建最小化原语。
//inside main loop, after calculating positions
IJON_MAX(player_y, player_x);
Listing 9: Annotated version of the game Super Mario Bros.
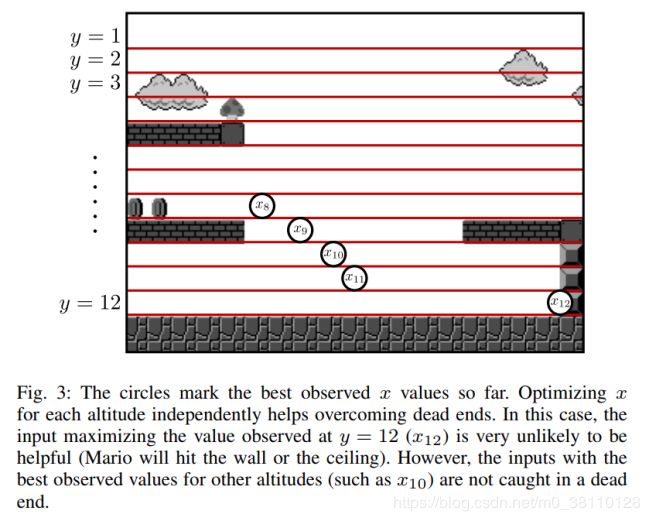
例6。以视频游戏Super Mario Bros为例,玩家在侧滚游戏中控制角色。在每个关卡中,目标是到达关卡的末端,同时避免敌人、陷阱和坑等危险。如果角色被敌人触碰或掉进坑里,游戏结束。要正确探索游戏的状态空间,重要的是达到每一个层次的末尾。如Listing 9所示,我们可以通过让fuzzer尝试最大化播放器的x坐标来完成这个级别。鉴于这是一款横向滚动游戏,因此可以有效地指导模糊测试者找到通过关卡成功完成游戏的方法。
然后,IJON-MAX(slot,x)注释告诉模糊器最大化字符的x坐标。 请注意,我们使用玩家的y坐标(高度)来选择slot。 这使我们能够在水平范围内独立地最大化不同高度上的进度。 通过增加输入集的多样性,我们减少了陷入死胡同的机会,如图3所示。使用这种技术,我们可以快速找到32个游戏关卡中29个的解决方案。 有关更多详细信息,请参见第V-C节。
IV. IMPLEMENTATION
我们将IJON实施为基于AFL的多个模糊器的扩展:AFLFAST,LAFINTEL,QSYM和ANGORA。 所有这些模糊器都共享相同的基础代码库,因此,对于所有模糊器而言,实现我们的方法所需的更改都是相似的。 总体而言,我们执行了两种不同的更改。 一方面,我们实现了一种将注释应用于目标应用程序的方法。 另一方面,我们扩展了IJON与目标之间的通信通道。
A. Adding Annotations
为了实现覆盖率反馈,AFL附带了一个用于clang的特殊编译器pass,用于检测每条分支指令。 此外,AFL提供了一个包装器,可用来代替clang来编译目标。 该包装器自动注入自定义编译器pass。 我们扩展了包装器和编译器通道。 为了支持我们的更改,我们引入了一个附加的运行时库,编译器将其静态链接。 运行时实现了各种辅助功能和宏,可用于对目标应用程序进行注释。 特别是,我们增加了对快速哈希函数的支持,该函数可用于生成分布更好的值或将字符串压缩为整数。 总之,我们使用了第三节中的原语,并添加了一些更高级的辅助函数。
1)IJON-ENABLE:为实现IJON-ENABLE,我们引入了一个适用于所有位图索引计算的掩码。 如果掩码设置为零,则只能寻址和更新第一个位图条目。 如果将其设置为0xffff,则使用原始行为。 这样,我们可以有效地禁用和启用覆盖范围跟踪。
2) IJON-INC and IJON-SET: 这两个注释都可以与位图直接交互,因此实现非常简单。 调用ijon_inc(n)后,位图中的第n项将增加。 同样,调用ijon_set(n)会将第n条目的最低有效位设置为1。
如果在程序代码中的多个位置使用了这些功能,则必须非常小心,不要重用相同的位图索引。 为了避免这种情况,我们引入了辅助宏IJON_INC(m)和IJON_SET(m)。 这两个宏都调用相应的函数,但根据m的哈希值以及宏调用的文件名和行号来计算位图索引n。 因此,避免在常用参数(例如0或1)上发生琐碎的冲突。
3)IJON-STATE:当调用IJON_STATE(n)时,我们更改了将基本块边缘映射到位图条目的方式。 为此,我们更改边缘元组的定义,以包括源ID和目标ID(状态,ID,IDT)之外的状态。 在此,“状态”是线程局部变量,用于存储与当前状态有关的信息。 调用IJON_STATE(n)更新状态:=状态state n。 这样,两个连续的调用会互相抵消
我们还修改了编译器pass,以使位图索引的计算如下:state⊕(ids * 2)⊕idt。 这样,每次状态变量更改时,每个边沿都会在位图中获得新索引。 这些技术允许相同的代码在不同的上下文中执行时产生不同的覆盖范围。
4)IJON-MAX:我们扩展了模糊器,以保持额外的第二输入队列以实现最大化。 我们支持最多增加512个不同的变量。 这些变量中的每一个都称为插槽slot。 模糊器仅存储为每个插槽产生最佳值的输入,并丢弃导致较小值的旧输入。 为了存储最大的观察值,我们引入了一个附加的共享内存max-map,该映射由64位无符号整数组成。 调用最大化原语IJON_MAX(slot,val)会更新maxmap [slot] = max(maxmap [slot],val)。
执行测试输入后,模糊器将检查共享位图和max-map是否有新覆盖。 与共享覆盖位图和全局位图的设计类似(如第II-A节中所述),我们还实现了全局max-map,该图在整个模糊测试过程中都将持续存在,并补充了共享最大图。 与位图相反,没有bucketing 应用于共享的max-map。 如果共享的max-map中的条目大于全局max-map中的对应条目,则认为该条目是新颖的。
由于我们现在有两个输入队列,因此我们还必须更新调度策略。 IJON要求用户提供使用原始队列(从代码覆盖率生成)或最大化队列(从最大化插槽生成)的概率。 使用此功能,用户可以决定哪个队列对选择模糊输入更为重视。 用户可以提供环境变量IJON_SCHEDULE_MAXMAP,其值为0到100。每次计划新的输入时,模糊器都会绘制一个介于100和100之间的随机数。 如果随机数小于IJON_SCHEDULE_MAXMAP的值,则会进行通常的基于AFL的调度。 否则,我们在max-map中选择一个随机的非零slot,并模糊测试对应于该slot的输入。 如果在模糊其输入的同时更新了同一插槽,则旧输入将立即被丢弃,并且基于新近更新的输入,将继续进行模糊测试阶段。
5) Helper函数:IJON的运行库包含一组Helper函数,可以简化公共注释。例如,运行库包含帮助函数来散列不同类型的数据,例如字符串、内存缓冲区、活动函数堆栈或当前行号和文件名。此外,还有一些helper函数可用于计算两个值之间的差异。我们实现了不同的助手函数来简化注释过程,如下所述:
•IJON_CMP(x,y):计算x和y之间不同的位数。 此辅助函数直接使用它来触摸位图中的单个字节。 值得一提的是,出于实用目的,它并不直接使用不同位数作为位图的索引。 考虑 Listing 5,如果在多个位置重复使用了相同的注释,则索引将发生冲突(两者共享0到64的范围)。 相反,IJON_CMP将参数与当前文件名和行的哈希值组合在一起。 因此,我们大大减少了碰撞的机会。
•IJON_HASH_INT(u32 old,u32 val):返回old和val的哈希。 如第III-D节所述,我们使用哈希函数来创建更多不同的索引集并减少发生冲突的可能性。
•IJON_HASH_STR(u32 old,charSTR):返回两个参数的哈希值。例如,我们使用这个helper函数来创建文件名的散列。
• IJON_HASH_MEM(u32 old, u8 mem, size_t len): 返回旧字节和mem的第一个len字节的哈希值
太长了。。未完待续