hadoop学习-mahout-Bayes分类算法示例程序
最近在看《hadoop实战》(陆嘉恒),在练习运行贝叶斯分类算法的示例程序的时候老是报错。
完美体现了:”书本里永远少一个环节“的真理。。。。
首先在运行贝叶斯算法程序之前,运行环境要求:
1、安装maven(书中没提到的)
2、安装mahout
3、安装hadoop
关于2,3的安装方式可以参考书本里或者网上的方法。
下面说说安装maven过程,网上很多是直接下载 tar包,然后解压出来。 http://apache.etoak.com//maven/binaries/apache-maven-3.0.2-bin.tar.gz
我是直接在终端下通过apt-get指令安装,两者方法区别不大 :
1、sudo apt-get maven2
2、设置环境变量,在/etc/profile中加入
export M2_HOME=/usr/local/maven
export PATH=${M2_HOME}/bin:${PATH}
以下是我的配置:
export JAVA_HOME=/usr/lib/jdk/jdk1.7.0_40
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/rt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export HADOOP_HOME=/root/hadoop-1.2.1
#export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH:$HADOOP_HOME/hadoop-core-1.2.1.jar
export M2_HOME=/usr/share/maven2
export PATH=${M2_HOME}/bin:${PATH}
export HADOOP_CONF_DIR=/root/hadoop-1.2.1/conf
export MAHOUT_HOME=/root/mahout/mahout-distribution-0.9
export PATH=${MAHOUT_HOME}/bin:${PATH}因为我是通过apt-get方式安装,所以maven2目录在/usr/share之下,通过解压出来的,只要在相应目录下找到conf/settings.xml即可。
大约在第50行。
添加
以下是我的配置
/root/.m2/repository
4、查看maven是否安装成功
mvn -version
Apache Maven 2.2.1 (rdebian-1)
Java version: 1.7.0_40
Java home: /usr/lib/jdk/jdk1.7.0_40/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "linux" version: "2.6.32-46-generic" arch: "i386" Family: "unix"
之后就是参考书本的13.4.5章节,运行示例了。
我在运行
bin/hadoop jar /root/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar org.apache.mahout.classifier.bayes.TrainClassifier -i 20news-input -o newsmodel -ng 3 -type bayes -source hdfs
报错如下

多次百度,谷歌,未果。。。。
无奈参考其中一篇博文的曲线救国法。
运行~/mahout/mahout-distribution-0.9/examples/bin目录下自带的classify-20newsgroups.sh脚本
首先我们来看看这个脚本的部分代码:
#WORK_DIR=/tmp/mahout-work-${USER}
WORK_DIR=/root/hadoop-1.2.1/20news-input
algorithm=( cnaivebayes naivebayes sgd clean)
if [ -n "$1" ]; then
choice=$1
else
echo "Please select a number to choose the corresponding task to run"
echo "1. ${algorithm[0]}"
echo "2. ${algorithm[1]}"
echo "3. ${algorithm[2]}"
echo "4. ${algorithm[3]} -- cleans up the work area in $WORK_DIR"
read -p "Enter your choice : " choice
fi
echo "ok. You chose $choice and we'll use ${algorithm[$choice-1]}"
alg=${algorithm[$choice-1]}
if [ "x$alg" != "xclean" ]; then
echo "creating work directory at ${WORK_DIR}"
#mkdir -p ${WORK_DIR}
if [ ! -e ${WORK_DIR}/20news-bayesinput ]; then
if [ ! -e ${WORK_DIR}/20news-bydate ]; then
if [ ! -f ${WORK_DIR}/20news-bydate.tar.gz ]; then
echo "Downloading 20news-bydate"
curl http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz -o ${WORK_DIR}/20news-bydate.tar.gz
fi
mkdir -p ${WORK_DIR}/20news-bydate
echo "Extracting..."
cd ${WORK_DIR}/20news-bydate && tar xzf ../20news-bydate.tar.gz && cd .. && cd ..
fi
fi
fi1. cnaivebayes
2. naivebayes
3. sgd
4. clean
其中最后一个选项clean是表示清空数据文件所在的临时目录。
当你选择前三项中的一项时,代码将判断工作目录${WORK_DIR}中有没有20news-bydate.tar.gz, 如果没有,通过curl 去http://people.csail.mit.edu取。这里要求你的机器上安装有curl 。
因为这里我的机器没有安装curl,而且已经下载好了20news-bydate.tar.gz(可以从http://qwone.com/~jason/20Newsgroups/下载)。所以我不希望再通过curl去下载,因此我手动修改了这个代码。
修改:WORK_DIR=/root/hadoop-1.2.1/20news-input
注释:#mkdir -p ${WORK_DIR}
这里的20news-input存放有20news-bydate.tar.gz
也不需要再创建这个目录,所以直接注释#mkdir -p ${WORK_DIR}
为了保留原始版本,改完后我另存为myclassify-20newsgroups.sh
然后运行./myclassify-20newsgroups.sh
因为这里有解压,上传到hdfs等等操作,需要等一会儿。。。
等我午饭归来,success!
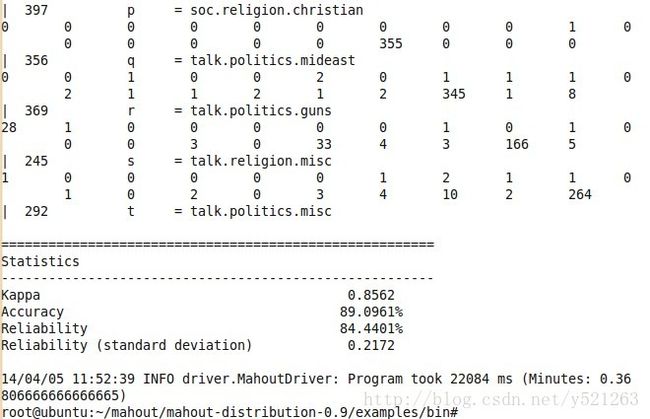
至于原来的方式的错误,我还没找到解决方法,希望有知道的朋友能指教下,也期待一起学习hadoop的朋友一起交流下,谢谢。
参考资料:
http://f.dataguru.cn/forum.php?mod=viewthread&tid=239064&fromuid=41168
http://log.medcl.net/item/2011/02/mahout_install/
《mahout in action》