【mysql知识点整理】--- mysql执行计划详解
文章目录
- 前言
- 1 id列 --- 用来判断语句的执行顺序
- 2 select_type列 --- 用来判断查询的类型
- 3 table列 --- 表示当前行操作的数据是关于哪张表的
- 4 partitions列
- 5 type ★★★
- 5.1 system
- 5.2 const --- 常见于主键或唯一索引,where后为确认的常量
- 5.3 eq_ref --- 常见于主键或唯一索引,where后为变量 ★ ★
- 5.4 ref --- 非唯一索引列上进行等值查找 ★★
- 5.5 fulltext --- 全文索引
- 5.6 ref_or_null --- 类似于ref,但多了对于null的处理
- 5.7 index_merge
- 5.8 unique_subquery --- copy自官网(我没试出来)
- 5.9 index_subquery --- copy自官网(我没试出来)
- 5.10 range(尽量保证)索引列上进行范围查找★ ★
- 5.11 index(至少) --- 全索引扫描★ ★
- 5.12 ALL(不可) --- 进行了全表扫描★ ★
- 6 possible_keys列 --- 可能会应用到的索引
- 7 key列 --- 实际使用到的索引
- 8 key_len --- 索引使用的字节数,在联合索引中用处表较大 ★★★
- 9 ref --- 索引中的哪一列被使用了
- 10 rows --- 查询出结果大致所扫描的行数
- 11 Extra --- 附加信息 ★★★
- 11.1 using filesort(尽量不要出现) --- 没有用索引进行的排序
- 11.2 using temporary(尽量不要出现) --- 使用了临时表
- 11.3 using index(比较好的sql) --- 使用到了覆盖索引 ★★★
- 11.4 using where --- 使用了where过滤条件
- 11.5 select tables optimized away(比较好的sql) --- 查到了已经优化的数据
- 11.6 Using join buffer (Block Nested Loop) --- 一般都需要进行优化 ★★★
- 12 filtered列 --- copy自官网
- 本文使用数据脚本
官网:https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
前言
EXPLAIN + SQL 的输出结果为一个表,表头如下:
![]()
该条SQL语句在mysql里的具体执行信息(即执行计划)就藏在该表里。要想读明白这些信息,必须搞明白这个表里各列的具体含义。
1 id列 — 用来判断语句的执行顺序
ID列:描述select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
根据id列中的数值可以分成以下几种情况:
- id值相同 — 执行顺序由上至下
- id值不同 — id值越大优先级越高,越先被执行
- id值既有相同,又有不同 — id值大的先执行,如果id值相同则由上到下执行
- id值为null: 官网描述如下:
The value can be NULL if the row refers to the union result of other rows.In this case, the table column shows a value like
2 select_type列 — 用来判断查询的类型
查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询
3 table列 — 表示当前行操作的数据是关于哪张表的
- 直接显示表名或者表的别名
- < derivedN > 由 ID 为 N 衍生出来的表
- < subqueryN> : 请参考 https://dev.mysql.com/doc/refman/8.0/en/subquery-materialization.html
4 partitions列
请参考:https://dev.mysql.com/doc/refman/8.0/en/partitioning-info.html
5 type ★★★
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery >
range(尽量保证)> index > ALL
较常用到的是:system>const>eq_ref>ref>range>index>ALL
5.1 system
The table has only one row (= system table). This is a special case of the const join type.
5.2 const — 常见于主键或唯一索引,where后为确认的常量
表示通过索引一次就找到了,const用于比较
primary key或者unique索引。因为只匹配一行数据,所以很快
如将主键置于where列表中,MySQL就能将该查询转换为一个常量
explain select * from t1 where t1.id =1;

5.3 eq_ref — 常见于主键或唯一索引,where后为变量 ★ ★
官网上给了两个栗子,我按照自己造的数据写了一下sql如下:
EXPLAIN SELECT * FROM t1,t2 WHERE t1.id=t2.id;
EXPLAIN SELECT * FROM t1,t2 WHERE t1.id=t2.id and t1.t1_col = 'yoyo';

5.4 ref — 非唯一索引列上进行等值查找 ★★
本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体
EXPLAIN select t1_col from t1 where t1_col = 'haha'; -- t1_col为非唯一索引列

5.5 fulltext — 全文索引
The join is performed using a FULLTEXT index.
5.6 ref_or_null — 类似于ref,但多了对于null的处理
注意: 在mysql里null 不等于null
关于null的优化处理可以参考: https://dev.mysql.com/doc/refman/8.0/en/is-null-optimization.html
EXPLAIN select t1_col from t1 where t1_col = 'haha' or t1_col = null; -- t1_col为非唯一索引列
![]()
5.7 index_merge
在查询过程中需要多个索引组合使用,通常出现在有 or 的关键字的sql中
更多详情请参考官网:https://dev.mysql.com/doc/refman/8.0/en/index-merge-optimization.html
5.8 unique_subquery — copy自官网(我没试出来)
This type replaces eq_ref for some IN subqueries of the following form:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
注意: 上面SELECT后跟的为主键索引或唯一索引(突然想到一个比较经典的问题,唯一索引一定非空么?☺☺☺)
unique_subquery is just an index lookup function that replaces the subquery completely for better efficiency.
5.9 index_subquery — copy自官网(我没试出来)
This join type is similar to unique_subquery. It replaces IN subqueries, but it works for nonunique indexes in subqueries of the following form:
value IN (SELECT key_column FROM single_table WHERE some_expr)
5.10 range(尽量保证)索引列上进行范围查找★ ★
官网文字性的介绍如下:
Only rows that are in a given range are retrieved, using an index to select the rows. The key column in the output row indicates which index is used. The key_len contains the longest key part that was used. The ref column is NULL for this type.
range can be used when a key column is compared to a constant using any of the =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, or IN() operators。
举例如下:
EXPLAIN select * from t1 where id BETWEEN 30 and 60; -- 主键索引
EXPLAIN select * from t1 where t1_col like "uuu%"; -- 非主键索引

需要注意的是,有些范围查询可能会被降为index
EXPLAIN select * from t1 where id in (1,2);

5.11 index(至少) — 全索引扫描★ ★
Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。
也就是说虽然all和Index都是读全表,但index是从索引中读取的,而all是从硬盘中读的。
explain select id from t2; -- id为索引列,所以type为index
explain select * from t2; -- 由于t2表中有其他字段没建索引,所以type为ALL
对于上面的第2条语句你会不会有什么想法???☺☺☺

5.12 ALL(不可) — 进行了全表扫描★ ★
EXPLAIN SELECT * FROM t2 WHERE t2_col = 'yoyo'; -- t2_col为非索引列

6 possible_keys列 — 可能会应用到的索引
显示可能应用在这张表中的索引,一个或多个。
查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用
7 key列 — 实际使用到的索引
实际使用的索引,如果为 NULL ,则没有使用索引。
8 key_len — 索引使用的字节数,在联合索引中用处表较大 ★★★
官网描述:
The key_len column indicates the length of the key that MySQL decided to use. The value of key_len enables you to determine how many parts of a multiple-part key MySQL actually uses. If the key column says NULL, the key_len column also says NULL.
Due to the key storage format, the key length is one greater for a column that can be NULL than for a NOT NULL column.
几点注意:
- 根据这个值,可以判断索引的使用情况,特别是在组合索引的时候,判断所有的索引字段是否都被查询用到。
- Key_len表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好
- 可以百度其计算规则,如:https://www.cnblogs.com/xuanzhi201111/p/4554769.html 。本文不过多叙述。
9 ref — 索引中的哪一列被使用了
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。
explain select * from t1,t2 where t1.t1_col = 't1_888' and t2.id = t1.id;

10 rows — 查询出结果大致所扫描的行数
官网介绍如下:
The rows column indicates the number of rows MySQL believes it must examine to execute the query.
For InnoDB tables, this number is an estimate, and may not always be exact.
11 Extra — 附加信息 ★★★
官网上列出了很多可能的值,我这里总结一些工作中可能会经常用到的。
11.1 using filesort(尽量不要出现) — 没有用索引进行的排序
MySQL 对数据使用一个外部的文件内容进行了排序,而不是按照表内的索引进行排序读取。
MySQL中无法利用索引完成的排序操作称为“文件排序”
explain select * from t2 order by t2_col;

实际工作中应尽量避免出现Using filesort。 如果通过前面的查询语句筛选后,只剩下很少的数据参与排序,然后才出现Using filesort还好;但是如果有大量数据参与非索引排序,那就完蛋了。
11.2 using temporary(尽量不要出现) — 使用了临时表
使了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。
EXPLAIN select t2_col2 from t2 GROUP BY t2_col2; --t2_col2列未添加索引

为什么GROUP BY会产生临时表???
其实很简单,GROUP BY的本质就是先排序( 从上面的语句中出现 using filesort可以进行佐证),排序后会生成一张排好序的临时表(我猜测应该对该临时表还进行了去重处理),然后再利用主表和排序后生成的临时表做笛卡尔积运算,从而得到分组后的结果。
11.3 using index(比较好的sql) — 使用到了覆盖索引 ★★★
在mysql的官网里貌似没提覆盖索引这个概念,但是它有这样一段描述:
The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
相信如果看懂了我上篇文章《【mysql知识点整理】 — mysql索引底层数据结构》的话,其实这句话是很好理解的。它的意思就是当你要查询的数据,直接可以通过索引树获得的话,那这种查询就是using index的。
这里应该至少可以从三个方面去理解(我之后应该会再写一篇文章,聊聊这里,所以不展开太多了):
- 直接从聚簇索引里获取到想要的数据
- 直接从非聚簇索引里获取到想要的数据
- 先通过非聚簇索引获取到该索引对应的主键值,然后拿着主键值再去聚簇索引里找到想要的数据
举个小栗子:
explain select t1_col from t1 where t1_col = 'yoo'; --t1_col列建立了普通索引

11.4 using where — 使用了where过滤条件
只想说一点,where后的条件假如为有索引的列,
老版本的mysql可能会出现using where, 新版本的可能不会出现。
explain select * from t1 where t1_col2= 'yy';

11.5 select tables optimized away(比较好的sql) — 查到了已经优化的数据
explain select count(*) from t1; -- 老版本的mysql innodb引擎可能不行
explain select max(id) from t1; -- 新老版本应该都支持

- innodb数据库引擎会维护当前表的总行数信息
- 由于id为自增主键,根据 B+Tree 的结构,它本身就是有序存放的
对于上诉这样的信息mysql不需要等到执行阶段再进行计算,查询执行计划生成的阶段即可完成优化。
11.6 Using join buffer (Block Nested Loop) — 一般都需要进行优化 ★★★
先看栗子:
(1)关联字段都没建索引的情况
explain select * from t2 left join t3 on t2.t2_col = t3.t3_col;
explain select * from t2,t3 where t2.t2_col = t3.t3_col;

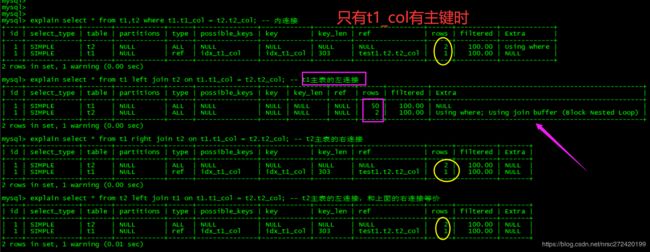
(2) 关联字段一边有索引的情况
explain select * from t1,t2 where t1.t1_col = t2.t2_col; -- 内连接
explain select * from t1 left join t2 on t1.t1_col = t2.t2_col; -- t1主表的左连接
explain select * from t1 right join t2 on t1.t1_col = t2.t2_col; -- t2主表的右连接
explain select * from t2 left join t1 on t1.t1_col = t2.t2_col; -- t2主表的左连接,和上面的右连接等价
(3) 关联字段两边都有索引的情况
explain select * from t1 , t4 where t1.t1_col = t4.t4_col;
explain select * from t1 left join t4 on t1.t1_col = t4.t4_col; -- 主表为t1
explain select * from t1 right join t4 on t1.t1_col = t4.t4_col; -- 主表为t4
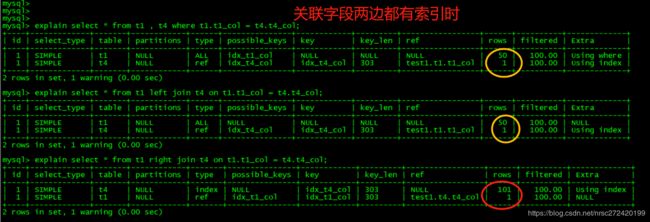
通过上面的栗子可以看到两种出现Using join buffer (Block Nested Loop)的情况:
- 两张表做关联查询,关联字段都没建索引时
- 进行左连接或者右连接查询时,非主表没有索引时
同时还需要注意的是:
- 内连接会自动选择小表作为
驱动表(可以简单理解为左右连接中的主表)
基于以上现象和结论至少可以得到下面两条sql优化的思路:★★★
- 左连接或者右连接时除非万不得已的情况下,一定要选择小表作为主表,并且在非主表上建立索引
- 无论如何主表数据都会被全部读取 — 主表索引没法用
- 非主表的索引可以被用到
- 内连接时会自动读取出小表的所有内容,所以在小表的列上加索引没有用,应在大表所在的列上加索引
12 filtered列 — copy自官网
官网介绍如下:
The filtered column indicates an estimated percentage of table rows that will be filtered by the table condition. The maximum value is 100, which means no filtering of rows occurred. Values decreasing from 100 indicate increasing amounts of filtering. rows shows the estimated number of rows examined and rows × filtered shows the number of rows that will be joined with the following table. For example, if rows is 1000 and filtered is 50.00 (50%), the number of rows to be joined with the following table is 1000 × 50% = 500.
本文使用数据脚本
-- 建表
CREATE TABLE `t1` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`t1_col` varchar(100) DEFAULT NULL,
`t1_col2` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_t1_col` (`t1_col`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=102 DEFAULT CHARSET=utf8;
CREATE TABLE `t2` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`t2_col` varchar(100) DEFAULT NULL,
`t2_col2` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
CREATE TABLE `t3` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`t3_col` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
CREATE TABLE `t4` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`t4_col` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_t4_col` (`t4_col`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=102 DEFAULT CHARSET=utf8;
-- t2表数据
INSERT INTO `test1`.`t2` (`t2_col`, `t2_col2`) VALUES ('t2_111', '111');
INSERT INTO `test1`.`t2` (`t2_col`, `t2_col2`) VALUES ('t2_112', '112');
-- t3表数据
INSERT INTO `test1`.`t3` ( `t3_col`) VALUES ('t3_111');
INSERT INTO `test1`.`t3` ( `t3_col`) VALUES ('t3_112');
-- t1,t4表数据插入
DROP PROCEDURE IF EXISTS my_insert;
CREATE PROCEDURE my_insert()
-- 定义存储过程
BEGIN
DECLARE m,n int DEFAULT 0;
loopname1:LOOP
INSERT INTO t1(t1_col,t1_col2) VALUES(CONCAT('t1_',FLOOR(1+RAND()*1000)),CONCAT('t11_',FLOOR(1+RAND()*1000)));
SET n=n+1;
IF n=50 THEN
LEAVE loopname1;
END IF;
END LOOP loopname1;
loopname2:LOOP
INSERT INTO t4(t4_col) VALUES(CONCAT('t4_',FLOOR(1+RAND()*1000)));
SET m=m+1;
IF m=100 THEN
LEAVE loopname2;
END IF;
END LOOP loopname2;
END;
-- 执行存储过程
CALL my_insert();