Java之网络爬虫WebCollector+selenium+phantomjs(二)
上一篇做小例子的时候,在获取页面上价格的时候发现,获取不到,查了下说是webcollector需要结合selenium与phantomjs来获取js生成的动态。下面就做个例子来学习。
准备材料在上一篇已经准备完毕,我是在windows系统上进行的测试,所以phantomjs运行环境下载phantomjs-windows下载即可,下载后解压到某个文件夹即可(可以把解压路径添加到环境变量里,如果没有加到环境变量那么在启动的时候需要加上路径)。selenium与phantomjs的jar包都在上一篇的pom文件里。
下面贴出代码:
PageUtisl.java
/*
* Copyright (C) 2015 zhao
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA.
*/
package com.zhao.crawler.util;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import cn.edu.hfut.dmic.webcollector.model.Page;
/**
*
*
* @author zhao
* @date 2015-10-22
*/
public class PageUtils {
/**
* 获取webcollector 自带 htmlUnitDriver实例(模拟默认浏览器)
*
* @param page
* @return
*/
public static HtmlUnitDriver getDriver(Page page) {
HtmlUnitDriver driver = new HtmlUnitDriver();
driver.setJavascriptEnabled(true);
driver.get(page.getUrl());
return driver;
}
/**
* 获取webcollector 自带htmlUnitDriver实例
*
* @param page
* @param browserVersion 模拟浏览器
* @return
*/
public static HtmlUnitDriver getDriver(Page page,
BrowserVersion browserVersion) {
HtmlUnitDriver driver = new HtmlUnitDriver(browserVersion);
driver.setJavascriptEnabled(true);
driver.get(page.getUrl());
return driver;
}
/**
* 获取PhantomJsDriver(可以爬取js动态生成的html)
*
* @param page
* @return
*/
public static WebDriver getWebDriver(Page page) {
// WebDriver driver = new HtmlUnitDriver(true);
// System.setProperty("webdriver.chrome.driver", "D:\\Installs\\Develop\\crawling\\chromedriver.exe");
// WebDriver driver = new ChromeDriver();
System.setProperty("phantomjs.binary.path", "D:/Program Files/phantomjs-2.0.0-windows/bin/phantomjs.exe");
WebDriver driver = new PhantomJSDriver();
driver.get(page.getUrl());
// JavascriptExecutor js = (JavascriptExecutor) driver;
// js.executeScript("function(){}");
return driver;
}
/**
* 直接调用原生phantomJS(即不通过selenium)
*
* @param page
* @return
*/
public static String getPhantomJSDriver(Page page) {
Runtime rt = Runtime.getRuntime();
Process process = null;
try {
process = rt.exec("D:/Program Files/phantomjs-2.0.0-windows/bin/phantomjs.exe" +
"D:/MyEclipseWorkSpace/WebCollectorDemo/src/main/resources/parser.js " +
page.getUrl().trim());
InputStream in = process.getInputStream();
InputStreamReader reader = new InputStreamReader(
in, "UTF-8");
BufferedReader br = new BufferedReader(reader);
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp = br.readLine())!=null){
sbf.append(tmp);
}
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
DemoJsCrawler.java
/*
* Copyright (C) 2015 zhao
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA.
*/
package com.zhao.crawler.demo;
import java.util.List;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.zhao.crawler.util.PageUtils;
import cn.edu.hfut.dmic.webcollector.crawler.DeepCrawler;
import cn.edu.hfut.dmic.webcollector.model.Links;
import cn.edu.hfut.dmic.webcollector.model.Page;
/**
*
*
* @author zhao
* @date 2015-10-22
*/
public class DemoJSCrawler extends DeepCrawler {
public DemoJSCrawler(String crawlPath) {
super(crawlPath);
}
@Override
public Links visitAndGetNextLinks(Page page) {
//HtmlUnitDriver
// handleByHtmlUnitDriver(page);
//PhantomJsDriver
handleByPhantomJsDriver(page);
return null;
}
/**
* webcollector自带获取html driver测试
*
* @param page
*/
protected void handleByHtmlUnitDriver(Page page){
/*HtmlUnitDriver可以抽取JS生成的数据*/
HtmlUnitDriver driver=PageUtils.getDriver(page,BrowserVersion.CHROME);
/*HtmlUnitDriver也可以像Jsoup一样用CSS SELECTOR抽取数据
关于HtmlUnitDriver的文档请查阅selenium相关文档*/
print(driver);
}
/**
* phantomjs driver测试
*
* @param page
*/
protected void handleByPhantomJsDriver(Page page){
WebDriver driver=PageUtils.getWebDriver(page);
print(driver);
driver.quit();
}
protected void print(WebDriver driver){
List divInfos = driver.findElements(By.cssSelector("li.gl-item"));
for(WebElement divInfo:divInfos){
WebElement price=divInfo.findElement(By.className("J_price"));
System.out.println(price+":"+price.getText());
}
}
public static void main(String[] args) throws Exception{
DemoJSCrawler crawler=new DemoJSCrawler("D:/test/crawler/jd/");
crawler.addSeed("http://list.jd.com/list.html?cat=1319,1523,7052&page=1&go=0&JL=6_0_0");
crawler.start(1);
}
}
这个类继承了DeepCrawler,里面主要有三个方法:
print()方法:打印获取的价格信息,格式为:价格所在元素:价格。
我打算捕获商品列表页面上的价格,用浏览器审查元素如下图所示
:
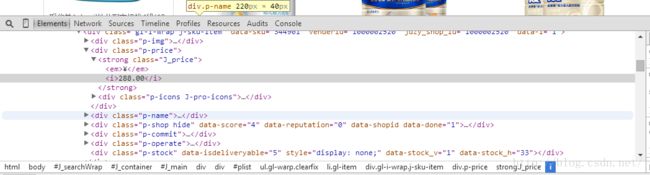
商品位于列表标签li class为gl-item的元素里面,再深入到里面价格在class 为J_price的strong标签里面。按照这个逻辑,我们先获取列表元素,然后再定位到价格标签,打印的时候格式为:价格所在标签:价格。
方法中的price.getText()是获取标签中间或子标签的文本内容(会自动过滤掉标签而获取其中的文本内容)。具体请查看selenium-api-2.12.chm
handleByHtmlUnitDriver():这个方法是用自带的driver获取页面。
下面运行程序,打印结果如下:

只打印了定位的标签,但是没有打印价格(通过查看 页面的js文件发现,京东的价格是js动态加载到页面上的)。证明webcollector 自带的html dirver对处理js动态生成的html页面并不友好。所以这时候就需要另外两个框架selenium与phantomjs配合抓取js动态生成的html页面。
handleByPhantomJsDriver()方法为通过PhantomJsDriver来获取html页面,运行结果如下所示:

通过日志看到成功获取到价格。下一篇将会做一个爬取京东商品列表信息的小例子,并且提供源码下载。上一篇提供各种资源下载及环境搭建。