淘宝订单数据分析
1、项目背景:通过行业常见指标对淘宝用户行为数据进行分析,本数据集包含了2017年11月25日至2017年12月3日之间,约一百万随机用户的所有行为数据(包括用户id、商品id、商品类目、时间戳、行为类型),给出优化建议。数据来源于阿里云天池。
https://tianchi.aliyun.com/dataset/dataDetail?dataId=649
2、提出问题和分析目标
电商指标:
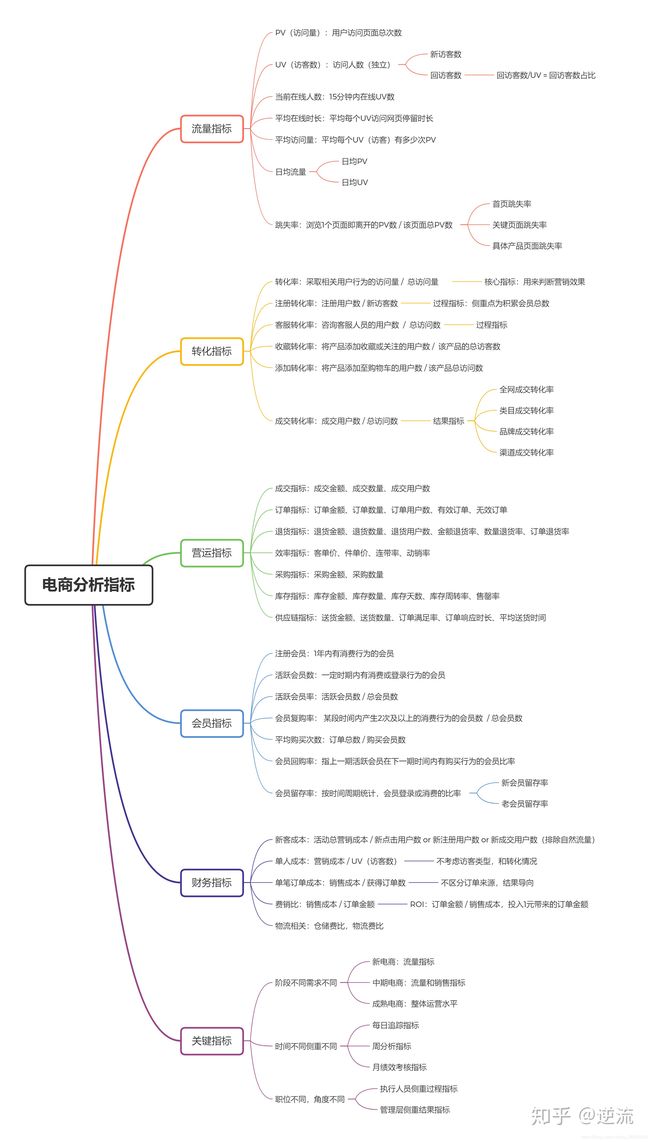
3.本数据集分析维度以及相关指标
【1】流量分布分析
【2】行为转化率分析
【3】消费偏好分析
【5】用户价值分析
三、理解数据
本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。
由于原数据集一共有1亿调数据记录,数据量较为庞大,本次分析选取大约300万条记录进行分析。
数据集简介:

四、数据分析
(1)python导入excel文件(数据量太大,这里导入前300万条)
import pandas as pd
import numpy as np
import os
import matplotlibos.chdir("D:\\UserBehavior")
data = pd.read_csv("UserBehavior.csv",nrows = 3000000)
data = data.rename(columns = {"1":"user_id","2268318":"item_id","2520377":"category_id","pv":"behavior","1511544070":"timestamps"})
(2)数据清洗
# 时间戳转换
data['timestamps'] = pd.to_datetime(data['timestamps'], unit='s') #unix转datetime格式
data['day'] = data['timestamps'].dt.date
data['hour'] = data['timestamps'].dt.hour
print("数据量:",data.shape[0])
# 异常时间处理
data = data[data['timestamps']>'2017-11-25']
data = data[data['timestamps']<'2017-12-04']
(3)构建模型与图表分析
#模型构建与数据分析
#总pv、总uv、总平均访问量(pv/uv)
uv = pd.DataFrame(data.groupby(['user_id'])['user_id'].value_counts()).count()[0] #访问量
pv = data[data['behavior']=='pv'].count()[0] #访客数
avgpv = pv/uv #平均访问量
print("访问量:",uv,"访客数:",pv,"平均访问量:",avgpv)
结果如下:
![]()
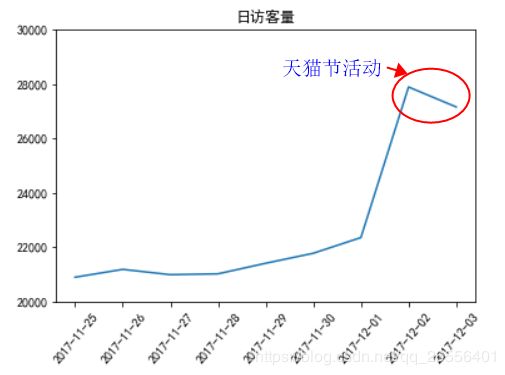
#日访客量、日点击量、日平均访客计算
dayUserCount = data.pivot_table(index=['day','user_id'],aggfunc='count') #透视表
dayUser = pd.DataFrame(dayUserCount.groupby(['day']).count()['behavior'])
pvData = data[data['behavior']=='pv']
dayPv = pd.DataFrame(pvData.pivot_table(index=['day'],aggfunc='count')['user_id']) #透视表
DayDate = pd.merge(dayUser, dayPv,on = 'day')
DayDate = DayDate.rename(columns = {'behavior':'日访客量','user_id':'日点击量'})
DayDate['日均点击量'] = DayDate['日点击量']/DayDate['日访客量']
#日访客图表分析
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] #指定默认字体
mpl.rcParams['axes.unicode_minus']
plt.plot(DayDate['日访客量'])
plt.xticks(rotation=50)
plt.title("日访客量")
plt.ylim(20000, 30000)

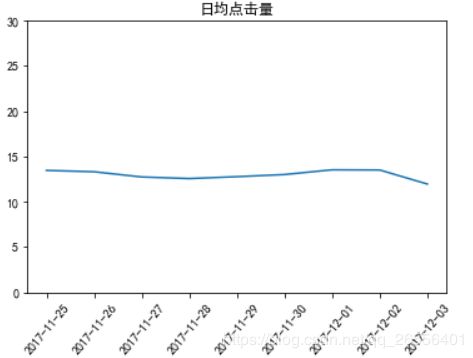
#分时访客分析
hourUserCount = data.pivot_table(index=['hour','user_id'],aggfunc='count') #透视表
hourUser = pd.DataFrame(hourUserCount.groupby(['hour']).count()['behavior'])
pvData = data[data['behavior']=='pv']
hourPv = pd.DataFrame(pvData.pivot_table(index=['hour'],aggfunc='count')['user_id']) #透视表
hourdata = pd.merge(hourUser, hourPv,on = 'hour')
hourdata = hourdata.rename(columns = {'behavior':'小时访客量','user_id':'小时点击量'})
hourdata['小时均点击量'] = hourdata['小时点击量']/hourdata['小时访客量']
#分时图表绘制
ax = plt.bar(range(len(hourdata)),hourdata['小时均点击量'])
plt.xticks(rotation=50)
plt.title("分时点击量分布")
plt.ylim(0, 15)
#高销量商品ID与商品类目
#前10高销量商品
#其成交量和转化率情况
itemData = pd.DataFrame()
pv = data[data['behavior']=='pv'] #商品点击量
itemPv= pd.DataFrame(pv.groupby(['item_id']).count()['behavior'])
buy= data[data['behavior']=='buy'] #商品购买量
itemBuy = pd.DataFrame(buy.groupby(['item_id']).count()['behavior'])
itemData = pd.merge(itemBuy,itemPv,on='item_id')
itemData = itemData.rename(columns={'behavior_x':'商品购买量','behavior_y':'商品浏览量'})itemData['转化率'] = itemData['商品购买量'] /itemData['商品浏览量']
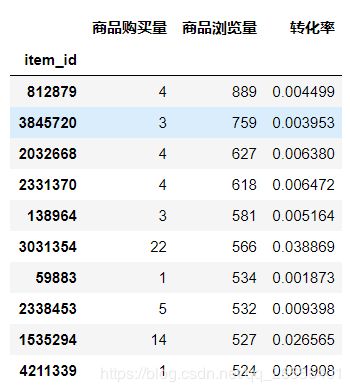
#流量前10商品id
itemData.sort_values(by = '商品浏览量',ascending=False).head(10)
结果如下:
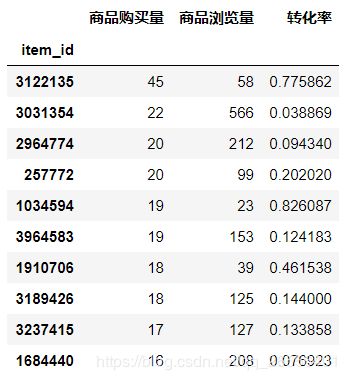
购买量前10商品id
itemData.sort_values(by = '商品购买量',ascending=False).head(10)
说明:本blog是作者本人熬夜做出来的,切勿抄袭哈。。。
内容待完善,下次更。。。