强化学习基础——形象化解释值函数含义以及期望的意义
1.值函数定义
1.1 V函数
我们先看一下经典的最短路问题,假设我们要求出起点s到终点g的最短路
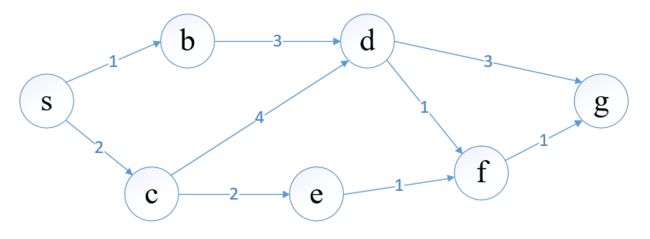
我们定义 V ∗ ( s ) V^\ast(s) V∗(s)为 s s s到终点 g g g的最短路, V ∗ ( f ) V^\ast(f) V∗(f) 为 f f f到终点 g g g的最短路,以此类推,为了求出这个最短路,我们从终点开始算起:
V ∗ ( g ) = 0 V ∗ ( f ) = 1 + V ∗ ( g ) = 1 V ∗ ( d ) = m i n { 3 + V ∗ ( g ) , 1 + V ∗ ( f ) } \begin{aligned} V^\ast(g)&=0 \\ V^\ast(f)&=1+V^\ast(g)=1\\ V^\ast(d)&=min\{3+V^\ast(g),1+V^\ast(f)\} \end{aligned} V∗(g)V∗(f)V∗(d)=0=1+V∗(g)=1=min{3+V∗(g),1+V∗(f)}
对终点 g g g来说,自己到自己的最短路为0。
对顶点 f f f来说,只有它自己和终点 g g g有路径,故顶点 f f f到 g g g的最短路由这条路径的权重和 V ∗ ( g ) V^\ast(g) V∗(g)相加
对顶点 d d d来说,有两个选择,可以选择权值为3的路径到 g g g,也可以选择权值为1的路径到 f f f,取这两种选择里最优选择即可
这样从后往前计算,我们可以得到起点 s s s到终点 g g g的最短路 V ∗ ( s ) V^\ast(s) V∗(s)
1.2 Q函数
有时我们除了要知道最短路,还要知道最短路这条路径的走向(即怎么走到终点),故我们还需要一个变量记录当前顶点的选择,我们定义 Q ∗ ( s , a ) Q^\ast(s,a) Q∗(s,a)为从 s s s顶点选择 a a a路径到终点 g g g的最短路,拿图例来说,顶点 s s s出发有两条路径可选,一条权值为1到达 b b b,记作 a 1 a_1 a1,一条权值为2到达 c c c,记作 a 2 a_2 a2(在强化学习中,我们可以将顶点定义为状态,选择路径定义为动作)
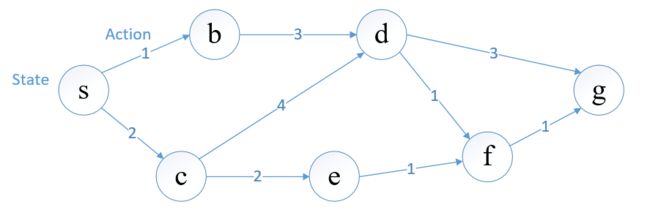
如果 s s s选择 a 1 a_1 a1路径,那么 Q ∗ ( s , a 1 ) Q^\ast(s,a_1) Q∗(s,a1)由这条路权值和 b b b到终点的最短路决定
Q ∗ ( s , a 1 ) = 1 + V ∗ ( b ) Q^\ast(s,a_1)=1+V^\ast(b) Q∗(s,a1)=1+V∗(b)
同样对于 a 2 a_2 a2路径,有
Q ∗ ( s , a 2 ) = 2 + V ∗ ( c ) Q^\ast(s,a_2)=2+V^\ast(c) Q∗(s,a2)=2+V∗(c)
对于 s s s点到终点的最短路,由这两种选择的最小值决定
V ∗ ( s ) = m i n { Q ∗ ( s , a 1 ) , Q ∗ ( s , a 2 ) } V^\ast(s)=min\{Q^\ast(s,a_1),Q^\ast(s,a_2)\} V∗(s)=min{Q∗(s,a1),Q∗(s,a2)}
我们可以将 V V V完全由 Q Q Q函数代替,以 Q ∗ ( s , a 2 ) Q^\ast(s,a_2) Q∗(s,a2)为例
Q ∗ ( s , a 2 ) = 2 + m i n { Q ∗ ( c , a 4 ) , Q ∗ ( c , a 2 ) } Q^\ast(s,a_2)=2+min\{Q^\ast(c,a_4), Q^\ast(c,a_2)\} Q∗(s,a2)=2+min{Q∗(c,a4),Q∗(c,a2)}
现在我们不仅求得了最优值,还记录了每次的选择。
1.3 通过随机性引入期望
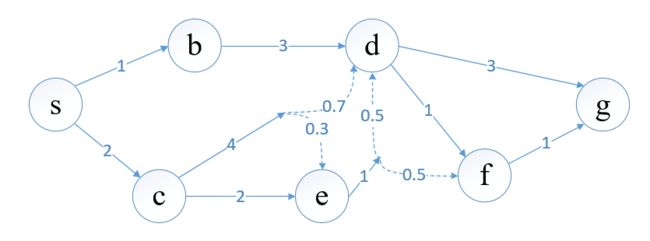
在之前的图中两点之间的到达关系是确定的,现在的图中两点之间具有概率关系,如 c c c点选择 a 4 a_4 a4路径有0.7的概率到达 d d d,有0.3的概率到达 e e e。
从原点到终点,即使策略确定(在每个点选择哪条路是确定的),最终得到的路径值是一个随机变量,因此我们定义最短路为期望最短路。
以 c c c为例,如果选择 a 4 a_4 a4路径,期望最短路为
Q ∗ ( c , a 4 ) = 4 + 0.7 ∗ m i n { Q ∗ ( d , a 3 ) , Q ∗ ( d , a 1 ) } + 0.3 ∗ Q ∗ ( e , a 1 ) Q^\ast(c,a_4)=4+0.7*min\{Q^\ast(d,a_3),Q^\ast(d,a_1)\}+0.3*Q^\ast(e,a_1) Q∗(c,a4)=4+0.7∗min{Q∗(d,a3),Q∗(d,a1)}+0.3∗Q∗(e,a1)
抽象化这个式子,顶点由 s s s表示,决策由 a a a表示,权值由顶点和决策决定,即 r ( s , a ) r(s,a) r(s,a), p ( s ′ ∣ s , a ) p(s^\prime|s,a) p(s′∣s,a)表示由当前顶点选择决策到下一个顶点的概率
Q ∗ ( s , a ) = r ( s , a ) + ∑ s ′ [ p ( s ′ ∣ s , a ) ∗ m i n a ′ Q ′ ( s ′ , a ′ ) ] = r ( s , a ) + E s ′ ∼ p ( s ′ ∣ s , a ) [ m i n a ′ Q ′ ( s ′ , a ′ ) ] \begin{aligned} Q^\ast(s,a)&=r(s,a)+\sum_{s^\prime}[p(s^\prime|s,a)*min_{a^\prime}Q^\prime(s^\prime,a^\prime)]\\ &=r(s,a)+E_{s^\prime\sim p(s^\prime|s,a)}[min_{a^\prime}Q^\prime(s^\prime,a^\prime)] \end{aligned} Q∗(s,a)=r(s,a)+s′∑[p(s′∣s,a)∗mina′Q′(s′,a′)]=r(s,a)+Es′∼p(s′∣s,a)[mina′Q′(s′,a′)]
在强化学习中,我们一般要最大化目标值,即将上式的 m i n min min改为 m a x max max,便得到 Q Q Q函数的最优贝尔曼方程
2. 关于期望
对于强化学习的目标,常常定义为
J ( θ ) = m a x θ E τ ∼ p θ ( τ ) R ( τ ) J(\theta)=max_\theta E_{\tau \sim p_\theta(\tau)}R(\tau) J(θ)=maxθEτ∼pθ(τ)R(τ)
τ \tau τ表示一条轨迹,可以类比于上面从原点到终点的一条路径, R ( τ ) R(\tau) R(τ)表示这条轨迹总的回报值,是一个随机变量,满足 p θ ( τ ) p_\theta(\tau) pθ(τ)这个概率分布,最终目标为最大化期望回报值。
R ( τ ) R(\tau) R(τ)是轨迹下每一步的决策回报加和,即 R ( τ ) = ∑ t = 0 T − 1 r ( s t , a t ) R(\tau)=\sum_{t=0}^{T-1}r(s_t,a_t) R(τ)=∑t=0T−1r(st,at),即 T T T个随机变量的和,每一个随机变量 r ( s t , a t ) r(s_t,a_t) r(st,at)由状态动作对 ( s t , a t ) (s_t,a_t) (st,at)决定,服从 p θ ( s t , a t ) p_\theta(s_t,a_t) pθ(st,at)概率分布
对于第一个随机变量 r ( s 0 , a 0 ) r(s_0,a_0) r(s0,a0)
p θ ( s 0 , a 0 ) = p ( s 0 ) π θ ( a 0 ∣ s 0 ) p ( s 1 ∣ s 0 , a 0 ) p_\theta(s_0,a_0)=p(s_0)\pi_\theta(a_0|s_0)p(s_1|s_0,a_0) pθ(s0,a0)=p(s0)πθ(a0∣s0)p(s1∣s0,a0)
第二个随机变量 r ( s 1 , a 1 ) r(s_1,a_1) r(s1,a1)
p θ ( s 1 , a 1 ) = p ( s 0 ) π θ ( a 0 ∣ s 0 ) p ( s 1 ∣ s 0 , a 0 ) π ( a 1 ∣ s 1 ) p ( s 2 ∣ s 1 , a 1 ) p_\theta(s_1,a_1)=p(s_0)\pi_\theta(a_0|s_0)p(s_1|s_0,a_0)\pi(a_1|s_1)p(s_2|s_1,a_1) pθ(s1,a1)=p(s0)πθ(a0∣s0)p(s1∣s0,a0)π(a1∣s1)p(s2∣s1,a1)
以此类推。
这 T T T个随机变量的联合概率分布可以认为是最后一个随机变量的概率分布 p θ ( s T − 1 , a T − 1 ) p_\theta(s_{T-1},a_{T-1}) pθ(sT−1,aT−1)
p θ ( s T − 1 , a T − 1 ) = p ( s 0 ) ∏ t = 0 T − 1 π θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) p_\theta(s_{T-1},a_{T-1})=p(s_0)\prod_{t=0}^{T-1}\pi_\theta(a_t|s_t)p(s_{t+1}|s_t,a_t) pθ(sT−1,aT−1)=p(s0)t=0∏T−1πθ(at∣st)p(st+1∣st,at)
也可以认为是该轨迹服从的概率分布
目标函数可以写为
J ( θ ) = m a x θ E τ ∼ p θ ( τ ) ∑ t = 0 n − 1 r ( s t , a t ) J(\theta)=max_\theta E_{\tau \sim p_\theta(\tau)}\sum_{t=0}^{n-1}r(s_t,a_t) J(θ)=maxθEτ∼pθ(τ)t=0∑n−1r(st,at)
有时为了凸显期望下标显示联合概率分布含义,也写作
J ( θ ) = m a x θ E s 0 , a 0 , s 1 ⋯ s T ∑ t = 0 n − 1 r ( s t , a t ) J(\theta)=max_\theta E_{s_0,a_0,s_1\cdots s_{T}}\sum_{t=0}^{n-1}r(s_t,a_t) J(θ)=maxθEs0,a0,s1⋯sTt=0∑n−1r(st,at)
我们还知道,期望的和等于和的期望,所以我们可以把求和提到期望外面
J ( θ ) = m a x θ ∑ t = 0 n − 1 E ( s t , a t ) ∼ p θ ( s t , a t ) r ( s t , a t ) J(\theta)=max_\theta \sum_{t=0}^{n-1}E_{(s_t,a_t)\sim p_\theta(s_t,a_t)}r(s_t,a_t) J(θ)=maxθt=0∑n−1E(st,at)∼pθ(st,at)r(st,at)
期望的下标也相应换成各自随机变量满足的概率分布
对于无限长度轨迹的情况,我们考虑以下的目标函数
J ( θ ) = m a x θ E ( s , a ) ∼ p θ ( s , a ) r ( s , a ) J(\theta)=max_\theta E_{(s,a)\sim p_\theta(s,a)}r(s,a) J(θ)=maxθE(s,a)∼pθ(s,a)r(s,a)
其中 p θ ( s , a ) p_\theta(s,a) pθ(s,a)表示稳态分布
参考资料
CS 294 Deep Reinforcement Learning
CS 598 Statistical Reinforcement Learning