机器学习面试真题1000题详细讲解(七)


python进阶教程
机器学习
深度学习
长按二维码关注
进入正文
201 最小二乘法是线性回归的一种解决方法,其实也是投影,但是并没有进行降维。下面哪些是基于核的机器学习算法?()
202 ![]()

203  解析详见:http://blog.csdn.net/snoopy_yuan/article/details/71703019
解析详见:http://blog.csdn.net/snoopy_yuan/article/details/71703019
204 神经网络中激活函数的真正意义?一个激活函数需要具有哪些必要的属性?还有哪些属性是好的属性但不必要的?205 梯度下降法的神经网络容易收敛到局部最优,为什么应用广泛?
https://www.zhihu.com/question/68109802/answer/262143638
人们直观的想象,高维的时候这样的局部极值会更多,指数级的增加,于是优化到全局最优就更难了。然而单变量到多变量一个重要差异是,单变量的时候,Hessian矩阵只有一个特征值,于是无论这个特征值的符号正负,一个临界点都是局部极值。但是在多变量的时候,Hessian有多个不同的特征值,这时候各个特征值就可能会有更复杂的分布,如有正有负的不定型和有多个退化特征值(零特征值)的半定型
在后两种情况下,是很难找到局部极值的,更别说全局最优了。207 请比较下EM算法、HMM、CRF。

208 带核的SVM为什么能分类非线性问题?

(2)Boosting之AdaBoost 
其次,两者都是线性模型。
209 用贝叶斯机率说明Dropout的原理
DeepFace 先进行了两次全卷积+一次池化,提取了低层次的边缘/纹理等特征。后接了3个Local-Conv层,这里是用Local-Conv的原因是,人脸在不同的区域存在不同的特征(眼睛/鼻子/嘴的分布位置相对固定),当不存在全局的局部特征分布时,Local-Conv更适合特征的提取。210 什么是共线性, 跟过拟合有什么关联?211 为什么网络够深(Neurons 足够多)的时候,总是可以避开较差Local Optima?212 机器学习中的正负样本213 机器学习中,有哪些特征选择的工程方法?214 在一个n维的空间中, 最好的检测outlier(离群点)的方法是()
![]()
(协方差矩阵中每个元素是各个矢量元素之间的协方差Cov(X,Y),Cov(X,Y) = E{ [X-E(X)] [Y-E(Y)]},其中E为数学期望)
![]()
若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则公式就成了:
![]()
也就是欧氏距离了。 215 对数几率回归(logistics regression)和一般回归分析有什么区别?216 bootstrap数据是什么意思?(提示:考“bootstrap”和“boosting”区别)217 “过拟合”只在监督学习中出现,在非监督学习中,没有“过拟
合”,这是()218 对于k折交叉验证, 以下对k的说法正确的是()219 回归模型中存在多重共线性, 你如何解决这个问题?220 模型的高bias是什么意思, 我们如何降低它 ?221 训练决策树模型, 属性节点的分裂, 具有最大信息增益的图是下图的哪一个()
A. Outlook222 对于信息增益, 决策树分裂节点, 下面说法正确的是()223 如果SVM模型欠拟合, 以下方法哪些可以改进模型 ()
而, gamma参数是你选择径向基函数作为kernel后,该函数自带的一个参数.隐含地决定了数据映射到新的特征空间后的分布.224 下图是同一个SVM模型, 但是使用了不同的径向基核函数的gamma参数, 依次是g1, g2, g3 , 下面大小比较正确的是: A. g1 > g2 > g3225 假设我们要解决一个二类分类问题, 我们已经建立好了模型, 输出是0或1, 初始时设阈值为0.5, 超过0.5概率估计, 就判别为1, 否则就判别为0 ; 如果我们现在用另一个大于0.5的阈值, 那么现在关于模型说法, 正确的是 : 226 假设, 现在我们已经建了一个模型来分类, 而且有了99%的预测准确率, 我们可以下的结论是 : 227 使用k=1的knn算法, 下图二类分类问题, “+” 和 “o” 分别代表两个类, 那么, 用仅拿出一个测试样本的交叉验证方法, 交叉验证的错误率是多少:
A. g1 > g2 > g3225 假设我们要解决一个二类分类问题, 我们已经建立好了模型, 输出是0或1, 初始时设阈值为0.5, 超过0.5概率估计, 就判别为1, 否则就判别为0 ; 如果我们现在用另一个大于0.5的阈值, 那么现在关于模型说法, 正确的是 : 226 假设, 现在我们已经建了一个模型来分类, 而且有了99%的预测准确率, 我们可以下的结论是 : 227 使用k=1的knn算法, 下图二类分类问题, “+” 和 “o” 分别代表两个类, 那么, 用仅拿出一个测试样本的交叉验证方法, 交叉验证的错误率是多少: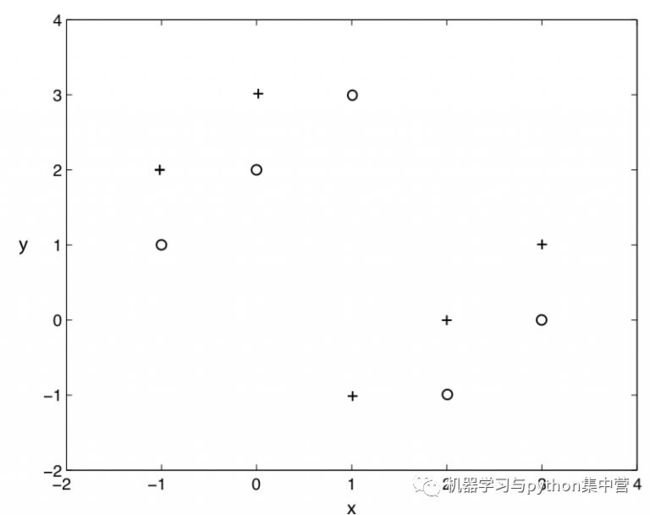 A. 0%228 我们想在大数据集上训练决策树, 为了使用较少时间, 我们可以:229 决策树没有学习率参数可以调. (不像集成学习和其它有步长的学习方法)决策树只有一棵树, 不是随机森林.230 假如我们使用非线性可分的SVM目标函数作为最优化对象, 我们怎么保证模型线性可分?
A. 0%228 我们想在大数据集上训练决策树, 为了使用较少时间, 我们可以:229 决策树没有学习率参数可以调. (不像集成学习和其它有步长的学习方法)决策树只有一棵树, 不是随机森林.230 假如我们使用非线性可分的SVM目标函数作为最优化对象, 我们怎么保证模型线性可分?
1.
2.
3.
4.
5.
6.
7.
8.

赶紧关注我们吧
您的点赞和分享是我们进步的动力!
↘↘↘