Docker部署MySQL 8.0配置主从同步,Docker部署Mycat配置读写分离,数据库分片
- 首先准备一台centos服务器
安装docker环境:
参考:https://www.runoob.com/docker/centos-docker-install.html
- docker部署MySQL
注意:创建docker的文件挂载目录,用docker安装MySQL的话必须让容器的存储目录挂载到宿主机,不然容器遇到故障有可能数据就没了.
在宿主机上创建两个文件夹:
/etc/mysql/conf.d 存放配置文件
/etc/mysql/data 存放MySQL数据
我用的是daocloud家的MySQL镜像,也可以用官方的,都一样
docker run --name mysql
-v /etc/mysql/conf.d:/etc/mysql/conf.d
-v /etc/mysql/data:/var/lib/mysql
-e MYSQL_ROOT_PASSWORD=123456 -d daocloud.io/mysql:8.0.11该命令会自动拉取镜像,并运行,命令中两行-v的意思就是冒号前面是宿主机的目录,冒号后是容器的目录
-e是该镜像自定义的一个环境变量,可以初始化MySQL的登录密码
容器运行起来之后,进入容器,修改加密方式和配置远程登录:
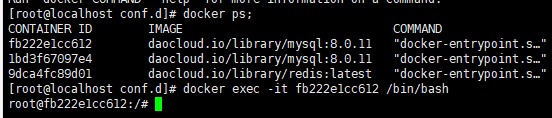
然后登录MySQL
mysql -u root -p123456
因为MySQL8.0版本的密码加密方式跟5.7版本不一样了,这里还是改成5.7版本的密码加密方式,不然的话,navicat这类客户端连接工具是连不上的,从库连接主库也可能会有问题
mysql> UPDATE user set host='%' where user='root';
刷新:
mysql> flush privileges;
授权:
mysql> GRANT ALL ON *.* TO 'root'@'%';
mysql> ALTER USER 'root'@'%' IDENTIFIED BY '123456' PASSWORD EXPIRE NEVER;
mysql> ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';因为我们要做主从和读写分离,所以至少需要两台以上的MySQL,参照上面的步骤再部署两个MySQL就可以了
- Docker部署Mycat
环境准备:jdk1.7以上,我这里用的1.8
mycat下载地址:http://www.mycat.org.cn/
在服务器root目录新建文件夹:mycat

Dockerfile的内容如下:
FROM docker.io/centos
COPY ./jdk-8u201-linux-x64.tar.gz /usr/local/
RUN tar -zxvf /usr/local/jdk-8u201-linux-x64.tar.gz -C /usr/local/
ENV JAVA_HOME=/usr/local/jdk1.8.0_201
ENV PATH=$PATH:$JAVA_HOME/bin
ENV CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
COPY ./Mycat-server-1.6.7.3-release-20190927161129-linux.tar.gz /usr/local/
RUN tar -zxvf /usr/local/Mycat-server-1.6.7.3-release-20190927161129-linux.tar.gz -C /usr/local/
ENV MYCAT_HOME=/usr/local/mycat
VOLUME ["/usr/local/mycat/conf","/usr/local/mycat/log"]
RUN source /etc/profile
RUN source ~/.bash_profile
EXPOSE 8066
CMD ["/usr/local/mycat/bin/mycat", "console"]
Dockerfile的内容很好理解,就是将宿主机的两个安装包拷贝到容器中的/usr/local目录,然后解压安装包配置jdk环境变量
VOLUME ["/usr/local/mycat/conf","/usr/local/mycat/log"] 是容器需要挂载的目录,我们mycat的配置文件肯定需要挂载到宿主机;
配置数据库分片:
scheme.xml和server.xml这两个文件可以从安装包的默认配置文件中拷贝出来
我这里是一台服务器Docker部署了两个MySQL,另外一台部署了一个,所以scheme.xml看起来是这样的:
select user()
select user()
select user()
server.xml只需要改user就可以了:

这里是mycat的登录用户名和密码,都是user
如果有多台或者多个实例,可以参考官方的配置拓展一下就可以了,这里不再细说
启动容器:
docker run -d --name mycat --restart=always \
-p 8066:8066 \
-v /home/mycat/conf:/usr/local/mycat/conf \
-v /home/mycat/logs:/usr/local/mycat/logs \
mycat:1.0查看mycat日志:
docker logs [容器id]
如果看到日志最后一行是Running Mycat-server... 则代表启动成功,然后现在就可以用数据库连接工具连接mycat了
插入数据测试一下:
用navicat连接mycat,选择相应的数据库,账户密码就是刚刚配置的server.xml里面的user,user
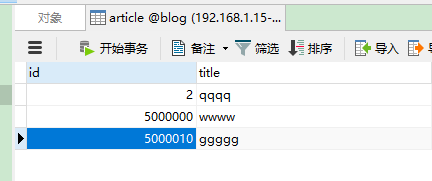
任意插入id不同的数据,逻辑表看到就是三条,但是这三条数据是分布在不同的物理表,可以查看到:
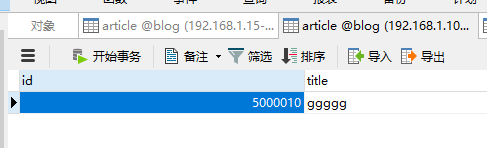
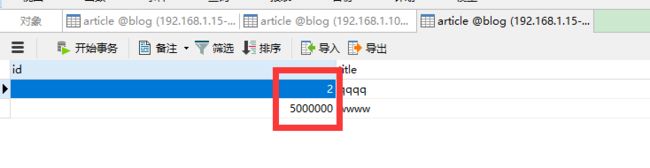
id一定要差异大一点,不然可能还是分到同一个数据库了,因为我们选的规则就是auto-sharding-long
如果id太大,就需要新增数据节点了:
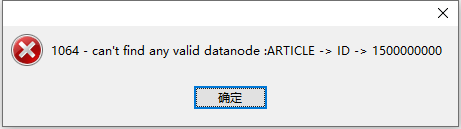
Mycat 分片规则
分片规则概述
在数据切分处理中,特别是水平切分中,中间件最终要的两个处理过程就是数据的切分、数据的聚合。选择合适的切分规则,至
关重要,因为它决定了后续数据聚合的难易程度,甚至可以避免跨库的数据聚合处理。
前面讲了数据切分中重要的几条原则,其中有几条是数据冗余,表分组(Table Group),这都是业务上规避跨库join的很好的方
式,但不是所有的业务场景都适合这样的规则,因此本章将讲述如何选择合适的切分规则。
a. Mycat全局表
如果你的业务中有些数据类似于数据字典,比如配置文件的配置,常用业务的配置或者数据量不大很少变动的表,这些表往往不
是特别大,而且大部分的业务场景都会用到,那么这种表适合于Mycat全局表,无须对数据进行切分,只要在所有的分片上保存一
份数据即可,Mycat 在Join操作中,业务表与全局表进行Join聚合会优先选择相同分片内的全局表join,避免跨库Join,在进行
数据插入操作时,mycat将把数据分发到全局表对应的所有分片执行,在进行数据读取时候将会随机获取一个节点读取数据。
目前Mycat没有做全局表的数据一致性检查,后续版本1.4之后可能会提供全局表一致性检查,检查每个分片的数据一致性。
全局表的配置如下
b. ER分片表
有一类业务,例如订单(order)跟订单明细(order_detail),明细表会依赖于订单,也就是说会存在表的主从关系,这类似业务
的切分可以抽象出合适的切分规则,比如根据用户ID切分,其他相关的表都依赖于用户ID,再或者根据订单ID切分,总之部分业务
总会可以抽象出父子关系的表。这类表适用于ER分片表,子表的记录与所关联的父表记录存放在同一个数据分片上,避免数据
Join跨库操作。
以order与order_detail例子为例,schema.xml中定义如下的分片配置,order,order_detail 根据order_id进行数据切分,保证相
同order_id的数据分到同一个分片上,在进行数据插入操作时,Mycat会获取order所在的分片,然后将order_detail也插入到
order所在的分片。
c. 多对多关联
有一类业务场景是 “主表A+关系表+主表B”,举例来说就是商户会员+订单+商户,对应这类业务,如何切分?
从会员的角度,如果需要查询会员购买的订单,那按照会员进行切分即可,但是如果要查询商户当天售出的订单,
那又需要按照商户做切分,可是如果既要按照会员又要按照商户切分,几乎是无法实现,这类业务如何选择切分规则非常难。目
前还暂时无法很好支持这种模式下的3个表之间的关联。目前总的原则是需要从业务角度来看,关系表更偏向哪个表,即“A的关
系”还是“B的关系”,来决定关系表跟从那个方向存储,未来Mycat版本中将考虑将中间表进行双向复制,以实现从A-关系表
以及B-关系表的双向关联查询如下图所示:
d. 主键分片vs 非主键分片
当你没人任何字段可以作为分片字段的时候,主键分片就是唯一选择,其优点是按照主键的查询最快,当采用自动增长的序列号
作为主键时,还能比较均匀的将数据分片在不同的节点上。
若有某个合适的业务字段比较合适作为分片字段,则建议采用此业务字段分片,选择分片字段的条件如下:
1. 尽可能的比较均匀分布数据到各个节点上;
2. 该业务字段是最频繁的或者最重要的查询条件。
常见的除了主键之外的其他可能分片字段有“订单创建时间”、“店铺类别”或“所在省”等。当你找到某个合适的业务字段作
为分片字段以后,不必纠结于“牺牲了按主键查询记录的性能”,因为在这种情况下,MyCAT提供了“主键到分片”的内存缓存
机制,热点数据按照主键查询,丝毫不损失性能。
对于非主键分片的table,填写属性primaryKey,此时MyCAT会将你根据主键查询的SQL语句的第一次执行结果进行分析,确定
该Table 的某个主键在什么分片上,并进行主键到分片ID的缓存。第二次或后续查询mycat会优先从缓存中查询是否有id–>node
即主键到分片的映射,如果有直接查询,通过此种方法提高了非主键分片的查询性能。
本节主要讲了如何去分片,如何选择合适分片的规则,总之尽量规避跨库Join是一条最重要的原则,下一节将介绍Mycat目前已有的分片规则,每种规则都有特定的场景,分析每种规则去选择合适的应用到项目中。
- MySQL主从复制和读写分离
主库在我们启动docker的时候,挂载了配置文件到宿主机,所以配置不用再进入容器修改了
在宿主机目录/etc/mysql/conf.d修改my.cnf文件
[mysqld]
sql_mode=STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION
# 配置需要主从的数据库
binlog-do-db=blog
# binlog忽略的数据库
binlog-ignore-db=mysql
# 启用二进制日志
log-bin=mysql-bin
# 服务器唯一id,一般为ip后缀
server-id=15
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
secure-file-priv= NULL然后重启容器:
docker restart [容器id]
创建用户并授权:
GRANT ALL PRIVILEGES ON *.* TO 'slave'@'%';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* to 'slave'@'%';
FLUSH PRIVILEGES;查看主库状态:
show master status;记住File字段和Position字段
- 从库配置
一样也是在宿主机的文件挂载目录修改配置,参考上面主库的修改方式,只是要注意server-id必须跟主库不一样;
然后连接从库,可以用navicat这类工具连接,然后执行命令:
change master to master_host='172.17.0.2',master_port=3306,master_user='slave',master_password='123456',master_log_file='mysql-bin.000005',master_log_pos=155 master_log_file就是刚刚show master status出来的File字段值,master_log_pos就是Position字段的值,分别表示binlog日志的文件名和位置;注意master_host的值,一定要正确,如果是单台机器部署了多个Docker容器,这个host不能配localhost或者其他,要配Docker容器的ip,可以这样查看宿主机所有的容器ip:
docker inspect -f '{{.Name}} - {{.NetworkSettings.IPAddress }}' $(docker ps -aq)启动从库复制功能:
start slave;
show slave status;
如果Slave_IO_Running不是yes,那就要检查主库的ip端口,账户密码是否正确 ;
如果Slave_SQL_Running不是yes,那就stop slave然后在navicat执行命令set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;再start slave就可以了
至此,主从复制就配置好了,然后测试一下在navicat下,主库手动插入一条数据,然后查一下从库,也有一条相同的数据了;(从库需要有同样的数据库才能插入成功)
读写分离:
还是上面分片的配置文件scheme.xml
show slave status
select user()
select user()
在datahost节点下新增了一个readhost
参数含义:
Balance参数设置:
1. balance=“0”, 所有读操作都发送到当前可用的writeHost上。
2. balance=“1”,所有读操作都随机的发送到readHost。
3. balance=“2”,所有读操作都随机的在writeHost、readhost上分发
4. balance=”3”,所有读请求随机的分发到wiriterHost对应的readhost执行,writerHost不负担读压力
WriteType参数设置:
1. writeType=“0”, 所有写操作都发送到可用的writeHost上。
2. writeType=“1”,所有写操作都随机的发送到readHost。
3. writeType=“2”,所有写操作都随机的在writeHost、readhost分上发。
“readHost是从属于writeHost的,即意味着它从那个writeHost获取同步数据,因此,当它所属的writeHost宕机了,则它也不会再参与到读写分离中来,即“不工作了”,这是因为此时,它的数据已经“不可靠”了。基于这个考虑,目前mycat 1.3和1.4版本中,若想支持MySQL一主一从的标准配置,并且在主节点宕机的情况下,从节点还能读取数据,则需要在Mycat里配置为两个writeHost并设置banlance=1。”
switchType 目前有三种选择:
-1:表示不自动切换
1 :默认值,自动切换
2 :基于MySQL主从同步的状态决定是否切换“Mycat心跳检查语句配置为 show slave status ,dataHost 上定义两个新属性: switchType="2" 与slaveThreshold="100",此时意味着开启MySQL主从复制状态绑定的读写分离与切换机制。Mycat心跳机制通过检测 show slave status 中的 "Seconds_Behind_Master", "Slave_IO_Running", "Slave_SQL_Running" 三个字段来确定当前主从同步的状态以及Seconds_Behind_Master主从复制时延。“
如何测试读写分离是否成功呢?
可以这样,我们配置的是读从库,写主库,从库会去主动同步主库的binlog,所以在navicat中,我们把从库的数据删几条
主库:

从库:
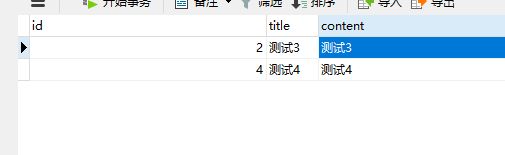
balance配置的是3,意思就是主库不承担读的压力,所有的读请求都会分发到从库;
那select * from article where title='测试2'就查不出来,'测试2'这条数据只在主库才有;
如果还是能查出来,就检查一下balance是不是配错了
好了,剩下的就自己玩了